
Не секрет, что задачи тестирования, как ручного, так и автоматизированного, постоянно требуют создания новых тестовых стендов.
Для того чтобы автотесты Поиска Mail.Ru выполнялись быстро и во всех необходимых окружениях, нам потребовалось научиться быстро разворачивать новые виртуальные машины с определенной конфигурацией.
Большое количество виртуальных машин в нашем облаке используется браузерной фермой WebDriver, масштабируя её, мы ускоряем выполнение тестов web-интерфейса Поиска.
Кроме этого, на виртуалках мы запускаем инструменты для сбора метрик качества кода и измерения покрытия, а также инструменты для тестирования Поиска, разработанные нами.

Всё начиналось с одного сервера с установленным гипервизором KVM и управлением libvirt. При этом новая виртуалка каждый раз создавалась вручную админами через таск в Jira. Такой процесс накладывал некоторые ограничения на оперативность и управляемость инфраструктуры отдела тестирования.
С течением времени, когда количество виртуальных машин с Windows выросло, надёжность решения снизилась: периодически VM с гостевыми Windows зависали, выедали весь CPU на хост машине, либо внезапно накатывали обновления и устанавливали новые браузеры. Среда выходила из-под контроля, и продолжать управлять ею в ручном режиме стало невозможно. Проанализировав задачи, мы составили следующий список требований, которым должна удовлетворять наша будущая платформа виртуализации:
Выражая требования баззвордами, мы искали IaaS-решение для организации private cloud. Данным требованиям на сегодняшний момент соответствует достаточно много платформ. Мы же остановили свой взгляд на следующих OpenSource-решениях:
Оценив эти проекты по перспективности, отсутствию vendor lock’ов и активности community, мы приняли решение в пользу OpenStack.
OpenStack представляет собой множество сервисов, каждый из которых отвечает за какую-то важную часть его функциональности. Отдельными сервисами являются авторизация, управление блочными устройствами, управление гипервизорами и планировщик создания виртуальных машин, при этом практически любой компонент OpenStack представляет собой сервис с RESTful API. Описывать настройку каждого сервиса нет смысла: это зависит от задач, поставленных перед инфраструктурой. Остановлюсь на ключевых компонентах, используемых у нас.
— Гипервизор: мы отдали предпочтение KVM. Причины были банальны — он включён в ядро. В перспективе это избавит нас от проблем с обновлением ядра.
— Как бэкенд блочных устройств и хранилище образов виртуалок мы выбрали Ceph. На момент принятия решения разработчики заявляли, что он не является production ready, поэтому к его тестированию мы отнеслись весьма серьёзно, но проблем с производительностью/надёжностью выявлено не было, и мы решили оставить его. Вообще использование Ceph на тот момент было достаточно экзотической конфигурацией для OpenStack, но поднимать кластер Swift для нас выглядело лишённой смысла задачей.
— В качестве бэкенда виртуализации сети мы выбрали OpenVSwitch, т.к. на тот момент (релиз Grizzli) OVS был единственным решением, которое работало поверх существующего VLAN.
На этапе развёртывания мы столкнулись с некоторыми трудностями: в конце 2012 года OpenStack ещё не так гладко деплоился на CentOS, и вообще OpenStack — довольно сложный инженероёмкий продукт, поэтому мы совместно с админами потратили много усилий, чтобы развернуть и настроить его.
Если вы займетесь реализацией подобного решения, лучше, если у вас будет выделенный человек, который сможет разобраться во всех его нюансах и при необходимости вникнет в детали реализации тех или иных сервисов.
Схема взаимодействия компонент, у нас выглядит так:

После развёртывания и проведения нагрузочных испытаний всех подсистем перед нами встал вопрос, как управлять конфигурацией наших гостевых систем. Средства управления конфигурацией в последнее время на слуху, так что описывать каждое из них подробно, на мой взгляд, нет смысла.
Тем не менее, в списке кандидатов были следующие системы:
Одним из важных критериев выбора для нас было умение работать с Windows XP, так как, по нашей статистке, она прочно занимает второе место среди десктопных систем на российском рынке. По данному критерию сразу отпал Puppet – на тот момент в официальной документации XP не значилась.
SaltStack, несмотря на свою перспективность и мою личную симпатию (проект написан на Python), оказался достаточно сырым, и многие вещи пришлось бы реализовывать самостоятельно (бутстрап новых нод, интеграция с cloud-init, наличие web api, и т. п.) либо ждать, пока проект эволюционно дойдёт до них сам.
В конечном итоге выбор пал на Chef: он лучше всего соответствовал нашим
требованиям, а также динамика его развития и активность community существенно опережала его конкурента (Salt).
