Сейчас наличие нескольких подключений к интернет на одном, в том числе и домашнем сервере — не редкость. Городские локалки, ADSL, 3G модемы… Добавим к этому сети домашние локальные и внешние виртуальные (VPN), и получим ядрёную смесь интерфейсов, между которыми необходимо роутить трафик, балансировать трафик между разными каналами в интернет (когда они есть), и переключаться с нерабочих каналов на рабочие (когда они отваливаются).
Судя по постам в инете, большинство людей, столкнувшихся с этой ситуацией, очень плохо представляет себе, как это настраивается. Надо отметить, что в линухе действительно управление роутингом весьма сложное и запутанное — следствие эволюционного развития и поддержки (частичной) совместимости. Я хочу описать принципы настройки роутинга multihomed серверов на конкретном, достаточно сложном, примере: на сервере три физических сетевых интерфейса (один в домашнюю локалку и два к ADSL-модемам), два ADSL-подключения (ADSL-модемы в режиме bridge, так что pppd поднимает этот же сервер) к разным провайдерам (одно со статическим IP, второе с динамическим), плюс VPN на сервер компании — итого шесть интерфейсов.
Тема достаточно сложная, поэтому для понимания материала потребуется хотя бы минимальное понимание работы роутинга (что такое default route и gateway), файрвола (маркировка пакетов, отслеживание соединений, связь между разными таблицами и цепочками файрвола и роутингом), pppd (скрипты ip-up/ip-down) и протоколов IP и TCP.
Итак, у нас есть три сетевых интерфейса:
Для настройки роутинга раньше (да и сейчас — в простых случаях) использовалась команда route. Про неё можете забыть — такие настройки делаются только через команду ip (из пакета iproute2), а одновременное использование и ip и route ничего кроме неприятностей не принесёт. Во времена команды route, таблица роутинга была одна. Сейчас таблиц роутинга несколько (и одна из них — main — та самая, с которой работает команда route). Эти таблицы перечислены в /etc/iproute2/rt_tables:
Просмотреть их содержимое можно командой ip route list table <имятаблицы>. В таблице local нет ничего интересного — там правила link-local роутинга через имеющиеся интерфейсы; в таблице main основные правила роутинга; таблица default по умолчанию пустая; таблица unspec (к которой так же можно обратиться как all) выводит все правила роутинга из всех существующих таблиц.
Для создания новых таблиц необходимо добавить их имена в этот файл (точнее, это необходимо только для обращения к своим таблицам по именам — по номерам к ним можно обращаться и так).
Как только у нас оказалось больше одной таблицы роутинга, понадобился и механизм, с помощью которого возможно выбрать используемую таблицу роутинга — его зовут правила роутинга (RPDB, routing policy database). Основное преимущество этого механизма — возможность выбирать роутинг не только на базе адреса назначения (как делала команда route и делает ip route ...), но и по другим критериям (исходный адрес, интерфейс, поля tos, fwmark, ...). Работает это так: вы указываете (через команду ip rule ...) любое количество правил в формате «критерии->таблица роутинга». Если для данного пакета критерии в правилах роутинга совпадут, и в указанной таблице роутинга найдётся маршрут для этого пакета (на базе адреса назначения), то оно выполнится; а если не найдётся, то мы возвращаемся в правила роутинга и проверяем другие варианты. Вот как выглядят правила роутинга по умолчанию:
Первая колонка — приоритет; правила просматриваются в порядке увеличения приоритета. Эти правила означают, что сначала просматривается таблица local (где link-local правила роутинга), потом таблица main (которой вы обычно управляли через команду route) и где обычно указан default route — т.е. на этом выполнение правил роутинга останавливается, потом (если в main не был указан default route) таблица default (пустая по умолчанию).
Вот простой пример, как всем этим хозяйством можно воспользоваться для того, чтобы пакеты с адреса домашней локалки 192.168.2.100 обрабатывались с помощью отдельных правил роутинга, отличных от роутинга по умолчанию (дадим ему доступ только к первому ADSL-модему и в интернет через первого провайдера):
Теперь немного о файрволе. С его помощью тоже возможно влиять на роутинг.
