Спасибо небу за то, что в субботу шел дождь, и я это прочитал (а вы скажите спасибо за то, что перевел). В воскресенье, однако, светило солнце и форматирование текста было отложено.
Отдельное спасибо автору, за разрешение отдельной публикации.
Крайне занятная статья о том, что такое бизнес логика и где ей жить. Статье, кстати, уже три года. А я нередко встречаю системы, где код от данных не отделен. Может привести к реальному холивару.
За годы развития мы продвинулись от десктопа к клиент-серверной архитектуре, потом к 3-х звенной конструкции, к n-звенной, к сервис ориентированной. Во время этого процесса многие вещи изменились, но многие привычки остались. Зачастую, сопротивление изменениям происходит от привычек. Однако, во многих случаях оно процедурное. Эта статья описывает, что мы делаем неправильно и возможные решения.
То, что я здесь опишу, один из методов построения n-звенных систем с точки зрения проектирования и архитектуры. Эта статья не фокусируется на коде. Есть много методов построения n-звенных систем, это только один из них. Если вы строите систему, я надеюсь, вы найдете хороший совет, методику или шаблон использования этого подхода.
Хотя данная статья может предлагать несколько отправных точек из «стандартных методов», все в этой статье базируется на Шаблонах и Методах Microsoft и описывается в Designing Data Tier Components and Passing Data through Tiers и других документах.
Даже если вы не решитесь применять все методологии, предложенные здесь, вам следует воспользоваться хотя некоторыми из них.
Спросите любого разработчика, где должна быть бизнес логика, и получите ответ: «Конечно же в бизнес слое».
Спросите того же разработчика, где находится бизнес логика в их организации, и снова услышите: «Конечно же в бизнес слое».
У вас не должно быть не малейших сомнений на счет того где должна быть бизнес логика – в бизнес слое. Не часть бизнес логики – вся бизнес логика должна быть в бизнес слое. После прочтения данной статьи, многие разработчики поймут что то, что они считали правдой о своих системах, таковой не является.
Эти термины часто используются вместе, но в данной статье я буду использовать их так, как опишу здесь.
Когда я использую слово звено, я подразумеваю физическое звено состоящее из физического сервера или группы серверов, выполняющих одинаковую функцию и сгруппированных только для повышения емкости.
Когда я использую слово слой, я подразумеваю сегмент системы, который ограничен собственным процессом или модулем. Множество слоев может содержаться в одном звене, но любой из них должен иметь возможность быть легко перенесенным на другое звено.
На настольных приложениях бизнес логика содержится на одном звене со всеми остальными слоями. Т.к. нет необходимости разделять слои, они зачастую перемешаны и не имеют четких границ.

В клиент-серверном приложении имеются два звена, что приводит к созданию как минимум двух слоев. На начальном этапе сервер рассматривался только как удаленная база данных, и деление было как на рисунке – приложение на клиенте и данные на сервере. Обычно вся бизнес логика находилась на клиенте, перемешанная с остальными слоями, такими как пользовательский интерфейс.

Достаточно быстро стало понятно, что можно сократить нагрузку на сеть и централизовать логику для уменьшения постоянных затрат на развертывание, перенеся большую часть бизнес логики на сервер. Архитектурно сервер был хорошо подготовленным местом в клиент-серверной системе, но база данных как платформа давала мало возможностей. Базы данных были спроектированы для хранения и выдачи и в их архитектуру не были заложены возможности расширения в направлении бизнес логики. Языки хранимых процедур в базах данных были разработаны для базовых преобразований данных, чтобы поддержать то, на что не хватало SQL. Языки хранимых процедур разработали для быстрого исполнения, а не для обслуживания сложных задач бизнес логики.
Но из двух зол эта была меньшей, и часть бизнес логики переехала в хранимые процедуры. На самом деле, я готов поспорить, что бизнес логика была ужата и вбита в рамки хранимых процедур, исключительно с прагматической точки зрения. В двух звеном мире – это было не идеальным, но все-таки гораздо лучшим.

