Часть 1 и Часть 2 в этом цикле статей показали, как создать приложение, используя mochiweb, и как передавать сообщения подключенным пользователям. Мы уменьшили постребление памяти до 8 Кб для каждого подключения. Мы повторили c10k тест. Мы сделали графики. Это была забава, но теперь пора повторить все для 1 миллиона соединений.
Это статья покрывает следующее:
• Использование базы данных Mnesia;
• Генерация правдоподобного набора данных вида «friends» для миллиона пользователей;
• Настройка Mnesia и ввод наших данных;
• Открытие миллиона соединений с одной машины;
• Сравнительный тест с 1 миллионом пользователей;
• Libevent + Си для обработки соединений;
• Финальные выводы.
Одна из частей этого теста заключается в возможности открыть 1 000 000 соединений с единственной тестовой машины. Написать сервер, который в состоянии принять 1 000 000 соединений легче, чем фактическое создавание 1 000 000 соединений. Таким образом, изрядная часть этой статьи о методах, используемых, чтобы открыть 1 000 000 соединений с единственной машины.
В части 2 мы использовали маршрутизатор, чтобы отправить сообщения определенным пользователям. Это прекрасно для chat/IM системы, но есть более полезные вещи, которые мы могли бы сделать вместо этого. Прежде, чем мы начнем крупномасштабный тест, давайте добавим еще один модуль – база данных подписчика. Мы создадим хранилище с данными о Ваших друзьях, таким образом, оно может предоставить Вам все события, сгенерированные людьми из Вашего списка друзей.
Мое намерение состоит в том, чтобы использовать это для Last.fm. Таким образом, я могу получить канал в реальном времени песен, которые мои друзья в настоящий момент слушают. Это может одинаково примениться и к другим событиям, сгенерированным в социальных сетях. Фото, загруженное в Flickr, элементы новостного канала Facebook, Twitter и т.д. У FriendFeed даже есть API в реальном времени в бете, таким образом, это определенно актуально.
Мы реализуем простой менеджер по подписке, но мы будем подписывать людей на всех их друзей автоматически.
API:
• add_subscriptions([{Subscriber, Subscribee},...])
• remove_subscriptions([{Subscriber, Subscribee},...])
• get_subscribers(User)
Примечательно:
• я включал qlc.hrl, необходимый для Mnesia, используя абсолютный путь. Это не хорошо, но по-другому у меня не получилось.
• get_subscribers порождает другой процесс и делегирует создание ответа этотому же процессу, используя gen_server:reply. Это означает, что цикл gen_server не будет блокироваться на этом вызове, если мы будем часто вызывать lookup.
• rr(”subsmanager.erl”). Пример ниже позволяет Вам использовать определения записей в оболочке erl. Поместить Ваши определений в records.hrl файл и включить его в Ваших модулях является лучшим стилем. Я поступил так для краткости.
Теперь проверим. first_run () создает схему Mnesia, поэтому важно вызвать его первым. Другой потенциальный глюк с mnesia — то, что (по умолчанию) к базе данных может получить доступ только узел, который создал ее, поэтому задайте оболочке erl имя.
Мы будем использовать целочисленные Id, чтобы различать пользователей – но для этого теста я использовал атомы (rj, alice, bob) и предполагал, что alice и bob являются друзьями rj. Замечательно, что mnesia (и ets/dets) не заботится, какие типы Вы использовали – любой терм Erlang допустим. Это означает, что обновление для поддержки различных типов не вызовет труда.
Вместо того, чтобы адресовать сообщения определенным пользователям, то есть router:send(123, «Hello user 123»), мы «пометим» сообщения – человек, который сгенерировал сообщение – и есть маршрутизатор, который передает сообщение каждому подписанному пользователю. Другими словами API будет работать так: router:send(123, «Hello everyone subscribed to user 123»).
Небольшой тест – я использовал атомы вместо id.
Видно, что alice может получать сообщения, когда кто-либо, на кого она подписана посылает сообщение, даже при том, что сообщение не было отправлено непосредственно alice. Вывод показывает, что маршрутизатор идентифицировал возможные цели как [alice, bob], но передал сообщение одному человеку, alice, потому что bob не был авторизован.
Мы можем сгенерировать много отношения наугад, но это не особенно реалистично. У социальных сетей обычно есть несколько суперпопулярных пользователей (у некоторых пользователей Twitter есть более чем 100 000 последователей), и много людей только с горсткой друзей.
Чтобы cгенерировать набор данных, я использовал модуль Python от превосходной библиотеки igraph:
Этот маленький модуль читает fakefriends.txt файл и создает список подписок.
Теперь в оболочке subsmanager Вы можете читать из текстового файла и добавлять подписки:
Отметьте дополнительные параметры – они помогут избежать сообщений «** WARNING ** Mnesia is overloaded». Документация Mnesia содержит много других настроек, достойных внимания.
Создание миллиона tcp соединений от одного узла нетривиально. У меня есть чувство, что люди, которые делают это регулярно, на выделенных маленьких кластерах для моделирования большого количества соединений, вероятно используют реальный инструмент вроде Tsung. Даже с настройкой из Части 1, мы все еще упираемся в жесткий предел портов. При создании tcp соединения, клиентский порт выделяется из диапазона в /proc/sys/net/ipv4/ip_local_port_range. Не имеет значения, если Вы задаете его вручную, или используете автоматический порт. В части 1 мы устанавливаем диапазон в «1024 65535», т.е. у нас 65535-1024 = 64511 непривилегированных доступных порта. Некоторые из них будут использоваться другими процессами, но мы никогда не перевалим за 64511 клиента, потому что мы исчерпаем порты.
Локальный диапазон портов связан с IP, так, если мы будем делать исходящие соединения из различных локальных IP-адресов, то мы будем в состоянии открыть больше 64511 исходящих соединений.
Так что давайте создадим 17 новых IP-адресов, чтобы сделать 62 000 соединений от каждого – это предоставит нам в общей сложности 1 054 000 соединений:
Если Вы проверите ifconfig теперь, Вы должны видеть свои виртуальные интерфейсы: eth0:1, eth0:2 … eth0:17, каждый с различным IP-адресом.
Все, что остается теперь, это изменить floodtest из Части 1, чтобы выбрать локальный IP. К сожалению, erlang http клиент не позволяет Вам определять исходный IP.
В этой точке я рассматривал другую возможность: использовать 17 пар IP – один на сервере и один на клиенте – каждая пара в их собственной изолированной /30 подсети. Я думаю, что, если бы я тогда заставил клиент соединиться с каким-либо IP сервера, он вынудил бы локальный адрес быть вторым из пары, потому что только один из локальных IP фактически будет в состоянии достигнуть IP сервера по данной подсети. В теории это означало бы объявлять, что локальный исходный IP на клиентской машине не будет необходим (хотя диапазон IP адресов сервера должен был бы быть определен). Я не знаю, сработало ли бы это или нет – это звучало вероятным в то время. В конце, я решил, что это было бы слишком извращенным.
gen_tcp позволяет Вам определять исходный адрес, таким образом, я закончил тем, что использовал сырой клиент:
Сперва я соединился с mochiweb приложением из Части 1 – оно просто отправляет одно сообщение каждому клиенту каждые 10 секунд.