Наша работа с Chef ничем не отличается от классического подхода, описанного на Хабре много раз: мы используем knife и плагин knife-openstack для интеграции с API OpenStack, knife-windows для бутстрапа Windows-нод и knife-spork для оповещений и организации процесса работы с Chef (статический анализ, работа с версиями, загрузка кукбуков/ролей/датабагов на сервер Chef).
Отдельно стоит рассказать о том, как мы тестируем и отлаживаем кукбуки. Без тестирования кукбука мы не выполняем push в репозиторий и не заливаем кукбук в Chef. Для этих целей мы используем vagrant www.vagrantup.com
— он позволяет автоматизировать процесс создания виртуальной машины и применение к ней кукбуков Chef. К слову, vagrant интегрируется не только с Chef; также есть возможность интегрировать его с другими CMS salt/puppet/cfengine/ansible.
Бывает так, что в общем доступе нет необходимых нам vagrant боксов (это зачастую касается Windows — из-за особенностей лицензионной политики), или боксы необходимо предварительно собрать. В таких случаях мы используем veewee. Veewee — это инструмент для подготовки vagrant боксов, он автоматизирует процедуру сборки vagrant box файлов для целевых операционных систем. Мы активно используем veewee для тестирования подготовки Windows box, а также для тестирования unattended установки Windows.
Так как же работает эта связка? Попробую описать конечный сценарий использования, чтобы стало понятнее. Оттолкнемся от какой-либо “живой” задачи. К примеру, нам необходимо для тестовых целей раскатывать браузер Amigo на несколько целевых платформ — пусть это будут Windows 7/Windows XP/Windows Vista/Windows 8.
Спустя несколько минут в нашем распоряжении настроенные виртуальные машины, на которых можно выполнять дальнейшие действия по тестированию (как ручному, так и автоматизированному).
Переход на данную инфраструктуру позволил накапливать знания в коде. Теперь у нас нет необходимости писать подробную документацию о том, как разворачивать наши прикладные проекты и передавать эти знания отделу оперирования. Всё описывается кодом (мы стараемся следовать идеологии Infrastructure as a Code). Мы в состоянии сами отладить наши deploy-процедуры (Vagrant) и создать новые vagrant box’ы c помощью Veewee. Переход на документируемую кодом инфраструктуру позволил нам сократить издержки на обновление, масштабирование и восстановление после сбоев нашей среды. А кроме того:
В список несомненных плюсов можно добавить то, что данное решение базируется на OpenSource компонентах (за исключением виртуальных машин Windows, лицензии на которые мы получаем по подписке MSDN).
В планах на будущее — обнародовать наши кукбуки для Chef и шаблоны veewee для сборки Windows (они у нас несколько отличаются от стандартных). Если данная тема заинтересует сообщество, мы также планируем написать статью про особенности подготовки образов Windows для OpenStack (rackspace/hpcloud).
Для того чтобы автотесты Поиска Mail.Ru выполнялись быстро и во всех необходимых окружениях, нам потребовалось научиться быстро разворачивать новые виртуальные машины с определенной конфигурацией.
Большое количество виртуальных машин в нашем облаке используется браузерной фермой WebDriver, масштабируя её, мы ускоряем выполнение тестов web-интерфейса Поиска.
Кроме этого, на виртуалках мы запускаем инструменты для сбора метрик качества кода и измерения покрытия, а также инструменты для тестирования Поиска, разработанные нами.

Предыстория
Всё начиналось с одного сервера с установленным гипервизором KVM и управлением libvirt. При этом новая виртуалка каждый раз создавалась вручную админами через таск в Jira. Такой процесс накладывал некоторые ограничения на оперативность и управляемость инфраструктуры отдела тестирования.
С течением времени, когда количество виртуальных машин с Windows выросло, надёжность решения снизилась: периодически VM с гостевыми Windows зависали, выедали весь CPU на хост машине, либо внезапно накатывали обновления и устанавливали новые браузеры. Среда выходила из-под контроля, и продолжать управлять ею в ручном режиме стало невозможно. Проанализировав задачи, мы составили следующий список требований, которым должна удовлетворять наша будущая платформа виртуализации:
- Наличие API для управления и библиотек, реализующих его
- Управление статусом виртуальной машины
- Управление профилем виртуальной машины (память/CPU/диск)
- Управление квотами для разных пользователей (нам очень не хотелось получить ситуацию, когда один пользователь мог повлиять на работоспособность других виртуальных окружений)
- Управление дисковыми подсистемами (бекапы/снапшоты)
- Управление сетью
- Возможности горизонтального масштабирования и обеспечение необходимого уровня отказоустойчивости
- Живое community
- Перспективы развития
Выбор решения
Выражая требования баззвордами, мы искали IaaS-решение для организации private cloud. Данным требованиям на сегодняшний момент соответствует достаточно много платформ. Мы же остановили свой взгляд на следующих OpenSource-решениях:
- Proxmox VE www.proxmox.com/proxmox-ve
- Xen www.xenproject.org
- OpenStack www.openstack.org
- Eucalyptus www.eucalyptus.com
- OpenNebula opennebula.org
Оценив эти проекты по перспективности, отсутствию vendor lock’ов и активности community, мы приняли решение в пользу OpenStack.
