Есть задачи, которые в рамках реляционных СУБД не имеют универсальных решений и для того чтобы получить хоть какой-то приемлемый результат, приходится придумывать целый набор костылей, который ты потом гордо называешь “Архитектура”. Не так давно мне как раз встретилась именно такая.
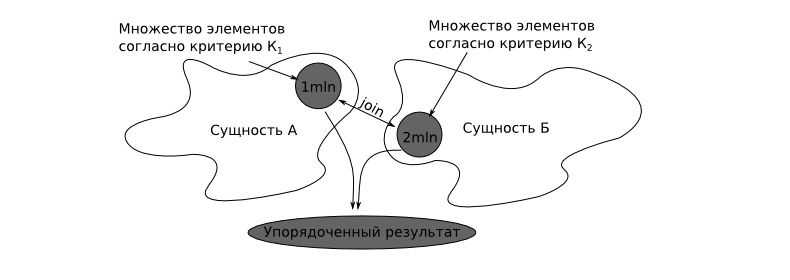
Предположим, имеется некоторые сущности А и Б, связанные между собой по принципу One-to-Many. Количество экземпляров данных сущностей достаточно велико. При отображении сущностей для пользователя необходимо применить ряд независимых критериев, как для сущности А так и для сущности Б. Причем результатом применения критериев являются множества достаточно большой мощности — порядка нескольких миллионов записей. Критерии фильтрации и принцип сортировки задается пользователем. Как (я бы ещё спросил: Зачем им миллионы записей на одном экране? — но говорят надо) показать все это пользователю за время 0 секунд?
Решать такие задачи всегда интересно, но их решение сильно зависит от СУБД, под управлением которой крутится твоя база данных. Если у тебя в рукаве козырной туз в виде Oracle, то есть шанс, что эти костыли он подставит сам. Но спустимся на землю — у нас есть только MySQL, так что придется почитать теорию.
Используя sql задачу можно сформулировать следующим образом:
План запроса в лоб не утешает.
Перед тем как городить кучу ненужных индексов, давайте проведем анализ, возможно ли вообще решить такую задачу на основании 2-х таблиц. Пусть первая таблица хранит характеристики сущности, а вторая — сами её детали. Обычно для обеспечения ссылочной целостности приходится пользоваться констрейнтами, однако если у вас имеются две таблицы подобного рода с большими объемами данных и постоянным DML’ингом, я бы не советовал это делать по причине Not a BUG#15136. И перевод базы в режим read committed с явным выставлением опасного параметра innodb_locks_unsafe_for_binlog в значение true, вас не спасет. Ну это так, к слову, вернемся к нашим баранам. Для начала посмотрим в документацию — какие у нас есть возможности по ускорению order by.
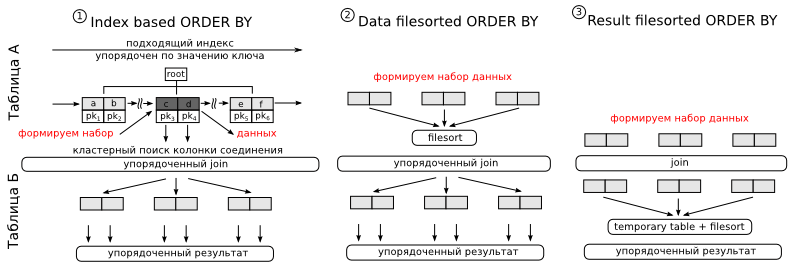
Вариант 1. Предположим у нас имеется индекс, первыми полями в котором идут колонки перечисленные в where, а последним колонка по которой делается сортировка. Так как данные в индексе хранятся в отсортированном виде, MySQL может использовать его для оптимизации сортировки. Алгоритм работы будет следующий. Применяя предикаты доступа, находим нужные нам участки индекса. В плане вы увидите либо range, либо ref, либо index в колонке type. Получая очередную порцию данных, в режиме runtime, читаем остальные колонки необходимые нам для выполнения join (ибо в индексе может и не быть всех нужных колонок, что звучит логично) и производим соединения со следующей таблицей. Так как данные из индекса мы читаем упорядоченно, то и на выходе такого join’а данные будут получаться в упорядоченном виде. При получении нужного количества данных, чтение индекса можно остановить. Для нас главным минусом этого подхода будет то, что колонки по которым производится поиск и колонка по которой производится сортировка — находятся в разных таблицах. Так что придется делать денормализацию.
