 Один из методов улучшения эффективности распараллеливания алгоритмов определенного класса – конвейеризация фаз исполнения, как последовательных, так и параллельных. Библиотека Intel TBB может помочь сократить усилия и время, необходимые на реализацию конвейеризированных алгоритмов, беря на себя заботу об управлении задачами и распределении нагрузки между потоками в системе. Однако, формулирование и формирование задач, составляющих фазы алгоритма, может быть нетривиальной проблемой в зависимости от сложности алгоритма, что в реальных приложениях чаще всего и бывает. Контролировать выполнение задач может оказаться еще сложнее, если сам алгоритм не содержит средства для контроля. Инструментарий анализа вычислительных задач в Intel VTune Amplifier помогает разработчикам представлять структуру исполнения в многопоточной среде в удобном графическом виде, увеличивая эффективность анализа и значительно сокращая время разработки приложений. В данной статье мы рассмотрим простой пример конвейеризированной задачи, и шаг за шагом распараллелим ее, используя конвейерный класс TBB, проанализируем с помощью VTune Amplifier и улучшим производительность реализации на основе результатов анализа.
Один из методов улучшения эффективности распараллеливания алгоритмов определенного класса – конвейеризация фаз исполнения, как последовательных, так и параллельных. Библиотека Intel TBB может помочь сократить усилия и время, необходимые на реализацию конвейеризированных алгоритмов, беря на себя заботу об управлении задачами и распределении нагрузки между потоками в системе. Однако, формулирование и формирование задач, составляющих фазы алгоритма, может быть нетривиальной проблемой в зависимости от сложности алгоритма, что в реальных приложениях чаще всего и бывает. Контролировать выполнение задач может оказаться еще сложнее, если сам алгоритм не содержит средства для контроля. Инструментарий анализа вычислительных задач в Intel VTune Amplifier помогает разработчикам представлять структуру исполнения в многопоточной среде в удобном графическом виде, увеличивая эффективность анализа и значительно сокращая время разработки приложений. В данной статье мы рассмотрим простой пример конвейеризированной задачи, и шаг за шагом распараллелим ее, используя конвейерный класс TBB, проанализируем с помощью VTune Amplifier и улучшим производительность реализации на основе результатов анализа. Введение
Как известно, вычислительная задача в общем случае может быть разделена на подзадачи (декомпозиция), которые выполняются параллельно разными вычислительными устройствами. В зависимости от типа задачи, либо входных данных, декомпозиция может быть применена к данным, либо к самой задаче. Упрощенно говоря, декомпозиция по данным может рассматриваться, как разделение входного набора данных для обработки одним и тем же алгоритмом, но в разных вычислителях. Декомпозиция по задачам – наоборот, несколько различных алгоритмов, выполняемых разными устройствами, либо над одними и теми же данными, либо над разными их частями. Основная цель декомпозиции для вычислительных утройств – сделать так, чтобы все доступные устройства были максимально заняты все время, пока вычисляется задача. Этим достигается максимальная производительность для имеющегося набора устройств при выполнении данной задачи, а значит — сокращение времени ее выполнения. В связи с этим, возможность анализировать выполнение, как каждой из частей задачи, так и всей задачи в целом, в вычислительной системе имеет огромное значение для оптимизации алгоритма. В этой статье мы и рассмотрим возможности анализа вычислительных задач, распараллеленных с использованием библиотеки Intel TBB, с помошью новой версии профилировщика VTune Amplifier XE 2013.
Сразу попрошу извинить меня за обилие английских терминов без перевода. Это сделано намеренно, так как при использовании инструментов их все равно придется использовать, а попытки их перевести на русский язык только запутают читателя. (UPD: мне сказали, что не переведенный текст на картинках режет глаза — работаю над переводом и скоро обновлю картинки)
Вступлене не случайно содержит обилие обобщающих выражений, таких как вычислительная система, набор данных, и т.д., потому, мы начнем с обощенного примера, который имеет мало общего с раеальными задачами, а потом постепенно перейдем к живому примеру, который и подвергнем анализу. Давайте рассмотрим сферический алгоритм, который исполняется в вакууме, но при этом сильно напоминает реальную задачу получения данных из какого-либо источника, выполнение каких-то высислительных процедур над этими данными, и запись обработанных данных в приемник (рис.1). Такая структура довольно типична для многих приложений, среди которых, быстрее всего на ум приходят кодеки, фильтры, либо коммуникационные протоколы.

