Статья поможет новичкам понять как настраивать оборудование Cisco и D-Link в трёхуровневой модели сети. Конфигурация, представленная тут, не является эталонной или базовой — она для примера и понимания сути вещей, т.к. для каждого сетевого решения применяются свои параметры и технологии.
Рассмотрим следующую схему трёхуровневой иерархической модели, которая используется во многих решениях построения сетей:

Распределение объектов сети по уровням происходит согласно функционалу, который выполняет каждый объект, это помогает анализировать каждый уровень независимо от других, т.е. распределение идёт в основном не по физическим понятиям, а по логическим.
На уровне ядра необходима скоростная и отказоустойчивая пересылка большого объема трафика без появления задержек. Тут необходимо учитывать, что ACL и неоптимальная маршрутизация между сетями может замедлить трафик.
Обычно при появлении проблем с производительностью уровня ядра приходиться не расширять, а модернизировать оборудование, и иногда целиком менять на более производительное. Поэтому лучше сразу использовать максимально лучшее оборудование не забывая о наличии высокоскоростных интерфейсов с запасом на будущее. Если применяется несколько узлов, то рекомендуется объединять их в кольцо для обеспечения резерва.
На этом уровне применяют маршрутизаторы с принципом настройки — VLAN (один или несколько) на один узел уровня Distribution.
Тут происходит маршрутизация пользовательского трафика между сетями VLAN’ов и его фильтрация на основе ACL. На этом уровне описывается политика сети для конечных пользователей, формируются домены broadcast и multicast рассылок. Также на этом уровне иногда используются статические маршруты для изменения в маршрутизации на основе динамических протоколов. Часто применяют оборудование с большой ёмкостью портов SFP. Большое количество портов обеспечит возможность подключения множества узлов уровня доступа, а интерфейс SFP предоставит выбор в использовании электрических или оптических связей на нижестоящий уровень. Также рекомендуется объедение нескольких узлов в кольцо.
Часто применяются коммутаторы с функциями маршрутизации (L2/3) и с принципом настройки: VLAN каждого сервиса на один узел уровня Access.
К уровню доступа непосредственно физически присоединяются сами пользователи.
Часто на этом уровне трафик с пользовательских портов маркируется нужными метками DSCP.
Тут применяются коммутаторы L2 (иногда L2/3+) с принципом настройки: VLAN услуги на порт пользователя + управляющий VLAN на устройство доступа.
При рассмотрении следующих технологий используется оборудование уровня ядра и распределения Cisco Catalyst, а для уровня доступа — D-Link DES. На практике такое разделение брендов часто встречается из-за разницы в цене, т.к. на уровень доступа в основном необходимо ставить большое количество коммутаторов, наращивая ёмкость портов, и не все могут себе позволить, чтобы эти коммутаторы были Cisco.
Соберём следующую схему:
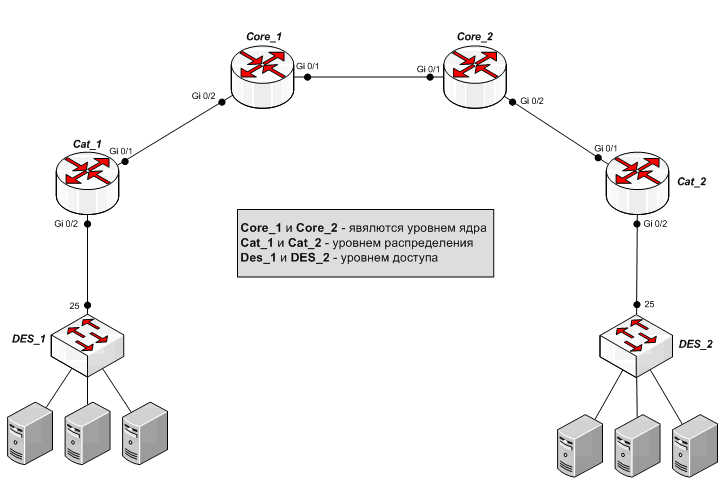
Схема упрощена для понимания практики: каждое ядро включает в себя только по одному узлу уровня распределения, и на каждый такой узел приходится по одному узлу уровня доступа.
На практике при больших масштабах сети смысл подобной структуры в том, что трафик пользователей с множества коммутаторов уровня доступа агрегируется на родительском узле распределения, маршрутизируется или коммутируется по необходимости на вышестоящее ядро, на соседний узел распределения или непосредственно между самими пользователями с разных узлов доступа. А каждое ядро маршрутизирует или коммутирует трафик между несколькими узлами распределения, которые непосредственно включены в него, или между соседними ядрами.
VLAN — это логическое разделение сети на независимые группы хостов.