Варианты 2 и 3 подходят только для случая, когда объем данных для соединения невелик, т.е. они подойдут только для высокоселективных колонок. В варианте два мы в начале сортируем полученные результаты, а затем производим join, в варианте же три, сортировка делается уже после джойна. Так как сортировка производимая MySQL может выполняться только над одной таблицей — в третьем случае требуется temporary table. Это не страшно, но может сильно затянуться. Однако третий случай — это единственно возможный вариант, когда MySQL может применить различные оптимизации для ускорения join’а. В первых двух случаях это будет nested loops. В плане выполнения эти сортировки будут отличаться следующим образом:
При втором и третьем способе сортировке limit может быть применен только по окончании процесса сортировки, по этой причине варианты 2 и 3 не получися использовать во всех случаях.
Загадочный filesort — это не что иное как quick sort слиянием.
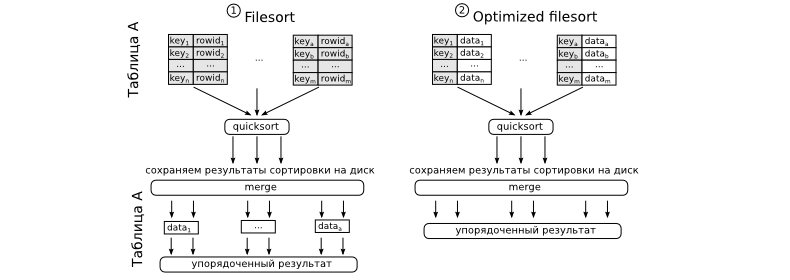
Сортировка может производится двумя способами. Первый — в начале делается сортировка, а потом читаются остальные данные из таблицы необходимые для окончания запроса. Второй вариант, считается оптимизированным, потому что таблица зачитывается один раз, вместе со всеми необходимыми столбцами, а затем уже сортируется. По плану вы их не сможете отличить друг от друга, однако путем быстрого эксперимента, это сделать возможно. Зато будет или нет применена оптимизированная сортировка отвечает параметр max_length_for_sort_data. Если данные, которые содержаться в кортежах меньше чем указанно в этом параметре, то сортировка будет оптимизирована.
Как видно из примера, сортировка по алгоритму номер 2 действительно в два раза быстрее, ибо читает в 2 раза меньше строк. Однако надо иметь ввиду, что оптимизированная сортировка требует значительных затрат памяти, и если выставить значение переменной max_length_for_sort_data в слишком высокое значение, то вы получите большой ввод вывод при полном простое процессора.
Итак, воспользуемся всей силой имеющихся решений. Делаем денормализацию (как вы её будете поддерживать, это уже другой вопрос). И строим составные индексы для неселективных колонок и обычные для высокоселективных. Таким образом, сортировка по индексу и ограничение по лимиту будет использоваться при запросах, в критериях которых участвуют только низко селективные колонки, а для высокоселективных будут использоваться более компактые и быстрые индексы с последующим однопроходным filesort без слияния.
К сожалению, после денормализации мы получили один недостаток. Постраничная верстка может раскидать детали одной сущности по разным страницам. Этого мы допустить не можем, поэтому предлагаю ставить костели дальше. Вместо того чтобы выбирать все необходимые данные сразу — выбираем только идентификаторы сущности А, с условием всех критериев, добавляем на конструкцию limit для пейджинга, а затем подцепляем детали сущности.
Признаюсь честно, в моем уме конструкция вида distinct + order by + limit по таблице таких объемов не может работать быстро, однако, разработчики MySQL думают по другому. При работе над данным вопросом, я натолкнулся на баг Not a BUG#33087, который как обычно оказался не багом, а фичей. После этого я решил понять, а как же MySQL оптимизирует distinct. Первой фразой в документации было: для оптимизации distinct могут использоваться все те же оптимизации, что используются и для group by. Тотально группировка может производится по двум алгоритмам.

