Вступление
В ноябре прошлого года появилась книга Magnus Lie Hetland под названием «Python Algorithms: Mastering Basic Algorithms in the Python Language». Автор много лет занимается программированием и сейчас читает курс теории алгоритмов в одном из норвежских университетов. В своей книге он довольно простыми словами объясняет методы построения и анализа алгоритмов, а также приводит множество примеров, ориентированных на программистов на Python. Автор сосредотачивает свое внимание на практическом подходе к построению и оптимизации решений различных алгоритмических задач. В одном из обзоров говорится, что эту книгу можно сравнить с классическим трудом Кормена.
Мы с tanenn понемногу переводим эту книгу, и я предлагаю вашему вниманию перевод части первой главы — «Empirical Evaluation of Algorithms».
Эмпирическая оценка алгоритмов
В этой книге описывается проектирование алгоритмов (и тесно связанный с ним анализ алгоритмов). Но в разработке есть также и другой немаловажный процесс, жизненно необходимый при создании крупных реальных проектов, это — оптимизация алгоритмов. С точки зрения такого разделения, проектирование алгоритма можно рассматривать как способ достижения низкой асимптотической сложности алгоритма (с помощью разработки эффективного алгоритма), а оптимизацию — как уменьшение констант, скрытых в этой асимптотике.
Хотя я могу дать несколько советов по алгоритмам проектирования в Python, сложно угадать, какие именно хитрости и уловки дадут вам лучшую производительность в конкретной задаче, над которой вы работаете, или для вашего оборудования и версии Python. (Асимптотики используются как раз для того, чтобы не было нужды прибегать к таким вещам). Вообще, в некоторых случаях хитрости могут вовсе не потребоваться, потому что ваша программа и так достаточно быстра. Самое простое, что вы можете сделать в большинстве случаев, это просто пробовать и смотреть. Если у вас есть идея какого-то хака, то просто опробуйте ее! Реализуйте свою хитрость и запустите несколько тестов. Есть ли улучшения? А если это изменение делает ваш код менее читаемым, а прирост производительности мал, то подумайте — стоит ли оно того?
Хотя теоретические аспекты так называемой экспериментальной алгоритмики (то есть, экспериментальной оценки алгоритмов и их реализации) и выходят за рамки этой книги, я дам вам несколько практических советов, которые могут быть весьма полезны.
Совет 1. Если возможно, то не беспокойтесь об этом
Беспокойство об асимптотической сложности может быть очень полезным. Иногда решение задачи из-за сложности на практике может перестать быть таковым. Однако, постоянные константы в асимптотике часто совсем не критичны. Попробуйте простую реализацию алгоритма для начала, и убедитесь, что она работает стабильно. Если она работает — не трогайте ее.
Совет 2. Для измерения времени работы используйте timeit
Модуль timeit предназначен для измерения времени работы. Хотя для получения действительно надежных данных вам потребуется выполнить кучу работы, для практических целей timeit вполне сгодится. Например:
>>> import timeit
>>> timeit.timeit("x = 2 + 2")
0.034976959228515625
>>> timeit.timeit("x = sum(range(10))")
0.92387008666992188Модуль timeit можно использовать прямо из командной строки, например:
$ python -m timeit -s"import mymodule as m" "m.myfunction()"Существует кое-что, с чем вы должны быть осторожны при использовании timeit: побочные эффекты, которые будут влиять на повторное исполнение timeit. Функция timeit будет запускать ваш код несколько раз, чтобы увеличить точность, и если прошлые запуски влияют на последующие, то вы окажетесь в затруднительном положении. Например, если вы измеряете скорость выполнения чего-то вроде mylist.sort(), список будет отсортирован только в первый раз. Во время остальных тысяч запусков список уже будет отсортированным и это даст нереально маленький результат.
Больше информации об этом модуле и о том, как он работает, можно найти в документации стандартной библиотеки Python.
Совет 3. Чтобы найти узкие места, используйте профайлер
Часто, для того чтобы понять, какие части программы требуют оптимизации, делаются разные догадки и предположения. Такие предположения нередко оказываются ошибочными. Вместо того, чтобы гадать, воспользуйтесь профайлером. В стандартной поставке Python идет несколько профайлеров, но рекомендуется использовать cProfile. Им так же легко пользоваться, как timeit, но он дает больше подробной информации о том, на что тратится время при выполнении программы. Если основная функция вашей программы называется main, вы можете использовать профайлер следующим образом:
import cProfile
cProfile.run('main()')Такой код выведет отчет о времени работы различных функций программы. Если в вашей системе нет модуля cProfile, используйте profile вместо него. Больше информации об этих модулях можно найти в документации. Если же вам не так интересны детали реализации, а просто нужно оценить поведение алгоритма на конкретном наборе данных, воспользуйтесь модулем trace из стандартной библиотеки. С его помощью можно посчитать, сколько раз будут выполнены то или иное выражение или вызов в программе.
Совет 4. Показывайте результаты графически
Визуализация может стать прекрасным способом, чтобы понять что к чему. Для исследования производительности часто применяются графики (например, для оценки связи количества данных и времени исполнения) и диаграммы типа «ящик с усами», отображающие распределение временных затрат при нескольких запусках. Примеры можно увидеть на рисунке.