Благодаря использованию VLAN можно осуществить следующие вещи:
Распределим VLAN'ы по схеме:
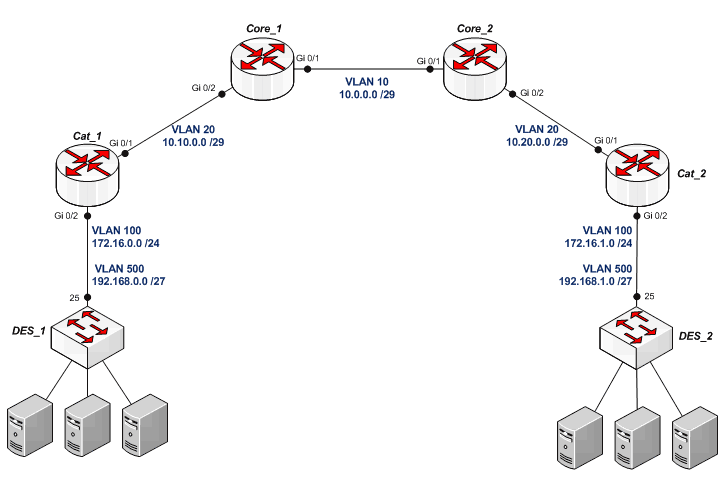
Начнём с уровня доступа.
На коммутаторе DES_1 (D-Link) создадим VLAN 100 для управления:
Добавим его тегированным на 25 порт:
Лучше запретить управляющий VLAN на портах (1-24), к которым подключаются пользователи:
Дефолтный VLAN устройства удалим:
Поставим IP адрес коммутатора в управляющий VLAN:
Пропишем шлюз, которым будет являться логический интерфейс устройства на вышестоящем уровне распределения:
Создадим VLAN 500, в котором предоставляется сервис DHCP (сам DHCP сервер будет находиться на уровне распределения) и сделаем его нетегированным на пользовательских портах (1-24) и тегированным на аплинке (25):
На DES_2 все те же настройки, кроме IP адреса (172.16.1.2) и шлюза (172.16.1.1).
Теперь перейдём к уровню распределения.
Настраиваем Cat_1.
Если мы используем коммутатор Catalyst, то VLAN'ы создаются в режиме конфигурации (
Предварительно лучше VTP переключить в прозрачный режим:
Необходимо создать три VLAN'а: управление узлами доступа – VLAN 100, для связи между Cat_1 и Core_1 — VLAN 20 и у нас один узел доступа на каждый уровень распределения, поэтому для сервиса DHCP создаётся один VLAN – 500, на реальной сети нужно на каждый коммутатор доступа по своему VLAN'у с DHCP:
Добавим VLAN 20 на интерфейс (gi 0/1), к которому подключено ядро.
Входим в режим конфигурации:
Конфигурация интерфейса gi 0/1:
Указываем использование стандарта 802.1Q:
Переводим порт в режим транка:
Добавляем VLAN:
Если на порту уже есть какие-то VLAN'ы, то необходимо использовать команду:
Теми же командами добавляем VLAN’ы 100, 500 на gi 0/2 к которому подключен DES_1.
Для конфигурации сразу нескольких интерфейсов одновременно можно делать так:
Укажем сеть для управления уровнем доступа:
Укажем IP для Cat_1:
Cat_2 настраиваем так же, только меняем адреса в VLAN'ах 100 и 20. VLAN 100 – 172.16.1.1 255.255.255.0, VLAN 20 – 10.20.0.2 255.255.255.248
На Core_1 создаём VLAN’ы 10 и 20, добавляем 10 на gi 0/1, куда подключен Core_2 и 20 на интерфейс gi 0/2, к которому подключен узел уровня распределения, ставим IP адреса: VLAN 10 – 10.0.0.1 255.255.255.248, VLAN 20 – 10.10.0.1 255.255.255.248.
На Core_2 создаём также VLAN’ы 10 и 20, добавляем 10 на gi 0/1, куда подключен Core_1 и 20 на интерфейс gi 0/2, к которому подключен Cat_2, ставим IP адреса: VLAN 10 – 10.0.0.2 255.255.255.248, VLAN 20 – 10.20.0.1 255.255.255.248.
DHCP – это клиент-серверный протокол для автоматической настройки IP адреса и других параметров у хоста сети.
В роли DHCP сервера будет выступать уровень распределения. В клиентском VLAN'е 500 создадим DHCP пул с сетью 192.168.0.0 255.255.255.224 для Cat_1 и 192.168.1.0 255.255.255.224 для Cat_2.
Настраиваем Cat_1.
Указываем DHCP пул:
Указываем сеть, из которой будут выдаваться адреса:
Указываем шлюз по умолчанию, который получит клиент DHCP:
Присваиваем клиенту dns сервера:
Задаём время аренды в днях:
Можно указать имя домена:
После этого выходим из режима конфигурации DHCP и исключаем ip адрес шлюза по умолчанию из DHCP пула:
Создаём логический интерфейс, который будет шлюзом по умолчанию для пользователей.