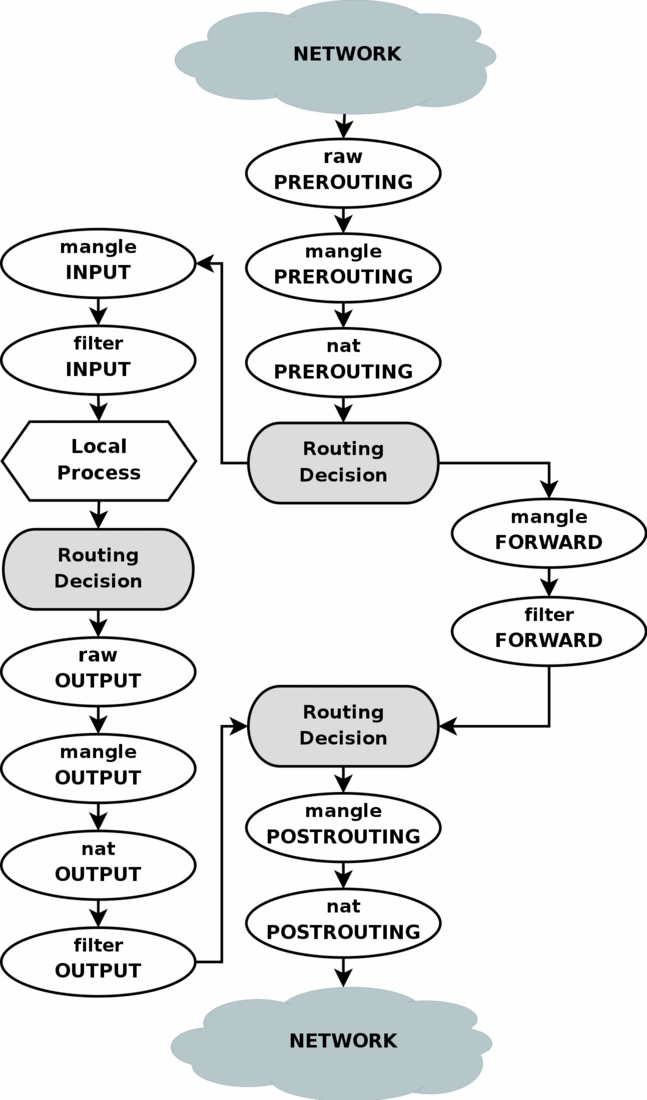
Как вы видите на схеме, пакеты от, например, локальных приложений проходят через этап «Routing Decision» дважды. Насколько я понимаю, первый раз это происходит в момент создания пакета, для того, чтобы определить для него исходящий интерфейс и исходящий IP (которые могут проверять правила файрвола, так что они должны быть уже известны когда пакет попадает в файрвол), плюс повторно роутинг для этого пакета вычисляется после выполнения цепочки MANGLE файрвола, которая могла изменить любые поля пакета, что могло повлиять на роутинг этого пакета.
В нашем случае самый простой способ влиять на роутинг через файрвол — изменять в цепочке MANGLE поле fwmark пакета, а потом с помощью правил роутинга выбирать таблицу роутинга на базе значения поля fwmark пакета (для этого потребуется создать несколько таблиц роутинга с разными правилами — например, в одной таблице прописать default route через одного провайдера, а в другой — через другого провайдера).
Путь к этому конечному результату местами тернист (баги особенности pppd и openvpn не дают расслабиться) и поэтому будет описан ниже. А пока давайте посмотрим, что нам требуется получить.
Для начала, настроим одновременное использование обоих провайдеров, с балансированием нагрузки в соотношении 8 к 2 (соответственно ширине каналов). Этот способ выбирает роутинг для каждого отдельного адреса назначения — т.е. если соединение изначально пошло через первого провайдера, то все его пакеты будут уходить только через первого провайдера, и все последующие соединения на этот адрес ещё некоторое время будут уходить только через этого провайдера. Балансировка не по соединениям а по пакета делается иначе, и будет работать только если у нас несколько соединений к одному провайдеру.
Т.к. ядро кеширует информацию о связи адресов назначения и выбранного для них роутинга по умолчанию, то может потребоваться сбросить этот кеш (чтобы ядро снова, с вероятностью 8 к 2, выбрало роутинг по умолчанию для этого адреса назначения):
Т.к. в некоторых случаях нам необходимо контролировать, через какой из внешних каналов отправить пакет, создадим для каждого канала отдельную таблицу роутинга со своим default route:
Теперь добавим правила роутинга так, чтобы с помощью файрвола выставив нужные значения fwmark мы могли выбрать нужную таблицу роутинга:
Значение 0x4/0x4 (значение/маска) означает, что из поля fwmark будут взяты биты по маске 0x4 (т.е. только третий бит) которые должны совпасть со значением 0x4. Т.е. в fwmark должен быть выставлен третий бит чтобы сработало правило для таблицы vpn, а остальные биты значения не имеют. Такой подход позволяет в файрволе выставить несколько битов в fwmark, указав таким образом несколько «подходящих» каналов для этого пакета. Приоритет этих каналов (если они все доступны) задаётся приоритетом правил роутинга. Если какой-то канал недоступен, то соответствующая таблица роутинга всё-равно будет просмотрена, но в ней не окажется default route, поэтому произойдёт возврат к следующим правилам роутинга и будет найден следующий подходящий канал.
