Давайте поговорим о строках, точнее об их переворачивании средствами .Net/C#. Так уж сложилось, что в стандартной библиотеке соответсвующей функции не наблюдается. И как мне подсказывают, написание функции обращения строки довольно популярный вопрос на собеседованиях при приеме на работу. Давайте посмотрим, как можно эффективно перевернуть строку средствами данной платформы.
Под катом приведен сравнительный анализ быстродействия разных методов переворачивания строки.
Кхрр-р-р… — сказала бензопила.
Тююю… — сказали мужики.
© Старый анекдот.
Ну что ж, начнем. Все реализации проверялись на быстродействие с одной строкой размером 256 мегабайт (128×1024×1024 символа) и 1024×1024 строками размером 256 байт (128 символов). Перед каждым замером форсировалась сборка мусора (что важно при таком размере тестовых данных), замер проводился 50 раз, 20 крайних отбрасывались, остальные значения усреднялись. Условными попугаями было выбрано количество тиков, выдаваемое объектом класса Stopwatch.
Тест проводился на двух компьютерах: Athlon64 x2 4200+, 2GB Dual-Channel DDR2 RAM и Pentium4 HT 3GHz, 3GB DDR RAM. Главным отличием между конфигурациями в данном тесте является быстродействие связки память-кэш — вторая система в этом отношении заметно медленнее.
С техническими формальностями покончено, теперь перейдем к собственно реализациям. Для большей наглядности, здесь не учтены unicode surrogate code points. Рассматривать подходы будем в порядке логичности и «красивости» реализации в контексте окружающей ее «экосистемы».
Сравнительные результаты замеров находятся в последней части этой заметки. Оптимальной в общем случае оказалась функция ReverseUnsafeCopy, если же ограничиваться только safe code — ReverseArrayManual. Если необходим safe code и огромные строки — прийдется мучаться с ReverseStringBuilder.
Будем следовать рекомендациям и для построения «большой» строки возьмем специальный инструмент — класс StringBuilder. Идея проста до ужаса: создаем builder нужного размера и идем по строке в обратном порядке, добавляя символы в новую строку.
Пробуем, запускаем, да… Как-то медленно работает это все, будем копать дальше.
Ха! Так этот билдер же обставлен проверками для обеспечения потокобезопасности со всех сторон, не, нам такое не надо. Но строка — это ведь массив сиволов. Так давайте его и перевернем, а результат преобразуем обратно в строку:
Совсем другое дело, получилось в 3.5 раза быстрее. Хм, а может можно еще лучше?
Так, думаем. Во-первых у нас данные копируются дважы: сначала из строки в массив, потом внутри массива. Во-вторых Array.Reverse — библиотечный метод, значит в нем есть проверки входных данных. Более того, для атомарных типов он явно реализован в виде native метода, а это дополнительное переключение контекста выполнения. Попробуем перевернуть строку в массив вручную:
Идем дальше. У нас же действия симметричны относительно середины строки, значит можно пустить два индекса навстречу и ученьшить количество итераций вдвое:
Хм… Что-то пошло не так, на системе с медленной памятью скорость упала в полтора раза. Учитывая специфику конфигураций и реализации, можем предположить, что виноваты скорость памяти и кэш процессора: раньше мы работали с двумя отдаленными областями памяти одновременно, теперь их стало четыре, соответсвенно подхват данных выполняется чаще.
Есть еще относительно красивый и короткий способ с LINQ, но он не выдерживает никакой критики в плане производительности — работает в 3-3.5 раза медленнее метода на базе StringBuilder. Виной тому прокачивание данных через IEnumerable и виртуальный вызов на каждую итерацию. Для желающих, ниже приведена реализация:
Проблема не столь критичная в большинстве случаев, но все «быстрые» из рассмотренных методов делают промежуточную копию строки в виде массива символов. На синтетических тестах это проявляется в том, что обернуть строку размером 512МБ смог только первый метод, остальные свалились по System.OutOfMemoryException. Также, не следует забывать, что лишние временные объекты повышают частоту срабатывания GC, а он хоть и оптимизирован до ужаса, но все-равно время кушает. В следующей части будем кроме скоростных оптимизаций также искать решение этой проблемы.