OpenStack представляет собой множество сервисов, каждый из которых отвечает за какую-то важную часть его функциональности. Отдельными сервисами являются авторизация, управление блочными устройствами, управление гипервизорами и планировщик создания виртуальных машин, при этом практически любой компонент OpenStack представляет собой сервис с RESTful API. Описывать настройку каждого сервиса нет смысла: это зависит от задач, поставленных перед инфраструктурой. Остановлюсь на ключевых компонентах, используемых у нас.
— Гипервизор: мы отдали предпочтение KVM. Причины были банальны — он включён в ядро. В перспективе это избавит нас от проблем с обновлением ядра.
— Как бэкенд блочных устройств и хранилище образов виртуалок мы выбрали Ceph. На момент принятия решения разработчики заявляли, что он не является production ready, поэтому к его тестированию мы отнеслись весьма серьёзно, но проблем с производительностью/надёжностью выявлено не было, и мы решили оставить его. Вообще использование Ceph на тот момент было достаточно экзотической конфигурацией для OpenStack, но поднимать кластер Swift для нас выглядело лишённой смысла задачей.
— В качестве бэкенда виртуализации сети мы выбрали OpenVSwitch, т.к. на тот момент (релиз Grizzli) OVS был единственным решением, которое работало поверх существующего VLAN.
На этапе развёртывания мы столкнулись с некоторыми трудностями: в конце 2012 года OpenStack ещё не так гладко деплоился на CentOS, и вообще OpenStack — довольно сложный инженероёмкий продукт, поэтому мы совместно с админами потратили много усилий, чтобы развернуть и настроить его.
Если вы займетесь реализацией подобного решения, лучше, если у вас будет выделенный человек, который сможет разобраться во всех его нюансах и при необходимости вникнет в детали реализации тех или иных сервисов.
Схема взаимодействия компонент, у нас выглядит так:

Управление конфигурацией
После развёртывания и проведения нагрузочных испытаний всех подсистем перед нами встал вопрос, как управлять конфигурацией наших гостевых систем. Средства управления конфигурацией в последнее время на слуху, так что описывать каждое из них подробно, на мой взгляд, нет смысла.
Тем не менее, в списке кандидатов были следующие системы:
- SaltStack saltstack.org
- Opscode Chef www.getchef.com
- Puppet puppetlabs.com
Одним из важных критериев выбора для нас было умение работать с Windows XP, так как, по нашей статистке, она прочно занимает второе место среди десктопных систем на российском рынке. По данному критерию сразу отпал Puppet – на тот момент в официальной документации XP не значилась.
SaltStack, несмотря на свою перспективность и мою личную симпатию (проект написан на Python), оказался достаточно сырым, и многие вещи пришлось бы реализовывать самостоятельно (бутстрап новых нод, интеграция с cloud-init, наличие web api, и т. п.) либо ждать, пока проект эволюционно дойдёт до них сам.
В конечном итоге выбор пал на Chef: он лучше всего соответствовал нашим
требованиям, а также динамика его развития и активность community существенно опережала его конкурента (Salt).
Наша работа с Chef ничем не отличается от классического подхода, описанного на Хабре много раз: мы используем knife и плагин knife-openstack для интеграции с API OpenStack, knife-windows для бутстрапа Windows-нод и knife-spork для оповещений и организации процесса работы с Chef (статический анализ, работа с версиями, загрузка кукбуков/ролей/датабагов на сервер Chef).
Тестирование
Отдельно стоит рассказать о том, как мы тестируем и отлаживаем кукбуки. Без тестирования кукбука мы не выполняем push в репозиторий и не заливаем кукбук в Chef. Для этих целей мы используем vagrant www.vagrantup.com
— он позволяет автоматизировать процесс создания виртуальной машины и применение к ней кукбуков Chef. К слову, vagrant интегрируется не только с Chef; также есть возможность интегрировать его с другими CMS salt/puppet/cfengine/ansible.
Бывает так, что в общем доступе нет необходимых нам vagrant боксов (это зачастую касается Windows — из-за особенностей лицензионной политики), или боксы необходимо предварительно собрать. В таких случаях мы используем veewee. Veewee — это инструмент для подготовки vagrant боксов, он автоматизирует процедуру сборки vagrant box файлов для целевых операционных систем. Мы активно используем veewee для тестирования подготовки Windows box, а также для тестирования unattended установки Windows.
