Система индексации в Evernote разработана для расширения поисковых возможностей Evernote и обеспечения поиска по медиафайлам. Ее задача — исследовать содержимое этих файлов и сделать любую обнаруженную в них текстовую информацию доступной для поиска. В настоящее время она обрабатывает изображения и файлы PDF, а также «цифровые чернила» (digital ink), но в планах у нас есть поддержка индексирования и других типов медиафайлов. Полученный индекс выводится в виде документа XML или PDF и содержит распознанные слова, альтернативные варианты распознавания, а также координаты найденных слов в документе (для последующей подсветки).
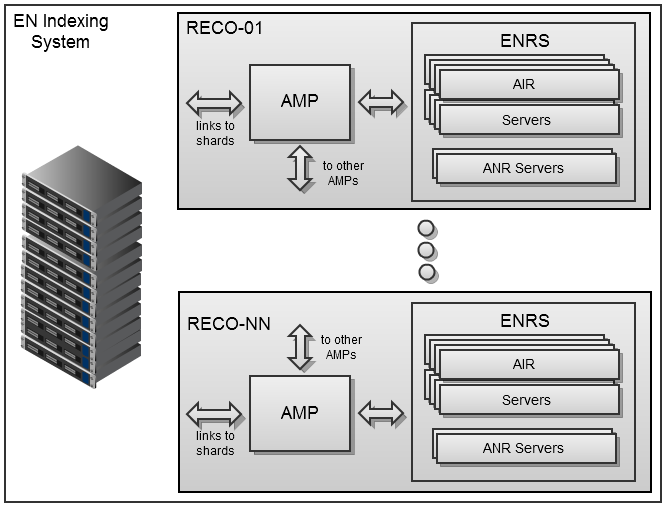
Система индексации реализована в виде фермы выделенных серверов Debian64, на каждом из которых запущен управляющий сервис AMP (Asynchronous Media Processor) и несколько процессов ENRS (Evernote Recognition Server) — обычно по суммарному количеству ядер процессоров. ENRS реализован в виде набора нативных библиотек, упакованных в веб-серверное приложение на Java6. Сейчас оно включает два компонента под кодовыми названиями AIR и ANR. Первый обрабатывает различные типы изображений и PDF, а второй предназначен для индексирования «цифровых чернил». AMP взаимодействует с серверами через HTTP REST API, который допускает гибкую конфигурацию системы, сохраняя при этом высокую пропускную способность при передаче больших файлов.
AMP получает исходные ресурсы от кластерных серверов (шардов), которые хранят пользовательские данные, и возвращает назад созданные индексы. Они будут включены в поисковый индекс веб-сервиса Evernote и будут синхронизированы на клиенты Evernote для компьютеров и мобильных устройств, чтобы упростить локальный поиск по медиафайлам. Чтобы минимизировать дополнительный трафик на шарды, уже занятые обработкой пользовательских запросов обработчики AMP по очереди транслируют информацию друг другу. Таким образом формируется единый распредленный обработчик медиаконтента, оптимизированный под текущие приоритеты загрузки и процессов сервиса. Система индексации Evernote получается достаточно устойчивой и будет работать даже если в строю останется лишь по одному компоненту каждого типа (в настоящее время система включает 37 AMP-обработчиков и свыше 500 серверных ENRS-процессов, которые имеют дело с примерно 2 миллионами медиафайлов в сутки).
Давайте подробнее рассмотрим компонент AIR в сервере ENRS. Идеологически распознавание AIR отличается от традиционных OCR-систем, поскольку его целью является создание не слитного читабельного текста, а полного поискового индекса. Это значит, что мы стремимся найти в изображениях максимальное количество слов с любым минимально приемлемым качеством, включая альтернативные варианты прочтения для неполных, нечетких и находящихся не в фокусе изображений слов.