Создаём сам интерфейс:
Ставим IP адрес:
Для Cat_2 делаем по аналогии, используя в VLAN'е 500 сеть 192.168.1.0 255.255.255.224
После этого пользователи DES_1 и DES_2 будут получать адреса по DHCP.
OSPF — удобный протокол динамической маршрутизации с учётом состояния каналов. Он позволяет составить полную схему сети, а затем выбрать на основе этого оптимальный маршрут. Функционирование основано на получении данных о состоянии сетевых связей или каналов. Подробное описание есть в википедии. Мы будем использовать именно этот протокол.
В реальной сети каждое ядро содержит area 0 (для связи с другими ядрами) и несколько других зон, в которые входят узлы уровня распределения. Эти узлы в пределах одной зоны удобно объединять в кольца, благодаря чему будет резерв и оптимальная маршрутизация. Например, это может выглядеть так:
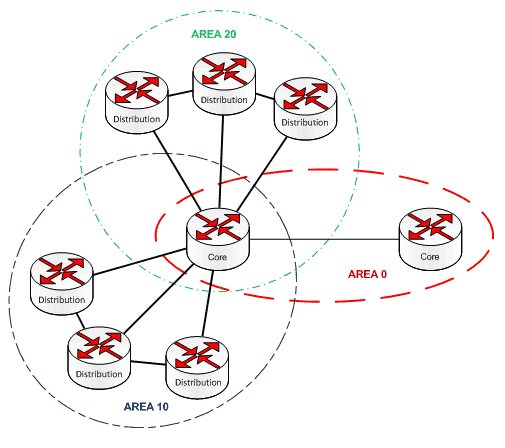
Определим зоны в нашей сети:

Настройка Core_1.
Включим маршрутизацию:
Включим процесс OSPF и укажем proccess-id (берётся произвольно, в нашем случае — 111):
Укажем сети для каждой из зон, в которые входит Core_1 (надо использовать инверсию маски):
Обычно прописывают ещё вручную Router-id (идентификатор маршрутизатора), указывая при этом IP адрес этого маршрутизатора. Если этого не делать, то Router-id будет выбран автоматически.
На Core_2 делаем всё точно также как и на Core_1.
При настройке Cat_1 включаем также маршрутизацию и процесс ospf с id 111. Указываем сеть 10.10.0.0 255.255.255.248 в area 10:
Необходимо указать редистрибьюцию сети для DHCP (она в int Vlan500) в этот процесс ospf. Делается это командой:
5 — это метрика для перераспределённого маршрута
1 – это тип внешней метрики – OSPF
После этой команды все сети в VLAN'ах Cat_1 будут доступны через ospf.
Редистрибьюцию пользовательских сетей DHCP также можно сделать через route-map и access-list или целиком указать в network x.x.x.x x.x.x.x area x. Всё это зависит от того, как и что нужно анонсировать в маршрутизации по сети.
Cat_2 настраиваем аналогично, только в area 10 надо указать network 10.20.0.0 0.0.0.7
По сути, теперь мы имеем работающую сеть, в которой пользователи с разных коммутаторов уровня доступа смогут обмениваться трафиком.
STP – протокол связующего дерева, предназначен для избавления от ненужных циклов трафика и используется для построения резервов по L2.
Протокол работает следующим образом:
Сделаем кольцо следующего вида:

Cat_3 и Cat_2 находятся в одной area, работая по VLAN'у 20 и соединены непосредственно друг с другом для резерва по L2.
На Core_2, Cat_2 и Cat_3 включаем rapid-pvst. Rapid-Per-VLAN-Spanning Tree позволяет строить дерево на каждый VLAN отдельно.
Указываем, что все существующие VLAN'ы должны участвовать в STP с приоритетом этого узла. Чтобы Core_2 был root bridge, ему надо поставить priority меньшее чем у Cat_3 и Cat_2, у которых в свою очередь priority может быть одинаковым.
Core_2:
Cat_3:
Cat_2:
После этого Core_2 станет root bridge, а один из портов Cat_3 или Cat_2 заблокируется для передачи трафика по VLAN'у 20 в сторону Core_2. Если необходимо указать, чтобы определённый VLAN не участвовал в STP, то делается это такой командой:
Следует заметить, что BPDU пакеты Cisco и D-Link, при помощи которых строится STP, не совместимы между собой, поэтому stp между оборудованием этих двух производителей скорее всего построить будет очень затруднительно.
SNMP – протокол простого управления сетью. При помощи него как правило собирается статистика работы оборудования, и он часто используется при автоматизации выполнения каких-либо операций на этом оборудовании.
На узлах всех уровней определим community, которое определяет доступ к узлу на read или write по этому протоколу, при условии, что это community совпадает у источника и получателя.
На Cisco:
Read —
Write —
Название snmp_community чувствительно к регистру.