Сценарии использования
Так как же работает эта связка? Попробую описать конечный сценарий использования, чтобы стало понятнее. Оттолкнемся от какой-либо “живой” задачи. К примеру, нам необходимо для тестовых целей раскатывать браузер Amigo на несколько целевых платформ — пусть это будут Windows 7/Windows XP/Windows Vista/Windows 8.
- Для начала мы подготавливаем vagrant боксы этих систем (если таковых ещё не имеется).
- Затем создаём кукбуки (knife cookbook create…), описывающие установку Amigo на каждую из этих систем (в каких-то случаях процедура будет унифицирована, в каких-то придётся добавлять предварительные условия и зависимости от операционных систем).
- Следующим шагом будет проверка того, корректно ли выкатывается созданный нами кукбук на каждую из целевых операционных систем (vagrant up), рисунок для упрощения восприятия:
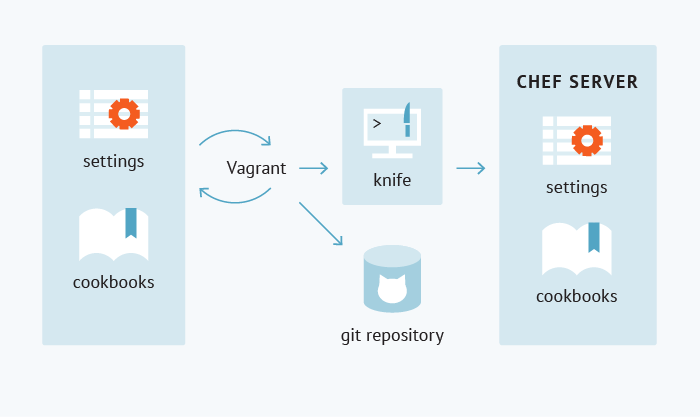
- После тестирования мы загружаем кукбук и его зависимости на сервер Chef (knife spork upload...).
- Создаём, описываем и загружаем роли (knife role from file...).
- И последним шагом создаём виртуальные машины с целевыми ОС, присваиваем им роли (knife openstack server create...). ещё один поясняющий рисунок:

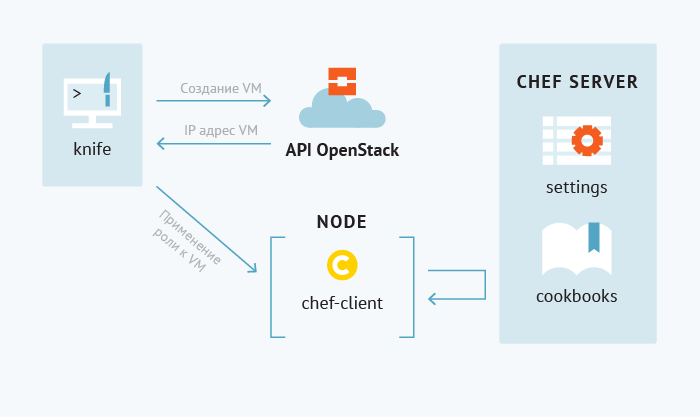
Спустя несколько минут в нашем распоряжении настроенные виртуальные машины, на которых можно выполнять дальнейшие действия по тестированию (как ручному, так и автоматизированному).
Что мы получили
Переход на данную инфраструктуру позволил накапливать знания в коде. Теперь у нас нет необходимости писать подробную документацию о том, как разворачивать наши прикладные проекты и передавать эти знания отделу оперирования. Всё описывается кодом (мы стараемся следовать идеологии Infrastructure as a Code). Мы в состоянии сами отладить наши deploy-процедуры (Vagrant) и создать новые vagrant box’ы c помощью Veewee. Переход на документируемую кодом инфраструктуру позволил нам сократить издержки на обновление, масштабирование и восстановление после сбоев нашей среды. А кроме того:
- ускорить тестирование наших десктопных продуктов
- автоматизировать выкладку наших кастомных инструментов отчётности/тестового мониторинга (мы активно применяем практики continuous delivery)
- ускорить настройку/выкладку инфраструктурных решений, которые требуются отделу тестирования (nexus/sonar и прочее)
- исключить из цепочки идея-решение ручной труд системных администраторов по созданию и настройке окружений
В список несомненных плюсов можно добавить то, что данное решение базируется на OpenSource компонентах (за исключением виртуальных машин Windows, лицензии на которые мы получаем по подписке MSDN).
В планах на будущее — обнародовать наши кукбуки для Chef и шаблоны veewee для сборки Windows (они у нас несколько отличаются от стандартных). Если данная тема заинтересует сообщество, мы также планируем написать статью про особенности подготовки образов Windows для OpenStack (rackspace/hpcloud).