Использование unsafe кода дает нам одно интересное преимущество: строки, которые раньше были immutable, теперь можно менять, но нужно быть предельно осторожным и изменять только копии строк — библиотека минимизирует количество копий одной строки, а вместе с интернированием строк это может привести к печальным последствиями для приложения.
Итак, создав новую строку нужного размера, мы можем смотреть на нее, как на массив и заполнить нужными данными. Ну и не стоит забывать об отстутствии проверок на валидность индексов, что тоже ускорит работу кода. Однако в силу специфики строк в .Net, мы не можем вот так просто создать строку нужной длины. Можно либо сделать строку из повторяющегося символа (например проблела) при помощи конструктора String(char, int), либо скопировать исходную строку используя String.Copy(String).
Вооружившись этими знаниями пишем следующие две реализации.
Делаем строку из пробелов и заполняем ее в обратном порядке:
Копируем и переворачиваем строку:
Как показали замеры, вторая версия работает заметно быстрее на медленной памяти и слегка медленнее на быстрой :) Причин видимо несколько: оперирование двумя отдаленными областями памяти вместо четырех и различие в скорости копирования блока памяти и простого его заполнения в цикле. Желающие могут попробовать сделать версию ReverseUnsafeFill с полным проходом (это может уменьшить число захватов данных из памяти в кэш) и испытать ее на медленной памяти, однако у меня есть основания считать, что это будет все-равно медленнее ReverseUnsafeCopy (хотя могу и ошибаться).
А что дальше? Ходят слухи, что обмен при помощи оператора XOR работает быстрее копирования через третью переменную (кстати в плюсах это еще и смотрится довольно красиво: «a ^= b ^= a ^= b;», в C#, увы, такая строка не cработает). Ну что, давайте проверим на деле.
В итоге получается в 1.2-1.5 раза медленнее обмена копированием. Трюк, работавший для быстрого обмена значений на регистрах, для переменных себя не оправдал (что характено, во многих компиляторах С/С++ он тоже выиграша не дает).
В поисках объяснения этого факта полезем внутрь приложения и почитаем результирующий CIL код.
Для получения ответа на этот вопрос стоит посмотреть на CIL-код, сгенерированный для двух способов обмена. Чтоб эти инструкции казались понятнее, поясню их назначение: ldloc.N — загружает на стек локальную переменную под номером N, stloc.N — считывает верхушку стека в локальную переменную номер N, xor — вычисляет значение операции XOR для двух значений наверху стека и загружает результат на стек вместо них.
Как легко заметить, версия с оператором XOR требует больше операций виртуальной машины. Более того, при последующей компиляции в native код, вполне вероятно наличие оптимизации, которая типичный обмен через третью переменную заменит более эффективной операцией обмена с учетом возможностей используемого процессора. Как побочный эффект анализа, получаем гипотетический «идеальный» обмен на CIL, было бы интересно проверить, даст ли его использование какой-либо эффект, но для этого надо возиться с ilasm или reflection/emit, может еще соберусь. Впрочем полученный код будет еще менее применим, чем unsafe c# поэтому практичекого интереса особо не представляет.
Ну и пока мы смотрим на внутренности сборок рефлектором, есть смысл взглянуть на реализацию библиотечных методов, использованных в первой части. Особняком здесь стоит Array.Reverse, который опирается на некую функцию Array.TrySZReverse, реализованную в виде native метода. Итак качаем Shared Source Common Language Infrastructure 2.0 — исходник .net 2.0 и смотрим, что ж это за зверь такой :) После недолгих поисков, в файле «sscli20\clr\src\vm\comarrayhelpers.h» находится шаблонная функция Reverse (в данном случае KIND будет соответствовать UINT16), которая (сюрприз!) до ужаса похожа на реализацию ReverseUnsafeCopy.
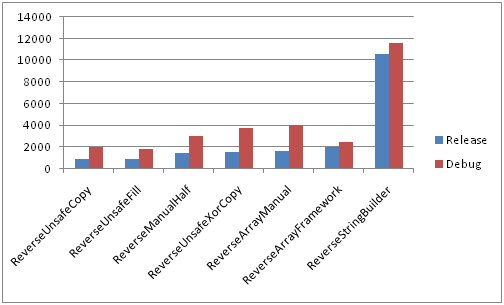
Анализ результатов замеров приведен в первых двух частях, здесь же изображены лишь сравнительные диаграммы отображающие отношение быстродействия рассмотренных выше функций. Точные числа в «ticks» слишком зависят от конфигурации и вряд-ли представляют особый интерес, все желающие могут самостоятельно замерить быстродействие используя предоставленные куски кода.
