Приветствую уважаемое сообщество!
Итак, это мой первый пост на хабре :)
Посвящен он будет серьезной теме, в которой, волею судеб, я неплохо разбираюсь. А именно, генной инженерии.
Помнится, тут пробегал пост в котором говорилось о геннотехнологической лаборатории “на коленке”. Оказалось, что тема интересна аудитории, поэтому я решил заняться ее развитием с просветительскими целями.
Я буду давать наглядные и понятные обычным людям примеры для описания сложных процессов. Если кто-то посчитает нужным меня поправить – не стесняйтесь. Я буду сознательно упускать многие вещи, но если вам кажется, что без них страдает логика изложения – так же поправляйте.
Итак, начнем. Допустим, мы хотим создать трансгенную новогоднюю елку светящуюся синим светом. Допустим, британские ученые как раз недавно открыли ген синего свечения. Вот и посмотрим на этот процесс по стадиям.
Ген свечения.
Будем вести эксперимент, как настоящие ученые. Они слышат что открыт новый ген, что же им делать дальше, если хочется создать елку?
Настоящий ученый обычно лезет в ncbi.nih.gov и по нескольким ключевым словам ищет научные публикации на эту тему. Например “синее свечение ген светится”. Типична ситуация, когда по одной из ссылок он действительно находит статью “британских ученых”, которая оказывается статьей группы китайских авторов, ни один из которых не отзывается на e-mail.
С другой стороны, в статье можно выяснить название этого гена. Пусть он будет называться ButiBl1 (названия генов принято давать буквенными обозначениями + индекс, а впереди может идти несколько первых букв названия организма из которого он выделен, их можно отбрасывать). ButiBl1, например, может быть расшифровано как Butiavka marina blue light 1 gene. Но правила здесь не строгие.
По названию гена в базе данных нуклеотидов ищут последовательность гена.Вот что примерно видит ученый на экране.
Кстати, мы можем воспользоваться инструментом BLAST и введя последовательность ДНК, получить, к каким генам она может относиться. Это тоже очень важный рутинный инструмент для генных инженеров.
Итак, мы получили последовательность гена. Очень хорошо, что дальше? Нужно ведь получить сам ген. Для этого вернемся к вопросу о том, что такое ДНК.
Про ДНК.
ДНК – это длинная молекула (очень длинная), является полимером из четырех вариантов маленьких молекул – азотистых оснований, попросту “букв”.
Геном клетки разбит на части — от одной до нескольких десятков молекул ДНК, причем обычно у каждой из них есть еще и своя копия -близнец, несущая те же гены. Каждая из молекул ДНК особым образом свернута чтобы поместиться в клетке и покрыта белковыми комплексами, образуя хромосому.
Я надеюсь, все это помнят, но если нужно освежить память, пожалуйста, в wiki :)
Итак, запомните главное:
1. ДНК – это молекула.
2. Так как это молекула, то ее не видно в микроскоп, не подцепить пинцетом и т.д. и т.п.
3. В клетке считаное количество молекул ДНК, причем если их много, то они разнородные и «собрать их пучком» чтобы подцепить пинцетом (пункт 2) тоже не получится.
Как же генные инженеры работают с молекулой ДНК если она одна и с ней невозможно провести никаких прямых манипуляций? Дело в том, что во всех процедурах происходит работа не с одной, а с множеством молекул ДНК, с тысячами и миллионами ее копий.
Тысячи таких одинаковых молекул плавают в водном растворе и этот раствор называется “препаратом ДНК”. Все манипуляции с молекулами проводятся типичными химическими методами.
То есть ученые работают не с одной молекулой, а с огромным их количеством в растворе с применением химических методов.
Как же нам получить ген bl1? Есть два способа. Первый – прямой химический синтез. Однако им не получить достаточно длинные молекулы из-за ошибок синтеза. Поясню, почему.