На всех узлах ядра и распределения выполняем эти команды:
На D-link:
Удаляем всё дефолтное:
Создаём community на read — DLINK_READ и на write — DLINK_WRITE:
Списки контроля доступа – это условия, которые проходят проверку при выполнении каких-либо операций.
ACL используется в связке со многими протоколами и сетевыми механизмами, фильтруя трафик на интерфейсах и протоколах NTP, OSPF и других.
Создадим правило для закрытия доступа из пользовательской сети Cat_1 (192.168.0.0 255.255.255.224) в сеть Cat_2, которая находится в VLAN'е 500:
Как видите, в extended access листах используется инверсия маски.
После создания списка доступа его необходимо применить на нужном интерфейсе:
Тем самым запретив на int vlan500 Cat_2 входящий трафик ip и udp от 192.168.0.0 255.255.255.224 на любой адрес.
Cisco:
Синхронизация внутреннего времени узла с внешним сервером (можно использовать несколько серверов):
Указание часового пояса (GMT +3):
Начальная и конечная дата перехода на летнее время:
Эти команды следует выполнить на всех узлах сети, либо указать на роутере ядра ntp master и остальные узлы синхронизировать с ним.
Также можно указать время вручную:
Но это делать крайне не рекомендуется — лучше использовать NTP.
D-Link:
Используем SNTP – более простая версия NTP.
Включаем SNTP:
Указание часового пояса (GMT +3):
Задаём NTP сервера:
Начальная и конечная дата перехода на летнее время:
Мы рассмотрели теорию трёхуровневой модели сети и некоторые базовые технологии, которые помогут в изучении таких сетей.
Теория трёхуровневой модели
Рассмотрим следующую схему трёхуровневой иерархической модели, которая используется во многих решениях построения сетей:
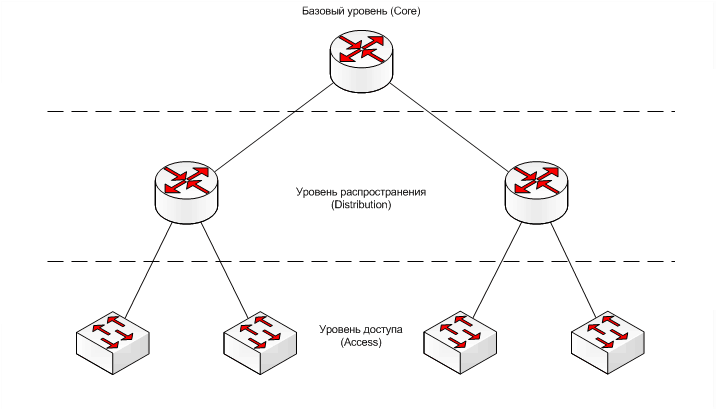
Распределение объектов сети по уровням происходит согласно функционалу, который выполняет каждый объект, это помогает анализировать каждый уровень независимо от других, т.е. распределение идёт в основном не по физическим понятиям, а по логическим.
Базовый уровень (Core)
На уровне ядра необходима скоростная и отказоустойчивая пересылка большого объема трафика без появления задержек. Тут необходимо учитывать, что ACL и неоптимальная маршрутизация между сетями может замедлить трафик.
Обычно при появлении проблем с производительностью уровня ядра приходиться не расширять, а модернизировать оборудование, и иногда целиком менять на более производительное. Поэтому лучше сразу использовать максимально лучшее оборудование не забывая о наличии высокоскоростных интерфейсов с запасом на будущее. Если применяется несколько узлов, то рекомендуется объединять их в кольцо для обеспечения резерва.
На этом уровне применяют маршрутизаторы с принципом настройки — VLAN (один или несколько) на один узел уровня Distribution.
Уровень распространения (Distribution)
Тут происходит маршрутизация пользовательского трафика между сетями VLAN’ов и его фильтрация на основе ACL. На этом уровне описывается политика сети для конечных пользователей, формируются домены broadcast и multicast рассылок. Также на этом уровне иногда используются статические маршруты для изменения в маршрутизации на основе динамических протоколов. Часто применяют оборудование с большой ёмкостью портов SFP. Большое количество портов обеспечит возможность подключения множества узлов уровня доступа, а интерфейс SFP предоставит выбор в использовании электрических или оптических связей на нижестоящий уровень. Также рекомендуется объедение нескольких узлов в кольцо.
Часто применяются коммутаторы с функциями маршрутизации (L2/3) и с принципом настройки: VLAN каждого сервиса на один узел уровня Access.
Уровень доступа (Access)
К уровню доступа непосредственно физически присоединяются сами пользователи.
Часто на этом уровне трафик с пользовательских портов маркируется нужными метками DSCP.
Тут применяются коммутаторы L2 (иногда L2/3+) с принципом настройки: VLAN услуги на порт пользователя + управляющий VLAN на устройство доступа.