Первый случай может быть применен только если имеется индекс, который задает группировку автоматически. Вторая схема используется во всех остальных случаях. Индексная группировка выполняется последовательно и может быть лимитирована — и это очень хорошо для нас, так как это именно что нам надо для вывода результатов по низко селективным индексам. Временные таблицы при таком подходе не используются (честно говоря это не совсем правда, так как в общем случае вам надо хранить результаты частичного джойна, а так же сами значения полученные в результате группировки для текущей группы, но это мелочи). Вторая схема работает ужасно медленно и жрет кучу оперативной памяти, так как все результаты группировки должны быть сохранены во временной таблицы, первичным ключом в которой является идентификатор группы. При очень больших значениях эта таблица преобразуется в MyISAM и сбрасывается на диск. Все новопоступающие группы вначале ищутся в этой большой таблице, а потом меняют в ней значения, если это необходимо или же добавляют новую строку, если группа не найдена. Конечная сортировка добивает производительность данного алгоритма. Именно по этой причине, если вам не нужен упорядоченный набор, часто рекомендуют добавлять order by null.
Таким образом, первый подход, а так же то, что MySQL перестает дальнейший поиск данных если совместно с distinct используется конструкция limit, и позволяет нам получать результат группировки очень быстро.
Итак, мы получили алгоритм, который быстро находит первые записи, но данный алгоритм не может нам посчитать общее количество записей. В качестве обходного решения можно возвращать на одну запись больше, чтобы на экране пользователю показалась кнопочка Next.
MySQL не умеет использовать более одного индекса в запросе, для одной таблицы. Чем нам это грозит? Попробуем выполнить запрос типа:
Поверьте вы не дождетесь его окончания, так как если вы посмотрите на данные, вы увидите там специально сформированный провал. Множество удовлетворяющее критерию det_low_selective_column = 0 не имеет пересечений со множеством, удовлетворяющем критерию low_selective_column = 1. Это знаем мы, но к сожалению, MySQL об этом ничего не знает. Поэтому он выбирает индекс, который по его мнению наиболее подходит для сканирования и делает полный скан 2-х индексов, выбранного и PK. Это убийственно долго так как сканирование первичного ключа, это фактически полное сканирование таблицы ввиду её кластерной организации. Все такие гэпы необходимо обрулить составными индексами.
И наконец, самый неприятный момент. InnoDB использует всего один мьютекс на каждый индекс. Поэтому, когда вы вперемешку запускаете запросы, которые пишут и читают данные одновременно, InnoDB engine блокирует индекс, приостанавливая операции чтения, так как операция записи может вызвать расщепление B-Tree и искомые записи могут оказаться в другой странице. Умные БД блокируют не все дерево, а лишь его расщепляемую часть. В MySQL данный алгоритм пока не реализован (хотя можно посмотреть InnoDB plugin на эту тему, в 5.5 он вроде как стал стандартом, может там все не так плохо). Для того чтобы обойти эту проблему, необходимо разделять данные, то есть использовать partitions. Все индексы в партиционных таблицах являются локально партиционированными, фактически каждая партиция в этом плане представляет собой отдельную таблицу, но партиционирование это уже другая история и в этой статье я её затрагивать не буду.
Решение ряда проблем, которые нам подкидывает суровая действительность, невозможно описать в двух словах. Проблема многокритериального поиска по нескольким множествам — одна из них. Можно воспользоваться Сфинкс и загрузить ряд шаблонов, предоставляемых данным сообществом, но рано или поздно вы все равно столкнетесь с проблемой, решения к которой никто за вас не придумал. И вот, тогда вам придется лезть в документацию, изучать данные и уговаривать пользователей этого не делать. Надеюсь, эта обзорная статья позволит вам избежать некоторых подводных камней, которые ожидают вас на этом тернистом пути.
З.Ы. ряд оптимизаций для group by пришлось опустить, ибо статья и так получилась очень большой. Почитать про них можно в официально документации, а так же ряд практических советов, для полного понимая проблематики.
