 Делиться с ближним своим для нас, божьих тварей, это очень характерно, считается добродетелью, и вообще, как утверждает первоисточник, положительно отражается на карме. Однако в мире, созданном архитекторами микропроцессоров, такое поведение не всегда приводит к хорошим результатам, особенно если это касается разделения памяти между потоками.
Делиться с ближним своим для нас, божьих тварей, это очень характерно, считается добродетелью, и вообще, как утверждает первоисточник, положительно отражается на карме. Однако в мире, созданном архитекторами микропроцессоров, такое поведение не всегда приводит к хорошим результатам, особенно если это касается разделения памяти между потоками. Мы все «немного читали» об оптимизации работы с памятью, и у нас отложилось, что полезно, когда «кэш остается горячим», то есть данные, к которым часто обращаются потоки, должны быть компактными и находиться в ближайшем к процессорному ядру кэше. Все так, но когда дело доходит до того, чтобы делиться доступом, потоки становятся злейшими врагами [производительности], а кэш не просто горячий, он аж «горит адским огнем» – такая во круг него разворачивается борьба.
Ниже мы рассмотрим простой, но показательный случай возникновения проблем производительности многопоточных программ, а потом я дам несколько общих рекомендаций, как избежать проблемы потери эффективности вычислений из-за разделения кэша между потоками.
Рассмотрим случай, который хорошо описан в Intel®64 and IA-32 Architectures Optimization Manual, однако про который программисты часто забывают, работая со массивами структур в могопоточном режиме. Они допускают обращение (с модификацией) потоков к данным структур, расположенных очень близко друг к другу, а именно в блоке, равном длине одной кэш-линии (64 байт). Мы это называем Сache line sharing. Существует два типа разделения кэш-линий: true sharing и false sharing.
True sharing (истинное разделение) – это когда потоки имеют доступ к одному и тому же объекту памяти, например, общей переменной или примитиву синхронизации. False sharing (
Почему страдает производительность, поясним на примере. Допустим, мы обрабатываем последовательность структур данных, находящихся в очереди, в многопоточном режиме. Активные потоки один за одним вынимают следующую структуру из очереди и каким-либо образом обрабатывают ее, модифицируя данные. Что может произойти на аппаратном уровне, если, например, размер этой структуры небольшой и не превышает нескольких десятков байт?
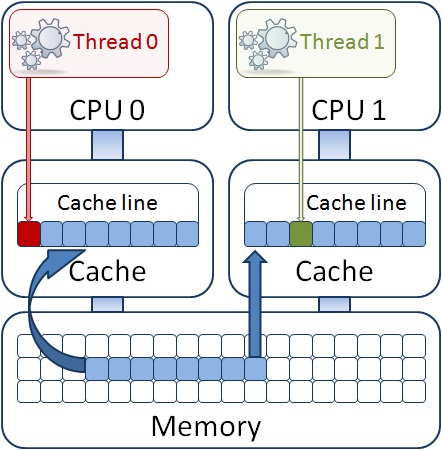
Условия для возникновения проблемы:
Два или более потока пишут в одну кэш-линию;
Один поток пишет, остальные читают из кэш-линии;
Один поток пишет, в остальных ядрах стработал HW prefetcher.
Может оказаться, что переменные в полях разных структур так расположились в памяти, что будучи считанными в L1 кэш процессора, находятся в одной кэш-линии, как на рисунке. При этом, если один из потоков модифицирует поле своей структуры, то вся кэш-линия в соответствии с cache coherency протоколом объявляется невалидной для остальных ядер процессора. Другой поток уже не сможет пользоваться своей структурой, несмотря на то, что она уже лежит в L1 кэше его ядра. В старых процессорах типа P4 в такой ситуации потребовалась бы долгая синхронизация с основной памятью, то есть модифицированные данные были бы отправлены в основную память и потом считаны в L1 кэш другого ядра. В текущем поколении процессоров (кодовое имя Sandy Bridge) синхронизационным механизмом используется общий кэш третьего уровня (или LLC – Last Level Cache), который является инклюзивным для подсистемы кэш-памяти и в котором располагаются все данные, находящиеся как в L2, так и в L1 всех ядер процессора. Таким образом, синхронизация происходит не с основной памятью, а с LLC, являющегося частью реализации протокола механизма когерентности кэшей, что намного быстрее. Но она все равно происходит, и на это требуется время, хотя и измеряемое всего несколькими десятками тактов процессора. А если данные в кэш-линии разделяются между потоками, которые выполняются в разных физических процессорах? Тогда уже придется синхнонизироваться между LLC разных чипов, а это намного дольше — уже сотни тактов. Теперь представим, что программа только и занимается тем, что в цикле обрабатывает поток данных, получаемых из какого-либо источника. Теряя сотни тактов на каждой итерации цикла, мы рискуем «уронить» свою производительность в разы.
