

— Смета была 200 миллионов рублей, а стала 650 миллионов! Вы обалдели?
По слухам, именно так начался этот проект на совете директоров банка. Курсовая разница по одной из поставок серверов составляла 450 миллионов рублей. Естественно, хотелось как-то уменьшить эти затраты.
Долгое время считалось, что архитектура x86 «из коробки» не предназначена для серьёзных вычислений. Самые серьёзные в мире вычисления (по нагрузке и требованиям к надёжности) — это банковское ядро, процессинг. Там не закончить считать вовремя 2–3 операционных дня подряд означает просто закрытие банка (и проблемы с банковской системой страны) из-за возникающего разрыва, который догнать уже невозможно.
Один банк из ТОП-10 ещё пару лет назад планировал докупить себе машин P-серии, известных своей надёжностью, масштабируемостью и производительностью. Про x86 там даже не думали, пока не настал кризис. Но кризис настал. Одна машина за 5–7 миллионов долларов (а нужна даже не одна и не две) — это немного перебор. Поэтому руководство решило тщательно изучить вопрос замены RISC на x86.
Ниже — сравнение двух подобных конфигураций (они не совсем одинаковые): P-серия с RISC-процессорами с ядрами на 4 ГГЦ из расчёта одно RISC-ядро на два ядра x86 2.7 ГГЦ. Всё это мы смонтировали в машзале дата-центра банка, загнали туда реальную базу, показывающую несколько банковских дней за прошлый год (у них есть специально заготовленная среда для тестов, полностью симулирующая реальность и полноценную нагрузку от транзакций, банкоматов, запросов и т. п.), и выяснили, что x86 подходит и стоит в разы дешевле.

В правом углу ринга
RISC-машины хороши своей способностью делать вычисления быстро и надёжно. До появления кластеров, как описано ниже, других альтернатив в банковском ядре не было — не получалось масштабироваться. Кроме того, RISC-машины лишены традиционного недостатка x86 при высокой нагрузке — у них не падает производительность при долгой постоянной нагрузке выше 70–80%. Но, учитывая редкость решений, цена соответствует. Плюс банки всегда берут расширенный сервис на поставку частей, а это сравнимо со стоимостью самой машины на 3 года (30% от стоимости закупки за год). Ещё одна особенность — апгрейд методом выкидывания старой железки. Например, P-серия трёхлетней давности сейчас часто списывается просто в тестовые среды, потому что боевого применения в системах ядра ей нет — надо закупать новые машины постоянно. Естественно, производители всячески мотивируют на «апгрейд покупкой» — тем и живут. Частый способ — повысить стоимость расширенной поддержки для машин старше 3 лет.
Вот график поставки таких машин по миру:

А вот соотношение стоимости покупки к операционным затратам:

В левом углу ринга
У HPE нашлось подходящее архитектурное решение Superdome — классическая реализация архитектуры ccNUMA на базе системного коммутатора «процессорных шин» с возможностью свободного расширения при добавлении ядер. До этой архитектуры фактически x86-кластеры так или иначе быстро упирались в свои пределы увеличения мощности из-за больших издержек на перетаскивание данных между ядрами.
По масштабируемости — это х86 блейды, соединённые между собой:

ОС — RED HAT + Oracle. Стоимость — в разы ниже, чем для RISC-архитектуры, поскольку все детали крупносерийные и широко распространены по рынку. Плюс лицензии выходят дешевле. Стоит добавить, что цена сервиса тоже существенно привлекательнее, поскольку и архитектура куда менее «шаманистая».
Немного гикпорна:

BL920s Gen9 Server Blade Memory Subsystem
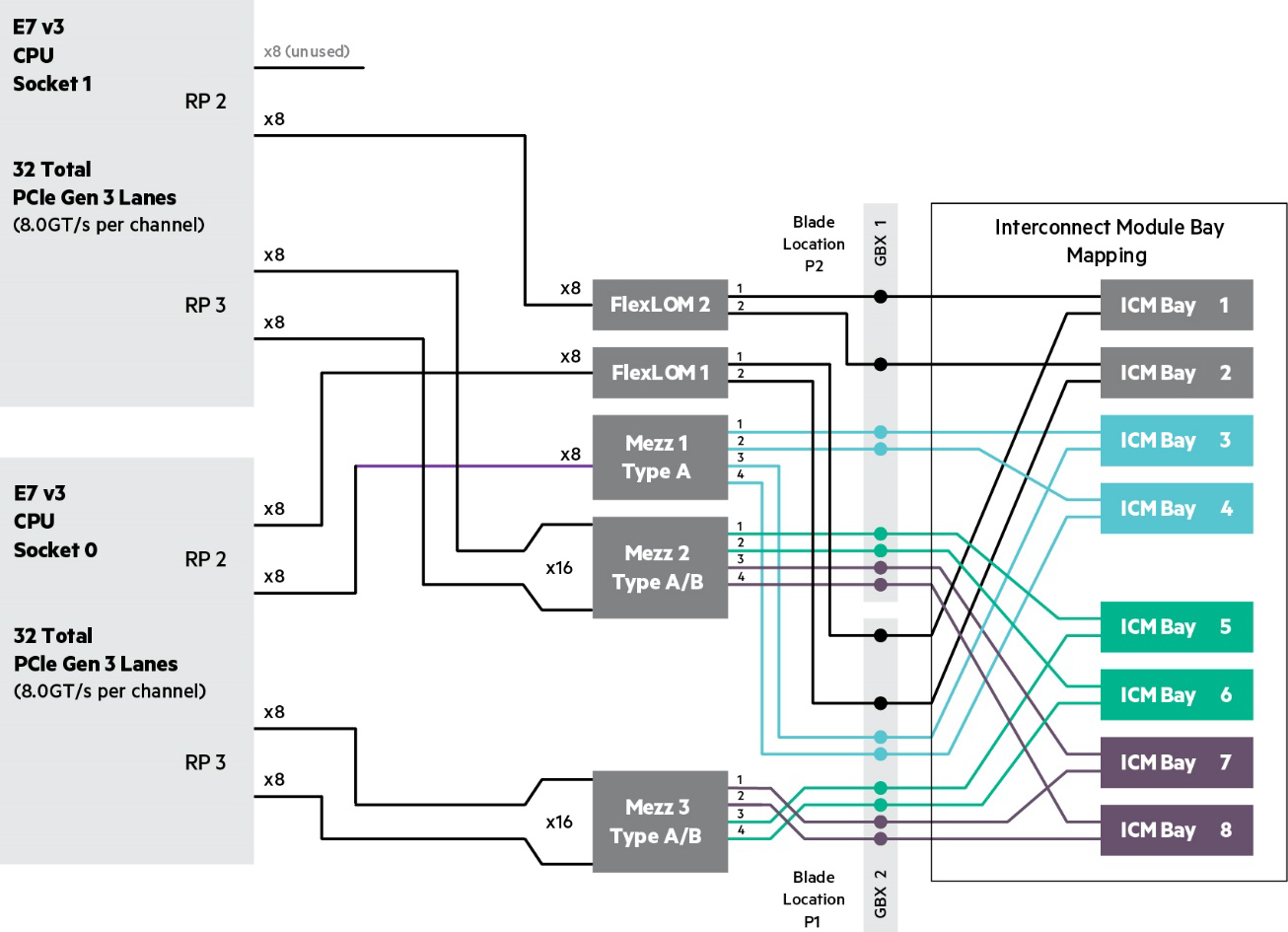
BL920s Gen9 Server Blade I/O Subsystem
Наша тестовая сборка: Integrity Superdome X, 8 x Intel Xeon E7-2890 v2, (15c / 2.8 GHz / 37.5 M / 155 W), ОЗУ
2048 GB (64 x 32 GB PC3-14900 DDR3 ECC registered Load Reduced DIMMs), Linux Red Hat 7.1, Oracle 11.2.0.4 с данными на Oracle ASM, порты 1 GbE: 4 x 1G SFP RJ45; 10GbE: 4 x 10G SFP+; 16 Gb FC: 8 x 16Gb SFP+. С ней СХД HDS VSP G1000, не менее 40K IOPS, для нагрузки, ориентированной на запись, 16 LUN по 2TB каждый, два порта по 8Gb.
Вот схема тестового стенда (часть названий замазана, это всё же банк):


Короткое резюме
x86-кластер явно может то же самое, что «тяжёлые» RISC-машины. С некоторыми особенностями, но может. Выигрыш — уменьшение итоговой стоимости владения на порядок. Ради этого стоит поковыряться и разобраться.
Да, чтобы переехать на x86, надо будет мигрировать с ОС AIX (это UNIX-подобная проприетарная операционная система) на Linux, скорее всего, в сборке RED HAT. И с одного Oracle на другой Oracle. Если для бизнеса вроде розницы это реальная сложность, то банковские коллеги восприняли всё прагматично и спокойно. И пояснили, что работа с ядром банка — это всё равно постоянная миграция с одних машин и систем на другие каждый год, и процесс не прекращается. Так что они ради той кучи денег, которую даст внедрение x86, готовы и не на такое. И с AIX на Linux они уже переходили, небольшой опыт есть. И некоторым их наследуемым подсистемам уже по 10 лет — в банке это настоящее окаменелое legacy, которое нужно поддерживать.
И поддерживают, не впервой.
Что касается нашей тестовой машины, то она пользуется дичайшим спросом. Из этого ТОП-10 банка она уже переехала в другой, где идёт похожая программа тестов. Следом — ещё один банк из десятки, а потом очередь из нескольких банков первой тридцатки. До ближайшей зимы вряд ли освободится, но ещё одна тестовая сборка есть у HPE, с ней вроде поспокойнее.
Ссылки:
- На CNEWS умными длинными словами
- Документы на Супердом: архитектура и спека Integrity Superdome X.
- Полезная ссылка — Server Performance Benchmarks — для просмотра результатов тестов и отчётов по ним для всех моделей серверов HPE. Просто выберите Superdome X и смотрите на рекордные результаты.
- Моя почта — YShvydchenko@croc.ru.
Да, решение — банк систему внедряет.