ДНК – это полимер. Его можно синтезировать наращивая по кирпичику, причем есть четыре кирпича разных цветов. На каждой стадии наращивания эффективность составляет порядка 99%. То есть из ста молекул одна получается неправильной. Теперь представьте, что нам нужно сделать молекулу длиной в 1000 букв? Тогда применяя банальную арифметику окажется, что доля верных молекул составит 0,99^1000=0,00004
Учитывая, что разделить верные и неверные молекулы почти невозможно, наша затея тут потерпит фиаско, и в реальных задачах синтез более 100-150 букв уже представляется малореалистичным.
Остается второй способ.
Потрошим бутявку
Мы выбиваем из шефа командировку на побережье Мальдивских островов, где только и водится пресловутая бутявка морская (Butiavka marina).
Ловим ее, толчем в порошок, заливаем последовательно разными химическими гадостями чтобы из всей массы тканей в растворе остались только молекулы ДНК. Конечный итог этого – препарат ДНК бутявки. Так как выделение производится из относительно большого образца, то там не одна молекула ДНК, а много – от каждой клетки по паре штук. Эта ДНК содержит не только ген bl1, но и все остальные бутявочные гены.
Этот этап называется выделением ДНК. Ее можно выделить не только в виде раствора, а переосадить и получить сухой препарат, то есть чистые молекулы ДНК.
Амплификация
Итак, командировка окончена, поэтому мы метнемся обратно в лабораторию где нас поджидает чудная процедура амплификации.
Смотрите, в препарате ДНК бутявки куча всяких разных генов, а не только нужный нам. Мы же можем работать только с однородными препаратами, нам нужно довести содержание молекул ДНК гена bl1 хотя бы процентов до 90.
И тут мы применяем поистине чудесный прием, являющийся краеугольным камнем современной биоинженерии, называемым полимеразной цепной реакцией или ПЦР (polymerase chain reaction, PCR). За открытие этого метода присудили нобелевскую премию, хотя до сих пор ходят споры о приоритете, поэтому фамилий не называю, кому интересно – почитайте.
Принцип полимеразной цепной реакции довольно сложен, объяснение дам очень грубое и только для того чтобы было хоть какое-то представление, за подробным – добро пожаловать по ссылке выше.
Итак, нам нужно размножить (амплифицировать) молекулы ДНК определенного гена. Для этого мы открываем страничку с последовательностью нашего гена и находим его концы. Берем 20-30 букв с конца и столько же с начала и синтезируем короткие молекулы ДНК химическим синтезом (обычно это делают специальные фирмы)
То есть мы имеем две новые пробирки. В одной из них плавает много коротких 30-буквенных последовательности ДНК, гомологичных началу гена, а во второй – то же самое, но для конца гена. Эти новые молекулы называются праймерами.
Теперь мы запускаем реакцию ПЦР, причем умножаться у нас будет участок между двумя праймерами (между начальным и концевым). Реакция ПЦР – это биохимическая циклическая реакция, требующая смены температуры. В свое время ее делали на водяных банях, теперь же используют специальные приборы – амплификаторы (они же ПЦР-машины). Их строение очень простое, там стоят элементы Пельтье, есть место для пробирок и ко всему этому присобачены электронные мозги и управляющая панель.

То есть вернулись мы в лабораторию с ДНК бутявки. Заказали два праймера — к началу и к концу гена. Потом взяли чистую пробирку, капнули туда чуть-чуть ДНК, чуть чуть каждого праймера, полимеразу (фермент, который строит ДНК), нуклеотидов для строительства ДНК, и немного солей для правильной работы фермента, поставили в амплификатор на пару часов. В амплификаторе смесь то нагревалась, то остужалась и на выходе мы получили пробирку в которой плавает очень много копий ДНК нужного нам гена.
Однако пробирка прозрачная, как увидеть что там есть какая-то ДНК, да еще нужная?
Детекция ДНК.
Существует много способов увидеть ДНК, я же опишу классический, называемый гель-электрофорезом.
