Вы наверное уже слышали о технологии масштабирования Liquid Resize, которая учитывает содержимое изображения. Если вам интересно как оно все работает и как можно реализовать все это самому, то читайте далее (осторожно, много рисунков).

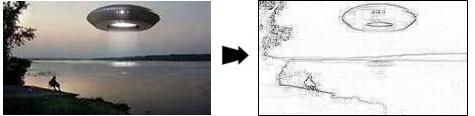
(НЛО прилетело и растянуло этот рисунок здесь)
Статья выложена мной по просьбе моего друга, который не может поместить ее на хабр, поскольку не имеет аккаунта. Благодаря вашим плюсам у автора появился инвайт, и он теперь с нами: Kotter.
Seam Carving — это алгоритм изменения размеров изображения, который учитывает содержимое изображения (как называют авторы — Content-Aware Image Resizing Algorithm). Впервые был продемонстрирован в 2007 году и вызвал немалый интерес. Наверное многие читатели Хабра про него слышали, поскольку тут уже были статьи на эту тему.
Возникает тогда вопрос: как же этот алгоритм учитывает содержимое изображений? В теории тут все просто — сначала вычисляется важность разных участков изображения, после чего изменяются в размере только те части, которые, по мнению алгоритма, являются не такими важными. На практике же для реализации этого алгоритма надо решить ряд вопросов: как определить насколько важными являются части изображения, как найти и сжать менее важные участки изображения и т. д.
В этой статье я попытался ответить на эти, а также на ряд других вопросов, возникающих при решении данной задачи.
Те, кто уже сейчас хотят посмотреть что у меня в итоге получилось, могут в конце статьи найти примеры изображений и демо-программу с прокомментированными исходниками.
Перед самой статьей хочется оговорить некоторые условности.
Во-первых. В статье я часто использую термин «энергия», хотя и не уверен в правильности этого термина. А использую я его потому, что сами авторы называют это английским словом «energy». Энергия точки означает ее важность в изображении. Чем больше энергия — тем важнее точка.
Во-вторых. В статье рассматривается только изменение размера по-горизонтали. При одновременном изменении размера по обоих направлениях принцип остается тот-же, только мы теперь рассматриваем не только вертикальные цепочки пикселей, но и горизонтальные.
В-третьих. У меня нету опыта написания под C#/.NET. Выбор платформы/языка написания программы был обусловлен простотой кода для понимания и широким охватом аудитории. Поэтому если я что-то написал в программе неэффективно или не «по дотнетовски», то не обращайте на это внимание. Не в этом суть программы.
В-четвертых. Русский для меня не родной язык, поэтому извините за возможные ошибки.
И последнее. Код программы не оптимален. Между простотой кода и оптимальностью кода я выбирал простоту, поэтому если вы захотите где-то использовать этот алгоритм — оптимизируйте его под свою задачу. Благо простор для оптимизаций там есть.
Вот, собственно, с прелюдией закончили, теперь переходим к самому интересному...
Весь алгоритм состоит из таких составных частей:
Теперь рассмотрим каждый пункт более детально.
Первым делом нам надо решить какие участки изображения важны, а какие не очень.
Для решения этой задачи авторы алгоритма предлагают для каждого пикселя посчитать его «энергию» — то есть какой-то условный показатель (в попугаях), который буде показывать важен ли данный пиксел в данном изображении, или не очень.
В принципе способов это сделать много: от самых простых (например посчитать изменения цвета по сравнению с соседними) до достаточно сложных (например сделать анализ акцентирования внимания человека). По словам самих авторов, они проверили множество функций энергии, и одна из самых простых функций дала один из лучших результатов. Поэтому мы воспользуемся сейчас этой функцией. Вот она:
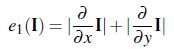
Если вы при виде данной формулы с производными испугались, что вам надо будет вспоминать матанализ, то зря. На самом деле она формулируется достаточно просто: энергия пикселя равна изменению цвета соседних пикселей по сравнению с данным пикселом. То есть чем больше разница в цвете между данным пикселем и соседними — тем больше его энергия.
Теперь рассмотрим реализацию вычислений энергии на практике. Пусть точки изображения характеризуются своей интенсивностью. У нас есть следующее изображение размером 3х3 точки:
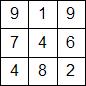
Сначала посчитаем по модулю разницу интенсивностей между пикселем и его соседями (справа и снизу), а потом вычислим энергию этого пикселя как среднее арифметическое этих значений.
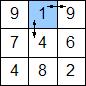
Для выделенного пикселя: разница между ним и соседом справа — 8, соседом снизу — 3. Среднее арифметическое — (8+3)/2 = 5.5. Но поскольку с целыми числами работать удобнее и быстрее, а такая точность излишняя, то отбросим дробную часть. То есть энергия выделенного пикселя равна 5.
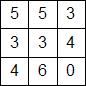
Аналогично посчитаем для остальных пикселей. При этом пиксели, которые крайние справа и крайние снизу будут иметь только соседа справа или снизу, поэтому для них значение разницы и будет средним арифметическим. Для пикселя в правом-нижнем углу таких соседей вообще нет, поэтому мы просто примем его энергию за 0. Хотя теоретически можно и для него посчитать энергию, но не будем усложнять себе жизнь, поскольку на практике им можно пренебречь.
В результате получим следующую матрицу энергий пикселей:
Если же у нас пиксели характеризуются не просто интенсивностью, а значением интенсивности отдельно для R, G, B, то энергия пикселя равна сумме энергий по каждой из компонент.
Пример карты энергий для изображения:
На этой картинке чем темнее цвет на карте энергий — тем больше энергия.
Я реализовал нахождение энергий пикселей с помощью следующей функции:
Функция работает с глобальными переменными: energy — массив, в который записываются энергии и image — массив, в котором хранится изображение.
У нас уже есть значения энергий для каждого пикселя, но теперь нам надо выбрать те пиксели у которых значение энергии минимальное. Но если мы начнем забирать/добавлять произвольные пиксели, то само изображение у нас просто расползется, и деформируется до неузнаваемости. Конечно такой результат нам не подходит. Поэтому сначала надо выбрать цепочку пикселей, а потом уж их удалять или прибавлять. При чем не произвольную цепочку, а «правильную».
«Правильная» цепочка — это набор точек, такой, что в каждой строчке изображения выбран ровно 1 пиксел, а пикселы в соседних строчках «соединены» или сторонами, или углами.
Пример «правильных» цепочек:

Пример «неправильных» цепочек:

Теперь мы знаем, что удалять надо «правильные» цепочки, тогда мы не сильно испортим изображение. Но какую цепочку тогда выбрать? Авторы алгоритма предлагают выбрать для удаления/растяжение те цепочки, сумма энергий пикселей, которые входят в нее, минимальна.
Отсюда возникает вполне естественный вопрос: как нам найти такую цепочку?
Вариант первый — перебираем все цепочки, их суммируем, и находим с минимальной суммой. Вариант, конечно, интересный, но тогда для обработки даже небольшого изображения нам надо будет ждать вечность :) Если у нас есть вечность в запасе, то пишем код полного перебора, запускаем и ждем. Если вы хотите увидеть результат за более короткий промежуток времени — то читаем дальше.
Тут нам на помощь приходить динамическое программирование. Не буду углубляться в детали, и показывать в чем именно «динамичность» программирования (кстати термин «программирование» тут отношения к написанию кода не имеет), и сразу перейду непосредственно к алгоритму. Если кто-то не знает, что такое «динамическое программирование» и хочет узнать — может почитать об этом на Википедии, или других источниках.
Сначала мы создадим новый массив, который по размеру равен массиву с энергиями пикселей. В этот массив мы для каждого пикселя запишем сумму элементов минимальной цепочки пикселей, которая начинается у верхнего края изображения и заканчивается на данном пикселе.
Покажем процесс вычисления на примере. Пусть у нас есть массив с значениями энергий для каждого пикселя:
Будем вычислять элементы этого массива по строчкам — от первой к последней. Для верхней строчки элементы данного массива будут равны элементам массива, поскольку из каждого такого элемента можно только 1 цепочку построить (все единичной длины):
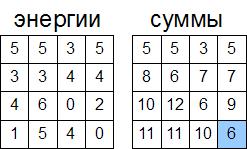
Теперь вычислим вторую строчку. Рассмотрим выделенную ячейку. Мы, чтобы построить цепочку от этой ячейки, можем пойти тремя способами, как показано на рисунке. Из этих трех способов нам надо выбрать минимальный (поскольку ми считаем суммы именно минимальных цепочек). Для выделенной ячейки это будет цепочка с суммой 3, и к этой цепочке прибавляем энергию самой ячейки. Поэтому в эту ячейку запишем число 7 (сумма 3 и 4). Аналогично посчитаем все суммы для всех элементов второй строки:

Перейдем к третьей строчке. В принципе, третья строчка считается аналогично второй. Снова рассмотрим выделенную ячейку. От нее мы можем образовать такие цепочки:
После вычисления таким образом всех строчек мы получим в результате следующий массив:
Если формализовать вычисление этого массива, то получим следующую формулу:
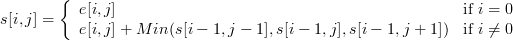
где s — наш массив сумм, а e — массив энергий.
Мой вариант реализации вычисления массива сумм:
Функция работает с глобальными переменными: energy — массив, в котором записаны энергии и sum — массив, в который записываются значения сумм.
Теперь, когда у нас уже есть этот массив, настало время задуматься — а для чего он вообще нам надо? Отвечу — по этому массиву мы теперь можем быстро найти цепочку с минимальной суммой энергий.
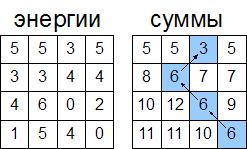
Сначала мы найдем какой пиксел из нижней строчки изображения принадлежит этой цепочке: элемент, что мы ищем, будет иметь наименьшее значение в массиве сумм среди элементов нижней строчки. Почему? Вспомните, что в данном массиве записаны значения сумм элементов минимальных цепочек от верхнего края до данного пиксела. Цепочки, которые нас интересуют заканчиваются на пикселе из последнего ряда. Соответственно для всего рисунка минимальная цепочка будет выбрана как минимальная из всех минимальных цепочек, которые заканчиваются на пикселях из нижней строчки.
Для нашего примера это будет следующий элемент:
Мы уже знаем на каком пикселе заканчивается минимальная цепочка, теперь мы можем найти пиксел из предпоследней строчки. Как уже было написано, из нижнего пиксела мы можем пойти только в 3 соседние пиксели на строчку выше: слева-сверху, сверху или справа-сверху. Среди этих пикселей выбираем пиксел с минимальным значением в массиве сумм, и переходим к нему. Продолжаем, пока на дойдем до верхней строчки. Процесс показан на следующем рисунке:
После выполнения всех этих операций мы получим то, чего и хотели — набор пикселей, которые мы можем изменить с минимальными потерями для изображения.
Пример минимальной цепочки на рисунке:

Программная реализация алгоритма поиска цепочки:
Мы, наконец-то, нашли цепочку пикселей, c которыми будем работать. Теперь можно вспомнить зачем вообще мы ее искали. Наша задача — изменение размера изображения. Увеличение и уменьшение изображение немного отличаются, поэтому сначала рассмотрим уменьшение, а потом уже увеличение.
Если нам надо уменьшить ширину картинки на 1 пиксел, то тут все просто: находим вертикальную цепочку, как это описывается выше, и просто удаляем ее из изображение. Я реализовал эту операцию с помощью следующего цикла:
В i-м элементе массива cropPixels записан номер столбика пикселя, который мы удаляем из i-й строчки. А сам цикл делает следующее: все пиксели, которые записаны справа от тех, которых удаляем, мы сдвигаем на одну точку влево. В результате этой операции наша цепочка пикселей будет удалена из изображения.
Если нам надо уменьшить изображение не на 1 пиксел, а на большее значение, то выполняем операцию удаления цепочки столько раз, сколько надо (каждый раз при этом нам надо будет эту цепочку искать).
Хочу обратить внимание, что операция уменьшения изображения на n пикселей и операция уменьшения изображения на 1 пиксел n раз не являются эквивалентными. Их отличие в том, что если мы уменьшаем на 1 пиксел n раз, то мы для каждой из промежуточных изображений ищем энергию пикселей, а если сразу уменьшаем на n, то энергии пикселей мы берем из исходного изображения.
Уменьшать изображения мы уже умеем, теперь надо выяснить, как же их надо увеличивать.
Первое, что приходит на ум — это точно так же, как и при уменьшении, выбирать цепочки и их «растягивать». Но если мы это реализуем мы получим такой результат:

Как мы видим, программа просто взяла один столбик и его растянула, а это не совсем то, что нам надо.
Следующая мысль может быть, например, такой: надо брать не одну минимальную цепочку, а столько, сколько надо, чтобы дополнить рисунок до нужной ширины. Допустим мы реализовали данный алгоритм, но что будет, если мы увеличим рисунок в 2 раза?