На быстрой памяти
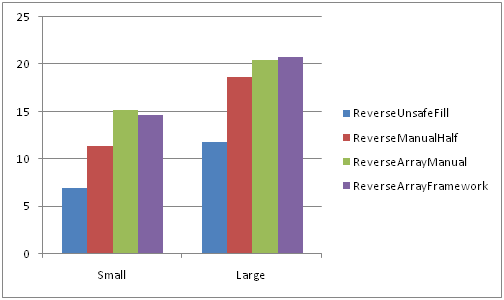
На медленной памяти
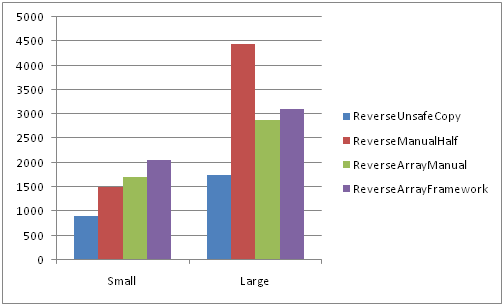
Большие строки
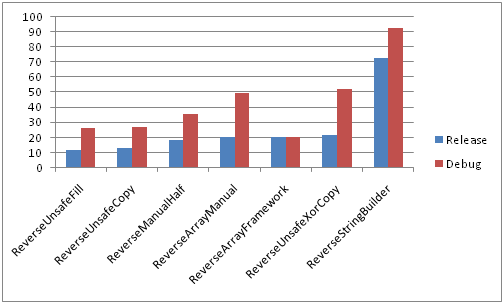
Короткие строки
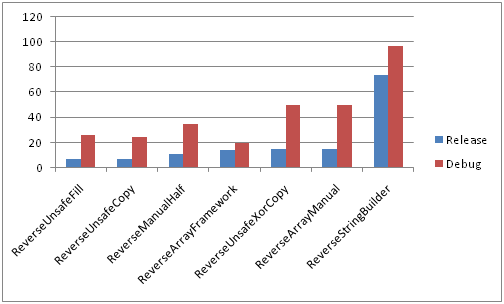
Большие строки
Короткие строки
Под катом приведен сравнительный анализ быстродействия разных методов переворачивания строки.
Кхрр-р-р… — сказала бензопила.
Тююю… — сказали мужики.
© Старый анекдот.
Ну что ж, начнем. Все реализации проверялись на быстродействие с одной строкой размером 256 мегабайт (128×1024×1024 символа) и 1024×1024 строками размером 256 байт (128 символов). Перед каждым замером форсировалась сборка мусора (что важно при таком размере тестовых данных), замер проводился 50 раз, 20 крайних отбрасывались, остальные значения усреднялись. Условными попугаями было выбрано количество тиков, выдаваемое объектом класса Stopwatch.
Тест проводился на двух компьютерах: Athlon64 x2 4200+, 2GB Dual-Channel DDR2 RAM и Pentium4 HT 3GHz, 3GB DDR RAM. Главным отличием между конфигурациями в данном тесте является быстродействие связки память-кэш — вторая система в этом отношении заметно медленнее.
С техническими формальностями покончено, теперь перейдем к собственно реализациям. Для большей наглядности, здесь не учтены unicode surrogate code points. Рассматривать подходы будем в порядке логичности и «красивости» реализации в контексте окружающей ее «экосистемы».
Сравнительные результаты замеров находятся в последней части этой заметки. Оптимальной в общем случае оказалась функция ReverseUnsafeCopy, если же ограничиваться только safe code — ReverseArrayManual. Если необходим safe code и огромные строки — прийдется мучаться с ReverseStringBuilder.
Часть первая: «нормальные» методы.
1. ReverseStringBuilder
Будем следовать рекомендациям и для построения «большой» строки возьмем специальный инструмент — класс StringBuilder. Идея проста до ужаса: создаем builder нужного размера и идем по строке в обратном порядке, добавляя символы в новую строку.