Оказывается, открытие большого количества соединений с помощью gen_tcp убивает много памяти. Я предполагаю, что потребовалось бы ~36GB, чтобы заставить это работать. Я не интересовался попыткой оптимизировать мой erlang http клиент, и единственной машиной с более 32Гб памяти, которую я мог достать, была одна из наших баз данных, и я не смог найти хорошее оправдание, чтобы выключить Last.fm, пока я балуюсь :)
В этот момент я решил вспомнить испытанный libevent, который, имеет HTTP API. У более новых версий также есть функция evhttp_connection_set_local_address в http API.
Вот http клиент на C, использующий libevent:
Большинство параметров заданы жестко как #define, таким образом, Вы можете отредактировать его и перекомпилировать:
Чтобы открыть больше 64 500 соединений, Вы должны определить локальный адрес и локальный порт самостоятельно, и управлять ими соответственно.
К сожалению, у libevent HTTP API нет опции, чтобы определить локальный порт. Я исправил libevent, чтобы добавить такую функцию:
Это было удивительно приятным опытом: libevent кажется правильно написанным, и документация довольно приличная.
С этим измененным libevent я смог добавить следующее в вышеупомянутом коде:
Теперь многократные соединения от различных адресов смогли использовать тот же самый локальный номер порта, определенный для локального адреса. Я перекомпилировал клиент, и позволил ему работать некоторое время, чтобы удостовериться, что он пройдет барьер.
Netstat подтверждает это:
Это показывает, сколько портов открыто в различных состояниях. Нам наконец удалось открыть больше 2^16 соединения.
Теперь у нас есть инструмент, способный к открытию миллиона http соединений от единственного компьютера. Похоже, это использует приблизительно 2 Кб для каждого подключения, плюс то, что занимает ядро. Пора провести тест нашего mochiweb сервера.
Для этого теста я использовал 4 различных сервера. Главное различие между данным тестом и предыдущими – это модифицированный клиент, написанный на Си.
Server 1 – Quad-core 2GHz CPU, 16GB of RAM
• Запуск subsmanager
• Загрузка данных
• Запуск маршрутизатора
Server 2 – Dual Quad-core 2.8GHz CPU, 32GB of RAM
• Запуск Mochiweb приложения
Server 3 – Quad-core 2GHz CPU, 16GB of RAM
• Создание 17 выртиуальных IP адресов
• Установка libevent
• Запуск клиента: ./httpclient (100 подключений в секунду)
Server 4 – Dual-core 2GHz, 2GB RAM
• Запуск msggen для отправки кучи сообщений
Использование памяти во время открытия соединений и в течении некоторого времени:

HttpClient имеет встроенную задержку 10мс между соединениями, поэтому потребовалось почти 3 часа, чтобы открыть миллион соединений. Потребовалосб окло 25Гб памяти. Вот как выглядит мой сервер глазами Ganglia:
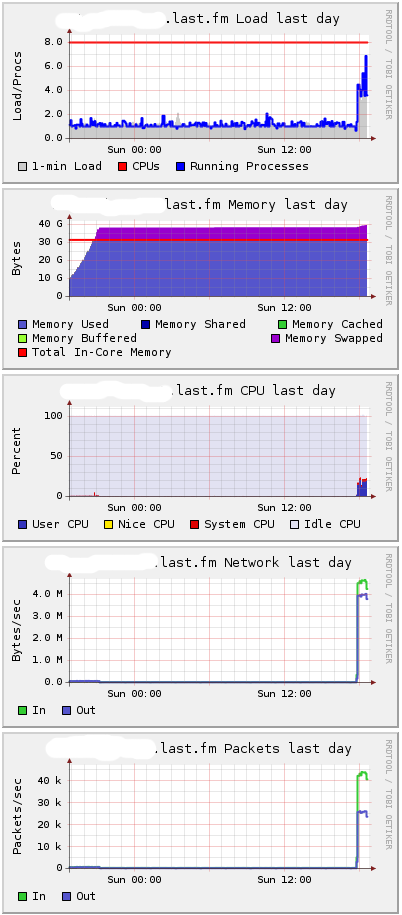
Вы можете видеть, что требуется около 38GB, и дальше начинается подкачка. Я подозреваю, что разница в основном в потреблении ядра.
Сообщения были сгенерированы, используя 1000 процессов, при среднем времени между сообщениями около 60мс на процесс, давая около 16666 сообщений в секунду:
Server 4 в Ganglia:
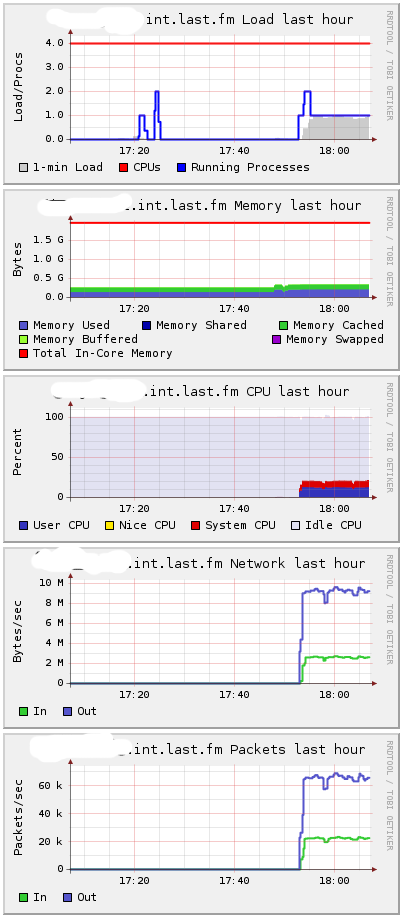
Около 10 MB в секунду – 16,666 сообщений.
Когда я начал посылать сообщения, загрузка на первом сервере осталась низкой. Потребление CPU на втором сервере возрастало:
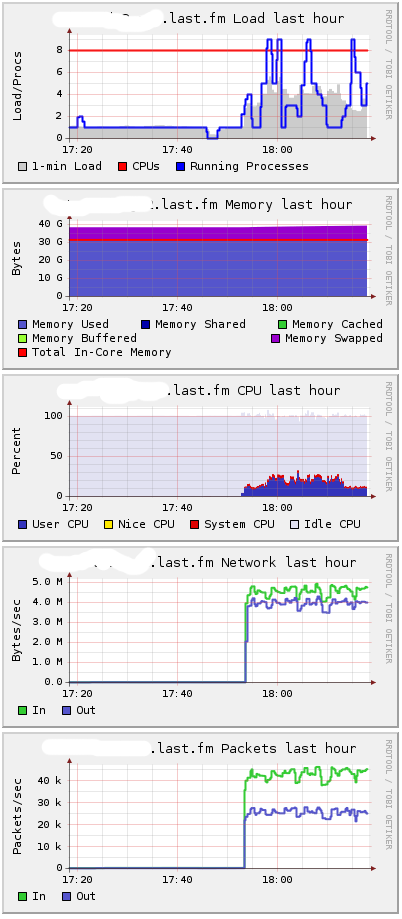
Естественно, что т.к. процессы выходят из hibernate() для обработки сообщений, использование памяти увеличивается незначительно. Наличие всех открытых подключений без каких-либо сообщений являестя оптимальным в использования памяти. Неудивительно, что какие-либо действия требуют больше памяти.
Так где же течет память? Mochiweb требует 40 Гб оперативной памяти, чтобы держать открытыми 1 000 000 активных соединений. Под нагрузкой, до 30GB из памяти будет использоваться mochiweb, а остальные 10 Гб ядром. Другими словами, необходимо около 40Кб на соединение.