В лаборатории имеется небольшая ванночка с электродами, называямая форезной камерой.
В эту ванночку заливается расплав электрофорезного геля, который по сути очень похож на мармелад. Но вместо сахара там находятся добавки солей и флуоресцентный краситель – бромистый этидий. Это вещество интересно тем, что встраивается в молекулу ДНК и в этом случае начинает светиться в ультрафиолете.
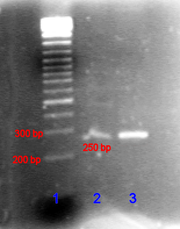
После того как гель застынет мы наносим в лунку на нем препарат ДНК где предположительно уже должно быть много копий гена bl1 и включаем электрический ток. В другую лунку наносим “маркер веса” – специальный препарат молекул ДНК, состоящий в равных долях из молекул длины 100, 200, 300 и т.д. нуклеотидов.
Молекулы ДНК полярны и движутся в электрическом поле, при этом чем они длиннее, тем сильнее цепляются за структуру геля и тем медленнее в нем движутся. Через некоторое время мы выключаем электричество и несем гель под ультрафиолетовую лампу.
На той дорожке где мы нанесли маркер веса мы видим кучу полосок. Самая дальняя от места нанесения пробы соответствует самой короткой ДНК, самая ближняя – самой длинной.
В соседних лунках ДНК бежит с одинаковой скоростью, поэтому мы сравниваем их расположение на соседних дорожках и можем определить, относительный размер.
Итак, мы обнаружили на дорожке где нанесли пробу одну светящуюся полоску и размер ее судя по соседнему маркеру веса является таким, каким мы ожидали.

Мы аккуратнентко вырезаем лезвием из геля этот светящийся кусочек – он содержит много ДНК гена bl1 запутавшейся в геле и с помощью специальных манипуляций высвобождаем из него молекулы.
Можно себя поздравить, мы выделили ген bl1 из бутявки!
Я рассказал только о первой стадии этого сложного и длинного процесса. Продолжать ли дальше? Решать вам :)
upd. Часть вторая.
Часть третья.
upd2. Перенес в биотехнологии
Итак, это мой первый пост на хабре :)
Посвящен он будет серьезной теме, в которой, волею судеб, я неплохо разбираюсь. А именно, генной инженерии.
Помнится, тут пробегал пост в котором говорилось о геннотехнологической лаборатории “на коленке”. Оказалось, что тема интересна аудитории, поэтому я решил заняться ее развитием с просветительскими целями.
Я буду давать наглядные и понятные обычным людям примеры для описания сложных процессов. Если кто-то посчитает нужным меня поправить – не стесняйтесь. Я буду сознательно упускать многие вещи, но если вам кажется, что без них страдает логика изложения – так же поправляйте.
Итак, начнем. Допустим, мы хотим создать трансгенную новогоднюю елку светящуюся синим светом. Допустим, британские ученые как раз недавно открыли ген синего свечения. Вот и посмотрим на этот процесс по стадиям.
Ген свечения.
Будем вести эксперимент, как настоящие ученые. Они слышат что открыт новый ген, что же им делать дальше, если хочется создать елку?
Настоящий ученый обычно лезет в ncbi.nih.gov и по нескольким ключевым словам ищет научные публикации на эту тему. Например “синее свечение ген светится”. Типична ситуация, когда по одной из ссылок он действительно находит статью “британских ученых”, которая оказывается статьей группы китайских авторов, ни один из которых не отзывается на e-mail.
С другой стороны, в статье можно выяснить название этого гена. Пусть он будет называться ButiBl1 (названия генов принято давать буквенными обозначениями + индекс, а впереди может идти несколько первых букв названия организма из которого он выделен, их можно отбрасывать). ButiBl1, например, может быть расшифровано как Butiavka marina blue light 1 gene. Но правила здесь не строгие.
По названию гена в базе данных нуклеотидов ищут последовательность гена.Вот что примерно видит ученый на экране.