* All code sources were highlighted with Source Code Highlighter.

Предположим, имеется некоторые сущности А и Б, связанные между собой по принципу One-to-Many. Количество экземпляров данных сущностей достаточно велико. При отображении сущностей для пользователя необходимо применить ряд независимых критериев, как для сущности А так и для сущности Б. Причем результатом применения критериев являются множества достаточно большой мощности — порядка нескольких миллионов записей. Критерии фильтрации и принцип сортировки задается пользователем. Как (я бы ещё спросил: Зачем им миллионы записей на одном экране? — но говорят надо) показать все это пользователю за время 0 секунд?
Решать такие задачи всегда интересно, но их решение сильно зависит от СУБД, под управлением которой крутится твоя база данных. Если у тебя в рукаве козырной туз в виде Oracle, то есть шанс, что эти костыли он подставит сам. Но спустимся на землю — у нас есть только MySQL, так что придется почитать теорию.
Используя sql задачу можно сформулировать следующим образом:
drop table if exists pivot;
drop table if exists entity_details;
drop table if exists entity;
create table pivot
(
row_number int(4) unsigned auto_increment,
primary key pk_pivot (row_number)
)
engine = innodb;
insert into pivot(row_number)
select null
from information_schema.global_status g1, information_schema.global_status g2
limit 500;
create table entity(entt_id int(10) unsigned auto_increment,
order_column datetime,
high_selective_column int(10) unsigned not null,
low_selective_column int(10) unsigned not null,
data_column varchar(32),
constraint pk_entity primary key(entt_id)
)
engine = innodb;
create table entity_details(edet_id int(10) unsigned auto_increment,
det_high_selective_column int(10) unsigned not null,
det_low_selective_column int(10) unsigned not null,
det_data_column varchar(32),
entt_entt_id int(10) unsigned,
constraint pk_entity_details primary key(edet_id)
)
engine = innodb;
insert into entity(order_column,
high_selective_column,
low_selective_column,
data_column
)
select date_add(str_to_date("20000101", "%Y%m%d"),
interval (p1.row_number + (p2.row_number - 1) * 300 + (p3.row_number - 1) * 300 * 300) second
)
order_column,
round((p1.row_number + (p2.row_number - 1) * 300 + (p3.row_number - 1) * 300 * 300) / 3, 0)
high_selective_column,
(p1.row_number + (p2.row_number - 1) * 300 + (p3.row_number - 1) * 300 * 300) mod 10 low_selective_column,
p1.row_number + (p2.row_number - 1) * 300 + (p3.row_number - 1) * 300 * 300 data_column
from (select * from pivot limit 300) p1,
(select * from pivot limit 300) p2,
(select * from pivot limit 300) p3;
insert into entity_details(det_high_selective_column,
det_low_selective_column,
det_data_column,
entt_entt_id
)
select e.high_selective_column + p.row_number det_high_selective_column,
case when e.low_selective_column = 0 then 0 else p.row_number end det_low_selective_column,
concat(e.data_column, ' det') det_data_column,
e.entt_id
from entity e,
(select * from pivot limit 2) p;
create index idx_entity_details_entt
on entity_details(entt_entt_id);
select *
from entity_details ed, entity e
where ed.entt_entt_id = e.entt_id
order by order_column desc
limit 0, 10;
План запроса в лоб не утешает.
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | e | ALL | PRIMARY | 26982790 | Using filesort | |||
| 1 | SIMPLE | ed | ref | idx_entity_details_entt | idx_entity_details_entt | 5 | test.e.entt_id | 1 | Using where |
Перед тем как городить кучу ненужных индексов, давайте проведем анализ, возможно ли вообще решить такую задачу на основании 2-х таблиц. Пусть первая таблица хранит характеристики сущности, а вторая — сами её детали. Обычно для обеспечения ссылочной целостности приходится пользоваться констрейнтами, однако если у вас имеются две таблицы подобного рода с большими объемами данных и постоянным DML’ингом, я бы не советовал это делать по причине Not a BUG#15136. И перевод базы в режим read committed с явным выставлением опасного параметра innodb_locks_unsafe_for_binlog в значение true, вас не спасет. Ну это так, к слову, вернемся к нашим баранам. Для начала посмотрим в документацию — какие у нас есть возможности по ускорению order by.