Все эти команды пока что ни на что не повлияли — файрвол fwmark не выставляет, значит правила роутинга для таблиц isp1, isp2 и vpn не срабатывают, а по умолчанию роутинг как и раньше определяется таблицей main:
Теперь мы можем указать, что доступ к веб-сайту со статистикой и контрольной панелью второго провайдера должен идти через второй ADSL:
Если необходимо, чтобы эти правила работали не только для пакетов исходящих с нашего сервера, но и для пакетов из домашней локалки, то необходимо все эти правила в файрвол добавлять не только в цепочку OUTPUT, но и в цепочку FORWARD.
Всё это будет отлично работать пока речь идёт только об исходящих соединениях. Но ведь у нас сервер… а к серверу бывают и входящие соединения. Допустим, у нас поднят веб-сайт на статическом IP s.s.s.s (канал первого провайдера). Теперь, если админ второго провайдера с сервера <ip_сайта_isp2> захочет заглянуть (через lynx) на наш веб-сайт, у него ничего не выйдет! Дело в том, что он пошлёт запрос на наш IP s.s.s.s (на котором веб-сайт) через канал нашего первого провайдера, а ответ на этот запрос наш сервер отправит через канал второго провайдера (и, соответственно, с адреса d.d.d.d — у нас ведь, разумеется, настроен SNAT/MASQUERADE пакетов исходящих через интерфейсы ppp0, ppp1 и tun0) — согласно настройкам файрвола, которые мы только что сделали: пакеты на адрес <ip_сайта_isp2> отправлять через канал второго провайдера. Веб-браузер админа, пославший запрос на адрес s.s.s.s никак не ожидает получить ответ с адреса d.d.d.d, так что работать это не будет.
Чтобы решить эту проблему, необходимо гарантировать ответы на входящие соединения с того интерфейса, с которого изначально были приняты пакеты. Для этого, к сожалению, придётся использовать отслеживание соединений файрволом (conntrack) для выставления fwmark (connmark). К сожалению — потому, что conntrack это большая сложная и глючная фигня, но выбора здесь нет. Делается это так (эти правила надо добавить в файрвол первыми, ДО правил устанавливающих fwmark вроде описанного выше):
Здесь мы маркируем входящие пакеты (точнее, соединения, к которым они относятся) согласно интерфейсам, с которых они пришли. Причем значение fwmark (точнее, connmark) выбираем такое, чтобы оно соответствовало таблице роутинга, через которую нужно отправлять ответы на эти пакеты (1,2,4 — для isp1, isp2 и vpn; 8 — это не используемый в правилах роутинга fwmark, т.е. пакеты с этим fwmark будут отправлены согласно обычному роутингу в таблице main — для пакетов из локальных сетей это вполне подходит).
На роутинг входящих пакетов эта маркировка никак не влияет, но это позволяет нам фактически привязать эту маркировку ко всем пакетам этого соединения, в т.ч. исходящим пакетам. Далее, для исходящих пакетов на этом же соединении (ответов на входящие пакеты) мы устанавливаем значение fwmark в то же значение, которое было у входящих пакетов и которое привязано к этому соединению (точнее, копируем значение connmark в fwmark). И если в результате у исходящих пакетов значение fwmark оказывается установлено (не 0), значит все последующие правила установки fwmark для выбора исходящего канала применять нельзя — этот пакет необходимо отправить через тот же интерфейс, через которых пришёл входящий пакет, поэтому останавливаемся (-j ACCEPT).
Итого, корректный вариант настройки файрвола согласно нашей постановке задачи выглядит так:
Вместе с настройками правил и таблиц роутинга мы получаем именно то, что нам требовалось. Осталось разобраться, как эти настройки устанавливать в динамике, с учётом того, что каналы могут падать и подниматься.
Честно говоря, статья получилась и так немаленькая, поэтому дополнительно загромождать её своими ip-up/down скриптами, как собирался, я сейчас не буду. Если кто-то попросит в комментариях — добавлю в статью позже. А сейчас кратко опишу основные задачи и проблемы, возникшие при реализации вышеописанных настроек.