Рис.1
Для сохранения глубины вакуума и упрощения примера мы не будем учитывать возможную зависимость между частями данных, поступающих из источника. Хотя это и не правильно, так как, например, при обработке видеокадров в кодеке, зависимость соседних пикселов учитывается алгоритмом. Однако, в общем случае всегда можно выделить достаточно большой массив данных, который можно считать независимым от других массивов. При этом можно достаточно безопасно применять декомпозицию для выполнения вычислительного алгоритма параллельно над различными частями данных, тем самым искажая сферичность алгоритма и делая из него нечто похожее на схему, представленную на рис.2: данные последовательно читаются из источника, обрабатываются в параллельных блоках (P), а затем опять же последовательно записываются (W) в приемник.

Рис.2
Если источником данных является последовательное устройство, такое как диск, либо сетевой интерфейс, то процесс чтения и записи будет тоже последовательным. И даже если вы располагаете свободными вычислительными потоками в системе, единственная стадия исполнения, которую можно будет распараллелить, это фаза исполнения алгоритма. Согласно закону Амдала, увеличение производительности всей задачи за счет распараллеливания будет ограничено этими последовательными фазами.
Пытаясь преодолеть это ограничение, мы можем перераспределить части задачи таким образом, чтобы добиться того, что все исполнительные потоки постоянно заняты ее выполнением. Это возможно, если части данных являются независимыми и их порядок обработки не важен, либо может быть восстановлен на выходе. Для этого мы строим простой конвейер, который состоит из тех же стадий Read/Process/Write, выполняемых каждым потоком (рис.3). Стадии Read и Write все так же остаются последовательными, но они распределены между потоками. При этом надо иметь в виду, что ни один поток не может начать стадию чтения или записи, пока какой-либо другой поток выполняет такую же стадию. Однако два разных потока вполне могу одновременно выполнять и чтение, и запись разных данных.
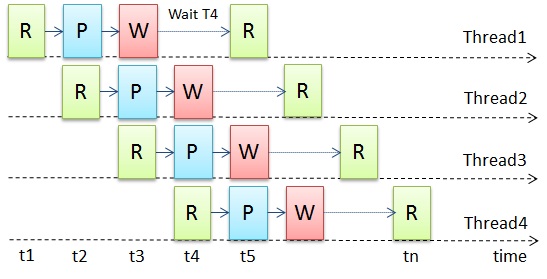
Рис.3
Реструктурировав алгоритм таким способом, формально мы использовали декомпозицию по задачам, то есть разные фазы задачи исполнялись разными потоками одновременно. В то же самое время, разделяя данные на части, и выполняя над ними одинаковые операции в разных потоках, мы используем и декомпозицию по данным. Такой комбинированных подход позволяет добиться того, что потоки постоянно заняты работой, тем самым максимизируя эффективность исполнения всей задачи. Однако сферичность алгоритма до сих пор остается таковой, так как мы здесь не учитываем возможных задержек в устройствах чтения/записи, а так же предполагаем, что для вычислительных потоков достаточно много работы, чтобы сгладить неровности в поступлении данных, и вычислительные устройства всегда доступны для исполнения алгоритма.
В реальной жизни все может быть сложнее. Например, никто не гарантирует стабильного значения времени, затраченного устройствами ввода/вывода на передачу данных, либо, что процессоры свободны в данных момент, или того, что данные однородны и требуют одинакового времени на обработку одним и тем же алгоритмом. Чаще всего входные данные могут поступать с задержкой, что обусловлено особенностями источника. Процессор может быть занят другими задачами с более высоким приоритетом. Некоторые данные могут требовать большего времени на обработку, например, кадры с мелкими деталями обрабатываются гораздо дольше алгоритмом сжатия, нежели кадры с равномерным фоном. Операции записи, как правило, не являются проблемой, так как в большинстве систем они буферизированы и физически запись данных в приемник может быть отложена на потом. Хотя это работает только в случае, если выходные данных не используются снова на входе. В общем, переходя от сферично-вакуумной модели к реальным реализациям задачи в имеющейся системе, вся задуманная эффективность конвейера может сойти на нет, и наша сложная схема останется такой же неэффективной, как была изначальная и простая (рис.4).

