
Другие части: Часть 1. Часть 3..
Данный пост — продолжение рассказа «Жизнь в эпоху «тёмного» кремния». В предыдущей части рассказывалось о том, что такое «тёмный» кремний и почему он появился. Также рассматривались два из четырех основных подходов, позволяющих микроэлектронике процветать в эпоху «темного» кремния. Было рассказано о роли новых открытий в области технологии производства, о том, как повысить энергоэффективность за счет параллелизма, а также, почему уменьшение площади процессорного кристалла, видится маловероятным. В этот раз на повестке дня следующий подход.
«The Dim Horseman» или управление энергопотреблением и температурным режимом.
“We will fill the chip with homogeneous cores
that would exceed the power budget
but we will underclock them (spatial dimming),
or use them all only in bursts (temporal dimming)
… “dim silicon”.
Раз сокращение площади кристалла видится маловероятным, то рассмотрим, как можно эффективно использовать «тёмные» области кремния. Здесь перед разработчиками встаёт выбор: использовать логику общего или специального назначения? В этот раз рассмотрим вариант универсальной логики, занятой работой лишь малую часть времени, и которую можно применять для широкого круга задач. Для логики, которая большую часть времени работает на пониженных частотах, используется термин «тусклый» (dim) кремний. [1]
Рассмотрим несколько методов проектирования, связанных с использованием «тусклого» кремния.
Near-Threshold Voltage процессоры. Один из недавно возникших подходов — это использование логики, работающей на пониженных уровнях напряжения, близких к порогу срабатывания (Near-Threshold Voltage, NTV) [2]. Логика, работающая в таком режиме, хоть и проигрывает в абсолютных показателях производительности, но даёт лучшие показатели на единицу потребляемой мощности.
В предыдущей части эта идея рассматривалась на примере одного компаратора. Если же говорить о более масштабных её использованиях, то в последнее время внимание привлекали NTV реализации SIMD процессоров [3]. SIMD — наиболее удачная форма параллелизма для данного подхода. Также исследовались многоядерные [4] и x86(IA32) [5] NTV процессоры.
Производительность NTV процессоров падает быстрее, чем соответствующая экономия энергии на одной операции. Например, 8х падение производительности при 40х общем снижении энергопотребления или 5х снижении на каждую операцию. Потери производительности можно компенсировать, используя большее число параллельно работающих процессоров. Но это будет эффективно, только предполагая идеальное распараллеливание, что в большей мере соответствует SIMD, чем иным архитектурам.
Возвращаясь к закону Мура, NTV может предложить 5х рост производительности, сохраняя то же энергопотребление, но используя в 40 раз большую площадь (примерно одиннадцать поколений техпроцесса).
Использование NTV создает разнообразные проблемы технического характера. Одной из таких проблем становится увеличение чувствительности схемы к вариации параметров технологического процесса. Процесс литографии состоит из нанесения множества слоев топологии на поверхность кремния (легирования). Но толщина и ширина линий в получаемых слоях может незначительно варьироваться, а это приводит к разбросу порогового напряжения транзисторов. Снижая рабочее напряжение, мы получаем больший разброс частот, на которых могут работать транзисторы. Это создает массу неудобств — обычно SIMD использует жестко синхронизированные параллельные блоки, чего трудно добиться в таких условиях.
Есть и другие проблемы, например, трудности создания SRAM-памяти, работающей при более низких напряжениях.
Увеличение кэша. Часто предлагаемая альтернатива — просто использовать темные области кремния для размещения кэша. Ведь можно легко себе представить рост кэша со скоростью 1.4-2х на каждое поколение техпроцесса. Больший кэш для задач с частыми кэш-промахами может улучшить как производительность, так и экономичность – обращение к памяти за пределами чипа требует много энергии. Частота кэш-промахов в основном и определяет целесообразность увеличения кэша. Согласно недавнему исследованию, оптимальный объем кэша определяется точкой, где производительность системы перестает быть ограниченной пропускной способностью и становится ограниченной по потребляемой мощности. [6]
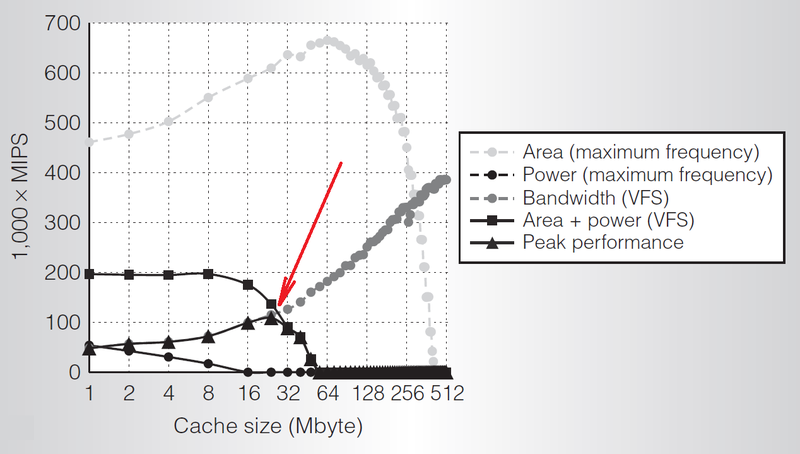
Зависимость производительности от объема кэша при различных ограничениях
Однако интерфейсы с внекристальной памятью становятся всё более энергоэффективны, а 3D-интеграция памяти ускоряет обращение к ней. Это, вероятно, сократит в будущем выигрыш от больших объемов кэша.
