 В этой статье рассматривается альтернативный подход к созданию приложений и реализации структуры базы данных.
В этой статье рассматривается альтернативный подход к созданию приложений и реализации структуры базы данных. Основная идея этого подхода состоит в том, что процесс разработки приложения строится на анализе отчётов, которые должны будут генерироваться готовым бизнес-приложением.
Мы называем такой подход RDD — Report-Driven Design.
В начале был отчёт
В Developer Express мы занимаемся созданием разных компонентов, в том числе реализующих то, что принято называть Business Intelligence или Business Analitycs, а именно анализом и обработкой данных. Поэтому у нас есть большой опыт общения с пользователями, создающими бизнес-приложения, и одной из основных задач для этих пользователей является генерация отчётов.
Общаясь с этими пользователями, мы неожиданно для себя открыли ряд проблем, которые часто возникают при реализации модуля отчётов в типичном бизнес-приложении.
Например, часто бывает так, что в приложении реализовано уже почти всё. И вот, когда приходит время для создания отчётов, обнаруживается, что сделать многие из них довольно проблематично.
В основном это происходит потому, что при проектировании базы данных не были продуманы какие-то связи. Или наоборот, база данных чрезмерно усложнена: в таблицах существует много лишних связей, большинство из которых не используется для создания отчётов.
К тому же, эта проблема может выражаться в том, что из-за неоптимальной структуры базы данных обработка SQL запросов для создания отчётов выполняется слишком долго. Такое могло случиться, например, потому что изначально обращалось больше внимания на то, как будет вводиться информация, а не на то, как лучше её выводить.
Согласитесь, такое случается довольно часто. Тогда встаёт резонный вопрос: «А почему бы не позаботиться об отчётах с самого начала? Почему бы не сделать их главной целью при проектировании приложения, если это именно то, что нам нужно в итоге?»
Что такое отчёт?
Давайте для начала определимся, что мы будем понимать под отчётом.
Какие ассоциации возникают у вас в голове при слове отчёт? Наверное, это страницы с какими-то данными, представленными в табличном или ином виде, который удобен для дальнейшего анализа.
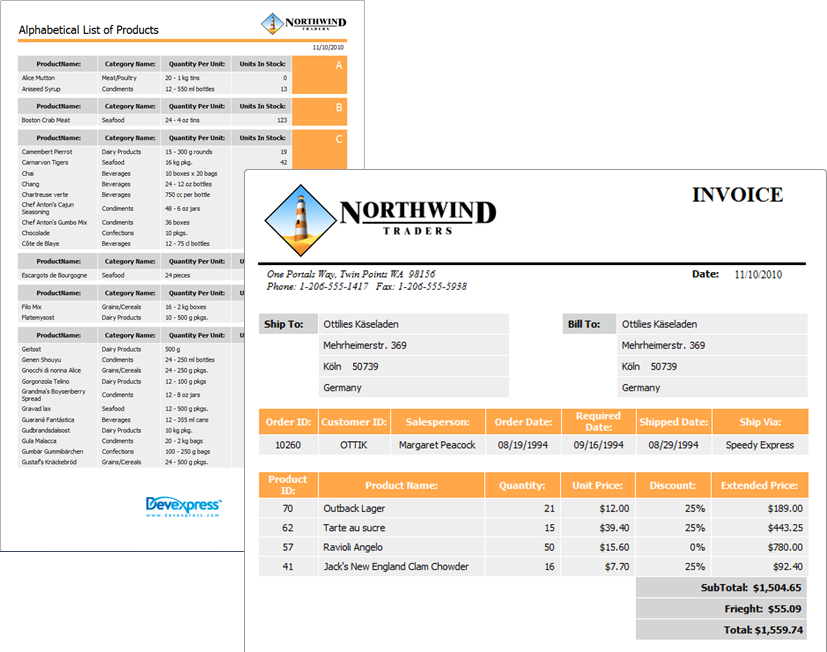
При этом совершенно понятно, что отчёт — это вовсе необязательно печатный вариант. Это может быть и какой-то файл, будь то xls, pdf, doc или даже веб-страница. Понятно, что отчёт может содержать не только табличные или кросс-табличные данные (так называемые pivot tables), но и графики, и много другой информации, которая тоже может быть полезна для анализа.