Рис.4
Для устранения неэффективности, возникшей из-за разбалансировки нагрузки, мы можем попытаться динамически распределять работу, выполняемую каждым потоком. Это потребует мониторинга состояния занятости потоков, управления размерами данных, обрабатываемых алгоритмом, и распределения подзадач между свободными потоками. Реализация такой инфраструктуры возможна небольшими усилиями, но только для простых случаев. В общем случае такая инфраструктура может оказаться довольно сложной для разработки с нуля. И тут самое время прорекламировать возможности библиотеки Intel TBB, которая уже содержит в себе механизм динамической балансировки нагрузки между потоками. А для нашего примера в TBB содержится встроенный алгоритм конвейера, который называется pipeline Class, подходящий для использования в нашей задаче.
Пример
Мы не будем сильно вдаваться в детали реализации алгоритма pipeline в TBB, так как всю информацию, включая открытый исходный код, можно найти на сайте threadingbuildingblocks.org. Ниже мы просто рассмотрим на примере нашей задачи, как создать конвейер с помощью TBB. А пример кода находится в директории библиотеки или на web-сайте.
В двух словах, конвейер – это применение последовательности исполнительных блоков к потоку объектов. Исполнительные блоки могут реализовывать стадии задачи, которые выполняют определенные действия над потоком данных. В библиотеке TBB эти стадии могут быть определены, как экземпляры класса filter. Таким образом, конвейер строится, как последовательность фильтров. Некоторые стадии (такие как Processing) могут работать параллельно в нескольких потоках с разными данными, поэтому их необходимо определить как parallel filter Class. Остальные стадии, такие как Read и Write должны быть выполнены последовательно и в определенном порядке (если изменение порядка не предусмотрено), и их определяем как serial_in_order filter Class. Библиотека содержит абстрактные классы для таких типов, и нам нужно наследовать наши классы от них. Ниже – пример, который с определенными упрощениями, показывает, как это сделать.
|
|
|
|
В нашем примере данные содержатся в файле, поэтому нужно определить private член класса для указателя на файл. Точно так же определяем и класс MyWriteFilter для стадии записи, и сохраняем указатель на выходной файл. Эти классы будут ответственны за выделение памяти для данных и передачу объектов по конвейеру. Основная работа выполняется в методе operator(), определенном в базовом классе. Нам нужно только переопределить эти методы, реализовав соответственно чтение данных из входного файла в контейнер и запись данных из контейнера в выходной файл.
|
|
Наша стадия Process может выполняться параллельно в потоках, поэтому ее определяем как класс parallel filter, а метод operator() должен содержать “мясо” алгоритма обработки потока данных.
|
|
Нам осталось только окончательно собрать конвейер: создать объекты класса filter, объект класса pipeline, и соединить все стадии. После построения конвейера необходимо вызвать метод run() класса pipeline, указав количество токенов (извините за такой перевод). В данном случае количество токенов означает количество объектов данных, которые могут исполняться в конвейере одновременно. Выбор правильного количества может стать отдельной темой для обсуждения, мы просто последуем рекомендациям в документах к TBB и выберем число, равное удвоенному количеству доступных в системе потоков. Это даст нам возможность иметь достаточно объектов данных, чтобы конвейер был занят, и, в тоже самое время, гарантирует отсутствие роста очереди объектов данных, если первая стадия обрабатывает их гораздо быстрее, чем последующие.
tbb::pipeline pipeline;
MyReadFilter r_filter( input_file );
pipeline.add_filter( r_filter );
MyProcessFilter p_filter;
pipeline.add_filter(p_filter );
MyWriteFilter w_filter( output_file );
pipeline.add_filter( w_filter );
pipeline.run(2*nthreads)
Таким образом, мы создали три подзадачи в конвейере, которые будут управляться библиотекой TBB для максимизации использования процессоров, доступных в системе – подзадача Process будет распараллелена, а остальные подзадачи будут динамически распределяться между потоками в зависимости от их доступности. Нам нужно было только правильно соединить эти стадии. Как вы можете увидеть, в примере нет кода управления потоками – все это скрыто в планировщике задач библиотеки.
