 Класс
Класс System.Drawing.Bitmap очень полезен в инфраструктуре .NET, т.к. позволяет считывать и сохранять файлы различных графических форматов. Единственная проблема – это то, что он не очень полезен для попиксельной обработки – например если нужно перевести битмап в ч/б. Под катом – небольшой этюд на эту тему.Допустим у нас есть два битмапа, один из которых считан из файла, а другой должен содержать ч/б конверсию:
// загружаем картинку
sourceBitmap = (Bitmap) Image.FromFile("Zap.png");<br/>
// делаем пустую картинку того же размера
targetBitmap = new Bitmap(sourceBitmap.Width, sourceBitmap.Height, sourceBitmap.PixelFormat);<br/>
targetBitmap был как sourceBitmap, только черно-белый. На самом деле, в C# делается это просто:void NaïveBlackAndWhite()<br/>
{<br/>
for (int y = 0; y < sourceBitmap.Height; ++y)<br/>
for (int x = 0; x < sourceBitmap.Width; ++x)<br/>
{<br/>
Color c = sourceBitmap.GetPixel(x, y);<br/>
byte rgb = (byte)(0.3 * c.R + 0.59 * c.G + 0.11 * c.B);<br/>
targetBitmap.SetPixel(x, y, Color.FromArgb(c.A, rgb, rgb, rgb));<br/>
}<br/>
}<br/>
// структура отражает один пиксель в 32bpp RGBA
struct Pixel {<br/>
BYTE Blue;<br/>
BYTE Green;<br/>
BYTE Red;<br/>
BYTE Alpha;<br/>
};<br/>
Pixel MakeGrayscale(Pixel& pixel)<br/>
{<br/>
const BYTE scale = static_cast<BYTE>(0.3 * pixel.Red + 0.59 * pixel.Green + 0.11 * pixel.Blue);<br/>
Pixel p;<br/>
p.Red = p.Green = p.Blue = scale;<br/>
p.Alpha = pixel.Alpha;<br/>
return p;<br/>
}<br/>
CPPSIMDLIBRARY_API void AlterBitmap(BYTE* src, BYTE* dst, int width, int height, int stride)<br/>
{<br/>
for (int y = 0; y < height; ++y) {<br/>
for (int x = 0; x < width; ++x)<br/>
{<br/>
int offset = x * sizeof(Pixel) + y * stride;<br/>
Pixel& s = *reinterpret_cast<Pixel*>(src + offset);<br/>
Pixel& d = *reinterpret_cast<Pixel*>(dst + offset);<br/>
// изменяем d
d = MakeGrayscale(s);<br/>
}<br/>
}<br/>
}<br/>
void UnmanagedBlackAndWhite()<br/>
{<br/>
// "зажимаем" байты обеих картинок
Rectangle rect = new Rectangle(0, 0, sourceBitmap.Width, sourceBitmap.Height);<br/>
BitmapData srcData = sourceBitmap.LockBits(rect, ImageLockMode.ReadWrite, sourceBitmap.PixelFormat);<br/>
BitmapData dstData = targetBitmap.LockBits(rect, ImageLockMode.ReadWrite, sourceBitmap.PixelFormat);<br/>
// отсылаем в unmanaged код для изменений
AlterBitmap(srcData.Scan0, dstData.Scan0, srcData.Width, srcData.Height, srcData.Stride);<br/>
// отпускаем картинки
sourceBitmap.UnlockBits(srcData);<br/>
targetBitmap.UnlockBits(dstData);<br/>
}<br/>
y и получил предсказуемое ускорение в 2 раза. Дальше захотелось поэкспериментировать и попробовать применить еще и SIMD. Для этого я написал вот этот, не очень читабельный, код:CPPSIMDLIBRARY_API void AlterBitmap(BYTE* src, BYTE* dst, int width, int height, int stride)<br/>
{<br/>
// факторы для конверсии в ч/б
static __m128 factor = _mm_set_ps(1.0f, 0.3f, 0.59f, 0.11f);<br/>
#pragma omp parallel for<br/>
for (int y = 0; y < height; ++y)<br/>
{<br/>
const int offset = y * stride;<br/>
__m128i* s = (__m128i*)(src + offset);<br/>
__m128i* d = (__m128i*)(dst + offset);<br/>
for (int x = 0; x < (width >> 2); ++x) {<br/>
// у нас 4 пикселя за раз
for (int p = 0; p < 4; ++p)<br/>
{<br/>
// конвертируем пиксель
__m128 pixel;<br/>
pixel.m128_f32[0] = s->m128i_u8[(p<<2)];<br/>
pixel.m128_f32[1] = s->m128i_u8[(p<<2)+1];<br/>
pixel.m128_f32[2] = s->m128i_u8[(p<<2)+2];<br/>
pixel.m128_f32[3] = s->m128i_u8[(p<<2)+3];<br/>
// четыре операции умножения - одной командой!
pixel = _mm_mul_ps(pixel, factor);<br/>
// считаем сумму
const BYTE sum = (BYTE)(pixel.m128_f32[0] + pixel.m128_f32[1] + pixel.m128_f32[2]);<br/>
// пишем назад в битмап
d->m128i_u8[p<<2] = d->m128i_u8[(p<<2)+1] = d->m128i_u8[(p<<2)+2] = sum;<br/>
d->m128i_u8[(p<<2)+3] = (BYTE)pixel.m128_f32[3];<br/>
}<br/>
s++;<br/>
d++;<br/>
}<br/>
}<br/>
}<br/>
_mm_mul_ps), все эти конверсии не дали никакого выигрыша по сравнению с обычными операциями – скорее наоборот, алгоритм начал работать медленнее. Вот результаты выполнения функций на картинке 360×480. Использовался 2х-ядерный MacBook с 4Гб RAM, результаты усредненные.
А вот и конечный результат:
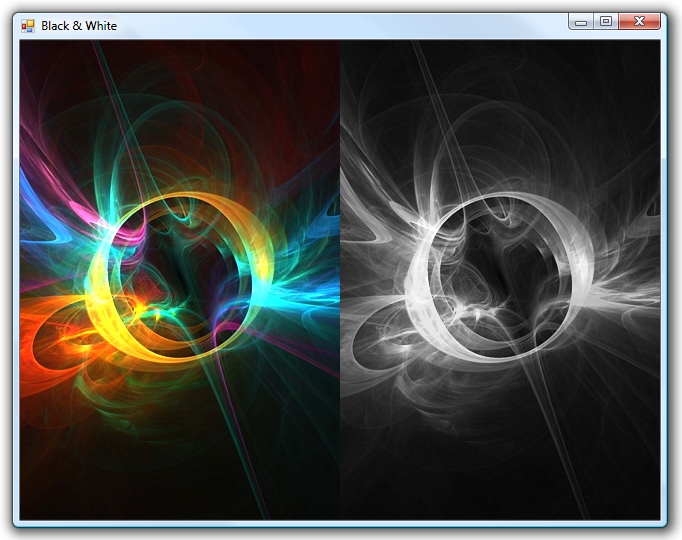
Выводы:
SetPixel/GetPixel– это зло, их трогать не стоит.
- OpenMP продолжает радовать, давая линейный scalability.
- Использование SIMD не гарантирует повышение производительности. Зато доставляет много хлопот.
Если кто-нибудь из читателей готов написать еще более эффективный алгоритм – милости просим! Протестирую и опубликую его прямо здесь.