Когда проблема клиент-серверной архитектуры стала явной, возросла популярность 3-х звенного подхода. Наибольшей и самой тяжелой проблемой того времени было количество подключений. Сейчас многие базы данных могут обрабатывать тысячи единовременных подключений, в девяностых большинство баз данных падали где-то на 500 подключений. Сервера зачастую лицензировались по кол-ву клиентских подключений. Это все и привело к тому, что потребовалось сократить количество подключений к базе данных.
Стало популярным объединение подключений в пул, однако для реализации пула подключений в системе с множеством отдельных клиентов, необходимо внедрить третье звено между клиентом и сервером. Среднее звено так и стало называться «среднее звено». В большинстве случаев среднее звено существовало только для управления пулом соединений, но в некоторых случаях бизнес логика начала перемещаться в среднее звено потому, что языки разработки (C++, VB, Delphi, Java) гораздо лучше подходили для реализации бизнес логики, чем языки хранимых процедур. Вскоре стало очевидно, что среднее звено –это наилучшее место для бизнес логики.
Также среднее звено предоставило возможность подключения клиентов с низкими скоростями, т.к. прямое соединение с базой данных, как правило, требует широкого канала и низкой задержки.
Прежде чем я продолжу, давайте четко определим: что же такое бизнес логика. Выступая с презентациями на конференциях и внутри компании, я начал опасаться того, что не все соглашаются с тем, чем является бизнес логика, и, довольно часто, даже не до конца понимают: что она есть, а что нет.
Сервер базы данных – это уровень хранения. Базы данных разработаны для хранения, получения и обновления данных с максимально высокой эффективностью. Функционал зачастую является СУПОм (Создать, Удалить, Получить, Обновить). Некоторые базы данных СУПОм и являются, но разговор не об этом.
Базы данных разработаны для того, чтобы очень быстро обслуживать эти операции. Они не разработаны для форматирования телефонных номеров, рассчитывать оптимальное использование и пиковые нагрузки, определять географическое местоположение и маршруты грузов, и так далее. Хотя, я видел все это и много более сложные задачи, реализованные только с помощью или большой частью на хранимых процедурах.
И все это относится не только к сложным вещам. Давайте представим себе простую задачу и такую, которую зачастую даже не относят к бизнес логике. Задача – Удалить Покупателя. Практически во всех системах, что я видел, удаление покупателя обрабатывается исключительно хранимой процедурой. Однако в удаление покупателя довольно многие решения должны быть приняты на уровне бизнес логики. Можно ли удалить покупателя? Какие процессы должны быть запущены до и после? Какие предосторожности должны быть соблюдены? Из каких таблиц записи должны быть удалены или обновлены в последствие?
Базе данных не должно быть дела до того, что такое покупатель, она должна заботиться только об элементах, используемых для хранения покупателя. У базы данных не должно быть возможности разобраться, какие таблицы должны хранить объект покупатель, и она должна работать с таблицами не обращая внимания на объект покупатель. Задача базы данных – хранить ряды в таблицах, которые описывают покупателя. Кроме базовых ограничений вроде каскадной целостности, типов данных, индексов и пустых значений, база данных не должна иметь функционального знания о том, что же из себя представляет покупатель в бизнес слое.
Хранимые процедуры, если они есть, должны оперировать только одной таблицей; исключение – это процедуры запрашивающие выборку из нескольких таблиц для выдачи данных. В этом случае, хранимые процедуры работают как представления (view). Представления и хранимые процедуры должны использоваться для консолидации значений, но исключительно для более быстрой и эффективной работы с данными в бизнес слое.
Но даже в компаниях, гордящихся новейшими достижениями в разработках и технологиях, и в тех, что с пеной у рта кричат о всей их бизнес логике в бизнес слое, короткий анализ базы данных быстро выявляет: удалить покупателя, добавить покупателя, заблокировать покупателя, заморозить покупателя и т.д. и т.п. И не только с покупателем, но и с многими другими объектами бизнес логики.
Я часто встречал хранимые процедуры вроде этой:
Регулярно часть бизнес логики отъезжает в бизнес слой.
В этом случае, часть бизнес логики была перемещена, но не вся. Некоторые таблицы обрабатываются и в слое бизнес логики. База данных не должна иметь ни малейшего представления о том, какие таблицы формируют покупателя в бизнес слое. Для всех трех операций, бизнес слой должен выдать SQL команду или вызвать три отдельные хранимые процедуры для реализации функционала в приведенной sp_DeleteCustomer.
Передав всю бизнес логику в бизнес слой, мы получим:
Удаление рядов может использовать хранимую процедуру, если они из одной таблицы. Однако, в современных базах данных, использующих кэширование запросов, это является несущественным улучшением производительности. К тому же, SQL, генерируемый такими системами очень прост, т.к. он работает с одной таблицей, и потому практически не требует оптимизации. На самом деле, базе данных становится не очень хорошо от слишком большого количества загруженных хранимых процедур, а простые SQL команды на них так не действуют.
Переведя даже модификацию таблиц в бизнес слой, мы получим следующие преимущества:
В виду того, что такой метод требует три успешных обращения к базе данных вместо одного, ваш узел бизнес логики должен быть подключен к базе данных по отдельному высокоскоростному сегменту, типа гигабита. Отправка 300 байт вместо 100 байт станет непринципиальной. Большинство баз данных поддерживают пакетную передачу SQL запросов, и все три запроса могут быть посланы в одном пакете, уменьшив нагрузку на сеть. Для выдачи таких запросов следует использовать слой доступа к данным, а не включать запросы прямо в код.
Некоторые администраторы баз данных и даже разработчики могут не принять этот уровень интеграции и настаивать на реализации таких пакетных обновлений в хранимых процедурах. Это выбор, который вы должны сделать, и он очень зависит от вашей базы данных и ваших приоритетов. Т.к. практически все современные базы данных используют механизмы кэширования запросов, выигрыш в производительности в большинстве случаев минимален, а четкие технологические причины не нагружать логикой хранимые процедуры есть. Если вы выберите оставить такие пакетные обновления в хранимых процедурах, вы должны быть очень осторожны, чтобы не допустить проскальзывания другой бизнес логики в хранимые процедуры, и ограничить свои хранимые процедуры СУПОвыми операциями, без каких либо условных операций и другой бизнес логики.
Давайте разберем еще один пример, обнаруженный мной и сеющий зерна войны среди разработчиков – является это бизнес логикой или нет. Я расскажу, почему я считаю это бизнес логикой, а не пользовательским интерфейсом или хранением. Этот пример не относится к легко реализуемому форматированию. Пример, который я буду использовать, — телефонные номера.
Каждая страна имеет свой собственный формат отображения телефонных номеров в приятной глазу манере. В некоторых странах их даже больше одной. Ниже несколько примеров:
Кипр:
+357 (25) 66 00 34
+357 (25) 660 034
+357 25 660 034
+357 2566 0034
Германия:
+49 211 123456
+49 211 1234-0
Северная Америка (США, Канада)
+1 (423) 235-2423
+1-423-235-2423
Россия:
+7 (812) 438-46-02
+7 (812) 438-4602
В Германии есть даже специальный официальный стандарт для форматирования – DIN 5008.
Конечно же, код страны отбрасывают при локальном использовании. Но давайте предположим, что у вас интернациональная система и необходимо хранить и отображать код страны. Для каждой страны мы выберем один формат отображения.
Договоримся форматировать телефоны следующим образом:
Обычно делается следующее, все не цифровые символы убираются и номер становится похожим на:
Phone: 35725660034
Иногда отделяется код страны и номер становится таким:
PhoneCountry: 357
PhoneLocal: 25660034
Кажется простым, но это еще одна задача для бизнес логики. Не все страны имеют код одинаковой длины. Коды стран могут быть от 1 до 3 знаков.
Зачастую обработка ввода (если код страны отделен) и логика отображения реализованы на клиенте, т.к. клиент написан на традиционном языке, который хорошо для этого подходит. Проблема в том, что клиенту требуется огромное количество данных для определения длины кодов стран, и потребуется обновление клиента каждый раз, когда изменился формат отображения.
Иногда форматирование осуществляется в хранимой процедуре. Проблема этого подхода в том, что языки хранимых процедур, не приспособленны для такого типа логики, и он часто приводит к багам и тормозам в работе с настоящей логики.
Еще чаще телефонные номера хранятся дважды. Один раз в чистом виде для хорошей индексации и поиска, и второй – в отформатированном для отображения. В дополнении к проблемам, описанным выше, получаем проблемы избыточных записей и обновления.
У особо изощренных экстрималов, встречающихся до смешного часто, телефонный номер хранится в том формате, в котором поступил. Проблема очевидна: телефоны нельзя быстро найти, проиндексировать или отсортировать.
Важно то, что хотя это и форматирование, оно не относится к пользовательскому интерфейсу, а попытка тотальной централизации может пристрелить базу данных. Это однозначно бизнес логика. Реализация форматирования в бизнес слое не допустит дублирования данных и будет написана на языке разработки, а не вбита в язык обработки данных.
Некоторые пакетные обновления выполняются во много раз быстрее, будучи реализованными с помощью хранимых процедур. В большинстве случаев можно обойтись простым SQL, но некоторые типы пакетных обновлений требуют циклов и при реализации в бизнес слое создадут тысячи SQL команд. В таких редких случаях, должна быть использована хранимая процедура, даже если в ней нужно реализовать бизнес логику. Нужно обратить особое внимание на то, чтобы в ней был реализован только необходимый минимум.
Я еще вернусь в статье к этой проблеме.
В клиент-серверных приложениях бизнес логика обычно имеется и на клиенте, и на сервере.
Реальное соотношение будет меняться от приложения и компании, предыдущий пример хорошо описывает клиент-серверные приложения. Большая часть бизнес логики была реализована в хранимых процедурах и представлениях в попытке централизовать бизнес логику. Однако многие бизнес правила не могут быть реализованы просто на SQL или хранимыми процедурами, или их быстрее выполнять на клиенте, так как они основываются на интерфейсе пользователя. Из-за этих противоположных факторов бизнес логика распределена между клиентом и сервером.
По многим причинам, которые я опишу позже в отдельной статье, при построении n-звенных систем ситуация становится только хуже в плане консолидации бизнес логики. Вместо консолидации, бизнес логика становится еще более фрагментированной.
Конечно же, каждая система имеет отличия в том, как бизнес логика распределяется по слоям, но есть одно общее для всех. Бизнес логика сейчас распределяется по трем слоям вместо двух. Далее я представлю несколько типичных сценариев.
Типичное распределение бизнес логики по n-звенной системе:

В таких случаях бизнес слой не содержит бизнес правил. Это не настоящий бизнес слой, а только форматер XML (или другого потокового формата) и адаптер наборов данных базы данных. Хотя некоторые плюсы такие как: пул соединений и изоляция БД, могут быть достигнуты, это не настоящий слой бизнес логики. Это скорее инородный физический слой без слоя логики.
Другой типичный сценарий:

Обычно некоторые бизнес правила приложения переходят в бизнес слой, но то, что было в базе данных, так в ней большей частью и остается.
При повторном использовании бизнес слоя в таких разработках бизнес правила должны повторяться и в клиентском приложении. Это сводит на нет основную цель внедрения бизнес слоя.
Также у клиентских приложений появляется возможность не выполнять бизнес правила, не реализуя их или просто игнорируя. При наличие настоящего бизнес слоя, это невозможно.
Вместо всего вышеперечисленного, бизнес слой должен содержать все бизнес правила.

Такая разработка имеет следующие преимущества:
Приведенный сценарий – это цель. Однако, некоторое дублирование, особенно для проверки данных, должно быть и на клиенте. Эти правила должны быть поддержаны и бизнес слоем. Кроме этого, в некоторых системах отдельные высоко емкие операции, такие как пакетные обновления, могут привести к исключениям и должны быть размещены в базе данных. Потому более реалистичных подход представлен ниже. Обратите внимание, что вся бизнес логика должна быть реализована в бизнес слое, и те минимальные наборы, присутствующие в других слоях, являются просто дублями исключительно для повышения производительности или отключения тех или иных компонент пользовательского интерфейса.