И как это часто бывает, где-то с предпоследних рядов (или, наоборот, из первых) поднимается рука, и очень дотошный слушатель задает очень хороший вопрос: А как мы можем быть уверены, что сконструированный конвейер эффективен? И если копнуть глубже, как узнать, каким именно образом выполняются подзадачи в конвейере, и каковы накладные расходы на управление подзадачами, и есть ли разрывы в их выполнении?
Предлагать сравнить его реализацию с первоначальной, неэффективной реализацией алгоритма – бессмысленно. Во-первых, так мы не поймем ничего, кроме того, что она будет работать быстрее. А во-вторых, возможно, она быстрее работать и не будет.
То есть простых ответов на поставленные вопросы нет. Нужно измерять и анализировать. Профилировка с помощью VTune Amplifier XE сделает этот процесс более легким, наглядным, и главное, быстрым. VTune Amplifier поможет нам определить эффективность загрузки процессоров в системе, наглядно покажет схему управления задачами библиотекой TBB, и обнаружит возможные ошибки, которые мы допустили в процессе построения конвейера, влияющие на производительность реализации алгоритма.
Давайте в образовательных целях начнем с Hotspot-анализа. Будем анализировать пример кода, который читает из файла целые значения в текстовом формате [стадия Read], возводит их в квадрат [Process] и записывает числа опять же в текстовом формате в выходной файл [Write]. Будем полагать, что читатель знаком с основами работы с профилировщиком VTune, и не станем вдаваться в детали, какую кнопку нажать, чтобы запустить профилировку.
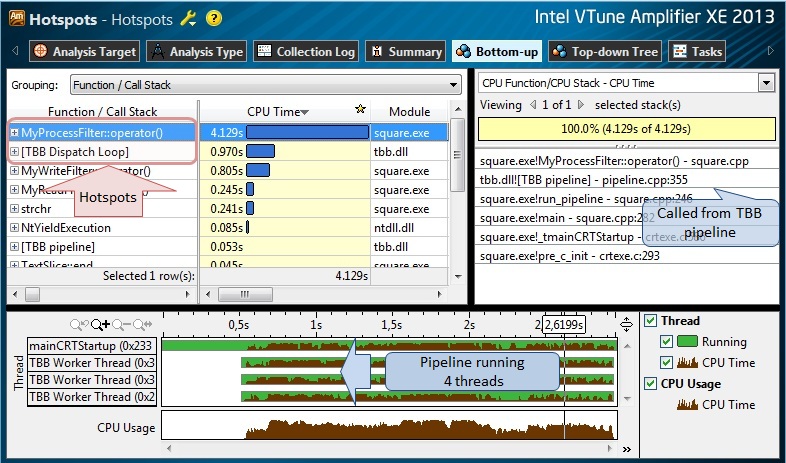
Рис.5.
Результаты Hotspot-анализа (рис.5) вполне ожидаемые – тестовая программа выполнялся 4-мя потоками на 4-х ядерном процессоре; метод MyProcessClass::operator(), вызываемый из TBB pipeline является самой “горячей” функцией, так как он выполняет конвертацию из текстового в целочисленное значение, вычисляет квадрат значения, и выполняет обратную конвертацию в текст. Что интересно, некоторая функция [TBB Dispatch Loop] (на самом деле не функция, а условное имя, скрывающее “внутренности” планировщика TBB) тоже в списке горячих, что может говорить нам о возможном наличии накладных расходов планирования. Давайте пока продолжим с Concurrency-анализом, и определим эффективность параллелизации алгоритма.
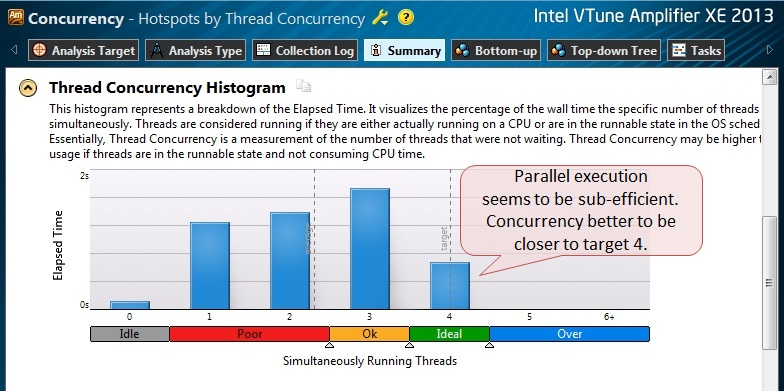
Рис.6.