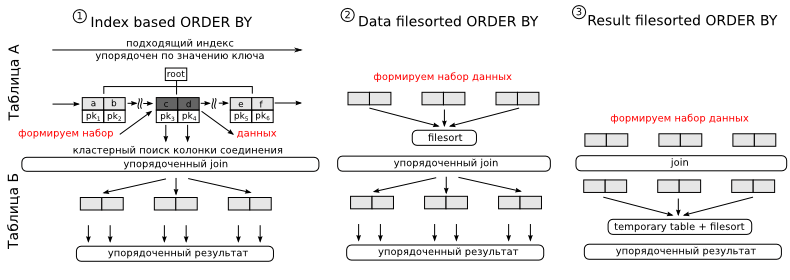
Вариант 1. Предположим у нас имеется индекс, первыми полями в котором идут колонки перечисленные в where, а последним колонка по которой делается сортировка. Так как данные в индексе хранятся в отсортированном виде, MySQL может использовать его для оптимизации сортировки. Алгоритм работы будет следующий. Применяя предикаты доступа, находим нужные нам участки индекса. В плане вы увидите либо range, либо ref, либо index в колонке type. Получая очередную порцию данных, в режиме runtime, читаем остальные колонки необходимые нам для выполнения join (ибо в индексе может и не быть всех нужных колонок, что звучит логично) и производим соединения со следующей таблицей. Так как данные из индекса мы читаем упорядоченно, то и на выходе такого join’а данные будут получаться в упорядоченном виде. При получении нужного количества данных, чтение индекса можно остановить. Для нас главным минусом этого подхода будет то, что колонки по которым производится поиск и колонка по которой производится сортировка — находятся в разных таблицах. Так что придется делать денормализацию.
Варианты 2 и 3 подходят только для случая, когда объем данных для соединения невелик, т.е. они подойдут только для высокоселективных колонок. В варианте два мы в начале сортируем полученные результаты, а затем производим join, в варианте же три, сортировка делается уже после джойна. Так как сортировка производимая MySQL может выполняться только над одной таблицей — в третьем случае требуется temporary table. Это не страшно, но может сильно затянуться. Однако третий случай — это единственно возможный вариант, когда MySQL может применить различные оптимизации для ускорения join’а. В первых двух случаях это будет nested loops. В плане выполнения эти сортировки будут отличаться следующим образом:
| Использование индекса для сортировки | Пусто |
| Использование filesort для таблицы A | “Using filesort” |
| Сохранению результатов JOIN во временную таблицу и использование filesort | “Using temporary; Using filesort” |
При втором и третьем способе сортировке limit может быть применен только по окончании процесса сортировки, по этой причине варианты 2 и 3 не получися использовать во всех случаях.
Загадочный filesort — это не что иное как quick sort слиянием.

Сортировка может производится двумя способами. Первый — в начале делается сортировка, а потом читаются остальные данные из таблицы необходимые для окончания запроса. Второй вариант, считается оптимизированным, потому что таблица зачитывается один раз, вместе со всеми необходимыми столбцами, а затем уже сортируется. По плану вы их не сможете отличить друг от друга, однако путем быстрого эксперимента, это сделать возможно. Зато будет или нет применена оптимизированная сортировка отвечает параметр max_length_for_sort_data. Если данные, которые содержаться в кортежах меньше чем указанно в этом параметре, то сортировка будет оптимизирована.