При переходе на центральный узел всегда есть искус «реализовать эту часть в хранимой процедуре». Потом «ту» и «вот эту». И скоро вы окажетесь в той же ситуации, что и были, без существенных изменений.
Хранимые процедуры должны использоваться для выполнения SQL и получения наборов данных в базах данных, которые оптимизируют хранимые процедуры лучше, чем представления. Но хранимые процедуры не должны быть использованы ни для чего другого, нежели объединения и выдачи данных. При обновлении данных она должна именно и только обновлять, но не интерпретировать данные каким-либо образом.
Есть задачи, где для повышения производительности некоторые компоненты должны быть помещены в хранимую процедуру. Но такие задачи на самом деле достаточно редки и они должны быть исключением, а не правилом. Каждое исключение должно быть проверенно и одобрено, а не просто реализовано по воле разработчика или администратора базы данных.
Звучит несколько странно, что покупка железа может сделать дешевле. Но при внедрении серверов среднего звена, практически никакого дополнительного ПО, кроме ОС, не требуется. А стоимость наращивания мощности сервера базы данных существенна по следующим причинам:
При переносе логики на среднее звено, вы можете существенно сократить нагрузку на базу данных и предотвратить преждевременное наращивание ее мощностей.
В добавление к стоимости, обновление среднего звена обычно проще чем обновление базы данных.
У баз данных есть врожденный предел того, на сколько они могут быть увеличены простым добавлением железа. В какой-то момент нужно начинать использовать другие технологии вроде деления, кластеризации, репликации и т.п. Но ни одна из этих технологий не является простой, и все требуют существенных вложений в железо, миграцию и сильно влияют на существующие системы.
Наращивать же сервера среднего звена гораздо проще. Как только запущен механизм распределения нагрузки, все сводится к задаче добавить новый сервер.
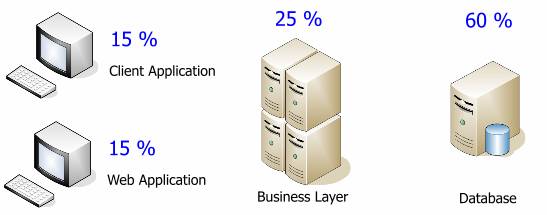
Давайте рассмотрим утверждения, которые я только что привел, используя следующую диаграмму. Заливка в сегментах показывает направление или важность их названия в отношении звеньев на диаграмме. Цена единицы возрастает, когда мы движемся от клиента, к среденму звену, к базе данных. Я использую слово единица для обозначения процессора или сервера, в зависимости от конфигурации.
(сверху вниз: цена единицы, средняя полоса пропускания, сложность развертывания, количество)
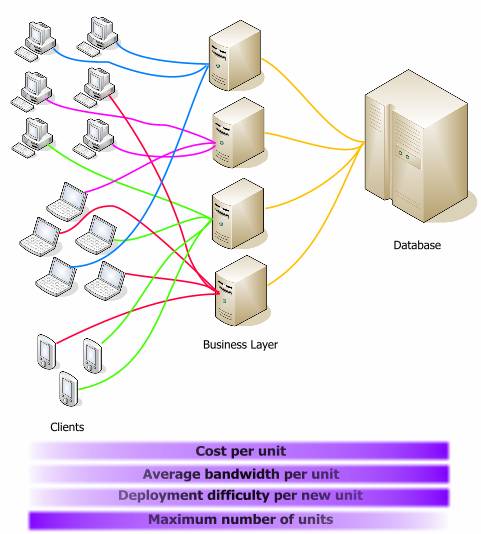
Если те же данные привести в относительных значениях, их можно легко сравнить:

Я не привел цифры на графиках потому, что они очень зависят от конфигурации сети, мощности процессоров и других факторов, уникальных для каждой организации. Каждая функция использует свои единицы измерения. Я представил лишь общее взаимоотношение измерений. Оно хорошо показывает, что среднее звено имеет емкость для роста и гораздо дешевле базы данных.
Если большая часть бизнес логики реализована в базе данных, вам будет нужна более мощная база данных.
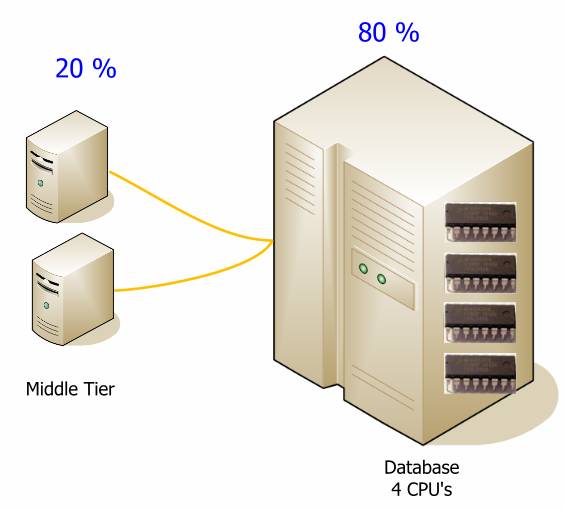
При переносе логики в среднее звено, вы можете серьезно снизить нагрузку на базу данных. Цифры представленные здесь, приведены только для демонстрации и будут меняться от системы к системе, но они могут помочь уловить идею. Хотя на следующей диаграмме и больше аппаратуры, суммарная стоимость системы будет меньше, и ее будет проще развернуть. Гораздо дешевле и проще наращивать среднее звено.
Давайте посмотрим еще раз на один из предыдущих графиков:
Какое единственное узкое место в системе? Какое из звеньев имеет выраженный предел наращивания? Это однозначно база данных. Все упирается в базу данных.
Потому перемещая вычисления в среднее звено, мы может отойти от границ слоя данных.
Есть несколько сложностей для перехода в среднее звено, и не все они заключаются в том, что нужно по-разному программировать.
Есть поговорка: «сложно избавиться от старых привычек». Это применимо и к команде. В команде вам нужно убедить не только себя, но и большинство команды.
Многие компании имеют устоявшиеся политики безопасности, предписывающие обеспечение безопасности в базе данных, а использование хранимых процедур в качестве представлений не дает достаточного контроля. Изменение корпоративных политик безопасности для перехода в n-звенный мир может оказаться очень сложным, если не невозможным.
В .Net безопасность, как и в новых технологиях Microsoft, ориентирована на корпоративную безопасность в среднем звене как никогда ранее, но многие компании все еще опираются на базы данных и либо не заботятся об изменениях, либо не хотят менятся.
Это рискованное утверждение. Настолько рискованная, что есть еще кое-что, что нужно сказать. Если вы администратор БД или разработчик, пожалуйста, не воспринимайте то, что я хочу сказать как стереотип или правду о всех администраторах баз данных. Однако, это превалирует и часто встречается. Если вы администратор БД, который не попадает под это описание – браво! Вы Президент баз данных, а не лорд баз данных.
Администраторы баз данных с работающей системой зачастую сопротивляются внесению каких-либо значительных изменений потому, что они могут сломать их систему. Многие организации имеют одного администратора и множество ассистентов. Администратор базы данных – король в своей вотчине и обладает последним словом во всем, что касается БД. И только менеджмент попытается взять верх над администратором, так тут же некомпетентный в проблемах базы данных менеджмент сдается администратору.
У многих администраторов БД очень мало знаний о том, зачем нужны изменения в сторону n-звенной архитектуры, или им просто всё равно. Для них любое звено всего лишь еще один клиент, и все для них клиент-серверная архитектура. Они заботятся лишь о работе базы данных и идут на сделку с разработчиками, только если она не доставит им каких-либо хлопот.
Администраторы баз данных не мигрируют по компаниям с такой частотой как разработчики, и многие из них руководят корпоративной базой данных на протяжении последних 10 и даже 20 лет. База данных очень важная для них вещь, и они не хотят идти ни на какие сделки. Они построили свое королевство и не хотят потерять контроль. Заставить такого администратора отдать часть безопасности и реализации можно только в серьезной битве и при поддержке менеджмента.
Другие администраторы не столь требовательны и пойдут на встречу всему, что сочтут разумным. Но во многих организациях, особенно крупных, есть сотни разработчиков и только один или парочка администраторов базы данных, и администраторы базы данных сидят на верхушке корпоративной цепочке команд.
Большая часть доступных сегодня инструментов, нестабильны или не предоставляют средств реализации бизнес логики. Многие инструменты акцентированы исключительно на масштабируемость, пул соединений и изоляцию базы данных, и не нацелены на реализацию потребностей бизнес логики.
Я обнаружил большую пользу в регулярном аудите архитектуры системы, при котором помечается некорректное размещение бизнес логики. Чем раньше они обнаружены, тем проще и дешевле их исправить. Если у вас нет специального главного архитектора, тогда разработчики из команды могут проверять друг друга. Если что-то найдено не в том месте, разработчик может оповестить команду и тимлидера.
Очень полезно обучать ассистентов администратора базы данных. Администраторы так долго реализовывали бизнес логику, что для них тяжело определить: где бизнес логика, а где хранилище. Ассистенты обычно делают только то, что от них требуют, как правило, следуя указаниям администратора.
Все равно процесс затронет ассистентов. Они пишут запросы, оптимизируют их и обслуживают базу данных. Также они должны отслеживать SQL, приходящий из среднего звена, и производительность БД. Ассистенты также продолжат проектировать архитектуру БД.
Часто встречается сопротивление менеджмента, хотя, это скорее простое препятствие, чем сложное. Менеджменту наплевать, стала ли легче ваша работа, но их заботят накладные расходы, время разработки, преимущества для бизнеса, ну и не плохо бы им рассказать о текущих потерях.
Основное препятствие на пути изменения менеджмента будет сопротивления администратора базы данных. Так что, сдайте менеджмент с потрохами и пусть они сами разбираются с администратором.
Основой этой статьи послужили шаблоны и методы, которые я использую почти десять лет. Конечно же, они постоянно пересматриваются и обновляются, чтобы получить преимущества новых технологий и быть адаптированными к изменениям в мире.
Во время своей работы, я прочитал много материала, написанного «экспертами». Большая часть их была написана разработчиками, хорошими в создании теорий и обучении других в том как надо делать, но никогда не применявшими свои собственные методы на практике. Другие были написаны опытными разработчиками с узким кругозором, а эти знания очень зависят от конкретного приложения. Когда разработчики читают такие материалы, они становятся уверенны в том, что есть только один путь решения проблемы. Разработчикам нужно мыслить шире и понимать, что описанное решение проблемы является только направлением, а не доктриной.
Я говорю об этом только потому, что очень редко можно найти что-то реально стоящее и не попасться в эти ловушки. Один из самых лучших материалов, которые я прочитал за прошедшие годы был написан в августе 2002 и это шаблоны и методики от Microsoft. Они очень хорошо составлены и согласуются с тем, что я описал здесь и в других моих статьях.
Пожалуйста, обратите внимание на Designing data tier components and passing data through tiers.
Изменение направления в больших компаниях является вопросом политически и высокого риска. С точки зрения разработчика проще лечь на дно и позволить другим грызть друг друга. Я сомневаюсь, что многие разработчики скажут нет своим проверенным методикам. В этой статье мне хочется дать вам несколько идей для реорганизации существующих у вас процессов, или хотя бы посмотреть на некоторые решения, которые обычно не обдумывались, более пристально.
Описанный подход наилучший для построения новых систем, или при изменении всей или части системы. На работающих системах лучше ничего не трогать до тех пор, когда какое-то обстоятельство не заставит вас заняться перестройкой.
UPD: по подсказке maovrn перенесено в «Проектирование и рефакторинг».
UPD1:
Для тех кто в танке:
1. На Хабре есть правила оформления переводов см. помощь
2. Для тех, кто не может осилить п.1. автор статьи Chad Z. Hower aka Kudzu
3. Для тех, кто читает только середину без начала и конца — статье три года. Потому, как минимум некорректно объявлять автора статьи безграмотным на основание того, что он не читал на момент публикации материалов, выпущенных после публикации.
4. Если данный апдейт вас задел — это ваши проблемы.
Отдельное спасибо автору, за разрешение отдельной публикации.
Крайне занятная статья о том, что такое бизнес логика и где ей жить. Статье, кстати, уже три года. А я нередко встречаю системы, где код от данных не отделен. Может привести к реальному холивару.
Где наша бизнес логика, сынок?
Введение
За годы развития мы продвинулись от десктопа к клиент-серверной архитектуре, потом к 3-х звенной конструкции, к n-звенной, к сервис ориентированной. Во время этого процесса многие вещи изменились, но многие привычки остались. Зачастую, сопротивление изменениям происходит от привычек. Однако, во многих случаях оно процедурное. Эта статья описывает, что мы делаем неправильно и возможные решения.
О статье
То, что я здесь опишу, один из методов построения n-звенных систем с точки зрения проектирования и архитектуры. Эта статья не фокусируется на коде. Есть много методов построения n-звенных систем, это только один из них. Если вы строите систему, я надеюсь, вы найдете хороший совет, методику или шаблон использования этого подхода.
Хотя данная статья может предлагать несколько отправных точек из «стандартных методов», все в этой статье базируется на Шаблонах и Методах Microsoft и описывается в Designing Data Tier Components and Passing Data through Tiers и других документах.
Даже если вы не решитесь применять все методологии, предложенные здесь, вам следует воспользоваться хотя некоторыми из них.
Цель
Спросите любого разработчика, где должна быть бизнес логика, и получите ответ: «Конечно же в бизнес слое».
Спросите того же разработчика, где находится бизнес логика в их организации, и снова услышите: «Конечно же в бизнес слое».
У вас не должно быть не малейших сомнений на счет того где должна быть бизнес логика – в бизнес слое. Не часть бизнес логики – вся бизнес логика должна быть в бизнес слое. После прочтения данной статьи, многие разработчики поймут что то, что они считали правдой о своих системах, таковой не является.
Термины
Эти термины часто используются вместе, но в данной статье я буду использовать их так, как опишу здесь.
Звено (tier)
Когда я использую слово звено, я подразумеваю физическое звено состоящее из физического сервера или группы серверов, выполняющих одинаковую функцию и сгруппированных только для повышения емкости.
Слой (layer)
Когда я использую слово слой, я подразумеваю сегмент системы, который ограничен собственным процессом или модулем. Множество слоев может содержаться в одном звене, но любой из них должен иметь возможность быть легко перенесенным на другое звено.
Развитие проблемы
Десктоп
На настольных приложениях бизнес логика содержится на одном звене со всеми остальными слоями. Т.к. нет необходимости разделять слои, они зачастую перемешаны и не имеют четких границ.

Клиент-сервер
В клиент-серверном приложении имеются два звена, что приводит к созданию как минимум двух слоев. На начальном этапе сервер рассматривался только как удаленная база данных, и деление было как на рисунке – приложение на клиенте и данные на сервере. Обычно вся бизнес логика находилась на клиенте, перемешанная с остальными слоями, такими как пользовательский интерфейс.

Достаточно быстро стало понятно, что можно сократить нагрузку на сеть и централизовать логику для уменьшения постоянных затрат на развертывание, перенеся большую часть бизнес логики на сервер. Архитектурно сервер был хорошо подготовленным местом в клиент-серверной системе, но база данных как платформа давала мало возможностей. Базы данных были спроектированы для хранения и выдачи и в их архитектуру не были заложены возможности расширения в направлении бизнес логики. Языки хранимых процедур в базах данных были разработаны для базовых преобразований данных, чтобы поддержать то, на что не хватало SQL. Языки хранимых процедур разработали для быстрого исполнения, а не для обслуживания сложных задач бизнес логики.
Но из двух зол эта была меньшей, и часть бизнес логики переехала в хранимые процедуры. На самом деле, я готов поспорить, что бизнес логика была ужата и вбита в рамки хранимых процедур, исключительно с прагматической точки зрения. В двух звеном мире – это было не идеальным, но все-таки гораздо лучшим.