В ходе различных испытаний с большим количеством соединений, я закончил тем, что сделал некоторые дополнительные изменения в sysctl.conf. Я пришел к этому с помощью проб и ошибок, и я не знаю, какие значения менять. Моя политика была в ожидании ошибки, чтобы проверить /var/log/kern.log и посмотреть, что мне скажет таинственная ошибка. Вот настройки:
Я хотел бы узнать больше о настройках TCP Linux, чтобы сделать более обоснованные объяснения. Почти наверняка, эти настройки не является оптимальными, но по крайней мере, этого было достаточно, чтобы достичь 1 000 000 соединений.
После вмешательства в HTTP API для libevent, казалось совершенно разумным провести сранение вышеописанного теста с libevent HTTPd, написанным на Cи.
Я бы хотел как можно больше кода оставить на erlang, так что давайте делать минимум на Cи — только обработку HTTP соединений.
Libevent имеет асинхронный HTTP API, что делает реализацию HTTP сервера тривиальной. Я также искал повод, чтобы попробовать интерфейс Си для Erlang. Это сервер HTTP с использованием libevent, который идентифицирует пользователей с помощью целого Id (как наше mochiweb приложение), а также действует как Erlang Си-узел.
Он подключается к назначенному Erlang узлу, прослушивает сообщения типа {123, <<«Hello user 123»>>}, отправляет “Hello user 123″ для пользователя 123, если он подключен. Сообщения для пользователей, которые не связаны отбрасываются, как и раньше.
Максимальное количество пользователей задано с помощью #define, прослушивается порт 8000 и ожидаются пользователи. Также жестко задано имя Erlang узела cookie.
Запустите узел, к которому будет подключатсясервер:
Запустим Си-узел:
Проверьте, что виден узел:
Откройте в своем браузере localhost:8000/test/123. Вы должны увидеть приветственное сообщение.
Далее отправьте сообщение Си-узлу:
Обратите внимание, что мы не используем Pid — мы используем {procname, node}. Мы используем «any», как название процесса, который игнорируется Cи-узлом.
Теперь вы в состоянии доставить сообщения через Erlang, но все соединения управляются libevent программой на Си, которая действует как узел Erlang.
После удаления отладочного вывода, я подключил 1 000 000 клиентов к httpdcnode серверу, используя тот же самый клиент, как и выше. Машина показала, в общей сложности чуть менее 10 Гб используемой памяти.
Память сервера была стабильно около 2GB:

Порядка 2Кб на каждое подключение.
Состояние памяти:
Так kernel/ TCP стек берет дополнительные 8Кб за соединение, которые кажутся высокими, но у меня нет ничего для для сравнения.
Этот libevent-cnode сервер требует определенной дополнительной работы над собой. Не разумно обрабатывать несколько соединений от одного пользователя, и все еще присутствуют “race conditions”, если вы отключитесь тогда, когда сообщение было только отправлено.
Несмотря на это, мы использовали Erlang для всех интересных вещей, и Cи + libevent использовались для низкоуровневых операций. Программа на Cи может быть запущен в качестве драйвера или C-узла, а интерфейсы Erlang могут дать вам достойный API. У меня все еще осталось желание поэкспериментировать с этим.
У меня есть достаточно данных сейчас судить, какое оборудование будет необходимо, если мы развернем большую систему масштаба Last.fm. Даже в худшем случае 40Кб за соединение является хорошим результатом — память довольно дешевая на данный момент, и 40GB для поддержки миллионов пользователей не является проблемой. 10GB еще лучше.
Это статья покрывает следующее:
• Использование базы данных Mnesia;
• Генерация правдоподобного набора данных вида «friends» для миллиона пользователей;
• Настройка Mnesia и ввод наших данных;
• Открытие миллиона соединений с одной машины;
• Сравнительный тест с 1 миллионом пользователей;
• Libevent + Си для обработки соединений;
• Финальные выводы.
Одна из частей этого теста заключается в возможности открыть 1 000 000 соединений с единственной тестовой машины. Написать сервер, который в состоянии принять 1 000 000 соединений легче, чем фактическое создавание 1 000 000 соединений. Таким образом, изрядная часть этой статьи о методах, используемых, чтобы открыть 1 000 000 соединений с единственной машины.
Запуск нашего Pubsub.
В части 2 мы использовали маршрутизатор, чтобы отправить сообщения определенным пользователям. Это прекрасно для chat/IM системы, но есть более полезные вещи, которые мы могли бы сделать вместо этого. Прежде, чем мы начнем крупномасштабный тест, давайте добавим еще один модуль – база данных подписчика. Мы создадим хранилище с данными о Ваших друзьях, таким образом, оно может предоставить Вам все события, сгенерированные людьми из Вашего списка друзей.
Мое намерение состоит в том, чтобы использовать это для Last.fm. Таким образом, я могу получить канал в реальном времени песен, которые мои друзья в настоящий момент слушают. Это может одинаково примениться и к другим событиям, сгенерированным в социальных сетях. Фото, загруженное в Flickr, элементы новостного канала Facebook, Twitter и т.д. У FriendFeed даже есть API в реальном времени в бете, таким образом, это определенно актуально.
Реализация менеджера подписки
Мы реализуем простой менеджер по подписке, но мы будем подписывать людей на всех их друзей автоматически.
API:
• add_subscriptions([{Subscriber, Subscribee},...])
• remove_subscriptions([{Subscriber, Subscribee},...])
• get_subscribers(User)
-module(subsmanager).
-behaviour(gen_server).
-include("/usr/local/lib/erlang/lib/stdlib-1.15.4/include/qlc.hrl").
-export([init/1, handle_call/3, handle_cast/2, handle_info/2, terminate/2, code_change/3]).
-export([add_subscriptions/1,
remove_subscriptions/1,
get_subscribers/1,
first_run/0,
stop/0,
start_link/0]).
-record(subscription, {subscriber, subscribee}).
-record(state, {}). % state is all in mnesia
-define(SERVER, global:whereis_name(?MODULE)).
start_link() ->
gen_server:start_link({global, ?MODULE}, ?MODULE, [], []).
stop() ->
gen_server:call(?SERVER, {stop}).
add_subscriptions(SubsList) ->
gen_server:call(?SERVER, {add_subscriptions, SubsList}, infinity).
remove_subscriptions(SubsList) ->
gen_server:call(?SERVER, {remove_subscriptions, SubsList}, infinity).
get_subscribers(User) ->
gen_server:call(?SERVER, {get_subscribers, User}).
%%
init([]) ->
ok = mnesia:start(),
io:format("Waiting on mnesia tables..\n",[]),
mnesia:wait_for_tables([subscription], 30000),
Info = mnesia:table_info(subscription, all),
io:format("OK. Subscription table info: \n~w\n\n",[Info]),
{ok, #state{}}.
handle_call({stop}, _From, State) ->
{stop, stop, State};
handle_call({add_subscriptions, SubsList}, _From, State) ->
% Transactionally is slower:
% F = fun() ->
% [ ok = mnesia:write(S) || S <- SubsList ]
% end,
% mnesia:transaction(F),
[ mnesia:dirty_write(S) || S <- SubsList ],
{reply, ok, State};
handle_call({remove_subscriptions, SubsList}, _From, State) ->
F = fun() ->
[ ok = mnesia:delete_object(S) || S <- SubsList ]
end,
mnesia:transaction(F),
{reply, ok, State};
handle_call({get_subscribers, User}, From, State) ->
F = fun() ->
Subs = mnesia:dirty_match_object(#subscription{subscriber=‘_’, subscribee=User}),
Users = [Dude || #subscription{subscriber=Dude, subscribee=_} <- Subs],
gen_server:reply(From, Users)
end,
spawn(F),
{noreply, State}.
handle_cast(_Msg, State) -> {noreply, State}.
handle_info(_Msg, State) -> {noreply, State}.
terminate(_Reason, _State) ->
mnesia:stop(),
ok.
code_change(_OldVersion, State, _Extra) ->
io:format("Reloading code for ?MODULE\n",[]),
{ok, State}.