Из результирующей гистограммы параллельности программы мы видим, что нам далеко до максимальной эффективности: в основном приложение исполнялось в менее чем 4-х потоках. (Синие столбики в гистограмме показывают по оси Y сколько времени приложение работало в X потоках. В идеале мы хотели бы видеть единственный столбик с уровнем параллельности 4 [concurrency level4], что означало бы, что наше приложение работало в 4-х потоках все время).
Даже быстрого взгляда на результаты в Bottom-Up View достаточно, что бы увидеть избыточную синхронизацию, которая происходила между потоками (рис.7). Можно навести указатель мышки на желтые линии перехода управления (transitions) и увидеть во всплывающем окне ссылку на источник этой синхронизации.
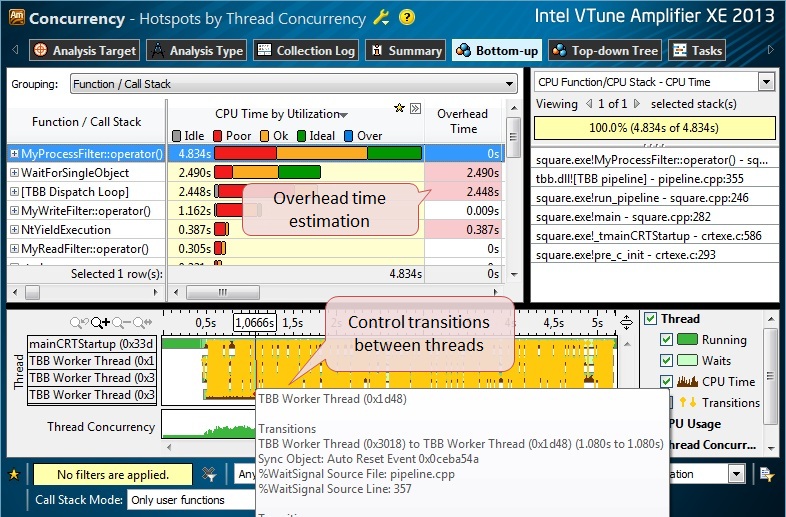
Рис.7.
В этот момент даже самый терпеливый пользователь бросил бы дальнейшие исследования, попутно обвинив разработчиков TBB в неэффективной реализации библиотеки. Тоже самое сделал бы и я, если бы у меня не было под рукой инструмента, позволяющего проанализировать работу планировщика. Теоретически, можно представить себе самостоятельную трассировку задач помощью инструментации исходного кода, и разбора трассы “вручную” либо каким-нибудь скриптом для выявления временных соотношений выполнения задач. Однако этот путь не выглядит привлекательным из-за трудоемкости обработки собранных трас. Поэтому я советую использовать инструментарий, который уже есть в VTune Amplifier и который можно использовать для быстрого восстановления структуры выполнения пользовательских задач в удобном графическом виде.
Чтобы задействовать анализатор задач нам нужно инструментировать исходный код с помощью специальных функций из Task API, который доступен в VTune Amplifier. Ниже перечислены шаги, которые необходимо сделать для этого:
- Включите в ваш исходник заголовочный файл из User API
#include "ittnotify.h" - Определите домен задачи. Часто бывает очень удобно разделять задачи, выполняемые в разных доменах, например, потоками в разных параллельных инфраструктурах (TBB, OpenMP, и т.д.)
__itt_domain* domain = __itt_domain_create("PipelineTaskDomain"); - Определите дескриптор задачи, который бы описывал стадию.