Практическое применение сетевых технологий в трёхуровневой модели
При рассмотрении следующих технологий используется оборудование уровня ядра и распределения Cisco Catalyst, а для уровня доступа — D-Link DES. На практике такое разделение брендов часто встречается из-за разницы в цене, т.к. на уровень доступа в основном необходимо ставить большое количество коммутаторов, наращивая ёмкость портов, и не все могут себе позволить, чтобы эти коммутаторы были Cisco.
Соберём следующую схему:

Схема упрощена для понимания практики: каждое ядро включает в себя только по одному узлу уровня распределения, и на каждый такой узел приходится по одному узлу уровня доступа.
На практике при больших масштабах сети смысл подобной структуры в том, что трафик пользователей с множества коммутаторов уровня доступа агрегируется на родительском узле распределения, маршрутизируется или коммутируется по необходимости на вышестоящее ядро, на соседний узел распределения или непосредственно между самими пользователями с разных узлов доступа. А каждое ядро маршрутизирует или коммутирует трафик между несколькими узлами распределения, которые непосредственно включены в него, или между соседними ядрами.
VLAN — Virtual Local Area Network
VLAN — это логическое разделение сети на независимые группы хостов.
Благодаря использованию VLAN можно осуществить следующие вещи:
- разделить одно физическое устройство (коммутатор) на несколько логических по уровню L2
- если назначить подсети различным VLAN'ам, то хосты подключенные в одно и тоже устройство (содержащее несколько VLAN'ов) будут иметь различные подсети, также можно хосты с разных устройств объединять в одни подсети
- сегментация трафика VLAN'ами приводит к образованию независимых широковещательных доменов, тем самым уменьшая количество широковещательного трафика на сети в целом
- разделение трафика на VLAN'ы также обеспечивает безопасность между разными сетями
Распределим VLAN'ы по схеме:
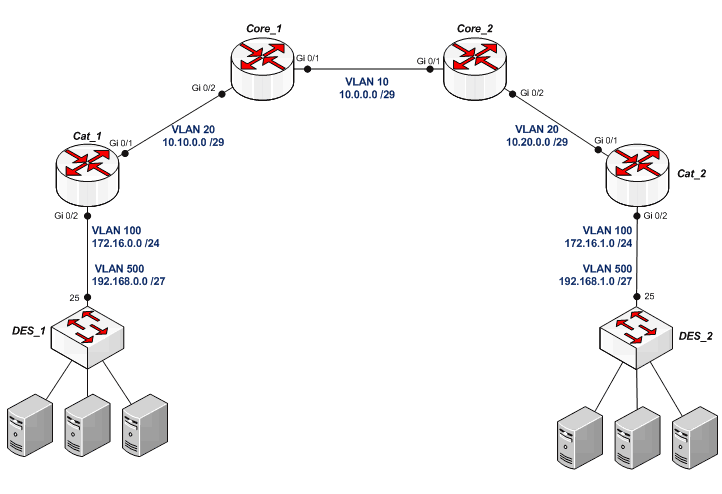
Начнём с уровня доступа.
На коммутаторе DES_1 (D-Link) создадим VLAN 100 для управления:
create vlan 100 tag 100Добавим его тегированным на 25 порт:
config vlan 100 add tagged 25Лучше запретить управляющий VLAN на портах (1-24), к которым подключаются пользователи:
config vlan 100 add forbidden 1-24Дефолтный VLAN устройства удалим:
config vlan default delete 1-26Поставим IP адрес коммутатора в управляющий VLAN:
config ipif System vlan 100 ipaddress 172.16.0.2/24 state enableПропишем шлюз, которым будет являться логический интерфейс устройства на вышестоящем уровне распределения:
create iproute default 172.16.0.1 1Создадим VLAN 500, в котором предоставляется сервис DHCP (сам DHCP сервер будет находиться на уровне распределения) и сделаем его нетегированным на пользовательских портах (1-24) и тегированным на аплинке (25):
create vlan 500 tag 500
config vlan 500 add untagged 1-23
config vlan 500 add tagged 25На DES_2 все те же настройки, кроме IP адреса (172.16.1.2) и шлюза (172.16.1.1).
Теперь перейдём к уровню распределения.
Настраиваем Cat_1.
Если мы используем коммутатор Catalyst, то VLAN'ы создаются в режиме конфигурации (
conf t) следующим образом:Vlan <список VLAN’ов через запятую>Предварительно лучше VTP переключить в прозрачный режим:
vtp mode transparentНеобходимо создать три VLAN'а: управление узлами доступа – VLAN 100, для связи между Cat_1 и Core_1 — VLAN 20 и у нас один узел доступа на каждый уровень распределения, поэтому для сервиса DHCP создаётся один VLAN – 500, на реальной сети нужно на каждый коммутатор доступа по своему VLAN'у с DHCP:
Vlan 100,20,500Добавим VLAN 20 на интерфейс (gi 0/1), к которому подключено ядро.