Судя по постам в инете, большинство людей, столкнувшихся с этой ситуацией, очень плохо представляет себе, как это настраивается. Надо отметить, что в линухе действительно управление роутингом весьма сложное и запутанное — следствие эволюционного развития и поддержки (частичной) совместимости. Я хочу описать принципы настройки роутинга multihomed серверов на конкретном, достаточно сложном, примере: на сервере три физических сетевых интерфейса (один в домашнюю локалку и два к ADSL-модемам), два ADSL-подключения (ADSL-модемы в режиме bridge, так что pppd поднимает этот же сервер) к разным провайдерам (одно со статическим IP, второе с динамическим), плюс VPN на сервер компании — итого шесть интерфейсов.
Тема достаточно сложная, поэтому для понимания материала потребуется хотя бы минимальное понимание работы роутинга (что такое default route и gateway), файрвола (маркировка пакетов, отслеживание соединений, связь между разными таблицами и цепочками файрвола и роутингом), pppd (скрипты ip-up/ip-down) и протоколов IP и TCP.
Общая конфигурация и постановка задачи
Итак, у нас есть три сетевых интерфейса:
- eth0 (192.168.0.2), подключён к первому ADSL модему (192.168.0.1)
- eth1 (192.168.1.2), подключён к второму ADSL модему (192.168.1.1)
- eth2 (192.168.2.1), подключён к домашней локальной сети (192.168.2.x) и является шлюзом в инет для этой локалки
- ppp0 (s.s.s.s), статический IP через первый ADSL модем к первому провайдеру (8Mbps)
- ppp1 (d.d.d.d), динамический IP через второй ADSL модем к второму провайдеру (2Mbps)
- tun0 (v.v.v.v), статический IP через VPN на сервер компании
- доступ с сервера и домашней локалки в инет при наличии любого из ADSL соединений
- балансирование трафика между ADSL соединениями если доступны оба, в соответствии с шириной каналов
- VPN должен быть поднят через любое ADSL соединение, а если доступны оба, то через первого провайдера (канал шире)
- почта должна отправляться через первого провайдера (там статический IP привязанный к моему домену)
- доступ к веб-сайту со статистикой и контрольной панелью второго провайдера должен идти через второй ADSL (провайдер закрыл доступ к своему сайту снаружи)
Немного теории
Для настройки роутинга раньше (да и сейчас — в простых случаях) использовалась команда route. Про неё можете забыть — такие настройки делаются только через команду ip (из пакета iproute2), а одновременное использование и ip и route ничего кроме неприятностей не принесёт. Во времена команды route, таблица роутинга была одна. Сейчас таблиц роутинга несколько (и одна из них — main — та самая, с которой работает команда route). Эти таблицы перечислены в /etc/iproute2/rt_tables:
# cat /etc/iproute2/rt_tables
#
# reserved values
#
255 local
254 main
253 default
0 unspec
#
# local
#
#1 inr.ruhep
Просмотреть их содержимое можно командой ip route list table <имятаблицы>. В таблице local нет ничего интересного — там правила link-local роутинга через имеющиеся интерфейсы; в таблице main основные правила роутинга; таблица default по умолчанию пустая; таблица unspec (к которой так же можно обратиться как all) выводит все правила роутинга из всех существующих таблиц.
Для создания новых таблиц необходимо добавить их имена в этот файл (точнее, это необходимо только для обращения к своим таблицам по именам — по номерам к ним можно обращаться и так).
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
127.0.0.0 127.0.0.1 255.0.0.0 UG 0 0 0 lo
192.168.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1
192.168.2.0 0.0.0.0 255.255.255.0 U 0 0 0 eth2
# ip route list table main
127.0.0.0/8 via 127.0.0.1 dev lo scope link
192.168.0.0/24 dev eth0 proto kernel scope link src 192.168.0.2
192.168.1.0/24 dev eth1 proto kernel scope link src 192.168.1.2
192.168.2.0/24 dev eth2 proto kernel scope link src 192.168.2.1
Как только у нас оказалось больше одной таблицы роутинга, понадобился и механизм, с помощью которого возможно выбрать используемую таблицу роутинга — его зовут правила роутинга (RPDB, routing policy database). Основное преимущество этого механизма — возможность выбирать роутинг не только на базе адреса назначения (как делала команда route и делает ip route ...), но и по другим критериям (исходный адрес, интерфейс, поля tos, fwmark, ...). Работает это так: вы указываете (через команду ip rule ...) любое количество правил в формате «критерии->таблица роутинга». Если для данного пакета критерии в правилах роутинга совпадут, и в указанной таблице роутинга найдётся маршрут для этого пакета (на базе адреса назначения), то оно выполнится; а если не найдётся, то мы возвращаемся в правила роутинга и проверяем другие варианты. Вот как выглядят правила роутинга по умолчанию:
# ip rule list
0: from all lookup local
32766: from all lookup main
32767: from all lookup default
Первая колонка — приоритет; правила просматриваются в порядке увеличения приоритета. Эти правила означают, что сначала просматривается таблица local (где link-local правила роутинга), потом таблица main (которой вы обычно управляли через команду route) и где обычно указан default route — т.е. на этом выполнение правил роутинга останавливается, потом (если в main не был указан default route) таблица default (пустая по умолчанию).
