
Продолжаем рассказ о методологиях разработки в области Больших Данных, применяемых в компании «МегаФон» (первая часть статьи тут). Каждый день приносит нам новые задачи, которые требуют новых решений. Поэтому и методики организации разработки постоянно совершенствуются.
Практическое воплощение «Канбан» – это результаты с крайне оперативной обратной связью. Этим требованиям отвечает концепция Continuous Delivery (CD), визуализировать которую можно в виде конвейера:

Принятая нами методология разработки подразумевает очень короткие периоды итераций. По этой причине CD-конвейер максимально автоматизирован: все три этапа тестирования проводятся без участия человека на сервере непрерывной интеграции. Он берет все изменения, внесенные на этапе «Разработка», применяет их, проводит тесты, после чего выдает отчет об успешности прохождения тестирования. Последний этап, «Внедрение», делается также автоматически на тестовых средах разработчиков, а для развертывания на пользовательских средах нужна команда человека.
Если говорить о каком-то одном приложении (например, создается простой вебсайт), то процесс CD не приводит к каким-либо сложностям. Но в случае разработки платформы ситуация меняется: платформа может иметь множество разных применений. Еще труднее будет протестировать все изменения при создании платформы для обработки данных: для получения точных результатов потребуется загрузить пару десятков терабайт данных. Это существенно удлиняет цикл непрерывной интеграции, поэтому его необходимо разделить на более мелкие задачи и проводить тестирование на небольших объемах данных.
Что именно поставляется в рамках процесса CD:
• Регулярные процессы, работающие на Hadoop (ETL).
• Аналитические сервисы реального времени.
• Интерфейсы для потребителей результатов аналитики.
Типичное бизнес-требование охватывает все три комплекта поставки: нужно наладить регулярные и онлайновые (в реальном времени) процессы, а также предоставить доступ к результатам — создать интерфейсы. Разнообразие интерфейсов существенно усложняет процесс разработки, все они требуют обязательного тестирования в рамках процесса CD.
Интеграция нон-стоп
Тестируемость продукта – одно из главных требований методологии CD. Для этого нами был создан инструментарий, позволяющий автоматически тестировать предметы поставки на машине разработчика, на сервере непрерывной интеграции и в среде приемочного тестирования. Например, для процессов, разработанных на языке программирования Apache Pig, мы разработали maven-плагин, который позволяет локально тестировать скрипты, также написанные на Apache Pig, как будто бы они работают на большом кластере. Это позволяет заметно экономить время.
Также мы разработали собственный инсталлятор. Он выполнен в виде DSL-языка на базе Groovy и позволяет очень просто и наглядно указать, куда нужно отправить каждый предмет поставки. Вся информация об имеющихся средах — тестовых, preproduction и production — хранится в созданном нами конфигурационном сервисе. Этот сервис является исполнительным посредником между инсталлятором и средами.
После развертывания предметов поставки проводится автоматизированное приемочное тестирование. Во время этого процесса имитируются все возможные действия пользователя: движение курсором мыши, переход по ссылкам в интерфейсах и на веб-страницах. То есть проверяется корректность работы системы с точки зрения пользователя. По сути, бизнес-требования однозначно фиксируются в виде приемочных тестов. Предметы поставки подвергаются также автоматизированному нагрузочному тестированию. Его цель заключается в подтверждении соблюдения требований по производительности. Для этого у нас выделена специальная среда.
Следующим этапом является статистический анализ качества кода на стиль и типичные ошибки кодирования. Код должен быть верен с точки зрения компилятора, не содержать логических ошибок, плохих имен и прочих огрехов стиля. Качество кода контролируют все разработчики, но в нашей сфере применение подобного анализа к предметам поставки не является стандартным шагом.
Инфраструктура
После успешного завершения тестирования начинается этап развертывания. В процессе отправки объектов поставки в промышленную эксплуатацию управление происходит автоматически, без участия человека. Наш серверный парк состоит из более чем 200 машин, для управления конфигурациями серверов используется система Puppet. Достаточно физически установить сервер в стойку, указать системе управления среду для подключения и роль сервера, а дальше все происходит автоматически: скачивание всех настроек, установка ПО, подключение к кластеру, запуск серверных компонентов, соответствующий нужной роли. Такой подход позволяет подключать и отключать серверы десятками, а не поштучно.
Мы используем простую конфигурацию среды:
• Рабочие серверы (worker nodes) в виде обычных «железных» машин.
• Облако виртуальных машин для различных утилитарных задач, не требующих больших мощностей. Например, управление метаданными, репозиторий артефактов, мониторинг.