Входим в режим конфигурации:
Cat_1#conf tКонфигурация интерфейса gi 0/1:
Cat_1(config)#int gigabitEthernet 0/1Указываем использование стандарта 802.1Q:
Cat_1(config-if)#switchport trunk encapsulation dot1q Переводим порт в режим транка:
Cat_1(config-if)#switchport mode trunk Добавляем VLAN:
Cat_1(config-if)#switchport trunk allowed vlan 20Если на порту уже есть какие-то VLAN'ы, то необходимо использовать команду:
switchport trunk allowed vlan add <список VLAN’ов>, т.к. если не указать add, то уже существующие VLAN’ы пропадут.Теми же командами добавляем VLAN’ы 100, 500 на gi 0/2 к которому подключен DES_1.
Для конфигурации сразу нескольких интерфейсов одновременно можно делать так:
Cat_1(config)#int range gigabitEthernet 0/2-3Укажем сеть для управления уровнем доступа:
Cat_1(config)#int Vlan100
Cat_1(config-if)#ip address 172.16.0.1 255.255.255.0Укажем IP для Cat_1:
Cat_1(config)#int Vlan20
Cat_1(config-if)#ip address 10.10.0.2 255.255.255.248Cat_2 настраиваем так же, только меняем адреса в VLAN'ах 100 и 20. VLAN 100 – 172.16.1.1 255.255.255.0, VLAN 20 – 10.20.0.2 255.255.255.248
На Core_1 создаём VLAN’ы 10 и 20, добавляем 10 на gi 0/1, куда подключен Core_2 и 20 на интерфейс gi 0/2, к которому подключен узел уровня распределения, ставим IP адреса: VLAN 10 – 10.0.0.1 255.255.255.248, VLAN 20 – 10.10.0.1 255.255.255.248.
На Core_2 создаём также VLAN’ы 10 и 20, добавляем 10 на gi 0/1, куда подключен Core_1 и 20 на интерфейс gi 0/2, к которому подключен Cat_2, ставим IP адреса: VLAN 10 – 10.0.0.2 255.255.255.248, VLAN 20 – 10.20.0.1 255.255.255.248.
DHCP — Dynamic Host Configuration Protocol
DHCP – это клиент-серверный протокол для автоматической настройки IP адреса и других параметров у хоста сети.
В роли DHCP сервера будет выступать уровень распределения. В клиентском VLAN'е 500 создадим DHCP пул с сетью 192.168.0.0 255.255.255.224 для Cat_1 и 192.168.1.0 255.255.255.224 для Cat_2.
Настраиваем Cat_1.
Указываем DHCP пул:
Cat_1(config)#ip dhcp pool Vlan500Указываем сеть, из которой будут выдаваться адреса:
Cat_1(dhcp-config)#network 192.168.0.0 255.255.255.224Указываем шлюз по умолчанию, который получит клиент DHCP:
Cat_1(dhcp-config)#default-router 192.168.0.1Присваиваем клиенту dns сервера:
Cat_1(dhcp-config)#dns-server <IP_DNS_Server_1> <IP_DNS_server_2> Задаём время аренды в днях:
Cat_1(dhcp-config)#lease 14Можно указать имя домена:
Cat_1(dhcp-config)#domain-name workgroup_1После этого выходим из режима конфигурации DHCP и исключаем ip адрес шлюза по умолчанию из DHCP пула:
Cat_1(dhcp-config)#ex
Cat_1(config)#ip dhcp excluded-address 192.168.0.1Создаём логический интерфейс, который будет шлюзом по умолчанию для пользователей.
Создаём сам интерфейс:
Cat_1(config)#int Vlan500Ставим IP адрес:
Cat_1(config-if)# ip address 192.168.0.1 255.255.255.224Для Cat_2 делаем по аналогии, используя в VLAN'е 500 сеть 192.168.1.0 255.255.255.224
После этого пользователи DES_1 и DES_2 будут получать адреса по DHCP.
OSPF — Open Shortest Path First
OSPF — удобный протокол динамической маршрутизации с учётом состояния каналов. Он позволяет составить полную схему сети, а затем выбрать на основе этого оптимальный маршрут. Функционирование основано на получении данных о состоянии сетевых связей или каналов. Подробное описание есть в википедии. Мы будем использовать именно этот протокол.