При распознавании изображений из реального мира, сервер AIR обрабатывает их в несколько подходов, каждый раз делая различные предположения. Изображение может быть огромным, но содержать всего несколько слов. Оно также может содержать рассеянные по картинке и по-разному ориентированные в пространстве слова. Шрифты могут быть как очень маленькими, так и достаточно большими на одном и том же участке. Текст может чередоваться: черный на белом фоне и сразу белый на черном. Это может быть смесь из разных языков и алфавитов. В случае с азиатскими языками в одной области могут быть представлены горизонтальные и вертикальные текстовые строки. Цветы шрифта с одинаковой интенсивностью могут слиться в единый серый уровень во время стандартной OCR-обработки. Печатный текст может включать рукописные комментарии. Рекламный материал может содержать искаженный, наклонный или меняющий на ходу размер текст. И это лишь несколько проблем, с которыми AIR-сервера сейчас сталкиваются около 2 миллионов раз в день.

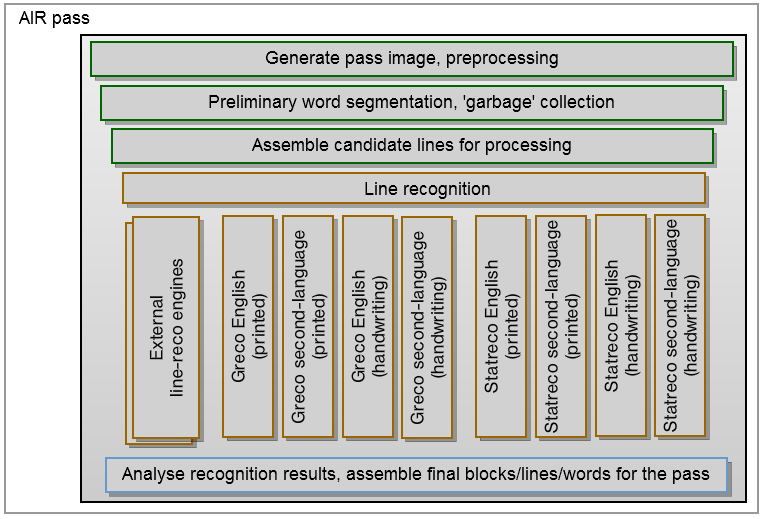
Ниже приведена диаграмма отдельно взятого «прохода» AIR-сервера. В зависимости от параметров вызова, такой проход будет специализироваться на отдельных видах обработки (размер, ориентация и т. д.), но основная схема остается одинаковой. Он начинается с подготовки набора изображений для обработки — масштабирования, перевода в оттенки серого, бинаризации. Затем картинки, таблицы, разметка и прочие нетекстовые артефакты необходимо по максимуму вычистить, чтобы система могла сфокусироваться на конкретных словах. После того, как предполагаемые слова определены, они собираются в текстовые строки и блоки.
Каждая строка каждого блока затем будет обработана несколькими механизмами распознавания — среди них и те, что были разработаны внутри компании, и лицензированные у других производителей. Использование нескольких механизмов важно не только потому, что они специализируются на разных типах текста и языков, но еще и потому, что позволяют реализовать «голосование». Под этим подразумевается анализ альтернатив распознавания слова, являющихся результатами разных механизмов обработки, что позволяет лучше отсекать ложные распознавания и обеспечивает более качественный результат за счет большого количества предложенных вариантов. Эти утвержденные ответы станут основой, из которой на финальном этапе будет воссоздаваться текстовая строка. Повторное использование решений для текстовых строк, сегментация слов и очистка от большинства сомнительных вариантов позволит уменьшить число ложных срабатываний при поиске.

Число проходов, необходимых для получения результата, определяется на начальном этапе модулем рендеринга и анализа изображений, но по мере достигнутого прогресса распознавания это число может быть увеличено или снижено. В случае обычного ясного отсканированного документа можно ограничиться только стандартным процессом OCR-распознавания. Фотография сложной сцены, сделанной телефонной камерой при плохом освещении, может потребовать глубокого анализа с полным набором проходов для извлечения большинства текстовых данных. Наличие множества цветных слов на неоднородном фоне может потребовать дополнительных подходов, специально созданных для отделения цвета. Присутствие маленького размытого текста потребует использования дорогого способа реверсивной цифровой фильтрации, позволяющего восстановить текст, прежде чем приступать к распознаванию.