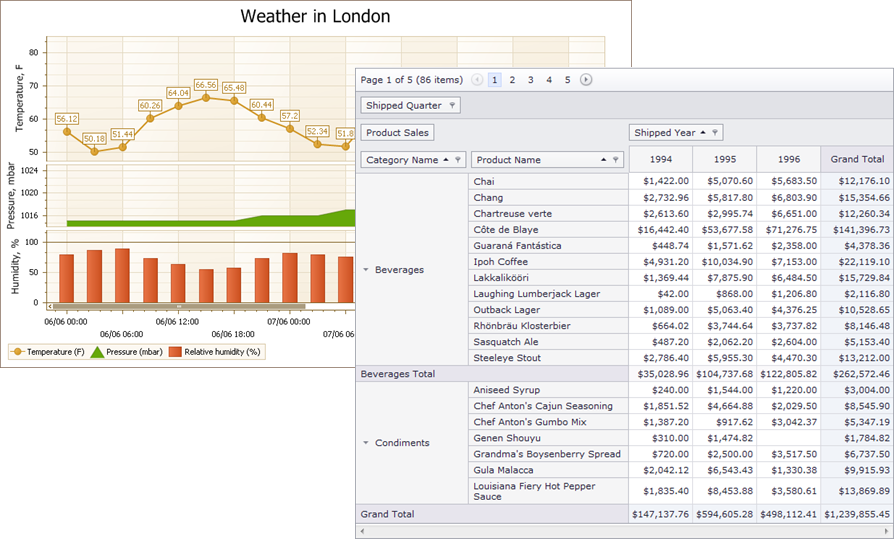
Таким образом, под отчётом мы понимаем любую страницу с информацией.
Четыре «I»
Итак, что же представляет собой процесс разработки по Report Driven Design? Прежде всего, мы понимаем его как итеративный процесс, что делает его сходным с другими Agile практиками.
При этом мы формулируем основную концепцию RDD в виде четырёх I:
- Information (Информация)
- Interaction (Взаимодействие)
- Input (Ввод данных)
- Iterate (Переход к следующему)
Сейчас я поясню, что всё это значит.
Прежде чем приступить к проектированию программы и базы данных для неё, вам необходимо получить от заказчика набор типичных отчётов, которые нужно будет генерировать. Затем вы берёте один из этих отчётов и анализируете, какая информация в нём представлена:
- горизонтальная информация сигнализирует о том, какие колонки могут быть в соответствующей таблице;
- вертикальное изменение данных даёт понимание того, какая информация должна храниться в строках;
- а группировочные данные в отчёте дают представление о том, какие надо заводить поля для группировки и нужно или нет выносить их в отдельную таблицу.
Переходим к следующему пункту: Interaction. Здесь важно понять, как данные с текущего отчёта взаимодействуют с информацией, полученной при анализе предыдущих отчётов, и как можно модифицировать текущую структуру, чтобы она была одинаково удобной как для анализируемого отчёта, так и для всех предыдущих отчетов.
С пунктом Input, я думаю, тоже всё ясно. Здесь надо определиться, каким образом пользователь будет вводить информацию, представленную в отчёте. Так как мы заходим к проектированию приложения с конца, с модуля отчётов, то фактически на стадии Input мы будем делать то, что зачастую реализуется в самом начале — формы ввода данных.
Ну и последний пункт — Iterate: переходим к следующему отчёту и повторяем заново все шаги.
Я допускаю, что сначала такая процедура может показаться вам неприменимой, по крайней мере, для вашего конкретного случая. Но если в вашем приложении генерирование отчетов занимает особое место, то вы можете смело попробовать применить RDD и убедиться, что это работает.
Давайте рассмотрим, как работает RDD, на «живом» примере. Для иллюстрации возьмём типичные задачи из жизни интернет-магазина.
Пример 1: Склады
Допустим, что при создании интернет-магазина была написана программа, которая позволяет вводить данные о товарах, находящихся на складе этого магазина. Информация быстро и удобно вводится в базу данных на сервере, который расположен на этом же складе.
Затем у того же магазина появляется 2 других склада, уже с другим ассортиментом товаров. И там стал использоваться тот же подход — сервер с программой, куда операторы заносят информацию о товаре. Итого мы имеем 3 разных склада с 3-мя базами данных.