Coarse-Grained Reconfigurable Arrays. Использование реконфигурируемой логики – не новая идея. Но использование её на битовом уровне, как это происходит в FPGA, связано с высокими накладными расходами энергии. Наиболее перспективным вариантом выглядит использование крупнозернистых реконфигурируемых массивов (Coarse-Grained Reconfigurable Arrays, CGRAs). Такие массивы конфигурируются для выполнения той или иной операции над целым словом. Идея состоит в том, чтобы разместить элементы логики в порядке, соответствующем естественному порядку вычислений, что позволяет сократить длину сигнальных связей и расходы, связанные с многократным мультиплексированием линий связи. [7] Кроме того, рабочий цикл CGRA очень мал, большую часть времени его логика бездействует, что делает его привлекательным для использования в качестве «тусклой» логики.
Исследования в области CGRA велись и ранее, они продолжаются и сейчас, в эпоху темного кремния. Коммерческий успех технологии был весьма ограничен, но новые проблемы часто заставляют нас взглянуть на старые идеи свежим взглядом. :)
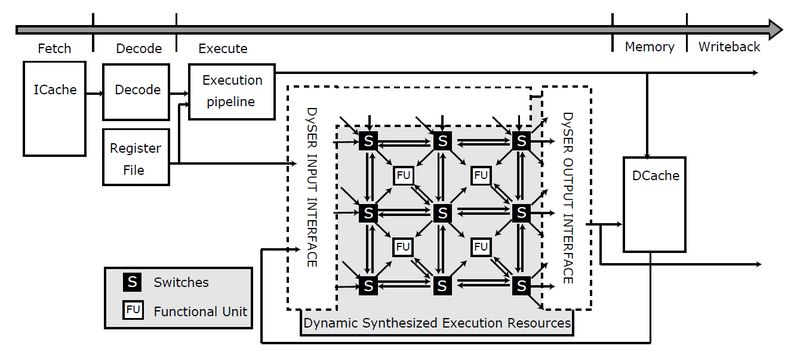
Использование реконфигурируемых массивов в составе процессора
Computational Sprinting и Turbo Boost. Описанные выше подходы использовали пространственное затемнение кремния, когда какая-то область логики спроектирована так, что всё время работает на сильно пониженных частотах или большей частью простаивает. Но существует и ряд методов, опирающихся на временное затемнение кремния. Например, процессор может обеспечить короткое (<1 мин.), но существенное увеличение производительности, повышая тактовую частоту. При этом временно превышается тепловой бюджет (~1.2-1.3 TDP), но расчет делается на тепловую емкость чипа и радиатора, как средство против повышения температуры. Спустя какое-то время частота возвращается к исходному значению, давая «остыть» радиатору. Технология Turbo Boost [8] использует именно этот подход для повышения производительности в нужный момент.
Вычислительный спринтинг, а вместе с ним версия Turbo Boost 2.0 делает шаг вперед по сравнению с оригинальной идеей, позволяя получать гораздо больший (~10x) прирост производительности, но лишь на доли секунды.

А теперь немного практики, чтобы не быть голословным. Чего удается добиться в современных процессорах с помощью этих и других подходов. Эффективно используя разнообразные методы как пространственного, так и временного затемнения, энергопотребление может меняться более чем в 50 раз в зависимости от нагрузки.
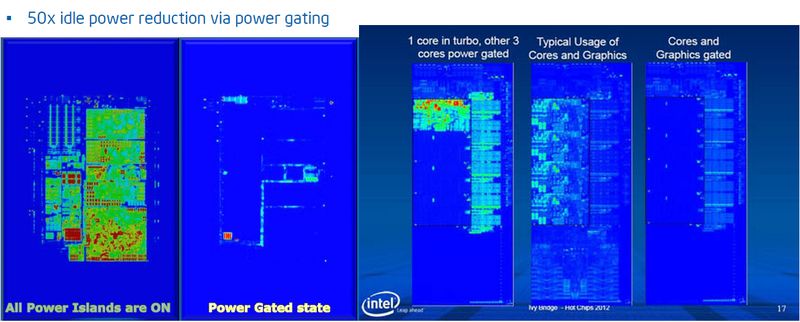
Инфракрасные снимки процессоров в различных конфигурациях энергопотребления
Однако обеспечивающая это система очень и очень сложна. Помимо соответствующих проектных решений микропроцессор содержит массу температурных датчиков (красные точки в правой части рисунка). Например, в Sandy Bridge на каждое процессорное ядро приходится по 12 датчиков и еще немалое их количество размещено за пределами процессорных ядер. Кроме того, в состав процессора входит специализированный блок (PCU – Package Control Unit), который выполняет firmware, управляющее энергопотреблением. При этом показания температурных датчиков используются не только для контроля температуры, но и, например, чтобы оценивать токи утечки, а PCU имеет интерфейс общения с внешним миром, что позволяет операционной системе и пользовательским приложениям осуществлять мониторинг данных и управлять энергопотреблением.