Вот простой пример, как всем этим хозяйством можно воспользоваться для того, чтобы пакеты с адреса домашней локалки 192.168.2.100 обрабатывались с помощью отдельных правил роутинга, отличных от роутинга по умолчанию (дадим ему доступ только к первому ADSL-модему и в интернет через первого провайдера):
# echo '100 local100' >> /etc/iproute2/rt_tables
# ip route add 192.168.0.0/24 dev eth0 table local100
# ip route add default via <шлюз_первого_провайдера> dev ppp0 table local100
# ip rule add from 192.168.2.100 lookup local100 priority 5
# ip route list table local100
192.168.0.0/24 dev eth0 scope link
default via <шлюз_первого_провайдера> dev ppp0
# ip rule list
0: from all lookup local
5: from 192.168.2.100 lookup local100
32766: from all lookup main
32767: from all lookup default
Теперь немного о файрволе. С его помощью тоже возможно влиять на роутинг.
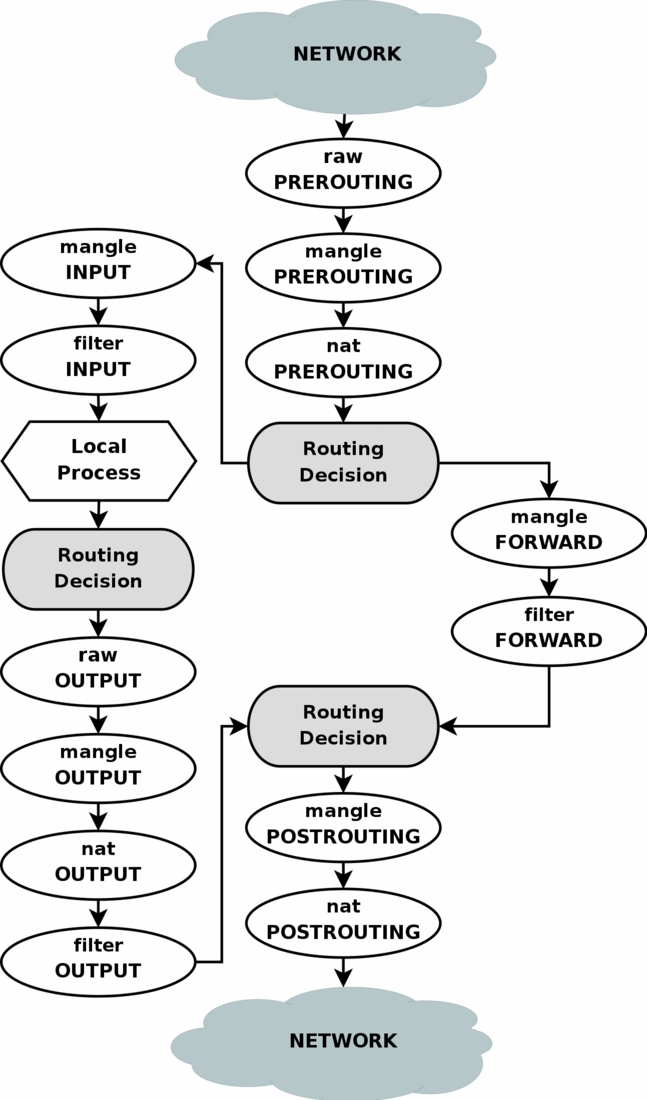
Как вы видите на схеме, пакеты от, например, локальных приложений проходят через этап «Routing Decision» дважды. Насколько я понимаю, первый раз это происходит в момент создания пакета, для того, чтобы определить для него исходящий интерфейс и исходящий IP (которые могут проверять правила файрвола, так что они должны быть уже известны когда пакет попадает в файрвол), плюс повторно роутинг для этого пакета вычисляется после выполнения цепочки MANGLE файрвола, которая могла изменить любые поля пакета, что могло повлиять на роутинг этого пакета.