Теперь попытаемся реализовать типичный отчёт из модуля администрирования. Этот отчёт будет выводить информацию о наличии разного товара на имеющихся складах. Глядя на такой отчёт, становится ясно, что если эти данные будут храниться в разных базах, физически удаленных друг от друга, то формироваться он может довольно долго.
Таким образом, совершенно логичным будет объединить все эти таблицы в одну базу данных и расположить её в одной локальной сети с приложением по генерации отчетов.
Возможно, ввод данных при этом замедлится (если оператор будет находиться в другой локальной сети), но не сильно, а генерация отчёта значительно вырастет.
Теперь идём дальше и переходим к другому отчёту. Это типичный отчёт для пользователя интернет-магазина, который представляет собой список товаров, заказанных пользователем.

Совершенно ясно, что информация о складе, на котором хранится заказанный пользователем товар, его совершенно не интересует. А значит, мы можем объёдинить все эти товары в одну таблицу. А чтобы информация о складе не пропадала совсем, можно ввести в эту таблицу ещё одну колонку — ID склада.
Пример 2: Голосование
Теперь рассмотрим ещё один пример из задачи по созданию интернет-магазина. Это так называемый Rating Control — элемент для голосования, например, для оценки покупателем выбранного товара.
Алгоритм тут простой: любой пользователь может один раз проголосовать за любой продукт. Следуя этому сценарию, мы заносим запись о каждом таком голосовании в нашу таблицу.
| CustomerID | ProductID | Rating |
|---|---|---|
Теперь нам надо посмотреть, какие нам понадобятся отчёты на основе этих данных.
Например, приведенная выше таблица будет очень полезна, если нам нужен отчёт, который содержит информацию о том, как конкретный человек голосовали за разные продукты.
Если же такого отчёта в нашем списке нет, то есть нам не важна информация по конкретному голосующему, а важна информация по конкретному продукту, то мы можем смело убрать поле CustomerID из этой таблицы.
| ProductID | Rating |
|---|---|
(Если мы всё же хотим сохранить информацию, по каким продуктам голосовал человек — а мы хотим, чтобы не дать голосовать ему ещё раз — то мы можем хранить эти данные либо в отдельной таблице CustomerID+ProductID, либо добавить ещё одну колонку RatedProducts в таблицу Customers и хранить эту информацию там в виде мета-данных)
Двигаясь дальше, мы можем вдруг осознать, что приведённый выше отчёт либо не сильно важен для нас, либо не нужен вовсе.
И гораздо важнее для нас оптимизировать работу приложения так, чтобы быстро выводить информацию о текущем рейтинге на страничке продукта. Тогда мы и вовсе можем существенно упростить нашу таблицу, сохраняя не все голоса, которые были, а их сумму, а также общее число пользователей, на которое надо делить эту сумму.
| ProductID | TotalRating | CustomersNumber |
|---|---|---|
Осталась лишь операция деления, которая будет выполняться каждый раз при выводе информации о текущем рейтинге продукта. Отлично.
Часто ли эта информация будет показываться? Очень часто — ведь очень много пользователей может «листать» каталог товаров (например, по 20 продуктов на странице), сравнивая их рейтинг.

Вопрос на засыпку: можем ли мы избавиться от операции деления в данном случае? ;-)
Ответ: мы можем хранить не сумму всех голосов, а текущий рейтинг. Тогда операция деления нужна будет именно в момент голосования, то есть опять же при вводе данных. Вот формула:
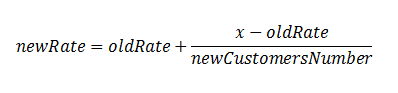
где x — голос пользователя.
ИТОГО
В завершение могу сказать, что мы не предлагаем использовать такой подход как панацею от всех бед. Однако в определенных ситуациях он вполне может быть полезен и позволит взглянуть на ваше приложение и ваши данные с другой стороны. Попробуйте его использовать хотя бы раз, и я надеюсь, это вам пригодится.
P.S.
Кстати, если вы вдруг собираетесь посетить DevCon'11 на этой неделе, я готов лично обсудить с вами плюсы и минусы этого подхода. Во второй день конференции я буду выступать с докладом по теме RDD и буду очень рад услышать ваше мнение, ну и просто пожать руку всем настоящим хабровцам.
До встречи на DevCon!