Также интересна следующая особенность многоядерных процессоров. При малой нагрузке избыточные процессорные ядра могут быть отключены для экономии энергии. Но Uncore (часть процессора, не включающая процессорные ядра – коммуникационная фабрика, разделяемый кэш, контроллер памяти и т.д.) отключен быть не может, т.к. это полностью остановит работу процессора. При этом энергопотребление Uncore сравнимо с энергопотреблением нескольких процессорных ядер.

Uncore
Желаемой экономии энергии можно достичь, управляя тактовой частотой Uncore. В случае, когда частота выше необходимой (точка 1), требования производительности Uncore полностью удовлетворяются, но энергия расходуется впустую и частота может быть снижена без ущерба для производительности. В случае, когда частота ниже необходимой (точка 2), страдает производительность и частота должна быть увеличена. Наша цель – найти оптимальную точку для текущей нагрузки (точка 3) и поддерживать её. Это непросто, т.к. для эффективной работы требования по производительности необходимо прогнозировать и изменять тактовую частоту заранее.
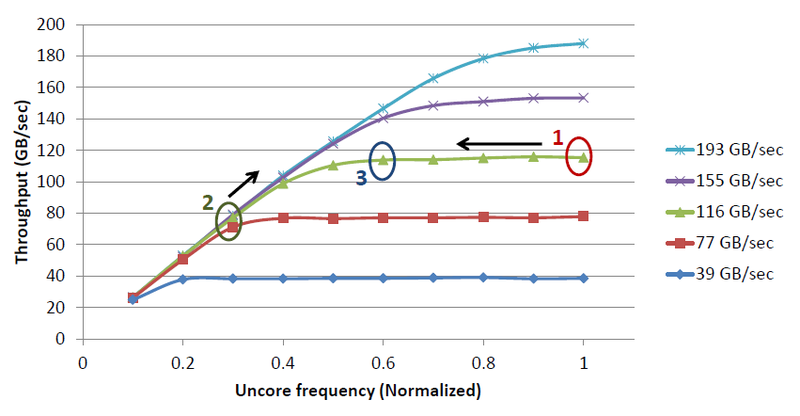
Кривые производительности Uncore от тактовой частоты при различной нагрузке
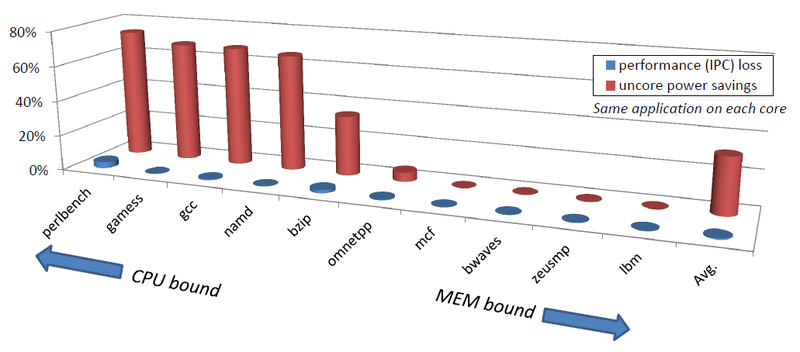
Потеря производительности и экономия энергии на различных задачах
Различные алгоритмы управления частотой Uncore позволяют добиться, например, 31% экономии энергии, потеряв лишь 0.6% производительности, или 73% экономии за счет 3.5% производительности соответственно.
Продолжение.
Источники
1. W. Huang, K. Rajamani, M. Stan, and K. Skadron.”Scaling with design constraints: Predicting the future of big chips." IEEE Micro, july-aug. 2011.
2. R. Dreslinski et al «Near-threshold computing: Reclaiming moore's law through energy efficient integrated circuits." Proceedings of the IEEE, Feb. 2010.
3. Hsu, Agarwal, Anders et al. “A 280mv-to-1.2v 256b reconfigurable simd vector permutation engine with 2-dimensional shuffle in 22nm cmos." In ISSCC, Feb. 2012.
4. D. Fick et al. “Centip3de: A 3930 dmips/w configurable near-threshold 3d stacked system with 64 arm cortex-m3 cores." In ISSCC, Feb. 2012.
5. Jain, Khare, Yada et al. “A 280mv-to-1.2v wide-operating-range ia-32 processor in 32nm cmos." In ISSCC, Feb. 2012.
6. N. Hardavellaset al. “Toward dark silicon in servers." IEEE Micro, 2011.
7. V. Govindaraju, C.-H. Ho, and K. Sankaralingam. “Dynamically specialized datapaths for energy efficient computing." In HPCA, 2011.
8. E. Rotem. ”Power management architecture of the 2nd generation Intel core microarchitecture, formerly codenamed sandy bridge." In Proceedings of Hotchips, 2011.