__itt_string_handle* hFileReadSubtask = __itt_string_handle_create("Read"); __itt_string_handle* hFileWriteSubtask = __itt_string_handle_create("Write"); __itt_string_handle* hDoSquareSubtask = __itt_string_handle_create("Do Square"); - Теперь оберните исходный код, выполняемый в стадиях задачи, вызовами инструментирующих API-функций: __itt_task_begin и __itt_task_end. Например, стадии чтения и записи могут быть интрументированы следующим образом:
void* MyReadFilter::operator()(void*) { __itt_task_begin(domain, __itt_null, __itt_null, hFileReadSubtask); // ALLOCATE MEMORY // READ A DATA ITEM FROM FILE // PUT DATA ITEM TO CONTAINER __itt_task_end(domain); }
void* MyWriteFilter::operator()(void*) { __itt_task_begin(domain, __itt_null, __itt_null, hFileWriteSubtask); // GET DATA ITEM FROM CONTAINER // WRITE THE DATA ITEM TO FILE // DEALLOCATE MEMORY __itt_task_end(domain); }
Точно также можно обернуть и стадию обработки чисел (Process stage). (Дальнейшую информацию по функциям User API можно найти в документации к продукту).
void* MyProcessFilter::operator()( void* item ) { __itt_task_begin(domain, __itt_null, __itt_null, hDoSquareSubtask); // FIND A CURRENT DATA ITEM IN CONTAINER // PROCESS THE ITEM __itt_task_end(domain); }
- Не забудьте добавить путь к заголовочным файлам VTune Amplifier в ваш проект:
$(VTUNE_AMPLIFIER_XE_2013_DIR)include - Статически слинкуйте ваш исполняемый модуль с библиотекой libittnotify.lib, путь к которой находится по
$(VTUNE_AMPLIFIER_XE_2013_DIR)lib[32|64] в зависимости от “битности” вашей системы.
Ну и наконец, нам осталось включить анализ пользовательских задач в окне конфигурирования анализа (рис.8) и запустить любой из типов профилировки, который нам необходим.
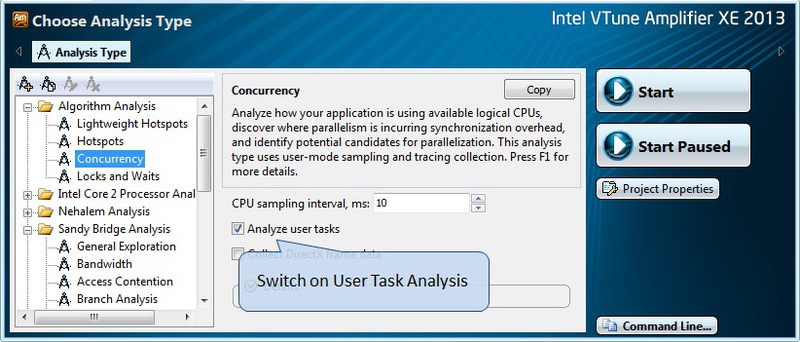
Рис.8.
После того, как закончилась профилировка Concurrency, переключаемся в Tasks View tab (рис.9). Здесь нам несколько мешают желтые линии переходов управления потоками – они могут быть отключены в панели справа, как и графики CPU Time, которые, возможно, закрывают нужную информацию. Однако, даже при этом задачи слабо различимы на временной шкале; цветные полоски, представляющие графическое изображение задач слишком тонкие, чтобы их различить. В этом случае выделите временной интервал поменьше и увеличьте масштаб (Zoom-In) из контекстного меню, вызываемого правым щелчком мышки, либо с помощью панели инструментов.
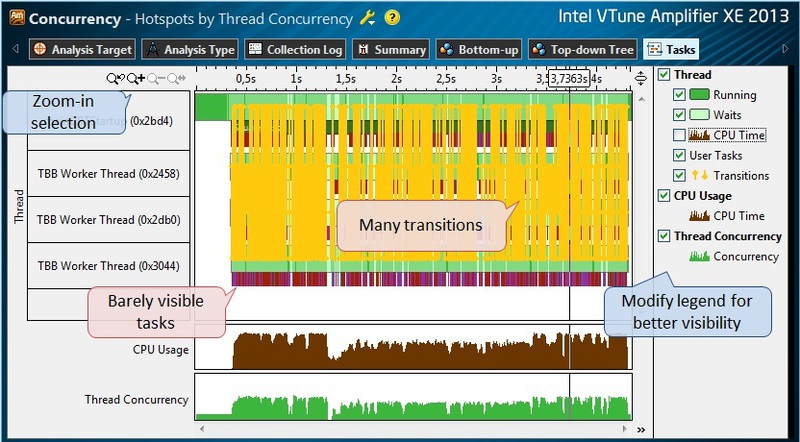
Рис.9.