3-звенка
Когда проблема клиент-серверной архитектуры стала явной, возросла популярность 3-х звенного подхода. Наибольшей и самой тяжелой проблемой того времени было количество подключений. Сейчас многие базы данных могут обрабатывать тысячи единовременных подключений, в девяностых большинство баз данных падали где-то на 500 подключений. Сервера зачастую лицензировались по кол-ву клиентских подключений. Это все и привело к тому, что потребовалось сократить количество подключений к базе данных.
Стало популярным объединение подключений в пул, однако для реализации пула подключений в системе с множеством отдельных клиентов, необходимо внедрить третье звено между клиентом и сервером. Среднее звено так и стало называться «среднее звено». В большинстве случаев среднее звено существовало только для управления пулом соединений, но в некоторых случаях бизнес логика начала перемещаться в среднее звено потому, что языки разработки (C++, VB, Delphi, Java) гораздо лучше подходили для реализации бизнес логики, чем языки хранимых процедур. Вскоре стало очевидно, что среднее звено –это наилучшее место для бизнес логики.
Также среднее звено предоставило возможность подключения клиентов с низкими скоростями, т.к. прямое соединение с базой данных, как правило, требует широкого канала и низкой задержки.
Что такое бизнес логика?
Прежде чем я продолжу, давайте четко определим: что же такое бизнес логика. Выступая с презентациями на конференциях и внутри компании, я начал опасаться того, что не все соглашаются с тем, чем является бизнес логика, и, довольно часто, даже не до конца понимают: что она есть, а что нет.
Сервер базы данных – это уровень хранения. Базы данных разработаны для хранения, получения и обновления данных с максимально высокой эффективностью. Функционал зачастую является СУПОм (Создать, Удалить, Получить, Обновить). Некоторые базы данных СУПОм и являются, но разговор не об этом.
Базы данных разработаны для того, чтобы очень быстро обслуживать эти операции. Они не разработаны для форматирования телефонных номеров, рассчитывать оптимальное использование и пиковые нагрузки, определять географическое местоположение и маршруты грузов, и так далее. Хотя, я видел все это и много более сложные задачи, реализованные только с помощью или большой частью на хранимых процедурах.
Удалить Покупателя
И все это относится не только к сложным вещам. Давайте представим себе простую задачу и такую, которую зачастую даже не относят к бизнес логике. Задача – Удалить Покупателя. Практически во всех системах, что я видел, удаление покупателя обрабатывается исключительно хранимой процедурой. Однако в удаление покупателя довольно многие решения должны быть приняты на уровне бизнес логики. Можно ли удалить покупателя? Какие процессы должны быть запущены до и после? Какие предосторожности должны быть соблюдены? Из каких таблиц записи должны быть удалены или обновлены в последствие?
Базе данных не должно быть дела до того, что такое покупатель, она должна заботиться только об элементах, используемых для хранения покупателя. У базы данных не должно быть возможности разобраться, какие таблицы должны хранить объект покупатель, и она должна работать с таблицами не обращая внимания на объект покупатель. Задача базы данных – хранить ряды в таблицах, которые описывают покупателя. Кроме базовых ограничений вроде каскадной целостности, типов данных, индексов и пустых значений, база данных не должна иметь функционального знания о том, что же из себя представляет покупатель в бизнес слое.
Хранимые процедуры, если они есть, должны оперировать только одной таблицей; исключение – это процедуры запрашивающие выборку из нескольких таблиц для выдачи данных. В этом случае, хранимые процедуры работают как представления (view). Представления и хранимые процедуры должны использоваться для консолидации значений, но исключительно для более быстрой и эффективной работы с данными в бизнес слое.
Но даже в компаниях, гордящихся новейшими достижениями в разработках и технологиях, и в тех, что с пеной у рта кричат о всей их бизнес логике в бизнес слое, короткий анализ базы данных быстро выявляет: удалить покупателя, добавить покупателя, заблокировать покупателя, заморозить покупателя и т.д. и т.п. И не только с покупателем, но и с многими другими объектами бизнес логики.
Я часто встречал хранимые процедуры вроде этой:
sp_DeleteCustomer(x)
Select row in customer table, is Locked field
If true then throw error
Sum total of customer billing table
If balance > 0 then throw error
Delete rows in customer billing table (A detail table)
if Customer table Created field older than one year then
Insert row in survey table
Delete row in customer table
Регулярно часть бизнес логики отъезжает в бизнес слой.
Business Layer (C#, etc)
Select row in customer table, is Locked field
If true then throw error.
Sum total of customer billing table
If balance > 0 then throw error.
if Customer table Created field older than one year then
Insert row in survey table
Call sp_DeleteCustomer
sp_DeleteCustomer(x)
Delete rows in customer billing table (A detail table)
Delete row in customer table
В этом случае, часть бизнес логики была перемещена, но не вся. Некоторые таблицы обрабатываются и в слое бизнес логики. База данных не должна иметь ни малейшего представления о том, какие таблицы формируют покупателя в бизнес слое. Для всех трех операций, бизнес слой должен выдать SQL команду или вызвать три отдельные хранимые процедуры для реализации функционала в приведенной sp_DeleteCustomer.
Передав всю бизнес логику в бизнес слой, мы получим:
Business Layer (C#, etc)
Select row in customer table, is Locked field
If true then throw error.
Sum total of customer billing table
If balance > 0 then throw error.
if Customer table Created field older than one year then
Insert row in survey table
Call sp_DeleteCustomer
Delete rows in customer billing table (A detail table)
Delete row in customer table
Удаление рядов может использовать хранимую процедуру, если они из одной таблицы. Однако, в современных базах данных, использующих кэширование запросов, это является несущественным улучшением производительности. К тому же, SQL, генерируемый такими системами очень прост, т.к. он работает с одной таблицей, и потому практически не требует оптимизации. На самом деле, базе данных становится не очень хорошо от слишком большого количества загруженных хранимых процедур, а простые SQL команды на них так не действуют.
Переведя даже модификацию таблиц в бизнес слой, мы получим следующие преимущества:
- Перенос базы данных может быть осуществлен с меньшими усилиями, т.к. все эти хранимые процедуры не нужно отлаживать для каждой СУБД.
- Модификация проще, т.к. вся логика содержится в одном слое, а не в двух.
- Отладка проще – логика не размазана по двум слоям.
- Другая логика не сможет проскользнуть в хранимую процедуру только потому, что «так проще».
В виду того, что такой метод требует три успешных обращения к базе данных вместо одного, ваш узел бизнес логики должен быть подключен к базе данных по отдельному высокоскоростному сегменту, типа гигабита. Отправка 300 байт вместо 100 байт станет непринципиальной. Большинство баз данных поддерживают пакетную передачу SQL запросов, и все три запроса могут быть посланы в одном пакете, уменьшив нагрузку на сеть. Для выдачи таких запросов следует использовать слой доступа к данным, а не включать запросы прямо в код.
Некоторые администраторы баз данных и даже разработчики могут не принять этот уровень интеграции и настаивать на реализации таких пакетных обновлений в хранимых процедурах. Это выбор, который вы должны сделать, и он очень зависит от вашей базы данных и ваших приоритетов. Т.к. практически все современные базы данных используют механизмы кэширования запросов, выигрыш в производительности в большинстве случаев минимален, а четкие технологические причины не нагружать логикой хранимые процедуры есть. Если вы выберите оставить такие пакетные обновления в хранимых процедурах, вы должны быть очень осторожны, чтобы не допустить проскальзывания другой бизнес логики в хранимые процедуры, и ограничить свои хранимые процедуры СУПОвыми операциями, без каких либо условных операций и другой бизнес логики.
Форматирование
Давайте разберем еще один пример, обнаруженный мной и сеющий зерна войны среди разработчиков – является это бизнес логикой или нет. Я расскажу, почему я считаю это бизнес логикой, а не пользовательским интерфейсом или хранением. Этот пример не относится к легко реализуемому форматированию. Пример, который я буду использовать, — телефонные номера.
Каждая страна имеет свой собственный формат отображения телефонных номеров в приятной глазу манере. В некоторых странах их даже больше одной. Ниже несколько примеров:
Кипр:
+357 (25) 66 00 34
+357 (25) 660 034
+357 25 660 034
+357 2566 0034
Германия:
+49 211 123456
+49 211 1234-0
Северная Америка (США, Канада)
+1 (423) 235-2423
+1-423-235-2423
Россия:
+7 (812) 438-46-02
+7 (812) 438-4602
В Германии есть даже специальный официальный стандарт для форматирования – DIN 5008.
Конечно же, код страны отбрасывают при локальном использовании. Но давайте предположим, что у вас интернациональная система и необходимо хранить и отображать код страны. Для каждой страны мы выберем один формат отображения.
Договоримся форматировать телефоны следующим образом:
- Данные поступают в различных форматах.
- У каждой страны есть свой уникальный способ отображать телефоны.
- Форматы некоторых стран не просты и меняются в зависимости от первых цифр.
- Первые несколько цифр (обычно код страны и региона) не всегда имеют фиксированную длину. Например, в России, 812 – код города Санкт-Петербург, 495 – Москва, но некоторые регионы имеют 4 знака (3952). Это приводит и к изменению и общей длины, и формата, в зависимости от регионального кода.
- При выходе новых законов, появлении новых операторов, интеграции Евросоюза, обновления телефонных систем и еще множестве всего, форматы и длины телефонов меняются довольно часто в глобальном масштабе. За недавнее время Кипр сменил свой код страны дважды: один раз при обновление системы, второй раз из-за возросшего числа сотовых операторов. Имея сотни стран во всем мире, следует ожидать изменений на регулярной основе.
Обычно делается следующее, все не цифровые символы убираются и номер становится похожим на:
Phone: 35725660034
Иногда отделяется код страны и номер становится таким:
PhoneCountry: 357
PhoneLocal: 25660034
Кажется простым, но это еще одна задача для бизнес логики. Не все страны имеют код одинаковой длины. Коды стран могут быть от 1 до 3 знаков.
Зачастую обработка ввода (если код страны отделен) и логика отображения реализованы на клиенте, т.к. клиент написан на традиционном языке, который хорошо для этого подходит. Проблема в том, что клиенту требуется огромное количество данных для определения длины кодов стран, и потребуется обновление клиента каждый раз, когда изменился формат отображения.
Иногда форматирование осуществляется в хранимой процедуре. Проблема этого подхода в том, что языки хранимых процедур, не приспособленны для такого типа логики, и он часто приводит к багам и тормозам в работе с настоящей логики.
Еще чаще телефонные номера хранятся дважды. Один раз в чистом виде для хорошей индексации и поиска, и второй – в отформатированном для отображения. В дополнении к проблемам, описанным выше, получаем проблемы избыточных записей и обновления.
У особо изощренных экстрималов, встречающихся до смешного часто, телефонный номер хранится в том формате, в котором поступил. Проблема очевидна: телефоны нельзя быстро найти, проиндексировать или отсортировать.
Важно то, что хотя это и форматирование, оно не относится к пользовательскому интерфейсу, а попытка тотальной централизации может пристрелить базу данных. Это однозначно бизнес логика. Реализация форматирования в бизнес слое не допустит дублирования данных и будет написана на языке разработки, а не вбита в язык обработки данных.
Исключения
Некоторые пакетные обновления выполняются во много раз быстрее, будучи реализованными с помощью хранимых процедур. В большинстве случаев можно обойтись простым SQL, но некоторые типы пакетных обновлений требуют циклов и при реализации в бизнес слое создадут тысячи SQL команд. В таких редких случаях, должна быть использована хранимая процедура, даже если в ней нужно реализовать бизнес логику. Нужно обратить особое внимание на то, чтобы в ней был реализован только необходимый минимум.
Я еще вернусь в статье к этой проблеме.
Сегодняшние системы
Клиент-сервер
В клиент-серверных приложениях бизнес логика обычно имеется и на клиенте, и на сервере.
Реальное соотношение будет меняться от приложения и компании, предыдущий пример хорошо описывает клиент-серверные приложения. Большая часть бизнес логики была реализована в хранимых процедурах и представлениях в попытке централизовать бизнес логику. Однако многие бизнес правила не могут быть реализованы просто на SQL или хранимыми процедурами, или их быстрее выполнять на клиенте, так как они основываются на интерфейсе пользователя. Из-за этих противоположных факторов бизнес логика распределена между клиентом и сервером.
N-звенка
По многим причинам, которые я опишу позже в отдельной статье, при построении n-звенных систем ситуация становится только хуже в плане консолидации бизнес логики. Вместо консолидации, бизнес логика становится еще более фрагментированной.
Конечно же, каждая система имеет отличия в том, как бизнес логика распределяется по слоям, но есть одно общее для всех. Бизнес логика сейчас распределяется по трем слоям вместо двух. Далее я представлю несколько типичных сценариев.
Сценарий 1
Типичное распределение бизнес логики по n-звенной системе:

В таких случаях бизнес слой не содержит бизнес правил. Это не настоящий бизнес слой, а только форматер XML (или другого потокового формата) и адаптер наборов данных базы данных. Хотя некоторые плюсы такие как: пул соединений и изоляция БД, могут быть достигнуты, это не настоящий слой бизнес логики. Это скорее инородный физический слой без слоя логики.
Сценарий 2
Другой типичный сценарий:

Обычно некоторые бизнес правила приложения переходят в бизнес слой, но то, что было в базе данных, так в ней большей частью и остается.
При повторном использовании бизнес слоя в таких разработках бизнес правила должны повторяться и в клиентском приложении. Это сводит на нет основную цель внедрения бизнес слоя.
Также у клиентских приложений появляется возможность не выполнять бизнес правила, не реализуя их или просто игнорируя. При наличие настоящего бизнес слоя, это невозможно.
Консолидация
Вместо всего вышеперечисленного, бизнес слой должен содержать все бизнес правила.

Такая разработка имеет следующие преимущества:
- Вся бизнес логика находится в одном месте и может быть легко проверенна, отлажена и изменена.
- Нормальный язык разработки может быть использован для реализации бизнес правил. Такие языки более гибкие и более подходят для бизнес правил, чем SQL и хранимые процедуры.
- База данных становится слоем хранения и может заниматься эффективным получением и хранением данных без ограничений относящихся к слою бизнес логики или представления.
Приведенный сценарий – это цель. Однако, некоторое дублирование, особенно для проверки данных, должно быть и на клиенте. Эти правила должны быть поддержаны и бизнес слоем. Кроме этого, в некоторых системах отдельные высоко емкие операции, такие как пакетные обновления, могут привести к исключениям и должны быть размещены в базе данных. Потому более реалистичных подход представлен ниже. Обратите внимание, что вся бизнес логика должна быть реализована в бизнес слое, и те минимальные наборы, присутствующие в других слоях, являются просто дублями исключительно для повышения производительности или отключения тех или иных компонент пользовательского интерфейса.