Когда все проходы завершены, наступает время для другой важной части AIR-процесса — окончательной сборки результатов. В сложных изображениях различные подходы могут создавать совершенно разные интерпретации для одних и тех же областей. Все эти конфликты должны быть разрешены, выбраны лучшие интерпретации, большинство некорректных альтернатив нужно отвергнуть и в итоге выстроить финальные блоки и строки текста.
После того, как внутренняя структура документа создана, остается последний шаг для формирования необходимого формата выходных данных. Для PDF-документов это все тот же PDF, где изображения заменены текстовыми блоками из распознанных слов. Для остальных поступающих документов это XML-индекс, который содержит список распознанных слов и указания на их месторасположение или списки штрихов (для «цифровых чернил»). Эта информация о местоположении позволит подсветить найденное слово в исходном изображении, когда пользователь будет искать документ, который содержит это слово.
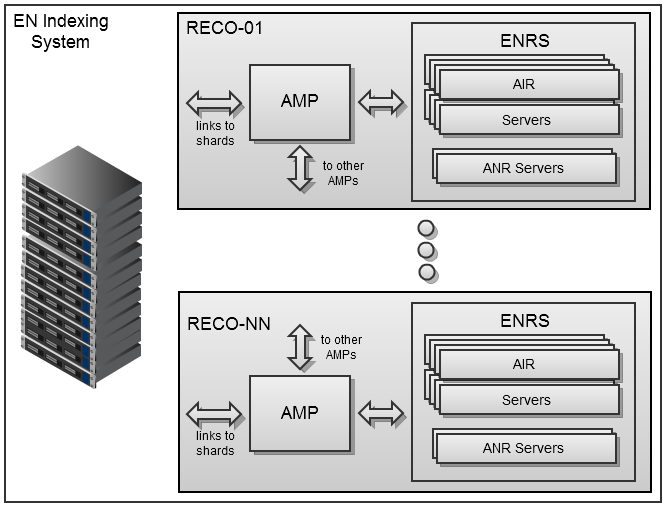
Система индексации реализована в виде фермы выделенных серверов Debian64, на каждом из которых запущен управляющий сервис AMP (Asynchronous Media Processor) и несколько процессов ENRS (Evernote Recognition Server) — обычно по суммарному количеству ядер процессоров. ENRS реализован в виде набора нативных библиотек, упакованных в веб-серверное приложение на Java6. Сейчас оно включает два компонента под кодовыми названиями AIR и ANR. Первый обрабатывает различные типы изображений и PDF, а второй предназначен для индексирования «цифровых чернил». AMP взаимодействует с серверами через HTTP REST API, который допускает гибкую конфигурацию системы, сохраняя при этом высокую пропускную способность при передаче больших файлов.
AMP получает исходные ресурсы от кластерных серверов (шардов), которые хранят пользовательские данные, и возвращает назад созданные индексы. Они будут включены в поисковый индекс веб-сервиса Evernote и будут синхронизированы на клиенты Evernote для компьютеров и мобильных устройств, чтобы упростить локальный поиск по медиафайлам. Чтобы минимизировать дополнительный трафик на шарды, уже занятые обработкой пользовательских запросов обработчики AMP по очереди транслируют информацию друг другу. Таким образом формируется единый распредленный обработчик медиаконтента, оптимизированный под текущие приоритеты загрузки и процессов сервиса. Система индексации Evernote получается достаточно устойчивой и будет работать даже если в строю останется лишь по одному компоненту каждого типа (в настоящее время система включает 37 AMP-обработчиков и свыше 500 серверных ENRS-процессов, которые имеют дело с примерно 2 миллионами медиафайлов в сутки).
Давайте подробнее рассмотрим компонент AIR в сервере ENRS. Идеологически распознавание AIR отличается от традиционных OCR-систем, поскольку его целью является создание не слитного читабельного текста, а полного поискового индекса. Это значит, что мы стремимся найти в изображениях максимальное количество слов с любым минимально приемлемым качеством, включая альтернативные варианты прочтения для неполных, нечетких и находящихся не в фокусе изображений слов.