В нашем случае самый простой способ влиять на роутинг через файрвол — изменять в цепочке MANGLE поле fwmark пакета, а потом с помощью правил роутинга выбирать таблицу роутинга на базе значения поля fwmark пакета (для этого потребуется создать несколько таблиц роутинга с разными правилами — например, в одной таблице прописать default route через одного провайдера, а в другой — через другого провайдера).
Настройка роутинга: конечный результат
Путь к этому конечному результату местами тернист (
Балансировка между двумя провайдерами
Для начала, настроим одновременное использование обоих провайдеров, с балансированием нагрузки в соотношении 8 к 2 (соответственно ширине каналов). Этот способ выбирает роутинг для каждого отдельного адреса назначения — т.е. если соединение изначально пошло через первого провайдера, то все его пакеты будут уходить только через первого провайдера, и все последующие соединения на этот адрес ещё некоторое время будут уходить только через этого провайдера. Балансировка не по соединениям а по пакета делается иначе, и будет работать только если у нас несколько соединений к одному провайдеру.
# ip route replace default scope global \
nexthop via <шлюз_isp1> dev ppp0 weight 8 \
nexthop via <шлюз_isp2> dev ppp1 weight 2
Т.к. ядро кеширует информацию о связи адресов назначения и выбранного для них роутинга по умолчанию, то может потребоваться сбросить этот кеш (чтобы ядро снова, с вероятностью 8 к 2, выбрало роутинг по умолчанию для этого адреса назначения):
# ip route flush cache
Ручной выбор канала для конкретных соединений
Т.к. в некоторых случаях нам необходимо контролировать, через какой из внешних каналов отправить пакет, создадим для каждого канала отдельную таблицу роутинга со своим default route:
# echo '1 isp1' >> /etc/iproute2/rt_tables
# echo '2 isp2' >> /etc/iproute2/rt_tables
# echo '3 vpn' >> /etc/iproute2/rt_tables
# ip route add default via <шлюз_isp1> dev ppp0 table isp1
# ip route add default via <шлюз_isp2> dev ppp1 table isp2
# ip route add default via <шлюз_vpn> dev tun0 table vpn
Теперь добавим правила роутинга так, чтобы с помощью файрвола выставив нужные значения fwmark мы могли выбрать нужную таблицу роутинга:
# ip rule add priority 100 fwmark 0x4/0x4 lookup vpn
# ip rule add priority 101 fwmark 0x1/0x1 lookup isp1
# ip rule add priority 102 fwmark 0x2/0x2 lookup isp2
Значение 0x4/0x4 (значение/маска) означает, что из поля fwmark будут взяты биты по маске 0x4 (т.е. только третий бит) которые должны совпасть со значением 0x4. Т.е. в fwmark должен быть выставлен третий бит чтобы сработало правило для таблицы vpn, а остальные биты значения не имеют. Такой подход позволяет в файрволе выставить несколько битов в fwmark, указав таким образом несколько «подходящих» каналов для этого пакета. Приоритет этих каналов (если они все доступны) задаётся приоритетом правил роутинга. Если какой-то канал недоступен, то соответствующая таблица роутинга всё-равно будет просмотрена, но в ней не окажется default route, поэтому произойдёт возврат к следующим правилам роутинга и будет найден следующий подходящий канал.