Как видно из этого рисунка — мы просто выбрали все точки, и растянули их по горизонтали, но это тоже не совсем то, что нам надо, поскольку этот способ не отличается от обычного растягивания.
Но в принципе сама идея последнего способа правильная, но с небольшим изменением: нам надо увеличивать изображение поэтапно, так, чтобы на каждом этапе охватывалось как можно больше «не важных» частей изображения, и как можно меньше «важных». Тогда возникает вопрос, как разбить процесс увеличение на этапы? Вариантов много — от разбиения на этапы вручную, до написания каких-то эвристических анализаторов. Но в своей программе я написал просто — разбивание на этапы происходит таким образом, чтобы на каждом этапе изображение не увеличивалось больше, чем на 50%. Иногда это дает приемлемый результат, иногда не очень, но, как я уже написал, вариантов реализации разбиения на этапы можно придумать много.
Если увеличить таким образом нашу картинку с НЛО, то получим следующий результат:

Как видим, НЛО, человек и дерево остались не измененными.
Все примеры масштабирования рисунков были получены с помощью программы, которую я написал параллельно с этой статьей, реализовав алгоритмы, которые здесь описываются.
Исходники и бинарник программы можете скачать внизу статьи.
Классический пример Content-Aware Resizing'а:

На следующей картинке ярко выражены «важные» объекты и фон.
(оригинал) (уменьшено) (увеличено)

Рисунок звездного неба. При изменении размера, форма звезд почти не изменяется.
(оригинал) (уменьшено) (увеличено)

И еще пример масштабирования двух фотографий, сделанных gmm.
(оригинал) (уменьшено) (увеличено)

(оригинал) (уменьшено) (увеличено)

Итак, что же мы получили в результате:
Спасибо тем, кто дочитал статью до конца, надеюсь было интересно.
Исходники (VS 2008)
Бинарник (.NET)
upd
Полезные линки по теме:

(НЛО прилетело и растянуло этот рисунок здесь)
Статья выложена мной по просьбе моего друга, который не может поместить ее на хабр, поскольку не имеет аккаунта. Благодаря вашим плюсам у автора появился инвайт, и он теперь с нами: Kotter.
Содержание
- Что такое Seam Carving?
- Несколько замечаний по прочтению статьи
- Общая схема алгоритма
- Вычисление энергии точек
- Нахождение цепочки с минимальной суммарной энергией
- Уменьшение рисунков
- Увеличение рисунков
- Примеры
- Итоги
Что такое Seam Carving?
Seam Carving — это алгоритм изменения размеров изображения, который учитывает содержимое изображения (как называют авторы — Content-Aware Image Resizing Algorithm). Впервые был продемонстрирован в 2007 году и вызвал немалый интерес. Наверное многие читатели Хабра про него слышали, поскольку тут уже были статьи на эту тему.
Возникает тогда вопрос: как же этот алгоритм учитывает содержимое изображений? В теории тут все просто — сначала вычисляется важность разных участков изображения, после чего изменяются в размере только те части, которые, по мнению алгоритма, являются не такими важными. На практике же для реализации этого алгоритма надо решить ряд вопросов: как определить насколько важными являются части изображения, как найти и сжать менее важные участки изображения и т. д.
В этой статье я попытался ответить на эти, а также на ряд других вопросов, возникающих при решении данной задачи.
Те, кто уже сейчас хотят посмотреть что у меня в итоге получилось, могут в конце статьи найти примеры изображений и демо-программу с прокомментированными исходниками.
Несколько замечаний по прочтению статьи
Перед самой статьей хочется оговорить некоторые условности.
Во-первых. В статье я часто использую термин «энергия», хотя и не уверен в правильности этого термина. А использую я его потому, что сами авторы называют это английским словом «energy». Энергия точки означает ее важность в изображении. Чем больше энергия — тем важнее точка.
Во-вторых. В статье рассматривается только изменение размера по-горизонтали. При одновременном изменении размера по обоих направлениях принцип остается тот-же, только мы теперь рассматриваем не только вертикальные цепочки пикселей, но и горизонтальные.
В-третьих. У меня нету опыта написания под C#/.NET. Выбор платформы/языка написания программы был обусловлен простотой кода для понимания и широким охватом аудитории. Поэтому если я что-то написал в программе неэффективно или не «по дотнетовски», то не обращайте на это внимание. Не в этом суть программы.
В-четвертых. Русский для меня не родной язык, поэтому извините за возможные ошибки.
И последнее. Код программы не оптимален. Между простотой кода и оптимальностью кода я выбирал простоту, поэтому если вы захотите где-то использовать этот алгоритм — оптимизируйте его под свою задачу. Благо простор для оптимизаций там есть.
Вот, собственно, с прелюдией закончили, теперь переходим к самому интересному...
Общая схема алгоритма
Весь алгоритм состоит из таких составных частей:
- Нахождение энергии каждой точки. На этом этапе нам надо узнать какие части изображения являются более важными, а какие — менее важными, исходя их этих данных мы в последствии будем менять размер изображения.
- Нахождение такой вертикальной цепочки пикселей, чтобы суммарная энергия пикселей, которые входят в эту цепочку была минимальной. Цепочка пикселей — это такой набор пикселей, что в каждой строке выбрано ровно по одному пикселю, и соседние пикселы в ней соединены сторонами или углами. Если мы найдем такую цепочку то сможем ее удалить из изображения, при этом минимально затронув информационное наполнение изображения.
- Когда мы нашли цепочку с минимальной энергией, то нам остается ее только удалить, если нам надо уменьшить изображение, или растянуть, если надо увеличить изображение.
Теперь рассмотрим каждый пункт более детально.
Вычисление энергии точек
Первым делом нам надо решить какие участки изображения важны, а какие не очень.
Для решения этой задачи авторы алгоритма предлагают для каждого пикселя посчитать его «энергию» — то есть какой-то условный показатель (в попугаях), который буде показывать важен ли данный пиксел в данном изображении, или не очень.
В принципе способов это сделать много: от самых простых (например посчитать изменения цвета по сравнению с соседними) до достаточно сложных (например сделать анализ акцентирования внимания человека). По словам самих авторов, они проверили множество функций энергии, и одна из самых простых функций дала один из лучших результатов. Поэтому мы воспользуемся сейчас этой функцией. Вот она:

Если вы при виде данной формулы с производными испугались, что вам надо будет вспоминать матанализ, то зря. На самом деле она формулируется достаточно просто: энергия пикселя равна изменению цвета соседних пикселей по сравнению с данным пикселом. То есть чем больше разница в цвете между данным пикселем и соседними — тем больше его энергия.
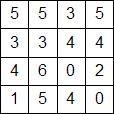
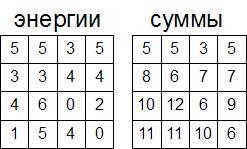
Теперь рассмотрим реализацию вычислений энергии на практике. Пусть точки изображения характеризуются своей интенсивностью. У нас есть следующее изображение размером 3х3 точки:

Сначала посчитаем по модулю разницу интенсивностей между пикселем и его соседями (справа и снизу), а потом вычислим энергию этого пикселя как среднее арифметическое этих значений.

Для выделенного пикселя: разница между ним и соседом справа — 8, соседом снизу — 3. Среднее арифметическое — (8+3)/2 = 5.5. Но поскольку с целыми числами работать удобнее и быстрее, а такая точность излишняя, то отбросим дробную часть. То есть энергия выделенного пикселя равна 5.
Аналогично посчитаем для остальных пикселей. При этом пиксели, которые крайние справа и крайние снизу будут иметь только соседа справа или снизу, поэтому для них значение разницы и будет средним арифметическим. Для пикселя в правом-нижнем углу таких соседей вообще нет, поэтому мы просто примем его энергию за 0. Хотя теоретически можно и для него посчитать энергию, но не будем усложнять себе жизнь, поскольку на практике им можно пренебречь.
В результате получим следующую матрицу энергий пикселей:

Если же у нас пиксели характеризуются не просто интенсивностью, а значением интенсивности отдельно для R, G, B, то энергия пикселя равна сумме энергий по каждой из компонент.
Пример карты энергий для изображения:
На этой картинке чем темнее цвет на карте энергий — тем больше энергия.
Я реализовал нахождение энергий пикселей с помощью следующей функции:
private void FindEnergy()
{
for (int i = 0; i < imgHeight; i++)
for (int j = 0; j < imgWidth; j++)
{
energy[i, j] = 0;
// Считаем отдельно для компонент R, G, B
for (int k = 0; k < 3; k++)
{
int sum = 0, count = 0;
// Если пиксел не крайний снизу, то добавляем в sum разность между текущим пикселом и соседом снизу
if (i != imgHeight - 1)
{
count++;
sum += Math.Abs((int)image[i, j, k] - (int)image[i + 1, j, k]);
}
// Если пиксел не крайний справа, то добавляем в sum разность между поточным пикселом и соседом справа
if (j != imgWidth - 1)
{
count++;
sum += Math.Abs((int)image[i, j, k] - (int)image[i, j + 1, k]);
}
// В массив energy добавляем среднее арифметическое разностей пикселя с соседями по k-той компоненте (то есть по R, G или B)
if (count != 0)
energy[i, j] += sum / count;
}
}
}
Функция работает с глобальными переменными: energy — массив, в который записываются энергии и image — массив, в котором хранится изображение.
Нахождение цепочки с минимальной суммарной энергией
У нас уже есть значения энергий для каждого пикселя, но теперь нам надо выбрать те пиксели у которых значение энергии минимальное. Но если мы начнем забирать/добавлять произвольные пиксели, то само изображение у нас просто расползется, и деформируется до неузнаваемости. Конечно такой результат нам не подходит. Поэтому сначала надо выбрать цепочку пикселей, а потом уж их удалять или прибавлять. При чем не произвольную цепочку, а «правильную».
«Правильная» цепочка — это набор точек, такой, что в каждой строчке изображения выбран ровно 1 пиксел, а пикселы в соседних строчках «соединены» или сторонами, или углами.
Пример «правильных» цепочек:

Пример «неправильных» цепочек:

Теперь мы знаем, что удалять надо «правильные» цепочки, тогда мы не сильно испортим изображение. Но какую цепочку тогда выбрать? Авторы алгоритма предлагают выбрать для удаления/растяжение те цепочки, сумма энергий пикселей, которые входят в нее, минимальна.
Отсюда возникает вполне естественный вопрос: как нам найти такую цепочку?
Вариант первый — перебираем все цепочки, их суммируем, и находим с минимальной суммой. Вариант, конечно, интересный, но тогда для обработки даже небольшого изображения нам надо будет ждать вечность :) Если у нас есть вечность в запасе, то пишем код полного перебора, запускаем и ждем. Если вы хотите увидеть результат за более короткий промежуток времени — то читаем дальше.
Тут нам на помощь приходить динамическое программирование. Не буду углубляться в детали, и показывать в чем именно «динамичность» программирования (кстати термин «программирование» тут отношения к написанию кода не имеет), и сразу перейду непосредственно к алгоритму. Если кто-то не знает, что такое «динамическое программирование» и хочет узнать — может почитать об этом на Википедии, или других источниках.
Сначала мы создадим новый массив, который по размеру равен массиву с энергиями пикселей. В этот массив мы для каждого пикселя запишем сумму элементов минимальной цепочки пикселей, которая начинается у верхнего края изображения и заканчивается на данном пикселе.
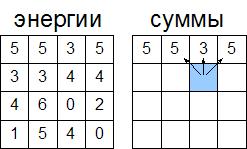
Покажем процесс вычисления на примере. Пусть у нас есть массив с значениями энергий для каждого пикселя:

Будем вычислять элементы этого массива по строчкам — от первой к последней. Для верхней строчки элементы данного массива будут равны элементам массива, поскольку из каждого такого элемента можно только 1 цепочку построить (все единичной длины):

Теперь вычислим вторую строчку. Рассмотрим выделенную ячейку. Мы, чтобы построить цепочку от этой ячейки, можем пойти тремя способами, как показано на рисунке. Из этих трех способов нам надо выбрать минимальный (поскольку ми считаем суммы именно минимальных цепочек). Для выделенной ячейки это будет цепочка с суммой 3, и к этой цепочке прибавляем энергию самой ячейки. Поэтому в эту ячейку запишем число 7 (сумма 3 и 4). Аналогично посчитаем все суммы для всех элементов второй строки:

Перейдем к третьей строчке. В принципе, третья строчка считается аналогично второй. Снова рассмотрим выделенную ячейку. От нее мы можем образовать такие цепочки:
- эта ячейка плюс минимальная цепочка длинны 8;
- эта ячейка плюс минимальная цепочка длинны 6;
- эта ячейка плюс минимальная цепочка длинны 7;
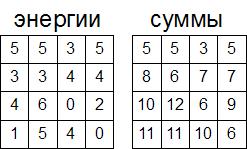
После вычисления таким образом всех строчек мы получим в результате следующий массив:
Если формализовать вычисление этого массива, то получим следующую формулу:
где s — наш массив сумм, а e — массив энергий.
Мой вариант реализации вычисления массива сумм:
private void FindSum()
{
// Для верхней строчки значение sum и energy будут совпадать
for (int j = 0; j < imgWidth; j++)
sum[0, j] = energy[0, j];
// Для всех остальных пикселей значение элемента (i,j) массива sum будут равны
// energy[i,j] + MIN ( sum[i-1, j-1], sum[i-1, j], sum[i-1, j+1])
for (int i = 1; i < imgHeight; i++)
for (int j = 0; j < imgWidth; j++)
{
sum[i, j] = sum[i - 1, j];
if (j > 0 && sum[i - 1, j - 1] < sum[i, j]) sum[i, j] = sum[i - 1, j - 1];
if (j < imgWidth - 1 && sum[i - 1, j + 1] < sum[i, j]) sum[i, j] = sum[i - 1, j + 1];
sum[i, j] += energy[i, j];
}
}
Функция работает с глобальными переменными: energy — массив, в котором записаны энергии и sum — массив, в который записываются значения сумм.
Теперь, когда у нас уже есть этот массив, настало время задуматься — а для чего он вообще нам надо? Отвечу — по этому массиву мы теперь можем быстро найти цепочку с минимальной суммой энергий.
Сначала мы найдем какой пиксел из нижней строчки изображения принадлежит этой цепочке: элемент, что мы ищем, будет иметь наименьшее значение в массиве сумм среди элементов нижней строчки. Почему? Вспомните, что в данном массиве записаны значения сумм элементов минимальных цепочек от верхнего края до данного пиксела. Цепочки, которые нас интересуют заканчиваются на пикселе из последнего ряда. Соответственно для всего рисунка минимальная цепочка будет выбрана как минимальная из всех минимальных цепочек, которые заканчиваются на пикселях из нижней строчки.
Для нашего примера это будет следующий элемент:

Мы уже знаем на каком пикселе заканчивается минимальная цепочка, теперь мы можем найти пиксел из предпоследней строчки. Как уже было написано, из нижнего пиксела мы можем пойти только в 3 соседние пиксели на строчку выше: слева-сверху, сверху или справа-сверху. Среди этих пикселей выбираем пиксел с минимальным значением в массиве сумм, и переходим к нему. Продолжаем, пока на дойдем до верхней строчки. Процесс показан на следующем рисунке:

После выполнения всех этих операций мы получим то, чего и хотели — набор пикселей, которые мы можем изменить с минимальными потерями для изображения.
Пример минимальной цепочки на рисунке:

Программная реализация алгоритма поиска цепочки:
private int[] FindShrinkedPixels()
{
// Номер последней строчки
int last = imgHeight - 1;
// Выделяем память под массив результатов
int[] res = new int[imgHeight];
// Ищем минимальный элемент массива sum, который находиться в нижней строке и записываем результат в res[last]
res[last] = 0;
for (int j = 1; j < imgWidth; j++)
if (sum[last, j] < sum[last, res[last]])
res[last] = j;
// Теперь вычисляем все элементы массива от предпоследнего до первого.
for (int i = last - 1; i >= 0; i--)
{
// prev - номер пикселя цепочки из предыдущей строки
// В этой строке пикселями цепочки могут быть только (prev-1), prev или (prev+1), поскольку цепочка должна быть связанной
int prev = res[i + 1];
// Здесь мы ищем, в каком элементе массива sum, из тех, которые мы можем удалить, записано минимальное значение и присваиваем результат переменной res[i]
res[i] = prev;
if (prev > 0 && sum[i, res[i]] > sum[i, prev - 1]) res[i] = prev - 1;
if (prev < imgWidth - 1 && sum[i, res[i]] > sum[i, prev + 1]) res[i] = prev + 1;
}
return res;
}
Уменьшение рисунков
Мы, наконец-то, нашли цепочку пикселей, c которыми будем работать. Теперь можно вспомнить зачем вообще мы ее искали. Наша задача — изменение размера изображения. Увеличение и уменьшение изображение немного отличаются, поэтому сначала рассмотрим уменьшение, а потом уже увеличение.
Если нам надо уменьшить ширину картинки на 1 пиксел, то тут все просто: находим вертикальную цепочку, как это описывается выше, и просто удаляем ее из изображение. Я реализовал эту операцию с помощью следующего цикла:
for (int i = 0; i < imgHeight; i++)
for (int j = cropPixels[i]; j < imgWidth; j++)
{
pImage[i, j] = pImage[i, j + 1];
}
В i-м элементе массива cropPixels записан номер столбика пикселя, который мы удаляем из i-й строчки. А сам цикл делает следующее: все пиксели, которые записаны справа от тех, которых удаляем, мы сдвигаем на одну точку влево. В результате этой операции наша цепочка пикселей будет удалена из изображения.
Если нам надо уменьшить изображение не на 1 пиксел, а на большее значение, то выполняем операцию удаления цепочки столько раз, сколько надо (каждый раз при этом нам надо будет эту цепочку искать).
Хочу обратить внимание, что операция уменьшения изображения на n пикселей и операция уменьшения изображения на 1 пиксел n раз не являются эквивалентными. Их отличие в том, что если мы уменьшаем на 1 пиксел n раз, то мы для каждой из промежуточных изображений ищем энергию пикселей, а если сразу уменьшаем на n, то энергии пикселей мы берем из исходного изображения.
Увеличение рисунков
Уменьшать изображения мы уже умеем, теперь надо выяснить, как же их надо увеличивать.
Первое, что приходит на ум — это точно так же, как и при уменьшении, выбирать цепочки и их «растягивать». Но если мы это реализуем мы получим такой результат:

Как мы видим, программа просто взяла один столбик и его растянула, а это не совсем то, что нам надо.
Следующая мысль может быть, например, такой: надо брать не одну минимальную цепочку, а столько, сколько надо, чтобы дополнить рисунок до нужной ширины. Допустим мы реализовали данный алгоритм, но что будет, если мы увеличим рисунок в 2 раза?

Как видно из этого рисунка — мы просто выбрали все точки, и растянули их по горизонтали, но это тоже не совсем то, что нам надо, поскольку этот способ не отличается от обычного растягивания.
Но в принципе сама идея последнего способа правильная, но с небольшим изменением: нам надо увеличивать изображение поэтапно, так, чтобы на каждом этапе охватывалось как можно больше «не важных» частей изображения, и как можно меньше «важных». Тогда возникает вопрос, как разбить процесс увеличение на этапы? Вариантов много — от разбиения на этапы вручную, до написания каких-то эвристических анализаторов. Но в своей программе я написал просто — разбивание на этапы происходит таким образом, чтобы на каждом этапе изображение не увеличивалось больше, чем на 50%. Иногда это дает приемлемый результат, иногда не очень, но, как я уже написал, вариантов реализации разбиения на этапы можно придумать много.
Если увеличить таким образом нашу картинку с НЛО, то получим следующий результат:

Как видим, НЛО, человек и дерево остались не измененными.
Примеры
Все примеры масштабирования рисунков были получены с помощью программы, которую я написал параллельно с этой статьей, реализовав алгоритмы, которые здесь описываются.
Исходники и бинарник программы можете скачать внизу статьи.
Классический пример Content-Aware Resizing'а:

На следующей картинке ярко выражены «важные» объекты и фон.

Рисунок звездного неба. При изменении размера, форма звезд почти не изменяется.

И еще пример масштабирования двух фотографий, сделанных gmm.


Итоги
Итак, что же мы получили в результате:
- Знание принципа работы такого интересного и полезного алгоритма, как Seam Carving;
- Программку, в которой можно поиграться в изменителя размеров изображений (конечно есть еще Photoshop и http://rsizr.com/, но в этих случаях у вас нет исходников);
- Простор для воображения по возможным улучшениям алгоритма (например можно детектор лиц к нему прицепить, результаты, думаю, будут получше);
- Знание, что Content-Aware Rescale в Photoshop это не особая фотошоповская магия, а обычный алгоритм, который поддается пониманию.
Спасибо тем, кто дочитал статью до конца, надеюсь было интересно.
P. S.
Исходники (VS 2008)
Бинарник (.NET)
upd
Полезные линки по теме:
- PDF, в котором авторы описывают алгоритм (англ, ~18 Мб).
- Улучшение способа подсчета энергии Sobol operator(англ).
- Динамическое программирование на русской Википедии. ДП использовалось в этом алгоритме, но имеет куда большую сферу применения, поэтому очень рекомендуеться почитать для тех, кто с ним не знаком.
- По просьбе prokoudine, упомяну о некоторых свободных реализациях алгоритма:
- Расширение Liquid Rescale для GIMP и ImageMagick, основаны на библиотеке liblqr,
- SeamCarvingGUI основанной на библиотеке CAIR

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}