%%
first_run() ->
mnesia:create_schema([node()]),
ok = mnesia:start(),
Ret = mnesia:create_table(subscription,
[
{disc_copies, [node()]},
{attributes, record_info(fields, subscription)},
{index, [subscribee]}, %index subscribee too
{type, bag}
]),
Ret.
Примечательно:
• я включал qlc.hrl, необходимый для Mnesia, используя абсолютный путь. Это не хорошо, но по-другому у меня не получилось.
• get_subscribers порождает другой процесс и делегирует создание ответа этотому же процессу, используя gen_server:reply. Это означает, что цикл gen_server не будет блокироваться на этом вызове, если мы будем часто вызывать lookup.
• rr(”subsmanager.erl”). Пример ниже позволяет Вам использовать определения записей в оболочке erl. Поместить Ваши определений в records.hrl файл и включить его в Ваших модулях является лучшим стилем. Я поступил так для краткости.
Теперь проверим. first_run () создает схему Mnesia, поэтому важно вызвать его первым. Другой потенциальный глюк с mnesia — то, что (по умолчанию) к базе данных может получить доступ только узел, который создал ее, поэтому задайте оболочке erl имя.
$ mkdir /var/mnesia
$ erl -boot start_sasl -mnesia dir '"/var/mnesia_data"' -sname subsman
(subsman@localhost)1> c(subsmanager).
{ok,subsmanager}
(subsman@localhost)2> subsmanager:first_run().
...
{atomic,ok}
(subsman@localhost)3> subsmanager:start_link().
Waiting on mnesia tables..
OK. Subscription table info:
[{access_mode,read_write},{active_replicas,[subsman@localhost]},{arity,3},{attributes,[subscriber,subscribee]},{checkpoints,[]},{commit_work,[{index,bag,[{3,{ram,57378}}]}]},{cookie,{{1224,800064,900003},subsman@localhost}},{cstruct,{cstruct,subscription,bag,[],[subsman@localhost],[],0,read_write,[3],[],false,subscription,[subscriber,subscribee],[],[],{{1224,863164,904753},subsman@localhost},{{2,0},[]}}},{disc_copies,[subsman@localhost]},{disc_only_copies,[]},{frag_properties,[]},{index,[3]},{load_by_force,false},{load_node,subsman@localhost},{load_order,0},{load_reason,{dumper,create_table}},{local_content,false},{master_nodes,[]},{memory,288},{ram_copies,[]},{record_name,subscription},{record_validation,{subscription,3,bag}},{type,bag},{size,0},{snmp,[]},{storage_type,disc_copies},{subscribers,[]},{user_properties,[]},{version,{{2,0},[]}},{where_to_commit,[{subsman@localhost,disc_copies}]},{where_to_read,subsman@localhost},{where_to_write,[subsman@localhost]},{wild_pattern,{subscription,'_','_'}},{{index,3},57378}]
{ok,<0.105.0>}
(subsman@localhost)4> rr("subsmanager.erl").
[state,subscription]
(subsman@localhost)5> subsmanager:add_subscriptions([ #subscription{subscriber=alice, subscribee=rj} ]).
ok
(subsman@localhost)6> subsmanager:add_subscriptions([ #subscription{subscriber=bob, subscribee=rj} ]).
ok
(subsman@localhost)7> subsmanager:get_subscribers(rj).
[bob,alice]
(subsman@localhost)8> subsmanager:remove_subscriptions([ #subscription{subscriber=bob, subscribee=rj} ]).
ok
(subsman@localhost)8> subsmanager:get_subscribers(rj).
[alice]
(subsman@localhost)10> subsmanager:get_subscribers(charlie).
[]
Мы будем использовать целочисленные Id, чтобы различать пользователей – но для этого теста я использовал атомы (rj, alice, bob) и предполагал, что alice и bob являются друзьями rj. Замечательно, что mnesia (и ets/dets) не заботится, какие типы Вы использовали – любой терм Erlang допустим. Это означает, что обновление для поддержки различных типов не вызовет труда.
Изменение маршрутизатора
Вместо того, чтобы адресовать сообщения определенным пользователям, то есть router:send(123, «Hello user 123»), мы «пометим» сообщения – человек, который сгенерировал сообщение – и есть маршрутизатор, который передает сообщение каждому подписанному пользователю. Другими словами API будет работать так: router:send(123, «Hello everyone subscribed to user 123»).
-module(router).
-behaviour(gen_server).
-export([start_link/0]).
-export([init/1, handle_call/3, handle_cast/2, handle_info/2,
terminate/2, code_change/3]).
-export([send/2, login/2, logout/1]).
-define(SERVER, global:whereis_name(?MODULE)).
% will hold bidirectional mapping between id <–> pid
-record(state, {pid2id, id2pid}).
start_link() ->
gen_server:start_link({global, ?MODULE}, ?MODULE, [], []).
% sends Msg to anyone subscribed to Id
send(Id, Msg) ->
gen_server:call(?SERVER, {send, Id, Msg}).
login(Id, Pid) when is_pid(Pid) ->
gen_server:call(?SERVER, {login, Id, Pid}).
logout(Pid) when is_pid(Pid) ->
gen_server:call(?SERVER, {logout, Pid}).
%%
init([]) ->
% set this so we can catch death of logged in pids:
process_flag(trap_exit, true),
% use ets for routing tables
{ok, #state{
pid2id = ets:new(?MODULE, [bag]),
id2pid = ets:new(?MODULE, [bag])
}
}.
handle_call({login, Id, Pid}, _From, State) when is_pid(Pid) ->
ets:insert(State#state.pid2id, {Pid, Id}),
ets:insert(State#state.id2pid, {Id, Pid}),
link(Pid), % tell us if they exit, so we can log them out
%io:format("~w logged in as ~w\n",[Pid, Id]),
{reply, ok, State};
handle_call({logout, Pid}, _From, State) when is_pid(Pid) ->
unlink(Pid),
PidRows = ets:lookup(State#state.pid2id, Pid),
case PidRows of
[] ->
ok;
_ ->
IdRows = [ {I,P} || {P,I} <- PidRows ], % invert tuples
ets:delete(State#state.pid2id, Pid), % delete all pid->id entries
[ ets:delete_object(State#state.id2pid, Obj) || Obj <- IdRows ] % and all id->pid
end,
%io:format("pid ~w logged out\n",[Pid]),
{reply, ok, State};
handle_call({send, Id, Msg}, From, State) ->
F = fun() ->
% get users who are subscribed to Id:
Users = subsmanager:get_subscribers(Id),
io:format("Subscribers of ~w = ~w\n",[Id, Users]),
% get pids of anyone logged in from Users list:
Pids0 = lists:map(
fun(U)->
[ P || { _I, P } <- ets:lookup(State#state.id2pid, U) ]
end,
[ Id | Users ] % we are always subscribed to ourselves
),
Pids = lists:flatten(Pids0),
io:format("Pids: ~w\n", [Pids]),
% send Msg to them all
M = {router_msg, Msg},
[ Pid ! M || Pid <- Pids ],
% respond with how many users saw the message
gen_server:reply(From, {ok, length(Pids)})
end,
spawn(F),
{noreply, State}.