В увеличенном изображении задач мы можем заметить пару проблем (рис.10). Первое – это огромные (по сравнению с длительностью самих задач) интервалы между задачами, в течение которых потоки находятся в неактивном состоянии, то есть процессоры простаивают, ожидая событий синхронизации. Вторая проблема – это длительность выполнения фаз задачи. Например, подзадача “Do Squire” выполняется всего около 0.1 миллисекунды. Это критически малый интервал исполнения, если учесть, что задачи управляются планировщиком TBB, и требуется определенное время на их планирование и назначение на исполнение рабочими потоками (TBB Worker Thread). То есть получается, что накладные расходы на управление подзадачами соизмеримы со временем выполнения самой задачи. Этого допускать нельзя, поэтому необходимо увеличить время, которое тратится на работу в подзадаче, то есть, другими словами, дать ей больше работы.
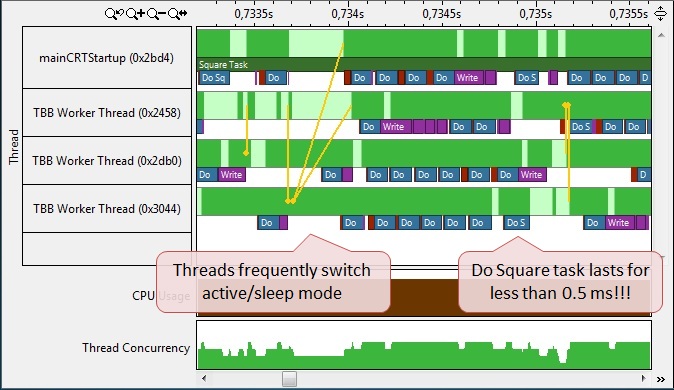
Рис. 10.
В нашем примере это и так понятно, какие функции в коде выполняют какие задачи, но это было сделано намеренно для упрощения представления в статье. В реальном приложении в исполнении задач могут быть задействованы десятки функций. Чтобы найти все функции, которые влияли на выполнение задач, и увеличить им нагрузку, мы можем переключиться в Bottom-Up view результатов для Concurrency, либо Hotspot профилировки. Теперь просто поменяем группирование функций по типу задач (TaskType/Function) и получим в таблице список подзадач, которые мы создали, инструментируя приложение. Раскрывая задачу, щелкая по значку “+”, мы получаем список и дерево вызовов функций, которые участвовали в исполнении данной подзадачи, занимая статистически значимое время процессора (рис.11).

Рис.11.
Далее, двойным щелчком мыши мы переходим в исходный код горячей функции MyProcessFilter::operator() и обнаруживаем, что она работает с передаваемым ей (text slice) отрезком текста (рис.12). Внутри этой функции происходит итерация по символам в тексте, конвертация в целочисленный тип, перемножение значения на само себя, и обратная конвертация в текстовый символ. Наиболее очевидным способов увеличения нагрузки для данной подзадачи было бы увеличение размера отрезка текста – это линейно увеличит количество операций, выполняемых в данной подзадаче. Мы просто выбираем новый размер максимального числа символов в отрезке MAX_CHAR_PER_INPUT_SLICE, который будет, скажем, в 100 раз больше первоначального (основываясь на временных показателях, которые мы получили во время профилировки). Мы так же предполагаем, что эффективность операций чтения и записи тоже вырастет с увеличением размера данных для одного объекта.

Рис.12.
Перекомпилируем приложение и профилируем его снова с использованием анализа задач (рис.13). Подзадача Do Square теперь исполняется примерно за 10 миллисекунд (наведите указатель мышки на изображение задачи, чтобы получить численные характеристики). Также практически отсутствуют “пробелы” между подзадачами, что делает потоки занятыми большее время. Можно также заметить, как планировщик TBB выстраивает одинаковые, но более короткие подзадачи, такие как фаза Write, соединяя их в более длинную очередь, и назначая на выполнения в одном потоке, тем самым снижая расходы на дополнительную синхронизацию.