Copy Source | Copy HTML
- static string ReverseStringBuilder(string str)
- {
- StringBuilder sb = new StringBuilder(str.Length);
- for (int i = str.Length; i-- != 0; )
- sb.Append(str[i]);
- return sb.ToString();
- }
Пробуем, запускаем, да… Как-то медленно работает это все, будем копать дальше.
2. ReverseArrayFramework
Ха! Так этот билдер же обставлен проверками для обеспечения потокобезопасности со всех сторон, не, нам такое не надо. Но строка — это ведь массив сиволов. Так давайте его и перевернем, а результат преобразуем обратно в строку:
Copy Source | Copy HTML
- static string ReverseArrayFramework(string str)
- {
- char[] arr = str.ToCharArray();
- Array.Reverse(arr);
- return new String(arr);
- }
Совсем другое дело, получилось в 3.5 раза быстрее. Хм, а может можно еще лучше?
3. ReverseArrayManual
Так, думаем. Во-первых у нас данные копируются дважы: сначала из строки в массив, потом внутри массива. Во-вторых Array.Reverse — библиотечный метод, значит в нем есть проверки входных данных. Более того, для атомарных типов он явно реализован в виде native метода, а это дополнительное переключение контекста выполнения. Попробуем перевернуть строку в массив вручную:
Copy Source | Copy HTML
- static string ReverseArrayManual(string originalString)
- {
- char[] reversedCharArray = new char[originalString.Length];
- for (int i = originalString.Length - 1; i > -1; i--)
- reversedCharArray[originalString.Length - i - 1] = originalString[i];
- return new string(reversedCharArray);
- }
4. ReverseManualHalf
Идем дальше. У нас же действия симметричны относительно середины строки, значит можно пустить два индекса навстречу и ученьшить количество итераций вдвое:
Copy Source | Copy HTML
- static string ReverseManualHalf(string originalString)
- {
- char[] reversedCharArray = new char[originalString.Length];
- int i = 0;
- int j = originalString.Length - 1;
- while (i <= j)
- {
- reversedCharArray[i] = originalString[j];
- reversedCharArray[j] = originalString[i];
- i++; j--;
- }
- return new string(reversedCharArray);
- }
Хм… Что-то пошло не так, на системе с медленной памятью скорость упала в полтора раза. Учитывая специфику конфигураций и реализации, можем предположить, что виноваты скорость памяти и кэш процессора: раньше мы работали с двумя отдаленными областями памяти одновременно, теперь их стало четыре, соответсвенно подхват данных выполняется чаще.
LINQ и метод Reverse
Есть еще относительно красивый и короткий способ с LINQ, но он не выдерживает никакой критики в плане производительности — работает в 3-3.5 раза медленнее метода на базе StringBuilder. Виной тому прокачивание данных через IEnumerable и виртуальный вызов на каждую итерацию. Для желающих, ниже приведена реализация:
Copy Source | Copy HTML
- static string ReverseStringLinq(string originalString)
- {
- return new string(originalString.Reverse().ToArray());
- }
Использование памяти
Проблема не столь критичная в большинстве случаев, но все «быстрые» из рассмотренных методов делают промежуточную копию строки в виде массива символов. На синтетических тестах это проявляется в том, что обернуть строку размером 512МБ смог только первый метод, остальные свалились по System.OutOfMemoryException. Также, не следует забывать, что лишние временные объекты повышают частоту срабатывания GC, а он хоть и оптимизирован до ужаса, но все-равно время кушает. В следующей части будем кроме скоростных оптимизаций также искать решение этой проблемы.
Часть вторая: когда хочется быстрее и эффективнее, или unsafe code.
Использование unsafe кода дает нам одно интересное преимущество: строки, которые раньше были immutable, теперь можно менять, но нужно быть предельно осторожным и изменять только копии строк — библиотека минимизирует количество копий одной строки, а вместе с интернированием строк это может привести к печальным последствиями для приложения.