При распознавании изображений из реального мира, сервер AIR обрабатывает их в несколько подходов, каждый раз делая различные предположения. Изображение может быть огромным, но содержать всего несколько слов. Оно также может содержать рассеянные по картинке и по-разному ориентированные в пространстве слова. Шрифты могут быть как очень маленькими, так и достаточно большими на одном и том же участке. Текст может чередоваться: черный на белом фоне и сразу белый на черном. Это может быть смесь из разных языков и алфавитов. В случае с азиатскими языками в одной области могут быть представлены горизонтальные и вертикальные текстовые строки. Цветы шрифта с одинаковой интенсивностью могут слиться в единый серый уровень во время стандартной OCR-обработки. Печатный текст может включать рукописные комментарии. Рекламный материал может содержать искаженный, наклонный или меняющий на ходу размер текст. И это лишь несколько проблем, с которыми AIR-сервера сейчас сталкиваются около 2 миллионов раз в день.

Ниже приведена диаграмма отдельно взятого «прохода» AIR-сервера. В зависимости от параметров вызова, такой проход будет специализироваться на отдельных видах обработки (размер, ориентация и т. д.), но основная схема остается одинаковой. Он начинается с подготовки набора изображений для обработки — масштабирования, перевода в оттенки серого, бинаризации. Затем картинки, таблицы, разметка и прочие нетекстовые артефакты необходимо по максимуму вычистить, чтобы система могла сфокусироваться на конкретных словах. После того, как предполагаемые слова определены, они собираются в текстовые строки и блоки.
Каждая строка каждого блока затем будет обработана несколькими механизмами распознавания — среди них и те, что были разработаны внутри компании, и лицензированные у других производителей. Использование нескольких механизмов важно не только потому, что они специализируются на разных типах текста и языков, но еще и потому, что позволяют реализовать «голосование». Под этим подразумевается анализ альтернатив распознавания слова, являющихся результатами разных механизмов обработки, что позволяет лучше отсекать ложные распознавания и обеспечивает более качественный результат за счет большого количества предложенных вариантов. Эти утвержденные ответы станут основой, из которой на финальном этапе будет воссоздаваться текстовая строка. Повторное использование решений для текстовых строк, сегментация слов и очистка от большинства сомнительных вариантов позволит уменьшить число ложных срабатываний при поиске.
Число проходов, необходимых для получения результата, определяется на начальном этапе модулем рендеринга и анализа изображений, но по мере достигнутого прогресса распознавания это число может быть увеличено или снижено. В случае обычного ясного отсканированного документа можно ограничиться только стандартным процессом OCR-распознавания. Фотография сложной сцены, сделанной телефонной камерой при плохом освещении, может потребовать глубокого анализа с полным набором проходов для извлечения большинства текстовых данных. Наличие множества цветных слов на неоднородном фоне может потребовать дополнительных подходов, специально созданных для отделения цвета. Присутствие маленького размытого текста потребует использования дорогого способа реверсивной цифровой фильтрации, позволяющего восстановить текст, прежде чем приступать к распознаванию.
Когда все проходы завершены, наступает время для другой важной части AIR-процесса — окончательной сборки результатов. В сложных изображениях различные подходы могут создавать совершенно разные интерпретации для одних и тех же областей. Все эти конфликты должны быть разрешены, выбраны лучшие интерпретации, большинство некорректных альтернатив нужно отвергнуть и в итоге выстроить финальные блоки и строки текста.
После того, как внутренняя структура документа создана, остается последний шаг для формирования необходимого формата выходных данных. Для PDF-документов это все тот же PDF, где изображения заменены текстовыми блоками из распознанных слов. Для остальных поступающих документов это XML-индекс, который содержит список распознанных слов и указания на их месторасположение или списки штрихов (для «цифровых чернил»). Эта информация о местоположении позволит подсветить найденное слово в исходном изображении, когда пользователь будет искать документ, который содержит это слово.