В реальной сети каждое ядро содержит area 0 (для связи с другими ядрами) и несколько других зон, в которые входят узлы уровня распределения. Эти узлы в пределах одной зоны удобно объединять в кольца, благодаря чему будет резерв и оптимальная маршрутизация. Например, это может выглядеть так:

Определим зоны в нашей сети:
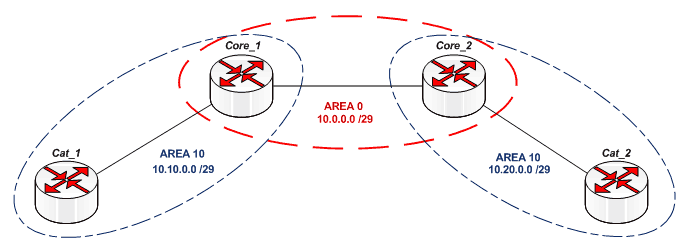
Настройка Core_1.
Включим маршрутизацию:
Core_1(config)# ip routing
Core_1(config)# ip classless
Core_1(config)# ip subnet-zeroВключим процесс OSPF и укажем proccess-id (берётся произвольно, в нашем случае — 111):
Core_1(config)#router ospf 111Укажем сети для каждой из зон, в которые входит Core_1 (надо использовать инверсию маски):
Core_1 (config-router)# network 10.0.0.0 0.0.0.7 area 0
Core_1 (config-router)# network 10.10.0.0 0.0.0.7 area 10Обычно прописывают ещё вручную Router-id (идентификатор маршрутизатора), указывая при этом IP адрес этого маршрутизатора. Если этого не делать, то Router-id будет выбран автоматически.
На Core_2 делаем всё точно также как и на Core_1.
При настройке Cat_1 включаем также маршрутизацию и процесс ospf с id 111. Указываем сеть 10.10.0.0 255.255.255.248 в area 10:
Cat_1(config)# ip routing
Cat_1(config)# ip classless
Cat_1(config)# ip subnet-zero
Cat_1(config)#router ospf 111
Cat_1(config-router)# network 10.10.0.0 0.0.0.7 area 10Необходимо указать редистрибьюцию сети для DHCP (она в int Vlan500) в этот процесс ospf. Делается это командой:
Cat_1(config-router)# redistribute connected metric 5 metric-type 1 subnets5 — это метрика для перераспределённого маршрута
1 – это тип внешней метрики – OSPF
После этой команды все сети в VLAN'ах Cat_1 будут доступны через ospf.
Редистрибьюцию пользовательских сетей DHCP также можно сделать через route-map и access-list или целиком указать в network x.x.x.x x.x.x.x area x. Всё это зависит от того, как и что нужно анонсировать в маршрутизации по сети.
Cat_2 настраиваем аналогично, только в area 10 надо указать network 10.20.0.0 0.0.0.7
По сути, теперь мы имеем работающую сеть, в которой пользователи с разных коммутаторов уровня доступа смогут обмениваться трафиком.
STP — Spanning Tree Protocol
STP – протокол связующего дерева, предназначен для избавления от ненужных циклов трафика и используется для построения резервов по L2.
Протокол работает следующим образом:
- на сети выбирается root bridge
- все не root узлы вычисляют оптимальный путь к root bridge, и порт (через который проходит этот путь) становится root port
- если путь к root bridge проходит через какой то узел, то такой узел сети становиться designated bridge и порт соответственно designated port
- порты, участвующие в дереве stp и не являющиеся root или designated блокируются
Сделаем кольцо следующего вида:
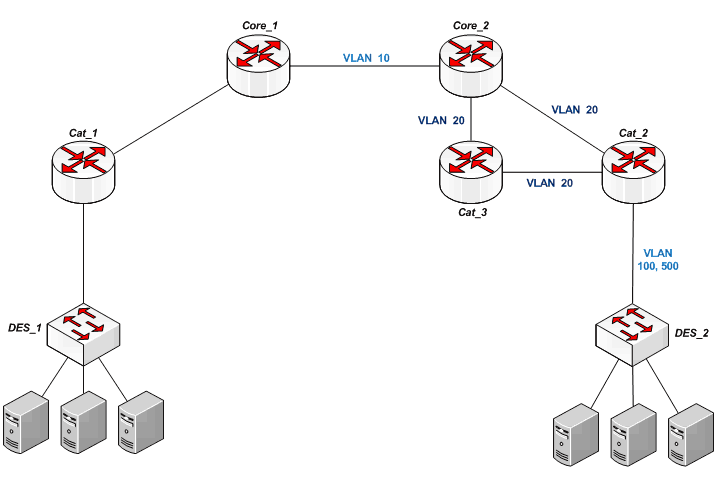
Cat_3 и Cat_2 находятся в одной area, работая по VLAN'у 20 и соединены непосредственно друг с другом для резерва по L2.
На Core_2, Cat_2 и Cat_3 включаем rapid-pvst. Rapid-Per-VLAN-Spanning Tree позволяет строить дерево на каждый VLAN отдельно.
Cat_1(config)#spanning-tree mode rapid-pvst
Указываем, что все существующие VLAN'ы должны участвовать в STP с приоритетом этого узла. Чтобы Core_2 был root bridge, ему надо поставить priority меньшее чем у Cat_3 и Cat_2, у которых в свою очередь priority может быть одинаковым.