Итак, создав новую строку нужного размера, мы можем смотреть на нее, как на массив и заполнить нужными данными. Ну и не стоит забывать об отстутствии проверок на валидность индексов, что тоже ускорит работу кода. Однако в силу специфики строк в .Net, мы не можем вот так просто создать строку нужной длины. Можно либо сделать строку из повторяющегося символа (например проблела) при помощи конструктора String(char, int), либо скопировать исходную строку используя String.Copy(String).
Вооружившись этими знаниями пишем следующие две реализации.
5. ReverseUnsafeFill
Делаем строку из пробелов и заполняем ее в обратном порядке:
Copy Source | Copy HTML
- static unsafe string ReverseUnsafeFill(string str)
- {
- if (str.Length <= 1) return str;
- String copy = new String(' ', str.Length);
- fixed (char* buf_copy = copy)
- {
- fixed (char* buf = str)
- {
- int i = 0;
- int j = str.Length - 1;
- while (i <= j)
- {
- buf_copy[i] = buf[j];
- buf_copy[j] = buf[i];
- i++; j--;
- }
- }
- }
- return copy;
- }
6. ReverseUnsafeCopy
Копируем и переворачиваем строку:
Copy Source | Copy HTML
- static unsafe string ReverseUnsafeCopy(string str)
- {
- if (str.Length <= 1) return str;
- char tmp;
- String copy = String.Copy(str);
- fixed (char* buf = copy)
- {
- char* p = buf;
- char* q = buf + str.Length - 1;
- while (p < q)
- {
- tmp = *p;
- *p = *q;
- *q = tmp;
- p++; q--;
- }
- }
- return copy;
- }
Как показали замеры, вторая версия работает заметно быстрее на медленной памяти и слегка медленнее на быстрой :) Причин видимо несколько: оперирование двумя отдаленными областями памяти вместо четырех и различие в скорости копирования блока памяти и простого его заполнения в цикле. Желающие могут попробовать сделать версию ReverseUnsafeFill с полным проходом (это может уменьшить число захватов данных из памяти в кэш) и испытать ее на медленной памяти, однако у меня есть основания считать, что это будет все-равно медленнее ReverseUnsafeCopy (хотя могу и ошибаться).
7. ReverseUnsafeXorCopy
А что дальше? Ходят слухи, что обмен при помощи оператора XOR работает быстрее копирования через третью переменную (кстати в плюсах это еще и смотрится довольно красиво: «a ^= b ^= a ^= b;», в C#, увы, такая строка не cработает). Ну что, давайте проверим на деле.
Copy Source | Copy HTML
- static unsafe string ReverseUnsafeXorCopy(string str)
- {
- if (str.Length <= 1) return str;
- String copy = String.Copy(str);
- fixed (char* buf = copy)
- {
- char* p = buf;
- char* q = buf + str.Length - 1;
- while (p < q)
- {
- *p ^= *q;
- *q ^= *p;
- *p ^= *q;
- p++; q--;
- }
- }
- return copy;
- }
В итоге получается в 1.2-1.5 раза медленнее обмена копированием. Трюк, работавший для быстрого обмена значений на регистрах, для переменных себя не оправдал (что характено, во многих компиляторах С/С++ он тоже выиграша не дает).
В поисках объяснения этого факта полезем внутрь приложения и почитаем результирующий CIL код.
Часть третья: лезем в CIL и коды библиотек .Net.
Почему обмен через XOR оказался хуже
Для получения ответа на этот вопрос стоит посмотреть на CIL-код, сгенерированный для двух способов обмена. Чтоб эти инструкции казались понятнее, поясню их назначение: ldloc.N — загружает на стек локальную переменную под номером N, stloc.N — считывает верхушку стека в локальную переменную номер N, xor — вычисляет значение операции XOR для двух значений наверху стека и загружает результат на стек вместо них.
| Обмен копированием | Обмен на базе XOR | Идеальный обмен CIL |
|---|---|---|
|
|
|
.locals init (<br/> |
.locals init (<br/> |
.locals init (<br/> |
L_0004: ldloc.0<br/> |
L_0004: ldloc.0<br/> |
L_0004: ldloc.0<br/> |
Как легко заметить, версия с оператором XOR требует больше операций виртуальной машины. Более того, при последующей компиляции в native код, вполне вероятно наличие оптимизации, которая типичный обмен через третью переменную заменит более эффективной операцией обмена с учетом возможностей используемого процессора. Как побочный эффект анализа, получаем гипотетический «идеальный» обмен на CIL, было бы интересно проверить, даст ли его использование какой-либо эффект, но для этого надо возиться с ilasm или reflection/emit, может еще соберусь. Впрочем полученный код будет еще менее применим, чем unsafe c# поэтому практичекого интереса особо не представляет.