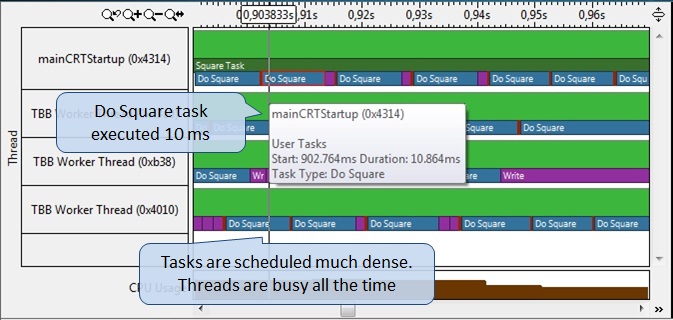
Рис.13.
Нам будет так же интересно проверить суммарную параллельность по всей программе. Как видно на рис.14, приложение выполнялось в основном 3-мя или 4-мя потоками, что является значительным достижением по сравнению с первоначальными результатами. Можно так же сравнить среднее значение Concurrency Level, но нужно помнить, что на него влияет и последовательная часть приложения, в том числе и та, которую мы не распараллеливали.
Да, сериальная часть исполнения программы остается, но она уменьшилась на треть. Ее можно так же наблюдать в результатах в TimeLine View. Если эту последовательную часть выделить и отфильтровать остальную часть времени, то мы можем увидеть, что ей соответствует фаза инициализации всего приложения в основном потоке. Если мы хотим точно определить, какая часть соответствовала работе конвейера и не относится к инициализации, то мы можем использовать функции User API, управляющие профилировкой – старт коллекции непосредственно перед созданием конвейера, и окончание коллекции после выполнении работы.

Рис.14.
Кроме графиков, дающих оценочное представление об улучшении эффективности реализации, мы можем посмотреть и сравнить численные показатели выполнения приложения. Все результаты в VTune Amplifier можно сравнивать, используя соответствующий функционал сравнения. Я просто приведу две картинки рядом, для лучшего восприятия соответствия результатов первоначального Hotspots-анализа, и полученного после изменения кода (рис.15). Что интересно, хотя время выполнения программы (Elapsed Time) уменьшилось, время, затраченное в функции MyProcessFilter::operator() не изменилось, так как у нас не поменялось общее количество работы, а просто она перераспределилась. При этом расходы на планирование задач TBB значительно сократились. Кроме того, суммарное время чтения и записи данных тоже уменьшилось, очевидно, из-за более эффективной работы с большими отрезками текста.
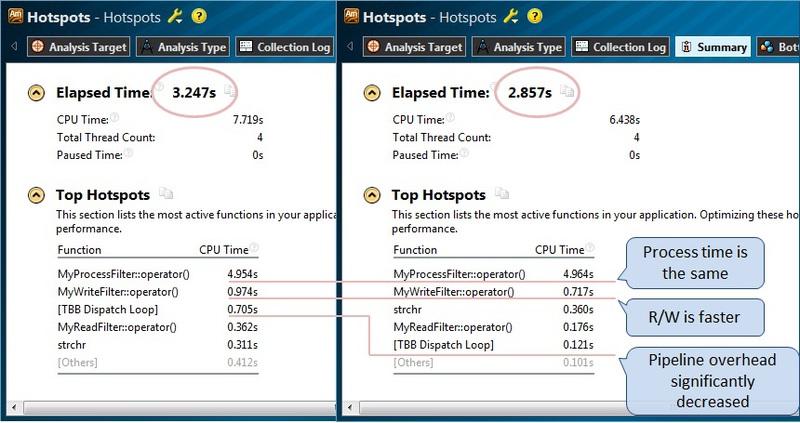
Рис.15.
Заключение
Декомпозиция по данным и по задачам эффективно используется для распараллеливания алгоритмов. Некоторые классы алгоритмов могут быть улучшены за счет использования приема конвейеризации последовательных и параллельных фаз исполнения. Библиотека Intel TBB может помочь значительно сократить время на реализацию конвейеризации алгоритмов, при этом беря на себя работу по планированию задач и сбалансированному их исполнению в имеющихся в системе потоках. Формирование задач на базе фаз алгоритма может быть нетривиальной задачей в зависимости от сложности реализуемого алгоритма, а управление выполнением задач может оказаться еще сложнее. Инструментарий Task Analysis в VTune Amplifier помогает разработчикам представлять структуру исполнения задач в многопоточной среде в удобном графическом виде, увеличивая эффективность анализа и значительно сокращая время разработки приложений.