Переезд на центральный узел
Скользкий путь
При переходе на центральный узел всегда есть искус «реализовать эту часть в хранимой процедуре». Потом «ту» и «вот эту». И скоро вы окажетесь в той же ситуации, что и были, без существенных изменений.
Хранимые процедуры должны использоваться для выполнения SQL и получения наборов данных в базах данных, которые оптимизируют хранимые процедуры лучше, чем представления. Но хранимые процедуры не должны быть использованы ни для чего другого, нежели объединения и выдачи данных. При обновлении данных она должна именно и только обновлять, но не интерпретировать данные каким-либо образом.
Есть задачи, где для повышения производительности некоторые компоненты должны быть помещены в хранимую процедуру. Но такие задачи на самом деле достаточно редки и они должны быть исключением, а не правилом. Каждое исключение должно быть проверенно и одобрено, а не просто реализовано по воле разработчика или администратора базы данных.
Дешевле
Звучит несколько странно, что покупка железа может сделать дешевле. Но при внедрении серверов среднего звена, практически никакого дополнительного ПО, кроме ОС, не требуется. А стоимость наращивания мощности сервера базы данных существенна по следующим причинам:
- Сервера баз данных, как правило, более высокого класса, чем сервера среднего звена, и стоят дороже.
- Базы данных зачастую лицензируются на процессор и добавление процессора – дорогостоящая процедура в терминах лицензий. Лицензионные сборы могут составлять от 5000 до 40000 долларов на процессор.
При переносе логики на среднее звено, вы можете существенно сократить нагрузку на базу данных и предотвратить преждевременное наращивание ее мощностей.
Проще
В добавление к стоимости, обновление среднего звена обычно проще чем обновление базы данных.
У баз данных есть врожденный предел того, на сколько они могут быть увеличены простым добавлением железа. В какой-то момент нужно начинать использовать другие технологии вроде деления, кластеризации, репликации и т.п. Но ни одна из этих технологий не является простой, и все требуют существенных вложений в железо, миграцию и сильно влияют на существующие системы.
Наращивать же сервера среднего звена гораздо проще. Как только запущен механизм распределения нагрузки, все сводится к задаче добавить новый сервер.
Топология
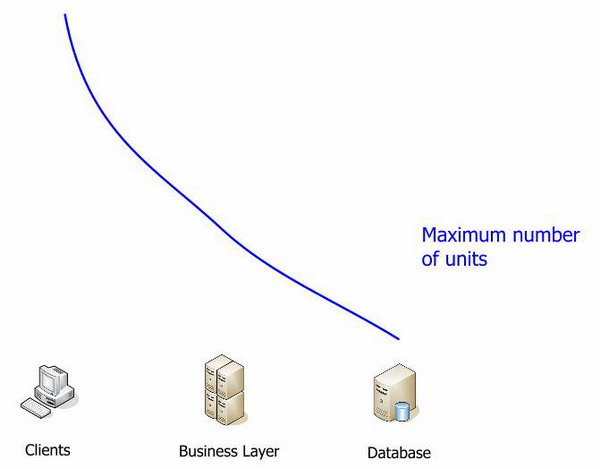
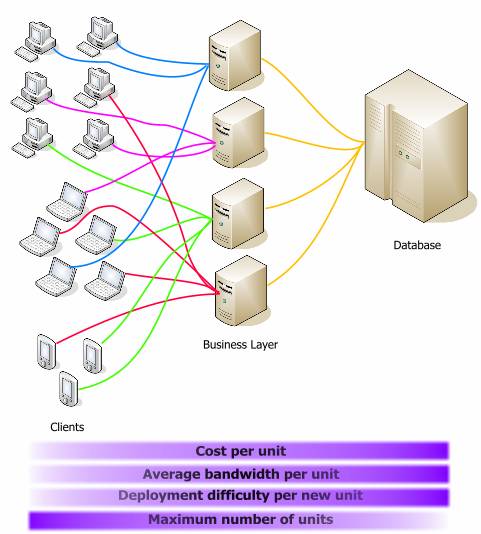
Давайте рассмотрим утверждения, которые я только что привел, используя следующую диаграмму. Заливка в сегментах показывает направление или важность их названия в отношении звеньев на диаграмме. Цена единицы возрастает, когда мы движемся от клиента, к среденму звену, к базе данных. Я использую слово единица для обозначения процессора или сервера, в зависимости от конфигурации.
(сверху вниз: цена единицы, средняя полоса пропускания, сложность развертывания, количество)
Если те же данные привести в относительных значениях, их можно легко сравнить:
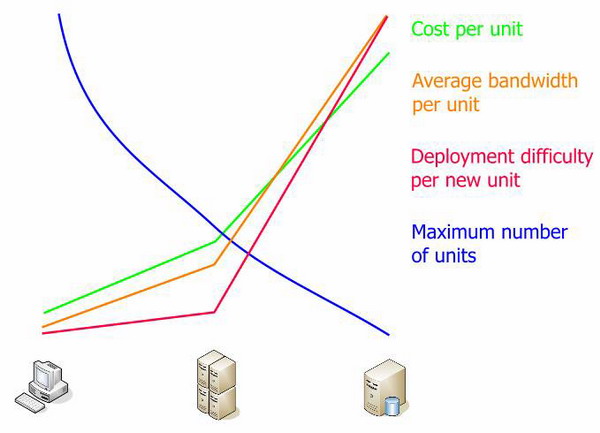
Я не привел цифры на графиках потому, что они очень зависят от конфигурации сети, мощности процессоров и других факторов, уникальных для каждой организации. Каждая функция использует свои единицы измерения. Я представил лишь общее взаимоотношение измерений. Оно хорошо показывает, что среднее звено имеет емкость для роста и гораздо дешевле базы данных.
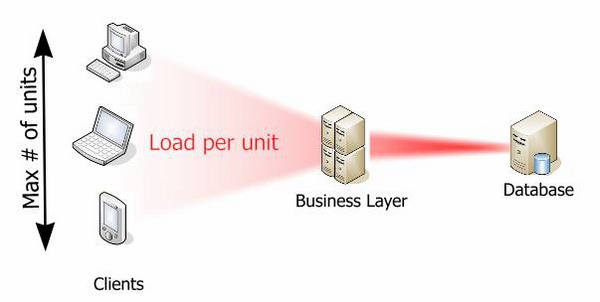
Вырасти середину
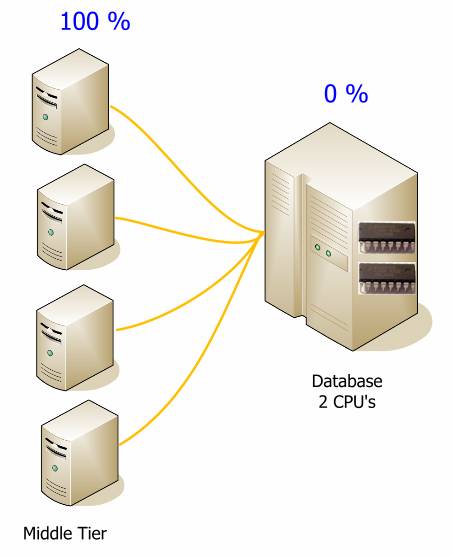
Если большая часть бизнес логики реализована в базе данных, вам будет нужна более мощная база данных.