Кстати, мы можем воспользоваться инструментом BLAST и введя последовательность ДНК, получить, к каким генам она может относиться. Это тоже очень важный рутинный инструмент для генных инженеров.
Итак, мы получили последовательность гена. Очень хорошо, что дальше? Нужно ведь получить сам ген. Для этого вернемся к вопросу о том, что такое ДНК.
Про ДНК.
ДНК – это длинная молекула (очень длинная), является полимером из четырех вариантов маленьких молекул – азотистых оснований, попросту “букв”.
Геном клетки разбит на части — от одной до нескольких десятков молекул ДНК, причем обычно у каждой из них есть еще и своя копия -близнец, несущая те же гены. Каждая из молекул ДНК особым образом свернута чтобы поместиться в клетке и покрыта белковыми комплексами, образуя хромосому.
Я надеюсь, все это помнят, но если нужно освежить память, пожалуйста, в wiki :)
Итак, запомните главное:
1. ДНК – это молекула.
2. Так как это молекула, то ее не видно в микроскоп, не подцепить пинцетом и т.д. и т.п.
3. В клетке считаное количество молекул ДНК, причем если их много, то они разнородные и «собрать их пучком» чтобы подцепить пинцетом (пункт 2) тоже не получится.
Как же генные инженеры работают с молекулой ДНК если она одна и с ней невозможно провести никаких прямых манипуляций? Дело в том, что во всех процедурах происходит работа не с одной, а с множеством молекул ДНК, с тысячами и миллионами ее копий.
Тысячи таких одинаковых молекул плавают в водном растворе и этот раствор называется “препаратом ДНК”. Все манипуляции с молекулами проводятся типичными химическими методами.
То есть ученые работают не с одной молекулой, а с огромным их количеством в растворе с применением химических методов.
Как же нам получить ген bl1? Есть два способа. Первый – прямой химический синтез. Однако им не получить достаточно длинные молекулы из-за ошибок синтеза. Поясню, почему.
ДНК – это полимер. Его можно синтезировать наращивая по кирпичику, причем есть четыре кирпича разных цветов. На каждой стадии наращивания эффективность составляет порядка 99%. То есть из ста молекул одна получается неправильной. Теперь представьте, что нам нужно сделать молекулу длиной в 1000 букв? Тогда применяя банальную арифметику окажется, что доля верных молекул составит 0,99^1000=0,00004
Учитывая, что разделить верные и неверные молекулы почти невозможно, наша затея тут потерпит фиаско, и в реальных задачах синтез более 100-150 букв уже представляется малореалистичным.
Остается второй способ.
Потрошим бутявку
Мы выбиваем из шефа командировку на побережье Мальдивских островов, где только и водится пресловутая бутявка морская (Butiavka marina).
Ловим ее, толчем в порошок, заливаем последовательно разными химическими гадостями чтобы из всей массы тканей в растворе остались только молекулы ДНК. Конечный итог этого – препарат ДНК бутявки. Так как выделение производится из относительно большого образца, то там не одна молекула ДНК, а много – от каждой клетки по паре штук. Эта ДНК содержит не только ген bl1, но и все остальные бутявочные гены.
Этот этап называется выделением ДНК. Ее можно выделить не только в виде раствора, а переосадить и получить сухой препарат, то есть чистые молекулы ДНК.
Амплификация
Итак, командировка окончена, поэтому мы метнемся обратно в лабораторию где нас поджидает чудная процедура амплификации.
Смотрите, в препарате ДНК бутявки куча всяких разных генов, а не только нужный нам. Мы же можем работать только с однородными препаратами, нам нужно довести содержание молекул ДНК гена bl1 хотя бы процентов до 90.
И тут мы применяем поистине чудесный прием, являющийся краеугольным камнем современной биоинженерии, называемым полимеразной цепной реакцией или ПЦР (polymerase chain reaction, PCR). За открытие этого метода присудили нобелевскую премию, хотя до сих пор ходят споры о приоритете, поэтому фамилий не называю, кому интересно – почитайте.