Core_2:
Core_2(config)#spanning-tree vlan 1-4094 priority 4096Cat_3:
Cat_3(config)#spanning-tree vlan 1-4094 priority 8192Cat_2:
Cat_2(config)#spanning-tree vlan 1-4094 priority 8192После этого Core_2 станет root bridge, а один из портов Cat_3 или Cat_2 заблокируется для передачи трафика по VLAN'у 20 в сторону Core_2. Если необходимо указать, чтобы определённый VLAN не участвовал в STP, то делается это такой командой:
no spanning-tree vlan <имя_VLAN'а>Следует заметить, что BPDU пакеты Cisco и D-Link, при помощи которых строится STP, не совместимы между собой, поэтому stp между оборудованием этих двух производителей скорее всего построить будет очень затруднительно.
SNMP — Simple Network Management Protocol
SNMP – протокол простого управления сетью. При помощи него как правило собирается статистика работы оборудования, и он часто используется при автоматизации выполнения каких-либо операций на этом оборудовании.
На узлах всех уровней определим community, которое определяет доступ к узлу на read или write по этому протоколу, при условии, что это community совпадает у источника и получателя.
На Cisco:
Read —
snmp-server community <название_snmp_community> RO Write —
snmp-server community <название_snmp_community> RWНазвание snmp_community чувствительно к регистру.
На всех узлах ядра и распределения выполняем эти команды:
Core_1(config)# snmp-server community CISCO_READ RO
Core_1(config)# snmp-server community CISCO_WRITE RWНа D-link:
Удаляем всё дефолтное:
delete snmp community public
delete snmp community private
delete snmp user initial
delete snmp group initial
delete snmp view restricted all
delete snmp view CommunityView allСоздаём community на read — DLINK_READ и на write — DLINK_WRITE:
create snmp view CommunityView 1 view_type included
create snmp group DLINK_READ v1 read_view CommunityView notify_view CommunityView
create snmp group DLINK_READ v2c read_view CommunityView notify_view CommunityView
create snmp group DLINK_WRITE v1 read_view CommunityView write_view CommunityView notify_view CommunityView
create snmp group DLINK_WRITE v2c read_view CommunityView write_view CommunityView notify_view CommunityView
create snmp community DLINK_READ view CommunityView read_only
create snmp community DLINK_WRITE view CommunityView read_writeACL — Access Control List
Списки контроля доступа – это условия, которые проходят проверку при выполнении каких-либо операций.
ACL используется в связке со многими протоколами и сетевыми механизмами, фильтруя трафик на интерфейсах и протоколах NTP, OSPF и других.
Создадим правило для закрытия доступа из пользовательской сети Cat_1 (192.168.0.0 255.255.255.224) в сеть Cat_2, которая находится в VLAN'е 500:
Cat_2(config)#ip access-list extended Access_denided_IN
Cat_2(config)#deny ip 192.168.0.0 0.0.0.31 any
Cat_2(config)#deny udp 192.168.0.0 0.0.0.31 anyКак видите, в extended access листах используется инверсия маски.
После создания списка доступа его необходимо применить на нужном интерфейсе:
Cat_2(config)#int Vlan500
Cat_2(config-if)# ip access-group Access_denided_IN inТем самым запретив на int vlan500 Cat_2 входящий трафик ip и udp от 192.168.0.0 255.255.255.224 на любой адрес.
NTP — Network Time Protocol
Cisco:
Синхронизация внутреннего времени узла с внешним сервером (можно использовать несколько серверов):
ntp server <IP вашего NTP сервера>Указание часового пояса (GMT +3):
clock timezone MSK 3Начальная и конечная дата перехода на летнее время:
clock summer-time MSK recurring last Sun Mar 2:00 last Sun Oct 3:00Эти команды следует выполнить на всех узлах сети, либо указать на роутере ядра ntp master и остальные узлы синхронизировать с ним.
Также можно указать время вручную:
clock set 18:00:00 20 Feb 2011Но это делать крайне не рекомендуется — лучше использовать NTP.
D-Link:
Используем SNTP – более простая версия NTP.
Включаем SNTP:
enable sntpУказание часового пояса (GMT +3):
config time_zone operator + hour 3 min 0Задаём NTP сервера:
config sntp primary <IP вашего NTP сервера_1> secondary <IP вашего NTP сервера_2> poll-interval 600poll-interval — интервал времени в секундах между запросами на обновление SNTP информации.Начальная и конечная дата перехода на летнее время:
config dst repeating s_week 1 s_day sun s_mth 4 s_time 0:3 e_week last e_day sun e_mth 10 e_time 0:3 offset 60Мы рассмотрели теорию трёхуровневой модели сети и некоторые базовые технологии, которые помогут в изучении таких сетей.