% handle death and cleanup of logged in processes
handle_info(Info, State) ->
case Info of
{‘EXIT’, Pid, _Why} ->
handle_call({logout, Pid}, blah, State);
Wtf ->
io:format("Caught unhandled message: ~w\n", [Wtf])
end,
{noreply, State}.
handle_cast(_Msg, State) ->
{noreply, State}.
terminate(_Reason, _State) ->
ok.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
Небольшой тест – я использовал атомы вместо id.
(subsman@localhost)1> c(subsmanager), c(router), rr("subsmanager.erl").
(subsman@localhost)2> subsmanager:start_link().
(subsman@localhost)3> router:start_link().
(subsman@localhost)4> Subs = [#subscription{subscriber=alice, subscribee=rj}, #subscription{subscriber=bob, subscribee=rj}].
[#subscription{subscriber = alice,subscribee = rj},
#subscription{subscriber = bob,subscribee = rj}]
(subsman@localhost)5> subsmanager:add_subscriptions(Subs).
ok
(subsman@localhost)6> router:send(rj, "RJ did something").
Subscribers of rj = [bob,alice]
Pids: []
{ok,0}
(subsman@localhost)7> router:login(alice, self()).
ok
(subsman@localhost)8> router:send(rj, "RJ did something").
Subscribers of rj = [bob,alice]
Pids: [<0.46.0>]
{ok,1}
(subsman@localhost)9> receive {router_msg, M} -> io:format("~s\n",[M]) end.
RJ did something
ok
Видно, что alice может получать сообщения, когда кто-либо, на кого она подписана посылает сообщение, даже при том, что сообщение не было отправлено непосредственно alice. Вывод показывает, что маршрутизатор идентифицировал возможные цели как [alice, bob], но передал сообщение одному человеку, alice, потому что bob не был авторизован.
Генерирование простого набор данных
Мы можем сгенерировать много отношения наугад, но это не особенно реалистично. У социальных сетей обычно есть несколько суперпопулярных пользователей (у некоторых пользователей Twitter есть более чем 100 000 последователей), и много людей только с горсткой друзей.
Чтобы cгенерировать набор данных, я использовал модуль Python от превосходной библиотеки igraph:
import igraph
g = igraph.Graph.Barabasi(1000000, 15, directed=False)
print "Edges: " + str(g.ecount()) + " Verticies: " + str(g.vcount())
g.write_edgelist("fakefriends.txt")
Загрузка данных в Mnesia
Этот маленький модуль читает fakefriends.txt файл и создает список подписок.
-module(readfriends).
-export([load/1]).
-record(subscription, {subscriber, subscribee}).
load(Filename) ->
for_each_line_in_file(Filename,
fun(Line, Acc) ->
[As, Bs] = string:tokens(string:strip(Line, right, $\n), " "),
{A, _} = string:to_integer(As),
{B, _} = string:to_integer(Bs),
[ #subscription{subscriber=A, subscribee=B} | Acc ]
end, [read], []).
% via: http://www.trapexit.org/Reading_Lines_from_a_File
for_each_line_in_file(Name, Proc, Mode, Accum0) ->
{ok, Device} = file:open(Name, Mode),
for_each_line(Device, Proc, Accum0).
for_each_line(Device, Proc, Accum) ->
case io:get_line(Device, "") of
eof -> file:close(Device), Accum;
Line -> NewAccum = Proc(Line, Accum),
for_each_line(Device, Proc, NewAccum)
end.
Теперь в оболочке subsmanager Вы можете читать из текстового файла и добавлять подписки:
$ erl -name router@minifeeds4.gs2 +K true +A 128 -setcookie secretcookie -mnesia dump_log_write_threshold 50000 -mnesia dc_dump_limit 40
erl> c(readfriends), c(subsmanager).
erl> subsmanager:first_run().
erl> subsmanager:start_link().
erl> subsmanager:add_subscriptions( readfriends:load("fakefriends.txt") ).
Отметьте дополнительные параметры – они помогут избежать сообщений «** WARNING ** Mnesia is overloaded». Документация Mnesia содержит много других настроек, достойных внимания.
1 000 000
Создание миллиона tcp соединений от одного узла нетривиально. У меня есть чувство, что люди, которые делают это регулярно, на выделенных маленьких кластерах для моделирования большого количества соединений, вероятно используют реальный инструмент вроде Tsung. Даже с настройкой из Части 1, мы все еще упираемся в жесткий предел портов. При создании tcp соединения, клиентский порт выделяется из диапазона в /proc/sys/net/ipv4/ip_local_port_range. Не имеет значения, если Вы задаете его вручную, или используете автоматический порт. В части 1 мы устанавливаем диапазон в «1024 65535», т.е. у нас 65535-1024 = 64511 непривилегированных доступных порта. Некоторые из них будут использоваться другими процессами, но мы никогда не перевалим за 64511 клиента, потому что мы исчерпаем порты.
Локальный диапазон портов связан с IP, так, если мы будем делать исходящие соединения из различных локальных IP-адресов, то мы будем в состоянии открыть больше 64511 исходящих соединений.
Так что давайте создадим 17 новых IP-адресов, чтобы сделать 62 000 соединений от каждого – это предоставит нам в общей сложности 1 054 000 соединений:
$ for i in `seq 1 17`; do echo sudo ifconfig eth0:$i 10.0.0.$i up ; done
Если Вы проверите ifconfig теперь, Вы должны видеть свои виртуальные интерфейсы: eth0:1, eth0:2 … eth0:17, каждый с различным IP-адресом.
Все, что остается теперь, это изменить floodtest из Части 1, чтобы выбрать локальный IP. К сожалению, erlang http клиент не позволяет Вам определять исходный IP.
В этой точке я рассматривал другую возможность: использовать 17 пар IP – один на сервере и один на клиенте – каждая пара в их собственной изолированной /30 подсети. Я думаю, что, если бы я тогда заставил клиент соединиться с каким-либо IP сервера, он вынудил бы локальный адрес быть вторым из пары, потому что только один из локальных IP фактически будет в состоянии достигнуть IP сервера по данной подсети. В теории это означало бы объявлять, что локальный исходный IP на клиентской машине не будет необходим (хотя диапазон IP адресов сервера должен был бы быть определен). Я не знаю, сработало ли бы это или нет – это звучало вероятным в то время. В конце, я решил, что это было бы слишком извращенным.
gen_tcp позволяет Вам определять исходный адрес, таким образом, я закончил тем, что использовал сырой клиент:
-module(floodtest2).
-compile(export_all).
-define(SERVERADDR, "10.1.2.3"). % where mochiweb is running
-define(SERVERPORT, 8000).