Принцип полимеразной цепной реакции довольно сложен, объяснение дам очень грубое и только для того чтобы было хоть какое-то представление, за подробным – добро пожаловать по ссылке выше.
Итак, нам нужно размножить (амплифицировать) молекулы ДНК определенного гена. Для этого мы открываем страничку с последовательностью нашего гена и находим его концы. Берем 20-30 букв с конца и столько же с начала и синтезируем короткие молекулы ДНК химическим синтезом (обычно это делают специальные фирмы)
То есть мы имеем две новые пробирки. В одной из них плавает много коротких 30-буквенных последовательности ДНК, гомологичных началу гена, а во второй – то же самое, но для конца гена. Эти новые молекулы называются праймерами.
Теперь мы запускаем реакцию ПЦР, причем умножаться у нас будет участок между двумя праймерами (между начальным и концевым). Реакция ПЦР – это биохимическая циклическая реакция, требующая смены температуры. В свое время ее делали на водяных банях, теперь же используют специальные приборы – амплификаторы (они же ПЦР-машины). Их строение очень простое, там стоят элементы Пельтье, есть место для пробирок и ко всему этому присобачены электронные мозги и управляющая панель.

То есть вернулись мы в лабораторию с ДНК бутявки. Заказали два праймера — к началу и к концу гена. Потом взяли чистую пробирку, капнули туда чуть-чуть ДНК, чуть чуть каждого праймера, полимеразу (фермент, который строит ДНК), нуклеотидов для строительства ДНК, и немного солей для правильной работы фермента, поставили в амплификатор на пару часов. В амплификаторе смесь то нагревалась, то остужалась и на выходе мы получили пробирку в которой плавает очень много копий ДНК нужного нам гена.
Однако пробирка прозрачная, как увидеть что там есть какая-то ДНК, да еще нужная?

Детекция ДНК.
Существует много способов увидеть ДНК, я же опишу классический, называемый гель-электрофорезом.
В лаборатории имеется небольшая ванночка с электродами, называямая форезной камерой.
В эту ванночку заливается расплав электрофорезного геля, который по сути очень похож на мармелад. Но вместо сахара там находятся добавки солей и флуоресцентный краситель – бромистый этидий. Это вещество интересно тем, что встраивается в молекулу ДНК и в этом случае начинает светиться в ультрафиолете.
После того как гель застынет мы наносим в лунку на нем препарат ДНК где предположительно уже должно быть много копий гена bl1 и включаем электрический ток. В другую лунку наносим “маркер веса” – специальный препарат молекул ДНК, состоящий в равных долях из молекул длины 100, 200, 300 и т.д. нуклеотидов.
Молекулы ДНК полярны и движутся в электрическом поле, при этом чем они длиннее, тем сильнее цепляются за структуру геля и тем медленнее в нем движутся. Через некоторое время мы выключаем электричество и несем гель под ультрафиолетовую лампу.
На той дорожке где мы нанесли маркер веса мы видим кучу полосок. Самая дальняя от места нанесения пробы соответствует самой короткой ДНК, самая ближняя – самой длинной.
В соседних лунках ДНК бежит с одинаковой скоростью, поэтому мы сравниваем их расположение на соседних дорожках и можем определить, относительный размер.
Итак, мы обнаружили на дорожке где нанесли пробу одну светящуюся полоску и размер ее судя по соседнему маркеру веса является таким, каким мы ожидали.
Мы аккуратнентко вырезаем лезвием из геля этот светящийся кусочек – он содержит много ДНК гена bl1 запутавшейся в геле и с помощью специальных манипуляций высвобождаем из него молекулы.
Можно себя поздравить, мы выделили ген bl1 из бутявки!
Я рассказал только о первой стадии этого сложного и длинного процесса. Продолжать ли дальше? Решать вам :)
upd. Часть вторая.
Часть третья.
upd2. Перенес в биотехнологии