drop procedure if exists pbenchmark_filesort;
delimiter $$
create procedure pbenchmark_filesort(i_repeat_count int(10))
main_sql:
begin
declare v_variable_value int(10);
declare v_loop_counter int(10) unsigned default 0;
declare continue handler for sqlstate '42S01' begin
end;
create temporary table if not exists temp_sort_results(
row_number int(10) unsigned
)
engine = memory;
truncate table temp_sort_results;
select variable_value
into v_variable_value
from information_schema.session_status
where variable_name = 'INNODB_ROWS_READ';
begin_loop:
loop
set v_loop_counter = v_loop_counter + 1;
if v_loop_counter <= i_repeat_count then
insert into temp_sort_results(row_number)
select sql_no_cache row_number from pivot order by concat(row_number, '0') asc;
truncate table temp_sort_results;
iterate begin_loop;
end if;
leave begin_loop;
end loop begin_loop;
select variable_value - v_variable_value records_read
from information_schema.session_status
where variable_name = 'INNODB_ROWS_READ';
end
$$
delimiter ;
set session max_length_for_sort_data = 0;
call pbenchmark_filesort(10000);
-- records_read
-- 10 000 000
-- 0:00:12.317 Query OK
set session max_length_for_sort_data = 1024;
call pbenchmark_filesort(10000);
-- records_read
-- 5 000 000
-- 0:00:06.228 Query OK
Как видно из примера, сортировка по алгоритму номер 2 действительно в два раза быстрее, ибо читает в 2 раза меньше строк. Однако надо иметь ввиду, что оптимизированная сортировка требует значительных затрат памяти, и если выставить значение переменной max_length_for_sort_data в слишком высокое значение, то вы получите большой ввод вывод при полном простое процессора.
Итак, воспользуемся всей силой имеющихся решений. Делаем денормализацию (как вы её будете поддерживать, это уже другой вопрос). И строим составные индексы для неселективных колонок и обычные для высокоселективных. Таким образом, сортировка по индексу и ограничение по лимиту будет использоваться при запросах, в критериях которых участвуют только низко селективные колонки, а для высокоселективных будут использоваться более компактые и быстрые индексы с последующим однопроходным filesort без слияния.
create table entity_and_details(entt_entt_id int(10) unsigned not null,
edet_edet_id int(10) unsigned not null,
order_column datetime,
high_selective_column int(10) unsigned not null,
low_selective_column int(10) unsigned not null,
det_high_selective_column int(10) unsigned not null,
det_low_selective_column int(10) unsigned not null,
constraint pk_entity_and_details primary key(entt_entt_id, edet_edet_id)
)
engine = innodb;
insert into entity_and_details(entt_entt_id,
edet_edet_id,
order_column,
high_selective_column,
low_selective_column,
det_high_selective_column,
det_low_selective_column
)
select entt_id,
edet_id,
order_column,
high_selective_column,
low_selective_column,
det_high_selective_column,
det_low_selective_column
from entity_details ed, entity e
where ed.entt_entt_id = e.entt_id;
create index idx_entity_and_details_low_date
on entity_and_details(low_selective_column, order_column);
create index idx_entity_and_details_det_low_date
on entity_and_details(det_low_selective_column, order_column);
create index idx_entity_and_details_date
on entity_and_details(order_column);
create index idx_entity_and_details_high
on entity_and_details(high_selective_column);
create index idx_entity_and_details_det_high
on entity_and_details(det_high_selective_column);
К сожалению, после денормализации мы получили один недостаток. Постраничная верстка может раскидать детали одной сущности по разным страницам. Этого мы допустить не можем, поэтому предлагаю ставить костели дальше. Вместо того чтобы выбирать все необходимые данные сразу — выбираем только идентификаторы сущности А, с условием всех критериев, добавляем на конструкцию limit для пейджинга, а затем подцепляем детали сущности.
select distinct entt_entt_id
from entity_and_details
where det_low_selective_column = 0
order by order_column
limit 0, 3;
select *
from entity_and_details
where entt_entt_id in (10, 20, 30);
Признаюсь честно, в моем уме конструкция вида distinct + order by + limit по таблице таких объемов не может работать быстро, однако, разработчики MySQL думают по другому. При работе над данным вопросом, я натолкнулся на баг Not a BUG#33087, который как обычно оказался не багом, а фичей. После этого я решил понять, а как же MySQL оптимизирует distinct. Первой фразой в документации было: для оптимизации distinct могут использоваться все те же оптимизации, что используются и для group by. Тотально группировка может производится по двум алгоритмам.