При переносе логики в среднее звено, вы можете серьезно снизить нагрузку на базу данных. Цифры представленные здесь, приведены только для демонстрации и будут меняться от системы к системе, но они могут помочь уловить идею. Хотя на следующей диаграмме и больше аппаратуры, суммарная стоимость системы будет меньше, и ее будет проще развернуть. Гораздо дешевле и проще наращивать среднее звено.
Бутылочное горлышко
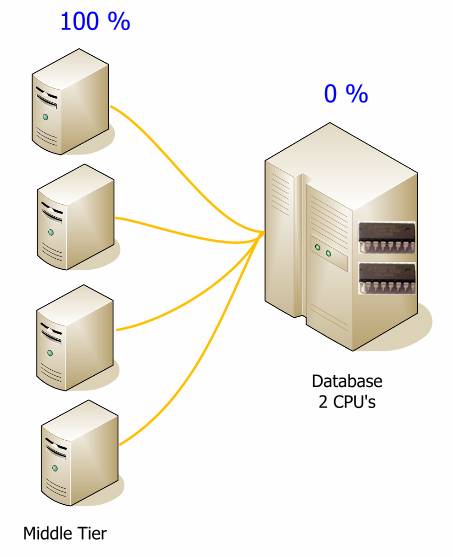
Давайте посмотрим еще раз на один из предыдущих графиков:
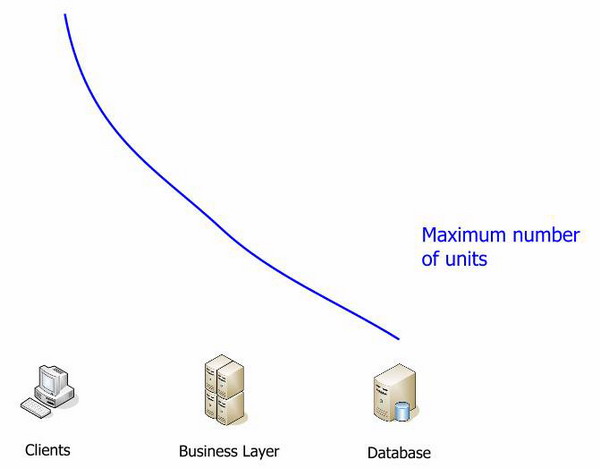
Какое единственное узкое место в системе? Какое из звеньев имеет выраженный предел наращивания? Это однозначно база данных. Все упирается в базу данных.

Потому перемещая вычисления в среднее звено, мы может отойти от границ слоя данных.
Сложности
Есть несколько сложностей для перехода в среднее звено, и не все они заключаются в том, что нужно по-разному программировать.
Привычки
Есть поговорка: «сложно избавиться от старых привычек». Это применимо и к команде. В команде вам нужно убедить не только себя, но и большинство команды.
Процедуры
Многие компании имеют устоявшиеся политики безопасности, предписывающие обеспечение безопасности в базе данных, а использование хранимых процедур в качестве представлений не дает достаточного контроля. Изменение корпоративных политик безопасности для перехода в n-звенный мир может оказаться очень сложным, если не невозможным.
В .Net безопасность, как и в новых технологиях Microsoft, ориентирована на корпоративную безопасность в среднем звене как никогда ранее, но многие компании все еще опираются на базы данных и либо не заботятся об изменениях, либо не хотят менятся.
Администраторы баз данных
Это рискованное утверждение. Настолько рискованная, что есть еще кое-что, что нужно сказать. Если вы администратор БД или разработчик, пожалуйста, не воспринимайте то, что я хочу сказать как стереотип или правду о всех администраторах баз данных. Однако, это превалирует и часто встречается. Если вы администратор БД, который не попадает под это описание – браво! Вы Президент баз данных, а не лорд баз данных.
Администраторы баз данных с работающей системой зачастую сопротивляются внесению каких-либо значительных изменений потому, что они могут сломать их систему. Многие организации имеют одного администратора и множество ассистентов. Администратор базы данных – король в своей вотчине и обладает последним словом во всем, что касается БД. И только менеджмент попытается взять верх над администратором, так тут же некомпетентный в проблемах базы данных менеджмент сдается администратору.
У многих администраторов БД очень мало знаний о том, зачем нужны изменения в сторону n-звенной архитектуры, или им просто всё равно. Для них любое звено всего лишь еще один клиент, и все для них клиент-серверная архитектура. Они заботятся лишь о работе базы данных и идут на сделку с разработчиками, только если она не доставит им каких-либо хлопот.
Администраторы баз данных не мигрируют по компаниям с такой частотой как разработчики, и многие из них руководят корпоративной базой данных на протяжении последних 10 и даже 20 лет. База данных очень важная для них вещь, и они не хотят идти ни на какие сделки. Они построили свое королевство и не хотят потерять контроль. Заставить такого администратора отдать часть безопасности и реализации можно только в серьезной битве и при поддержке менеджмента.
Другие администраторы не столь требовательны и пойдут на встречу всему, что сочтут разумным. Но во многих организациях, особенно крупных, есть сотни разработчиков и только один или парочка администраторов базы данных, и администраторы базы данных сидят на верхушке корпоративной цепочке команд.
Инструментарий
Большая часть доступных сегодня инструментов, нестабильны или не предоставляют средств реализации бизнес логики. Многие инструменты акцентированы исключительно на масштабируемость, пул соединений и изоляцию базы данных, и не нацелены на реализацию потребностей бизнес логики.
Решения
Архитектура
Я обнаружил большую пользу в регулярном аудите архитектуры системы, при котором помечается некорректное размещение бизнес логики. Чем раньше они обнаружены, тем проще и дешевле их исправить. Если у вас нет специального главного архитектора, тогда разработчики из команды могут проверять друг друга. Если что-то найдено не в том месте, разработчик может оповестить команду и тимлидера.
Обучение ассистентов
Очень полезно обучать ассистентов администратора базы данных. Администраторы так долго реализовывали бизнес логику, что для них тяжело определить: где бизнес логика, а где хранилище. Ассистенты обычно делают только то, что от них требуют, как правило, следуя указаниям администратора.
Все равно процесс затронет ассистентов. Они пишут запросы, оптимизируют их и обслуживают базу данных. Также они должны отслеживать SQL, приходящий из среднего звена, и производительность БД. Ассистенты также продолжат проектировать архитектуру БД.
Обучение менеджеров
Часто встречается сопротивление менеджмента, хотя, это скорее простое препятствие, чем сложное. Менеджменту наплевать, стала ли легче ваша работа, но их заботят накладные расходы, время разработки, преимущества для бизнеса, ну и не плохо бы им рассказать о текущих потерях.
Основное препятствие на пути изменения менеджмента будет сопротивления администратора базы данных. Так что, сдайте менеджмент с потрохами и пусть они сами разбираются с администратором.
Что еще почитать
Основой этой статьи послужили шаблоны и методы, которые я использую почти десять лет. Конечно же, они постоянно пересматриваются и обновляются, чтобы получить преимущества новых технологий и быть адаптированными к изменениям в мире.
Во время своей работы, я прочитал много материала, написанного «экспертами». Большая часть их была написана разработчиками, хорошими в создании теорий и обучении других в том как надо делать, но никогда не применявшими свои собственные методы на практике. Другие были написаны опытными разработчиками с узким кругозором, а эти знания очень зависят от конкретного приложения. Когда разработчики читают такие материалы, они становятся уверенны в том, что есть только один путь решения проблемы. Разработчикам нужно мыслить шире и понимать, что описанное решение проблемы является только направлением, а не доктриной.
Я говорю об этом только потому, что очень редко можно найти что-то реально стоящее и не попасться в эти ловушки. Один из самых лучших материалов, которые я прочитал за прошедшие годы был написан в августе 2002 и это шаблоны и методики от Microsoft. Они очень хорошо составлены и согласуются с тем, что я описал здесь и в других моих статьях.
Пожалуйста, обратите внимание на Designing data tier components and passing data through tiers.
Заключение
Изменение направления в больших компаниях является вопросом политически и высокого риска. С точки зрения разработчика проще лечь на дно и позволить другим грызть друг друга. Я сомневаюсь, что многие разработчики скажут нет своим проверенным методикам. В этой статье мне хочется дать вам несколько идей для реорганизации существующих у вас процессов, или хотя бы посмотреть на некоторые решения, которые обычно не обдумывались, более пристально.
Описанный подход наилучший для построения новых систем, или при изменении всей или части системы. На работающих системах лучше ничего не трогать до тех пор, когда какое-то обстоятельство не заставит вас заняться перестройкой.
UPD: по подсказке maovrn перенесено в «Проектирование и рефакторинг».
UPD1:
Для тех кто в танке:
1. На Хабре есть правила оформления переводов см. помощь
2. Для тех, кто не может осилить п.1. автор статьи Chad Z. Hower aka Kudzu
3. Для тех, кто читает только середину без начала и конца — статье три года. Потому, как минимум некорректно объявлять автора статьи безграмотным на основание того, что он не читал на момент публикации материалов, выпущенных после публикации.
4. Если данный апдейт вас задел — это ваши проблемы.