Благодаря такому подходу утилитарные задачи не занимают мощностей физических серверов, а служебные сервисы надежно защищены от сбоев, виртуальные машины перезапускаются автоматически. При этом рабочие серверы не являются единственными точками сбоя и могут быть безболезненно заменены или переконфигурированы. Часто можно слышать о платформах, где упор делается на облачную экосистему при построении кластеров. Но использование облака для решения «тяжелых» аналитических задач с большими объемами данных менее эффективно с точки зрения стоимости. Используемая нами схема построения среды дает экономию в расходах на инфраструктуру, поскольку обычная, не виртуальная, машина эффективнее на операциях ввода-вывода с локальных дисков.
Каждая среда состоит из части облака виртуальных машин и некоторого количества рабочих серверов. В том числе у нас есть тестовые среды на виртуальных машинах по запросу, которые временно разворачиваются для решения каких-то задач. Эти машины можно создать даже на локальной машине разработчика. Для автоматического развертывания виртуальных машин мы используем приложение Vagrant.
Помимо тестовых сред разработчиков мы поддерживаем три важные среды:
• Среда приемо-сдаточных испытаний — UAT.
• Cреда для нагрузочного тестирования — Performance.
• Промышленная среда — Production.
Переключение рабочих серверов из одной среды в другую занимает считанные часы. Это простой процесс, требующий минимального вмешательства человека.
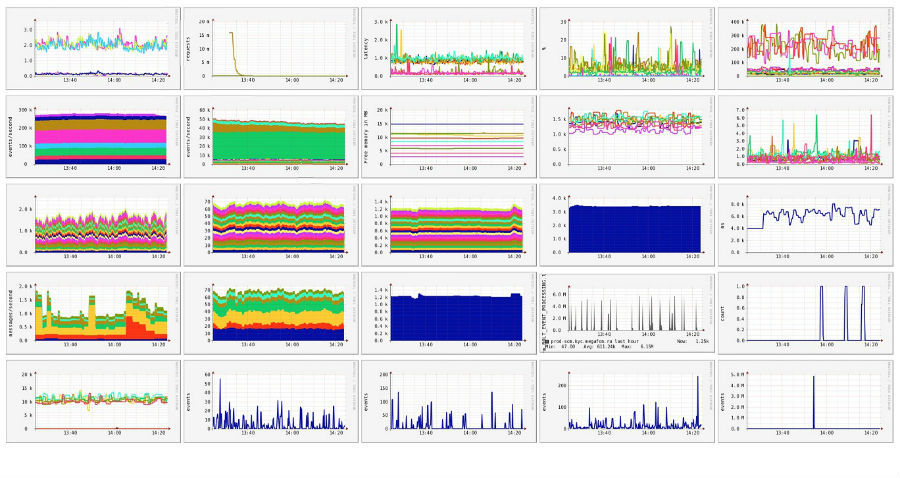
Для мониторинга используется распределенная система Ganglia, логи агрегируются в Elastic, для алертинга используется – Nagios. Вся информация выводится на видеостену, состоящую из больших телевизоров под управлением микрокомпьютеров Raspberry Pi. Каждый из них отвечает за отдельный фрагмент общего большого изображения. Эффективное и очень доступное решение: на панель выводится общая наглядная картина состояния сред и процесса непрерывной поставки. Достаточно одного взгляда, чтобы получить точную информацию том, как проходит процесс разработки, как чувствуют себя сервисы в промышленной эксплуатации.
Объем обрабатываемых нами данных превышает 500 000 сообщений в секунду. По 50 000 из них система реагирует менее чем за секунду. Накопленная база данных для анализа занимает около 5 петабайт, в перспективе она вырастет до 10 петабайт.
Каждый из серверов отправляет в мониторинг в среднем 50 метрик в минуту. Количество показателей, по которым осуществляется контроль допустимых параметров и алертинг — более 1600.
Большие Данные – бесценный источник информации: превращая цифры в знания, можно развивать новые продукты для абонентов, улучшать уже существующие, оперативно реагировать на изменение обстановки или, например, поведенческих моделей пользователей.
Вот лишь несколько примеров из достаточно большого списка применимости Больших Данных:
• Геопространственный анализ распределения нагрузки на сеть: где, как и почему возрастает нагрузка на сеть.
• Поведенческий анализ устройств в сотовой сети.
• Динамика появления новых устройств.
В частности, мы используем результаты анализа Больших Данных при радиопланировании и модернизации собственной сетевой инфраструктуры. Также нами создан ряд сервисов, предоставляющих различную аналитику в режиме реального времени.