Все эти команды пока что ни на что не повлияли — файрвол fwmark не выставляет, значит правила роутинга для таблиц isp1, isp2 и vpn не срабатывают, а по умолчанию роутинг как и раньше определяется таблицей main:
# ip route list ### "table main" можно не указывать
<шлюз_vpn> dev tun0 proto kernel scope link src <v.v.v.v>
<шлюз_isp1> dev ppp0 proto kernel scope link src <s.s.s.s>
<шлюз_isp2> dev ppp1 proto kernel scope link src <d.d.d.d>
192.168.2.0/24 dev eth2 proto kernel scope link src 192.168.2.1
192.168.1.0/24 dev eth1 proto kernel scope link src 192.168.1.2
192.168.0.0/24 dev eth0 proto kernel scope link src 192.168.0.2
127.0.0.0/8 via 127.0.0.1 dev lo scope link
default
nexthop via <шлюз_isp1> dev ppp0 weight 8
nexthop via <шлюз_isp2> dev ppp1 weight 2
# ip route list table isp1
default via <шлюз_isp1> dev ppp0
# ip route list table isp2
default via <шлюз_isp2> dev ppp1
# ip route list table vpn
default via <шлюз_vpn> dev tun0
# ip rule list
0: from all lookup local
100: from all fwmark 0x4/0x4 lookup vpn
101: from all fwmark 0x1/0x1 lookup isp1
102: from all fwmark 0x2/0x2 lookup isp2
32766: from all lookup main
32767: from all lookup default
Теперь мы можем указать, что доступ к веб-сайту со статистикой и контрольной панелью второго провайдера должен идти через второй ADSL:
# iptables -t mangle -A OUTPUT -d <ip_сайта_isp2>/32 -j MARK --set-mark 0x2
Если необходимо, чтобы эти правила работали не только для пакетов исходящих с нашего сервера, но и для пакетов из домашней локалки, то необходимо все эти правила в файрвол добавлять не только в цепочку OUTPUT, но и в цепочку FORWARD.
Ответ с того же интерфейса
Всё это будет отлично работать пока речь идёт только об исходящих соединениях. Но ведь у нас сервер… а к серверу бывают и входящие соединения. Допустим, у нас поднят веб-сайт на статическом IP s.s.s.s (канал первого провайдера). Теперь, если админ второго провайдера с сервера <ip_сайта_isp2> захочет заглянуть (через lynx) на наш веб-сайт, у него ничего не выйдет! Дело в том, что он пошлёт запрос на наш IP s.s.s.s (на котором веб-сайт) через канал нашего первого провайдера, а ответ на этот запрос наш сервер отправит через канал второго провайдера (и, соответственно, с адреса d.d.d.d — у нас ведь, разумеется, настроен SNAT/MASQUERADE пакетов исходящих через интерфейсы ppp0, ppp1 и tun0) — согласно настройкам файрвола, которые мы только что сделали: пакеты на адрес <ip_сайта_isp2> отправлять через канал второго провайдера. Веб-браузер админа, пославший запрос на адрес s.s.s.s никак не ожидает получить ответ с адреса d.d.d.d, так что работать это не будет.
Чтобы решить эту проблему, необходимо гарантировать ответы на входящие соединения с того интерфейса, с которого изначально были приняты пакеты. Для этого, к сожалению, придётся использовать отслеживание соединений файрволом (conntrack) для выставления fwmark (connmark). К сожалению — потому, что conntrack это большая сложная и глючная фигня, но выбора здесь нет. Делается это так (эти правила надо добавить в файрвол первыми, ДО правил устанавливающих fwmark вроде описанного выше):
# iptables -t mangle -A INPUT -i ppp0 -j CONNMARK --set-mark 0x1
# iptables -t mangle -A INPUT -i ppp1 -j CONNMARK --set-mark 0x2
# iptables -t mangle -A INPUT -i tun0 -j CONNMARK --set-mark 0x4
# iptables -t mangle -A INPUT -i eth+ -j CONNMARK --set-mark 0x8
# iptables -t mangle -A OUTPUT -j CONNMARK --restore-mark
# iptables -t mangle -A OUTPUT -m mark ! --mark 0x0 -j ACCEPT
Здесь мы маркируем входящие пакеты (точнее, соединения, к которым они относятся) согласно интерфейсам, с которых они пришли. Причем значение fwmark (точнее, connmark) выбираем такое, чтобы оно соответствовало таблице роутинга, через которую нужно отправлять ответы на эти пакеты (1,2,4 — для isp1, isp2 и vpn; 8 — это не используемый в правилах роутинга fwmark, т.е. пакеты с этим fwmark будут отправлены согласно обычному роутингу в таблице main — для пакетов из локальных сетей это вполне подходит).
На роутинг входящих пакетов эта маркировка никак не влияет, но это позволяет нам фактически привязать эту маркировку ко всем пакетам этого соединения, в т.ч. исходящим пакетам. Далее, для исходящих пакетов на этом же соединении (ответов на входящие пакеты) мы устанавливаем значение fwmark в то же значение, которое было у входящих пакетов и которое привязано к этому соединению (точнее, копируем значение connmark в fwmark). И если в результате у исходящих пакетов значение fwmark оказывается установлено (не 0), значит все последующие правила установки fwmark для выбора исходящего канала применять нельзя — этот пакет необходимо отправить через тот же интерфейс, через которых пришёл входящий пакет, поэтому останавливаемся (-j ACCEPT).