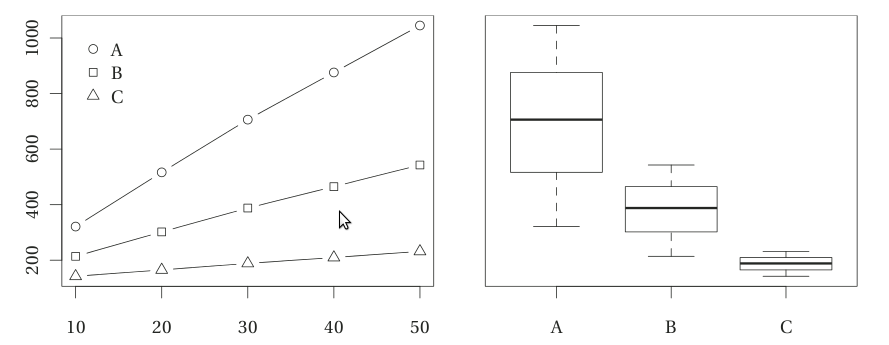
Отличная библиотека для построения графиков и диаграмм из Python — matplotlib (можно взять на http://matplotlib.sf.net).
Совет 5. Будьте внимательны в выводах, основанных на сравнении времени выполнения
Этот совет довольно расплывчатый, потому что существует много ловушек, в которые можно попасть, делая выводы о том, какой способ лучше, на основании сравнения времени работы. Во-первых, любая разница, которую вы видите, может определяться случайностью. Если вы используете специальные инструменты вроде timeit, риск такой ситуации меньше, потому что они повторяют измерение времени вычисления выражения несколько раз (или даже повторяют весь замер несколько раз, выбирая лучший результат). Таким образом, всегда будут случайные погрешности и если разница между двумя реализациями не превышает некоторой погрешности, нельзя сказать, что эти реализации различаются (хотя и то, что они одинаковы, тоже нельзя утверждать).
Проблема усложняется, если вы сравниваете больше двух реализаций. Количество пар для сравнения увеличивается пропорционально квадрату количества сравниваемых версий, сильно увеличивая вероятность того, что как минимум две из версий будут казаться слегка различными. (Это называется проблемой множественного сравнения). Существуют статистические решения этой проблемы, но самый простой способ — повторить эксперимент с двумя подозрительными версиями. Возможно, потребуется сделать это несколько раз. Они по-прежнему выглядят похожими?
Во-вторых, есть несколько моментов, на которые нужно обращать внимание при сравнении средних величин. Как минимум, вы должны сравнивать средние значения реального времени работы. Обычно, чтобы получить показательные числа при измерении производительности, время работы каждой программы нормируется делением на время выполнения какого-нибудь стандартного, простого алгоритма. Действительно, это может быть полезным, но в ряде случаев сделает бессмысленными результаты замеров. Несколько полезных указаний на эту тему можно найти в статье «How not to lie with statistics: The correct way to summarize benchmark results» Fleming and Wallace. Также можно почитать Bast and Weber's «Don't compare averages», или более новую статью Citron и др. "The harmonic or geometric mean: does it really matter?".
И в-третьих, возможно, ваши выводы нельзя обобщать. Подобные измерения на другом наборе входных данных и на другом железе могут дать другие результаты. Если кто-то будет пользоваться результаты ваших измерений, необходимо последовательно задокументировать, каким образом вы их получили.
Совет 6. Будьте осторожны, делая выводы об асимптотике из экспериментов
Если вы хотите что-то сказать окончательно об асимптотике алгоритма, то необходимо проанализировать ее, как описано ранее в этой главе. Эксперименты могут дать вам намеки, но они очевидно проводятся на конечных наборах данных, а асимптотика — это то, что происходит при сколь угодно больших размерах данных. С другой стороны, если только вы не работаете в академической сфере, цель асимптотического анализа — сделать какой-то вывод о поведении алгоритма, реализованного конкретным способом и запущенного на определенном наборе данных, а это значит, что измерения должны быть соответствующими.
Предположим, вы предполагаете, что алгоритм работает с квадратичной сложностью, но вы не можете окончательно доказать это. Можете ли вы использовать эксперименты для доказательства вашего предположения? Как уже говорилось, эксперименты (и оптимизация алгоритмов) имеют дело в основном с постоянными коэффициентами, но выход есть. Основной проблемой является то, что ваша гипотеза на самом деле непроверяема экспериментально. Если вы утверждаете, что алгоритм имеет сложность О(n²), то данные не могут это ни подтвердить, ни опровергнуть. Тем не менее, если вы сделаете вашу гипотезу более конкретной, то она станет проверяемой. Вы могли бы, например, основываясь на некоторых данных положить, что время работы программы никогда не будет превышать 0.24n²+0.1n+0.03 секунд в вашем окружении. Это проверяемая (точнее, опровергаемая) гипотеза. Если вы сделали множество измерений, но так и не можете найти контр-примеры, значит ваша гипотеза может быть верна. А это уже и подтверждает гипотезу о квадратичной сложности алгоритма.
Заключение
Саму книгу можно заказать, например, на Amazon.
Следующие в очереди на перевод — главы о представлении и работе с графами и деревьями. Автор описывает практические аспекты эффективной работы с этими структурами данных средствами Python.