Для открытого рынка мы (впервые на телекоммуникационном рынке России!) запустили в ноябре 2013 года геопространственный сервис анализа городских потоков, включая пешеходов и общественный транспорт. Примеров таких коммерческих сервисов, не основанных на GPS, в мире — единицы.
Отдельно немного расскажем о нашей команде. Кроме команды R&D, занимающейся непосредственно разработкой сервисов, у нас существует направление DevOps, которое отвечает за работоспособность всех решений.
Они наравне с заказчиками участвуют в процессе постановки задач, предлагают свои доработки для каждого из сервисов. Они также предъявляют требования к качеству и функционалу разработок и участвуют в тестировании и приёмке. Чуть подробнее про это направление можно почитать тут.

Про наш московский офис уже не раз писали в разных изданиях (например, тут), но следует отметить, что разработчики, DevOps и аналитики трудятся на расстоянии друг от друга): в Москве, Нижнем Новгороде и Екатеринбурге. Для того, чтобы процесс не страдал, мы используем много платных и бесплатных инструментов, значительно облегчающих всем жизнь.
Нам очень помогает Slack для общения как внутри команды разработчиков, так и с подрядчиками. Сейчас это вообще модный хипстерский тренд, но как инструмент для общения он очень и очень хорош. Кроме того, мы перешли на внутренний GitLab, интегрировали все процессы с Jira и Confluence. Для всех офисов внедрен единый стандарт разработки, единые правила оформления задач, единый подход к обеспечению сотрудников оборудованием и прочими вещами, необходимыми в работе.
С течением времени перед нами становится все больше задач. Поэтому наша команда пополняется новыми профессионалами, способными приносить пользу в самых различных областях. Работать с Большими Данными в крупном телекоммуникационном операторе – это интересная, амбициозная задача. И мы с оптимизмом смотрим в будущее – впереди нас ждет много интересного.
«Дочки» РЖД получили в пользование разработанную «МегаФоном» тестовую версию сервиса для анализа пассажироперевозок. Это инструмент, который помогает определить размер и подробные характеристики рынка перевозок. Предположительно коммерческий запуск проекта состоится в 2016 году.
Предлагаемый «МегаФоном» сервис дает возможность РЖД управлять пассажиропотоком: мотивировать людей приобретать билеты на то или иное направление, анализировать падение или рост уровня продаж, наполняемость вагонов. Анализ полученной информации позволяет оперативно вносить коррективы: варьировать цены на билеты (например, делая их привлекательными как в определенное время суток, так и в «низкий» сезон), оптимизировать расписание электричек (добавлять дополнительные поезда в часы пик и, напротив, убирать не пользующиеся спросом в определенные часы составы).
Например, сервис «МегаФона» проанализировал маршрут Москва — Волгоград — Москва в майские праздники этого года: спрос вырос на 6,8% по сравнению с тем же периодом прошлого года. При этом сервис показал, что потеря постоянных клиентов на маршруте Москва — Волгоград за последний год составила 8,3%.
В «МегаФоне» подсчитали, что транспортные компании в России тратят на подобные исследования более 1,2 млрд. руб. ежегодно. При этом сами компании могут собирать лишь часть доступных им данных, а сервис сотового оператора дает возможность увидеть всю картину рынка в целом, благодаря чему перевозчик увеличивает свою долю на общем рынке пассажироперевозок на 1,5–2%. А это миллиарды рублей.
Как мы работаем сейчас
Continuous Delivery
Практическое воплощение «Канбан» – это результаты с крайне оперативной обратной связью. Этим требованиям отвечает концепция Continuous Delivery (CD), визуализировать которую можно в виде конвейера:

Принятая нами методология разработки подразумевает очень короткие периоды итераций. По этой причине CD-конвейер максимально автоматизирован: все три этапа тестирования проводятся без участия человека на сервере непрерывной интеграции. Он берет все изменения, внесенные на этапе «Разработка», применяет их, проводит тесты, после чего выдает отчет об успешности прохождения тестирования. Последний этап, «Внедрение», делается также автоматически на тестовых средах разработчиков, а для развертывания на пользовательских средах нужна команда человека.
Если говорить о каком-то одном приложении (например, создается простой вебсайт), то процесс CD не приводит к каким-либо сложностям. Но в случае разработки платформы ситуация меняется: платформа может иметь множество разных применений. Еще труднее будет протестировать все изменения при создании платформы для обработки данных: для получения точных результатов потребуется загрузить пару десятков терабайт данных. Это существенно удлиняет цикл непрерывной интеграции, поэтому его необходимо разделить на более мелкие задачи и проводить тестирование на небольших объемах данных.