Как работает Array.Reverse?
Ну и пока мы смотрим на внутренности сборок рефлектором, есть смысл взглянуть на реализацию библиотечных методов, использованных в первой части. Особняком здесь стоит Array.Reverse, который опирается на некую функцию Array.TrySZReverse, реализованную в виде native метода. Итак качаем Shared Source Common Language Infrastructure 2.0 — исходник .net 2.0 и смотрим, что ж это за зверь такой :) После недолгих поисков, в файле «sscli20\clr\src\vm\comarrayhelpers.h» находится шаблонная функция Reverse (в данном случае KIND будет соответствовать UINT16), которая (сюрприз!) до ужаса похожа на реализацию ReverseUnsafeCopy.
Copy Source | Copy HTML
- static void Reverse(KIND array[], UNIT32 index, UNIT32 count) {
- LEAF_CONTRACT;
-
- _ASSERTE(array != NULL);
- if (count == 0) {
- return;
- }
- UNIT32 i = index;
- UNIT32 j = index + count - 1;
- while(i < j) {
- KIND temp = array[i];
- array[i] = array[j];
- array[j] = temp;
- i++;
- j--;
- }
- }
Часть четвертая: результаты бинарного марафона.
Анализ результатов замеров приведен в первых двух частях, здесь же изображены лишь сравнительные диаграммы отображающие отношение быстродействия рассмотренных выше функций. Точные числа в «ticks» слишком зависят от конфигурации и вряд-ли представляют особый интерес, все желающие могут самостоятельно замерить быстродействие используя предоставленные куски кода.
Сравнение лучших методов из первых двух частей
На быстрой памяти
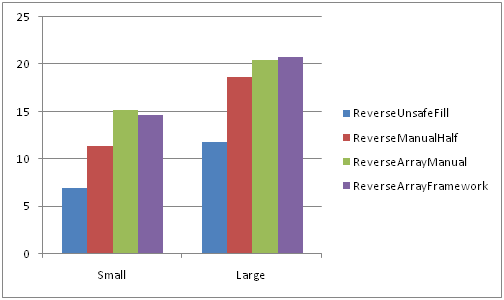
На медленной памяти

Сравнение всех методов в Debug и Release конфигурациях на быстрой памяти
Большие строки

Короткие строки
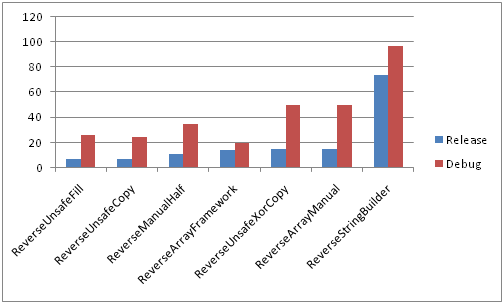
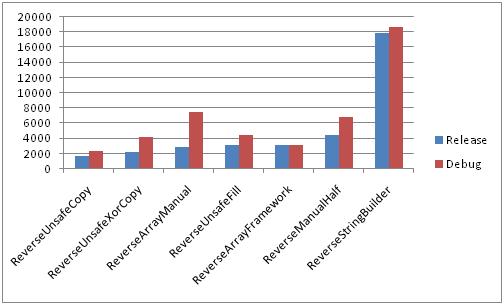
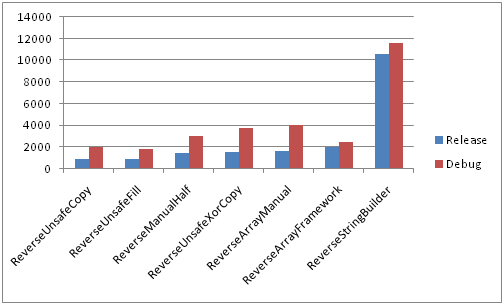
Сравнение всех методов в Debug и Release конфигурациях на медленной памяти
Большие строки

Короткие строки