 В обсуждении моего недавнего перевода замечательнейшей статьи про CAPTCHA несколько раз появлялись вопросы насчет reCAPTCHA, а именно как же эта система работает. Под катом я в общих чертах объясню суть reCAPTCHA, наглядно покажу как она работает и каким же образом она цифрует книжки.
В обсуждении моего недавнего перевода замечательнейшей статьи про CAPTCHA несколько раз появлялись вопросы насчет reCAPTCHA, а именно как же эта система работает. Под катом я в общих чертах объясню суть reCAPTCHA, наглядно покажу как она работает и каким же образом она цифрует книжки.Расскажу я все достаточно кратко, но зато понятно. Приведенные иллюстрации были взяты с официального сайта reCAPTCHA
Stop spam
По своей сущности, reCAPTCHA выполняет ту же функцию, которую выполняют другие капчи. Суть проста, вводим предложенный текст и тем самым доказываем, что мы не робот. Главным отличием от других систем является то, что reCAPTCHA не только защищает сайт от спамеров, но еще и выполняет другую, достаточно интересную функцию.
Read books
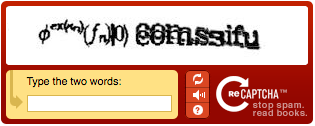
Как вы наверняка заметили, reCAPTCHA предлагает ввести два слова, что практически не встречается у других капч. Суть в том, что пользователь при вводе этих слов не только доказывает, что он человек, но еще и помогает распознавать старые книги и газеты.
Принцип работы прост:
Допустим, есть энная книга, которая сохранилась в малом количестве экземпляров, при этом все они в плохом состоянии. Один экземпляр в отсканированном виде попал в руки Google (владелец reCAPTCHA). Что с ним делать? Правильно, цифровать (и дело тут не только в сохранении наследия, но об этом позже). Как цифровать? Цифровать, используя системы распознавания символов (OCR). Но, как многим известно, эти системы очень часто грешат многочисленными ошибками в выданном результате. Вручную перебирать весь текст на предмет ошибок — слишком дорогое удовольствие. И вот, на помощь приходит reCAPTCHA. Одно слово в изображении распозналось системой OCR правильно, а вот второе никак нет. Второе слово — за пользователем, именно то, что он введет будет использовано в качестве замены ошибочному варианту, предложенным OCR. Наверняка сейчас некоторые усмехнутся, да, я знаю про то, что фактически вместо второго слова можно ввести что угодно. Но каждое непонятное для OCR слово reCAPTCHA показывает пользователям сотни, а то и тысячи раз (при цифре в 200 миллионов генераций в день это очень мало), и в конечном итоге правильным считается тот вариант, который пользователи вводили чаще всего.
От скучного текста перейдем к иллюстрациям:



Разумеется, это что-то вроде идеальной ситуации, где все складывается так, как задумывалось создателями reCAPTCHA. Но наверняка многие из вас сталкивались с абсолютно нечитаемыми словами, предлагаемыми для ввода. Проблема в том, что некоторые книги \ газеты сохранились настолько плохо, что порой и вручную они распознаются отвратительно. Вот пример:



Именно таким образом пользователи помогают оцифровывать книжки средствами reCAPTCHA. По-моему, это прекрасно.
Я ничего не понял!
Вкратце: изображение, генерируемое reCAPTCHA, состоит из двух отсканированных слов. Одно уже заведомо известно системе, насчет второго же есть сомнения. Именно это второе слово и есть объект для распознавания силами пользователей. Грубо говоря, интерфейс reCAPTCHA мог бы выглядеть и вот так:

Скрипты для распознавания
Бытует ошибочное мнение, что reCAPTCHA невозможно взломать (речь идет об автоматическом распознавании приведенного текста, без участия человека). Однако, судя по тенденциям, это не так. С течением времени reCAPTCHA понаделала различных подводных камней для систем распознавания. Среди них искривление текста, пересечение его полосами, так же недавно была введена фича, благодаря которой проверочное (известное системе) слово выглядит сдвоенным. Все это указывает на то, что reCAPTCHA все таки испытывает некоторые трудности с защитой.
Никто и не подозревал
Есть люди, которые критикуют reCAPTCHA, и с этической точки зрения, критикуют они не зря. Дело в том, что за распознанный текст Google так или иначе получает деньги. А сами тексты добываются вполне себе бесплатно, силами пользователей. То есть, тут имеет место бесплатный труд. Лично меня это не волнует, к тому же, никто не заставляет пользователей вводить reCAPTCHA, и более того, никто не заставляет веб-мастеров устанавливать ее на свои сайты :)
Ирония
Наверняка некоторые из вас, прочитав предыдущий абзац, поняли, что тут что-то не так. Все знают о сервисах по ручному распознаванию капчи, где миллионы азиатов вводят капчу за гроши. Итак, если принять во внимание предыдущий абзац, то получается, что эти азиаты работают не только на сервис по распознаванию, они работают и на Google. Бесплатно.