% Generate the config in bash like so (chose some available address space):
% EACH=62000; for i in `seq 1 17`; do echo "{{10,0,0,$i}, $((($i-1)*$EACH+1)), $(($i*$EACH))}, "; done
run(Interval) ->
Config = [
{{10,0,0,1}, 1, 62000},
{{10,0,0,2}, 62001, 124000},
{{10,0,0,3}, 124001, 186000},
{{10,0,0,4}, 186001, 248000},
{{10,0,0,5}, 248001, 310000},
{{10,0,0,6}, 310001, 372000},
{{10,0,0,7}, 372001, 434000},
{{10,0,0,8}, 434001, 496000},
{{10,0,0,9}, 496001, 558000},
{{10,0,0,10}, 558001, 620000},
{{10,0,0,11}, 620001, 682000},
{{10,0,0,12}, 682001, 744000},
{{10,0,0,13}, 744001, 806000},
{{10,0,0,14}, 806001, 868000},
{{10,0,0,15}, 868001, 930000},
{{10,0,0,16}, 930001, 992000},
{{10,0,0,17}, 992001, 1054000}],
start(Config, Interval).
start(Config, Interval) ->
Monitor = monitor(),
AdjustedInterval = Interval / length(Config),
[ spawn(fun start/5, [Lower, Upper, Ip, AdjustedInterval, Monitor])
|| {Ip, Lower, Upper} <- Config ],
ok.
start(LowerID, UpperID, _, _, _) when LowerID == UpperID -> done;
start(LowerID, UpperID, LocalIP, Interval, Monitor) ->
spawn(fun connect/5, [?SERVERADDR, ?SERVERPORT, LocalIP, "/test/"++LowerID, Monitor]),
receive after Interval -> start(LowerID + 1, UpperID, LocalIP, Interval, Monitor) end.
connect(ServerAddr, ServerPort, ClientIP, Path, Monitor) ->
Opts = [binary, {packet, 0}, {ip, ClientIP}, {reuseaddr, true}, {active, false}],
{ok, Sock} = gen_tcp:connect(ServerAddr, ServerPort, Opts),
Monitor ! open,
ReqL = io_lib:format("GET ~s\r\nHost: ~s\r\n\r\n", [Path, ServerAddr]),
Req = list_to_binary(ReqL),
ok = gen_tcp:send(Sock, [Req]),
do_recv(Sock, Monitor),
(catch gen_tcp:close(Sock)),
ok.
do_recv(Sock, Monitor)->
case gen_tcp:recv(Sock, 0) of
{ok, B} ->
Monitor ! {bytes, size(B)},
io:format("Recvd ~s\n", [ binary_to_list(B)]),
io:format("Recvd ~w bytes\n", [size(B)]),
do_recv(Sock, Monitor);
{error, closed} ->
Monitor ! closed,
closed;
Other ->
Monitor ! closed,
io:format("Other:~w\n",[Other])
end.
% Monitor process receives stats and reports how much data we received etc:
monitor() ->
Pid = spawn(?MODULE, monitor0, [{0,0,0,0}]),
timer:send_interval(10000, Pid, report),
Pid.
monitor0({Open, Closed, Chunks, Bytes}=S) ->
receive
report -> io:format("{Open, Closed, Chunks, Bytes} = ~w\n",[S]);
open -> monitor0({Open + 1, Closed, Chunks, Bytes});
closed -> monitor0({Open, Closed + 1, Chunks, Bytes});
chunk -> monitor0({Open, Closed, Chunks + 1, Bytes});
{bytes, B} -> monitor0({Open, Closed, Chunks, Bytes + B})
end.
Сперва я соединился с mochiweb приложением из Части 1 – оно просто отправляет одно сообщение каждому клиенту каждые 10 секунд.
erl> c(floodtest2), floodtest2:run(20).
Оно быстро съело всю мою память
Оказывается, открытие большого количества соединений с помощью gen_tcp убивает много памяти. Я предполагаю, что потребовалось бы ~36GB, чтобы заставить это работать. Я не интересовался попыткой оптимизировать мой erlang http клиент, и единственной машиной с более 32Гб памяти, которую я мог достать, была одна из наших баз данных, и я не смог найти хорошее оправдание, чтобы выключить Last.fm, пока я балуюсь :)
В этот момент я решил вспомнить испытанный libevent, который, имеет HTTP API. У более новых версий также есть функция evhttp_connection_set_local_address в http API.
Вот http клиент на C, использующий libevent:
#include <sys/types.h>
#include <sys/time.h>
#include <sys/queue.h>
#include <stdlib.h>
#include <err.h>
#include <event.h>
#include <evhttp.h>
#include <unistd.h>
#include <stdio.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <time.h>
#include <pthread.h>
#define BUFSIZE 4096
#define NUMCONNS 62000
#define SERVERADDR "10.103.1.43"
#define SERVERPORT 8000
#define SLEEP_MS 10
char buf[BUFSIZE];
int bytes_recvd = 0;
int chunks_recvd = 0;
int closed = 0;
int connected = 0;
// called per chunk received
void chunkcb(struct evhttp_request * req, void * arg)
{
int s = evbuffer_remove( req->input_buffer, &buf, BUFSIZE );
//printf("Read %d bytes: %s\n", s, &buf);
bytes_recvd += s;
chunks_recvd++;
if(connected >= NUMCONNS && chunks_recvd%10000==0)
printf(">Chunks: %d\tBytes: %d\tClosed: %d\n", chunks_recvd, bytes_recvd, closed);
}
// gets called when request completes
void reqcb(struct evhttp_request * req, void * arg)
{
closed++;
}
int main(int argc, char **argv)
{
event_init();
struct evhttp *evhttp_connection;
struct evhttp_request *evhttp_request;
char addr[16];
char path[32]; // eg: "/test/123"
int i,octet;
for(octet=1; octet<=17; octet++){
sprintf(&addr, "10.224.0.%d", octet);
for(i=1;i<=NUMCONNS;i++) {
evhttp_connection = evhttp_connection_new(SERVERADDR, SERVERPORT);
evhttp_connection_set_local_address(evhttp_connection, &addr);
evhttp_set_timeout(evhttp_connection, 864000); // 10 day timeout
evhttp_request = evhttp_request_new(reqcb, NULL);
evhttp_request->chunk_cb = chunkcb;
sprintf(&path, "/test/%d", ++connected);
if(i%100==0) printf("Req: %s\t->\t%s\n", addr, &path);
evhttp_make_request( evhttp_connection, evhttp_request, EVHTTP_REQ_GET, path );
evhttp_connection_set_timeout(evhttp_request->evcon, 864000);
event_loop( EVLOOP_NONBLOCK );
if( connected % 200 == 0 )
printf("\nChunks: %d\tBytes: %d\tClosed: %d\n", chunks_recvd, bytes_recvd, closed);
usleep(SLEEP_MS*1000);
}
}
event_dispatch();
return 0;
}
Большинство параметров заданы жестко как #define, таким образом, Вы можете отредактировать его и перекомпилировать:
$ gcc -o httpclient httpclient.c -levent
$ ./httpclient
Он все еще не в состоянии открыть больше 64 500 портов
Чтобы открыть больше 64 500 соединений, Вы должны определить локальный адрес и локальный порт самостоятельно, и управлять ими соответственно.
К сожалению, у libevent HTTP API нет опции, чтобы определить локальный порт. Я исправил libevent, чтобы добавить такую функцию:
void evhttp_connection_set_local_port(struct evhttp_connection *evcon, u_short port);.
Это было удивительно приятным опытом: libevent кажется правильно написанным, и документация довольно приличная.
С этим измененным libevent я смог добавить следующее в вышеупомянутом коде:
evhttp_connection_set_local_port(evhttp_connection, 1024+i);
Теперь многократные соединения от различных адресов смогли использовать тот же самый локальный номер порта, определенный для локального адреса. Я перекомпилировал клиент, и позволил ему работать некоторое время, чтобы удостовериться, что он пройдет барьер.
Netstat подтверждает это:
# netstat -n | awk '/^tcp/ {t[$NF]++}END{for(state in t){print state, t[state]}}'
TIME_WAIT 8
ESTABLISHED 118222
Это показывает, сколько портов открыто в различных состояниях. Нам наконец удалось открыть больше 2^16 соединения.