Давайте посмотрим на следующий пример, специально упрощенный для того, чтобы было легче понять причины проблемы. Не сомневайтесь, в реальных приложениях такие же случаи встречаются очень часто, и в отличие от рафинированного примера, даже обнаружить существование проблемы не так просто. Ниже мы покажем, как с помощью профилировщика производительности быстро находить такие ситуации.
Потоковая функция в цикле пробегает по двум массивам float a[i] и b[i], перемножает их значения по индексу массива и складывает в локальные переменные потоков localSum[tid]. Для усиления эффекта эта операция делается несколько (ITERATIONS) раз.
int work(void *pArg)
{
int j = 0, i = 0;
int tid = (int) pArg;
for (j = 0; j < ITERATIONS; j++){
for (i = tid; i < MAXSIZE; i+= NUM_PROCS){
a[i] = i + a[i] * b[i];
localSum[tid] += a[i];}}
}
Беда в том, что для разделения данных между потоками выбран способ перемежевания индексов цикла. То есть, если у нас работают два потока, первый будет обращаться к элементам массивов a[0] и b[0], второй — к элементам a[1] и b[1], первый — a[2] и b[2], второй — a[3] и b[3], и так далее. При этом элементы массива a[i] модифицируются потоками. Не трудно видеть, что в одну кэш-линию попадут 16 элементов массива, и потоки будут одновременно доступаться к соседним элементам, «сводя с ума» механизм синхрониции кэшей процессора.

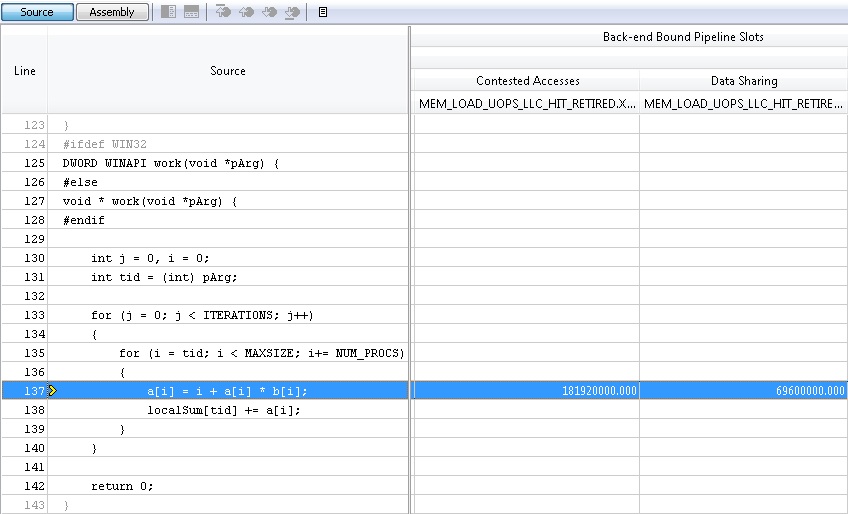
Самое неприятное в том, что мы даже не заметим по работе программы существование этой проблемы. Она будет просто работать медленнее, чем может, вот и все. Как оценить эффективность программы с помощью профилировщика VTune Amplifier XE, я уже описывал в одном из постов на Хабре. Используя профиль General Exploration, о котором я там упоминал, можно увидеть описываемую проблему, которая будет «подсвечена» инструментом в результатах профилировки в колонке Contested Access. Эта метрика как раз и измеряет соотношение циклов, потраченых на синхронизацию кэшей процессора при их модификации потоками.

Если кому-то интересно, что стоит за этой метрикой, то во время комплексной профилировки инструмент среди других аппаратных счетчиков собирает и данные счетчика:
MEM_LOAD_UOPS_LLC_HIT_RETIRED.XSNP_HITM_PS – Точный счетчик(PS) выполненной(RETIRED) операции(OUPS) загрузки(LOAD) данных(MEM), которые оказалиcь(HIT) в LLC и модифицированны(M). «Точный» счетчик означает, что данные, собранные таким счетчиком в семплировании, относятся к указателю инструкции (IP), следующему после инструкции, которая была той самой загрузкой, приведшей к синхронизации кэшей. Набрав статистику по этой метрике, мы можем с определенной точностью указать адрес инструкции, и, соответственно, строку исходного кода, где производилось чтение. VTune Amplifier XE может показать, какие потоки читали эти данные, а дальше мы уже должны сами сориентироваться, как реализован многопоточный доступ к данным и как исправить ситуацию.