Итого, корректный вариант настройки файрвола согласно нашей постановке задачи выглядит так:
# iptables -t mangle -A INPUT -i ppp0 -j CONNMARK --set-mark 0x1
# iptables -t mangle -A INPUT -i ppp1 -j CONNMARK --set-mark 0x2
# iptables -t mangle -A INPUT -i tun0 -j CONNMARK --set-mark 0x4
# iptables -t mangle -A INPUT -i eth+ -j CONNMARK --set-mark 0x8
# iptables -t mangle -A OUTPUT -j CONNMARK --restore-mark
# iptables -t mangle -A OUTPUT -m mark ! --mark 0x0 -j ACCEPT
# iptables -t mangle -A OUTPUT -p tcp -m tcp --dport 25 -j MARK --set-mark 0x1
# iptables -t mangle -A OUTPUT -d <ip_сервера_vpn>/32 -p udp -m udp --dport 1130 -j MARK --set-mark 0x1
# iptables -t mangle -A OUTPUT -d <ip_сайта_isp2>/32 -j MARK --set-mark 0x2
Вместе с настройками правил и таблиц роутинга мы получаем именно то, что нам требовалось. Осталось разобраться, как эти настройки устанавливать в динамике, с учётом того, что каналы могут падать и подниматься.
Тернистый путь к конечному результату
Честно говоря, статья получилась и так немаленькая, поэтому дополнительно загромождать её своими ip-up/down скриптами, как собирался, я сейчас не буду. Если кто-то попросит в комментариях — добавлю в статью позже. А сейчас кратко опишу основные задачи и проблемы, возникшие при реализации вышеописанных настроек.
- pppd не умеет сам поднимать множественный default route, поэтому его необходимо запускать с опцией nodefaultroute, и устанавливать default route ручками в /etc/ppp/ip-{up,down} скриптах (или пользовательских скриптах, вызываемых автоматически из этих скриптов — в разных дистрибутивах это настроено по-разному).
- Поскольку каналы поднимаются по одному, то в момент вызова скрипта ip-up может не быть никакого default route (этот канал поднялся первым) и тогда он должен установить обычный одиночный default route через этот канал; а может уже существовать default route через другой канал (этот канал поднялся вторым), и тогда ему нужно заменить одиночный default route на двойной (с nexthop-ами и weight) — это делается в таблице роутинга main.
- Так же необходимо добавить одиночный default route через этот канал в соответствующую таблицу роутинга (isp1 или isp2).
- В скрипте ip-down, по логике, надо проделать обратную операцию (если отключился один из двух каналов, то нужно двойной default route заменить на обычный через оставшийся канал, если отключился последний канал то нужно вообще удалить default route)… Но на практике pppd сам удаляет default route, даже если он был двойной и даже если pppd запускался с опцией nodefaultroute (вероятно, это баг в pppd). Поэтому задача в ip-down обратная: если это был не единственный канал, то поднять обычный default route через оставшийся канал. К сожалению, здесь тоже не всё просто: pppd удаляет default route параллельно с выполнением скрипта ip-down, т.е. возникает race condition! Так что в ip-down надо сначала дождаться, пока pppd удалит default route, а уже потом поднимать его снова.
- После внесения изменений в роутинг (и в ip-up и в ip-down) не помешает сделать ip route flush cache.
- Ещё одно: оба канала могут подниматься/падать одновременно, и их ip-up/down скрипты тоже могут сработать одновременно. Чаще всего это будет приводить к race condition и порче default route. :) Поэтому необходимо обеспечить блокировку при запуске этих скриптов, гарантирующую, что только один из них будет работать в один момент времени — проще всего это реализовать через утилиту chpst из пакета runit или утилиту setlock из пакета daemontools.
- openvpn тоже умеет вызывать пользовательские up/down скрипты...
- В up необходимо добавить одиночный default route через этот канал в соответствующую таблицу роутинга (vpn).
- После внесения изменений в роутинг (и в up и в down) не помешает сделать ip route flush cache.
- В down в этой конфигурации ничего не требуется (default route из таблицы vpn будет удалён ядром автоматически когда упадёт этот канал), но если что-то потребуется сделать, то имейте в виду, что up скрипт запускается от root, а down от юзера openvpn (или какого вы там указали в настройках openvpn) (это вероятно тоже баг), а юзер openvpn обычно не имеет достаточно прав чтобы управлять роутингом (приходится использовать sudo).