Теперь у нас есть инструмент, способный к открытию миллиона http соединений от единственного компьютера. Похоже, это использует приблизительно 2 Кб для каждого подключения, плюс то, что занимает ядро. Пора провести тест нашего mochiweb сервера.
C1024K
Для этого теста я использовал 4 различных сервера. Главное различие между данным тестом и предыдущими – это модифицированный клиент, написанный на Си.
Server 1 – Quad-core 2GHz CPU, 16GB of RAM
• Запуск subsmanager
• Загрузка данных
• Запуск маршрутизатора
Server 2 – Dual Quad-core 2.8GHz CPU, 32GB of RAM
• Запуск Mochiweb приложения
Server 3 – Quad-core 2GHz CPU, 16GB of RAM
• Создание 17 выртиуальных IP адресов
• Установка libevent
• Запуск клиента: ./httpclient (100 подключений в секунду)
Server 4 – Dual-core 2GHz, 2GB RAM
• Запуск msggen для отправки кучи сообщений
Использование памяти во время открытия соединений и в течении некоторого времени:
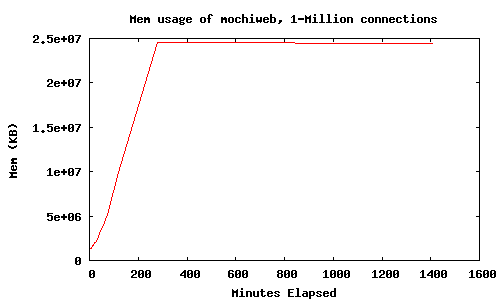
HttpClient имеет встроенную задержку 10мс между соединениями, поэтому потребовалось почти 3 часа, чтобы открыть миллион соединений. Потребовалосб окло 25Гб памяти. Вот как выглядит мой сервер глазами Ganglia:
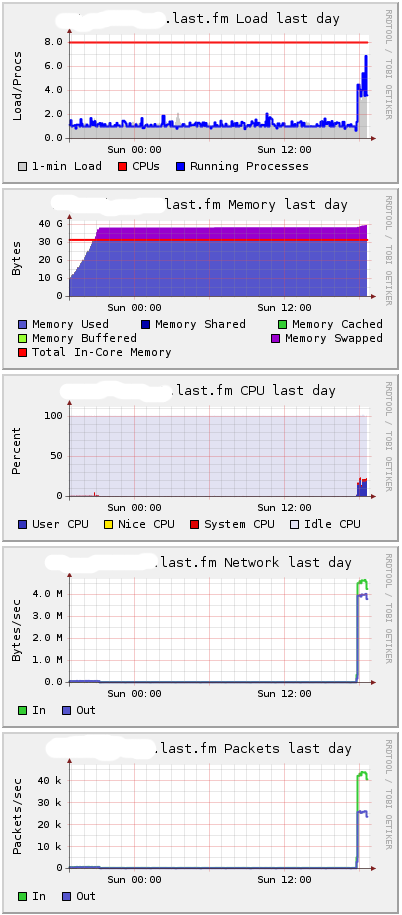
Вы можете видеть, что требуется около 38GB, и дальше начинается подкачка. Я подозреваю, что разница в основном в потреблении ядра.
Сообщения были сгенерированы, используя 1000 процессов, при среднем времени между сообщениями около 60мс на процесс, давая около 16666 сообщений в секунду:
erl> [ spawn( fun()->msggen:start(1000000, 10+random:uniform(100), 1000000) end) || I <- lists:seq(1,1000) ].
Server 4 в Ganglia:
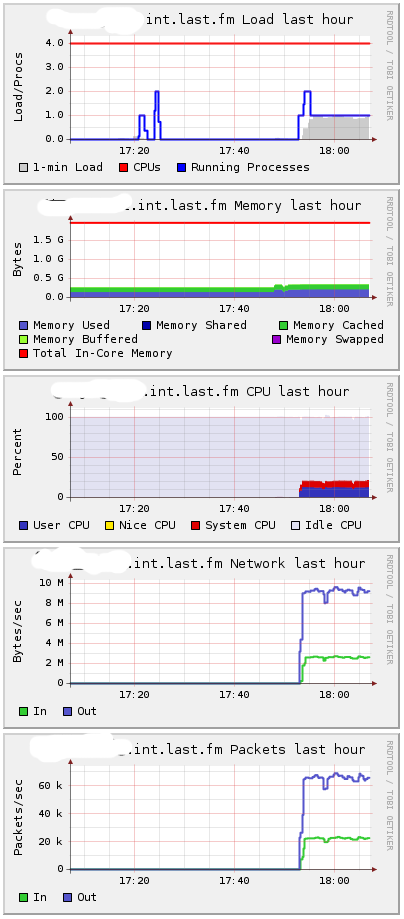
Около 10 MB в секунду – 16,666 сообщений.
Когда я начал посылать сообщения, загрузка на первом сервере осталась низкой. Потребление CPU на втором сервере возрастало:

Естественно, что т.к. процессы выходят из hibernate() для обработки сообщений, использование памяти увеличивается незначительно. Наличие всех открытых подключений без каких-либо сообщений являестя оптимальным в использования памяти. Неудивительно, что какие-либо действия требуют больше памяти.
Так где же течет память? Mochiweb требует 40 Гб оперативной памяти, чтобы держать открытыми 1 000 000 активных соединений. Под нагрузкой, до 30GB из памяти будет использоваться mochiweb, а остальные 10 Гб ядром. Другими словами, необходимо около 40Кб на соединение.
В ходе различных испытаний с большим количеством соединений, я закончил тем, что сделал некоторые дополнительные изменения в sysctl.conf. Я пришел к этому с помощью проб и ошибок, и я не знаю, какие значения менять. Моя политика была в ожидании ошибки, чтобы проверить /var/log/kern.log и посмотреть, что мне скажет таинственная ошибка. Вот настройки:
net.core.rmem_max = 33554432
net.core.wmem_max = 33554432
net.ipv4.tcp_rmem = 4096 16384 33554432
net.ipv4.tcp_wmem = 4096 16384 33554432
net.ipv4.tcp_mem = 786432 1048576 26777216
net.ipv4.tcp_max_tw_buckets = 360000
net.core.netdev_max_backlog = 2500
vm.min_free_kbytes = 65536
vm.swappiness = 0
net.ipv4.ip_local_port_range = 1024 65535
Я хотел бы узнать больше о настройках TCP Linux, чтобы сделать более обоснованные объяснения. Почти наверняка, эти настройки не является оптимальными, но по крайней мере, этого было достаточно, чтобы достичь 1 000 000 соединений.
Узел Erlang на Libevent
После вмешательства в HTTP API для libevent, казалось совершенно разумным провести сранение вышеописанного теста с libevent HTTPd, написанным на Cи.
Я бы хотел как можно больше кода оставить на erlang, так что давайте делать минимум на Cи — только обработку HTTP соединений.
Libevent имеет асинхронный HTTP API, что делает реализацию HTTP сервера тривиальной. Я также искал повод, чтобы попробовать интерфейс Си для Erlang. Это сервер HTTP с использованием libevent, который идентифицирует пользователей с помощью целого Id (как наше mochiweb приложение), а также действует как Erlang Си-узел.
Он подключается к назначенному Erlang узлу, прослушивает сообщения типа {123, <<«Hello user 123»>>}, отправляет “Hello user 123″ для пользователя 123, если он подключен. Сообщения для пользователей, которые не связаны отбрасываются, как и раньше.