Относительно нашего простого примера ситуацию исправить очень легко. Нужно просто разделить данные на блоки, при этом количество блоков будет равно количеству потоков. Кто-то может возразить: если массивы достаточно большие, то блоки могут просто не вместиться в кэш, и данные, загружаемые из памяти для каждого потока, будут вытеснять друг друга из кэша. Это будет верно в случае, если все данные блока используются постоянно, а не один раз. Например, при перемножении матриц мы пройдемся по элементам двумерного массива сначала по строкам, потом по столбцам. И если обе матрицы не помещаются в кэш (любого уровня), то они буду вытеснены, а повторный доступ к элементам потребует повторной загрузки из следующего уровня, что негативно влияет на производительность. В общем случае с матрицами применяется модифицированное перемножение матриц поблочно, при этом матрицы разбиваются на блоки, которые заведомо помещаются в заданную кэш-память, что значительно увеличивает производительность алгоритма.
int work(void *pArg)
{
int j = 0, i = 0;
int tid = (int) pArg;
for (j = 0; j < ITERATIONS; j++){
chunks = MAXSIZE / NUM_PROCS;
for (i = tid * chunks; i < (tid + 1) * chunks; i++){
a[i] = i + a[i] * b[i];
localSum[tid] += a[i];}}
}
False sharing

No False sharing
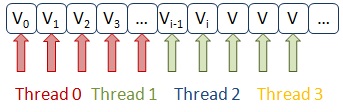
Сравнение доступа потоков к элементам массива в случае False sharing и в исправленном коде
В нашем простом случае данные используются всего один раз, и даже если они будут вытеснены из кэш-памяти, они нам уже не понадобятся. А о том, чтобы данные обоих массивов a[i] и b[i], расположенные далеко друг от друга в адресном пространстве, вовремя оказались в кэше позаботится аппаратный prefetcher – механизм подкачки данных из основной памяти, реализованный в процессоре. Он отлично работает, если доступ к элементам массива последовательный.
В заключение, можно дать несколько общих рекомендаций, как избежать проблемы потери эффективности вычислений из-за разделения кэша между потоками. Из самого названия проблемы можно понять, что следует избегать кодирования, где потоки обращаются к общим данным очень часто. Если это true sharing мьютекса потоками, то возможно существует проблема излишней синхроницации, и следует пересмотреть подход к разделению ресурса, который защещен этим мьютексом. В общем случае старайтесь избегать глобальных и статических переменных, к которым требуется доступ из потоков. Используйте локальные переменные потоков.
Если вы работаете со структурами данных в многопоточном режиме, уделите внимание их размеру. Используйте «подкладки» (padding), чтобы нарастить размер структуры до 64 байт:
struct data_packet
{
int address[4];
int data[8];
int attribute;
int padding[3];
}
Выделяйте память под структуры по выровненному адресу:
__declspec(align(64)) struct data_packet sendpack
Используйте массивы структур вместо структур массивов:
data_packet sendpack[NUM];
вместо
struct data_packet
{
int address[4][NUM];
int data[8][NUM];
int attribute[NUM];
}
Как видно, в последнем случае потоки, модифицирующие одно из полей, приведут к запуску механизма синхронизации кэш-памяти.
Для объектов, аллоцируемых в динамической памяти с помощью malloc или new, cоздавайте локальные пулы памяти для потоков, либо используйте параллельные библиотеки, которые сами умеют это делать. Например, библиотека TBB содержит масштабируемые и выравнивающие аллокаторы, которые полезно использовать для масштабируемости многопоточных программ.
Ну и заключительный совет: не стоит бросаться решать проблему, если она не сильно влияет на общую производительность приложения. Всегда оценивайте потенциальный выигрыш, который вы получите в результате затрат на оптимизацию вашего кода. Используйте инструменты профилировки, чтобы оценить этот выигрыш.
P.S. Попробуйте мой примерчик, и расскажите, на сколько процентов увеличилось быстродействие теста на вашей платформе.