Первый случай может быть применен только если имеется индекс, который задает группировку автоматически. Вторая схема используется во всех остальных случаях. Индексная группировка выполняется последовательно и может быть лимитирована — и это очень хорошо для нас, так как это именно что нам надо для вывода результатов по низко селективным индексам. Временные таблицы при таком подходе не используются (честно говоря это не совсем правда, так как в общем случае вам надо хранить результаты частичного джойна, а так же сами значения полученные в результате группировки для текущей группы, но это мелочи). Вторая схема работает ужасно медленно и жрет кучу оперативной памяти, так как все результаты группировки должны быть сохранены во временной таблицы, первичным ключом в которой является идентификатор группы. При очень больших значениях эта таблица преобразуется в MyISAM и сбрасывается на диск. Все новопоступающие группы вначале ищутся в этой большой таблице, а потом меняют в ней значения, если это необходимо или же добавляют новую строку, если группа не найдена. Конечная сортировка добивает производительность данного алгоритма. Именно по этой причине, если вам не нужен упорядоченный набор, часто рекомендуют добавлять order by null.
Таким образом, первый подход, а так же то, что MySQL перестает дальнейший поиск данных если совместно с distinct используется конструкция limit, и позволяет нам получать результат группировки очень быстро.
Теперь о неприятном
Итак, мы получили алгоритм, который быстро находит первые записи, но данный алгоритм не может нам посчитать общее количество записей. В качестве обходного решения можно возвращать на одну запись больше, чтобы на экране пользователю показалась кнопочка Next.
MySQL не умеет использовать более одного индекса в запросе, для одной таблицы. Чем нам это грозит? Попробуем выполнить запрос типа:
select distinct entt_entt_id
from entity_and_details
where det_low_selective_column = 0 and low_selective_column = 1
order by order_column
limit 0, 3;Поверьте вы не дождетесь его окончания, так как если вы посмотрите на данные, вы увидите там специально сформированный провал. Множество удовлетворяющее критерию det_low_selective_column = 0 не имеет пересечений со множеством, удовлетворяющем критерию low_selective_column = 1. Это знаем мы, но к сожалению, MySQL об этом ничего не знает. Поэтому он выбирает индекс, который по его мнению наиболее подходит для сканирования и делает полный скан 2-х индексов, выбранного и PK. Это убийственно долго так как сканирование первичного ключа, это фактически полное сканирование таблицы ввиду её кластерной организации. Все такие гэпы необходимо обрулить составными индексами.
И наконец, самый неприятный момент. InnoDB использует всего один мьютекс на каждый индекс. Поэтому, когда вы вперемешку запускаете запросы, которые пишут и читают данные одновременно, InnoDB engine блокирует индекс, приостанавливая операции чтения, так как операция записи может вызвать расщепление B-Tree и искомые записи могут оказаться в другой странице. Умные БД блокируют не все дерево, а лишь его расщепляемую часть. В MySQL данный алгоритм пока не реализован (хотя можно посмотреть InnoDB plugin на эту тему, в 5.5 он вроде как стал стандартом, может там все не так плохо). Для того чтобы обойти эту проблему, необходимо разделять данные, то есть использовать partitions. Все индексы в партиционных таблицах являются локально партиционированными, фактически каждая партиция в этом плане представляет собой отдельную таблицу, но партиционирование это уже другая история и в этой статье я её затрагивать не буду.
Заключение
Решение ряда проблем, которые нам подкидывает суровая действительность, невозможно описать в двух словах. Проблема многокритериального поиска по нескольким множествам — одна из них. Можно воспользоваться Сфинкс и загрузить ряд шаблонов, предоставляемых данным сообществом, но рано или поздно вы все равно столкнетесь с проблемой, решения к которой никто за вас не придумал. И вот, тогда вам придется лезть в документацию, изучать данные и уговаривать пользователей этого не делать. Надеюсь, эта обзорная статья позволит вам избежать некоторых подводных камней, которые ожидают вас на этом тернистом пути.
З.Ы. ряд оптимизаций для group by пришлось опустить, ибо статья и так получилась очень большой. Почитать про них можно в официально документации, а так же ряд практических советов, для полного понимая проблематики.
* All code sources were highlighted with Source Code Highlighter.