#include <sys/types.h>
#include <sys/time.h>
#include <sys/queue.h>
#include <stdlib.h>
#include <err.h>
#include <event.h>
#include <evhttp.h>
#include <stdio.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include "erl_interface.h"
#include "ei.h"
#include <pthread.h>
#define BUFSIZE 1024
#define MAXUSERS (17*65536) // C1024K
// List of current http requests by uid:
struct evhttp_request * clients[MAXUSERS+1];
// Memory to store uids passed to the cleanup callback:
int slots[MAXUSERS+1];
// called when user disconnects
void cleanup(struct evhttp_connection *evcon, void *arg)
{
int *uidp = (int *) arg;
fprintf(stderr, "disconnected uid %d\n", *uidp);
clients[*uidp] = NULL;
}
// handles http connections, sets them up for chunked transfer,
// extracts the user id and registers in the global connection table,
// also sends a welcome chunk.
void request_handler(struct evhttp_request *req, void *arg)
{
struct evbuffer *buf;
buf = evbuffer_new();
if (buf == NULL){
err(1, "failed to create response buffer");
}
evhttp_add_header(req->output_headers, "Content-Type", "text/html; charset=utf-8");
int uid = -1;
if(strncmp(evhttp_request_uri(req), "/test/", 6) == 0){
uid = atoi( 6+evhttp_request_uri(req) );
}
if(uid <= 0){
evbuffer_add_printf(buf, "User id not found, try /test/123 instead");
evhttp_send_reply(req, HTTP_NOTFOUND, "Not Found", buf);
evbuffer_free(buf);
return;
}
if(uid > MAXUSERS){
evbuffer_add_printf(buf, "Max uid allowed is %d", MAXUSERS);
evhttp_send_reply(req, HTTP_SERVUNAVAIL, "We ran out of numbers", buf);
evbuffer_free(buf);
return;
}
evhttp_send_reply_start(req, HTTP_OK, "OK");
// Send welcome chunk:
evbuffer_add_printf(buf, "Welcome, Url: ‘%s’ Id: %d\n", evhttp_request_uri(req), uid);
evhttp_send_reply_chunk(req, buf);
evbuffer_free(buf);
// put reference into global uid->connection table:
clients[uid] = req;
// set close callback
evhttp_connection_set_closecb( req->evcon, cleanup, &slots[uid] );
}
// runs in a thread – the erlang c-node stuff
// expects msgs like {uid, msg} and sends a a ‘msg’ chunk to uid if connected
void cnode_run()
{
int fd; /* fd to Erlang node */
int got; /* Result of receive */
unsigned char buf[BUFSIZE]; /* Buffer for incoming message */
ErlMessage emsg; /* Incoming message */
ETERM *uid, *msg;
erl_init(NULL, 0);
if (erl_connect_init(1, "secretcookie", 0) == -1)
erl_err_quit("erl_connect_init");
if ((fd = erl_connect("httpdmaster@localhost")) < 0)
erl_err_quit("erl_connect");
fprintf(stderr, "Connected to httpdmaster@localhost\n\r");
struct evbuffer *evbuf;
while (1) {
got = erl_receive_msg(fd, buf, BUFSIZE, &emsg);
if (got == ERL_TICK) {
continue;
} else if (got == ERL_ERROR) {
fprintf(stderr, "ERL_ERROR from erl_receive_msg.\n");
break;
} else {
if (emsg.type == ERL_REG_SEND) {
// get uid and body data from eg: {123, <<"Hello">>}
uid = erl_element(1, emsg.msg);
msg = erl_element(2, emsg.msg);
int userid = ERL_INT_VALUE(uid);
char *body = (char *) ERL_BIN_PTR(msg);
int body_len = ERL_BIN_SIZE(msg);
// Is this userid connected?
if(clients[userid]){
fprintf(stderr, "Sending %d bytes to uid %d\n", body_len, userid);
evbuf = evbuffer_new();
evbuffer_add(evbuf, (const void*)body, (size_t) body_len);
evhttp_send_reply_chunk(clients[userid], evbuf);
evbuffer_free(evbuf);
}else{
fprintf(stderr, "Discarding %d bytes to uid %d – user not connected\n",
body_len, userid);
// noop
}
erl_free_term(emsg.msg);
erl_free_term(uid);
erl_free_term(msg);
}
}
}
// if we got here, erlang connection died.
// this thread is supposed to run forever
// TODO – gracefully handle failure / reconnect / etc
pthread_exit(0);
}
int main(int argc, char **argv)
{
// Launch the thread that runs the cnode:
pthread_attr_t tattr;
pthread_t helper;
int status;
pthread_create(&helper, NULL, cnode_run, NULL);
int i;
for(i=0;i<=MAXUSERS;i++) slots[i]=i;
// Launch libevent httpd:
struct evhttp *httpd;
event_init();
httpd = evhttp_start("0.0.0.0", 8000);
evhttp_set_gencb(httpd, request_handler, NULL);
event_dispatch();
// Not reached, event_dispatch() shouldn’t return
evhttp_free(httpd);
return 0;
}
Максимальное количество пользователей задано с помощью #define, прослушивается порт 8000 и ожидаются пользователи. Также жестко задано имя Erlang узела cookie.
Запустите узел, к которому будет подключатсясервер:
$ erl -setcookie secretcookie -sname httpdmaster@localhost
Запустим Си-узел:
$ gcc -o httpdcnode httpdcnode.c -lerl_interface -lei -levent
$ ./httpdcnode
Проверьте, что виден узел:
erl> nodes(hidden).
[c1@localhost]
Откройте в своем браузере localhost:8000/test/123. Вы должны увидеть приветственное сообщение.
Далее отправьте сообщение Си-узлу:
erl> {any, c1@localhost} ! {123, <<"Hello Libevent World">>}.
Обратите внимание, что мы не используем Pid — мы используем {procname, node}. Мы используем «any», как название процесса, который игнорируется Cи-узлом.
Теперь вы в состоянии доставить сообщения через Erlang, но все соединения управляются libevent программой на Си, которая действует как узел Erlang.
После удаления отладочного вывода, я подключил 1 000 000 клиентов к httpdcnode серверу, используя тот же самый клиент, как и выше. Машина показала, в общей сложности чуть менее 10 Гб используемой памяти.
Память сервера была стабильно около 2GB:

Порядка 2Кб на каждое подключение.
Состояние памяти:
Mem: 32968672k total, 9636488k used, 23332184k free, 180k buffers
Так kernel/ TCP стек берет дополнительные 8Кб за соединение, которые кажутся высокими, но у меня нет ничего для для сравнения.
Этот libevent-cnode сервер требует определенной дополнительной работы над собой. Не разумно обрабатывать несколько соединений от одного пользователя, и все еще присутствуют “race conditions”, если вы отключитесь тогда, когда сообщение было только отправлено.
Несмотря на это, мы использовали Erlang для всех интересных вещей, и Cи + libevent использовались для низкоуровневых операций. Программа на Cи может быть запущен в качестве драйвера или C-узла, а интерфейсы Erlang могут дать вам достойный API. У меня все еще осталось желание поэкспериментировать с этим.
Финальные выводы
У меня есть достаточно данных сейчас судить, какое оборудование будет необходимо, если мы развернем большую систему масштаба Last.fm. Даже в худшем случае 40Кб за соединение является хорошим результатом — память довольно дешевая на данный момент, и 40GB для поддержки миллионов пользователей не является проблемой. 10GB еще лучше.