Предметы поставки
Что именно поставляется в рамках процесса CD:
• Регулярные процессы, работающие на Hadoop (ETL).
• Аналитические сервисы реального времени.
• Интерфейсы для потребителей результатов аналитики.
Типичное бизнес-требование охватывает все три комплекта поставки: нужно наладить регулярные и онлайновые (в реальном времени) процессы, а также предоставить доступ к результатам — создать интерфейсы. Разнообразие интерфейсов существенно усложняет процесс разработки, все они требуют обязательного тестирования в рамках процесса CD.
Интеграция нон-стоп
Тестируемость продукта – одно из главных требований методологии CD. Для этого нами был создан инструментарий, позволяющий автоматически тестировать предметы поставки на машине разработчика, на сервере непрерывной интеграции и в среде приемочного тестирования. Например, для процессов, разработанных на языке программирования Apache Pig, мы разработали maven-плагин, который позволяет локально тестировать скрипты, также написанные на Apache Pig, как будто бы они работают на большом кластере. Это позволяет заметно экономить время.
Также мы разработали собственный инсталлятор. Он выполнен в виде DSL-языка на базе Groovy и позволяет очень просто и наглядно указать, куда нужно отправить каждый предмет поставки. Вся информация об имеющихся средах — тестовых, preproduction и production — хранится в созданном нами конфигурационном сервисе. Этот сервис является исполнительным посредником между инсталлятором и средами.
После развертывания предметов поставки проводится автоматизированное приемочное тестирование. Во время этого процесса имитируются все возможные действия пользователя: движение курсором мыши, переход по ссылкам в интерфейсах и на веб-страницах. То есть проверяется корректность работы системы с точки зрения пользователя. По сути, бизнес-требования однозначно фиксируются в виде приемочных тестов. Предметы поставки подвергаются также автоматизированному нагрузочному тестированию. Его цель заключается в подтверждении соблюдения требований по производительности. Для этого у нас выделена специальная среда.
Следующим этапом является статистический анализ качества кода на стиль и типичные ошибки кодирования. Код должен быть верен с точки зрения компилятора, не содержать логических ошибок, плохих имен и прочих огрехов стиля. Качество кода контролируют все разработчики, но в нашей сфере применение подобного анализа к предметам поставки не является стандартным шагом.
Инфраструктура
После успешного завершения тестирования начинается этап развертывания. В процессе отправки объектов поставки в промышленную эксплуатацию управление происходит автоматически, без участия человека. Наш серверный парк состоит из более чем 200 машин, для управления конфигурациями серверов используется система Puppet. Достаточно физически установить сервер в стойку, указать системе управления среду для подключения и роль сервера, а дальше все происходит автоматически: скачивание всех настроек, установка ПО, подключение к кластеру, запуск серверных компонентов, соответствующий нужной роли. Такой подход позволяет подключать и отключать серверы десятками, а не поштучно.
Мы используем простую конфигурацию среды:
• Рабочие серверы (worker nodes) в виде обычных «железных» машин.
• Облако виртуальных машин для различных утилитарных задач, не требующих больших мощностей. Например, управление метаданными, репозиторий артефактов, мониторинг.
Благодаря такому подходу утилитарные задачи не занимают мощностей физических серверов, а служебные сервисы надежно защищены от сбоев, виртуальные машины перезапускаются автоматически. При этом рабочие серверы не являются единственными точками сбоя и могут быть безболезненно заменены или переконфигурированы. Часто можно слышать о платформах, где упор делается на облачную экосистему при построении кластеров. Но использование облака для решения «тяжелых» аналитических задач с большими объемами данных менее эффективно с точки зрения стоимости. Используемая нами схема построения среды дает экономию в расходах на инфраструктуру, поскольку обычная, не виртуальная, машина эффективнее на операциях ввода-вывода с локальных дисков.
Каждая среда состоит из части облака виртуальных машин и некоторого количества рабочих серверов. В том числе у нас есть тестовые среды на виртуальных машинах по запросу, которые временно разворачиваются для решения каких-то задач. Эти машины можно создать даже на локальной машине разработчика. Для автоматического развертывания виртуальных машин мы используем приложение Vagrant.
Помимо тестовых сред разработчиков мы поддерживаем три важные среды:
• Среда приемо-сдаточных испытаний — UAT.
• Cреда для нагрузочного тестирования — Performance.
• Промышленная среда — Production.
Переключение рабочих серверов из одной среды в другую занимает считанные часы. Это простой процесс, требующий минимального вмешательства человека.
Для мониторинга используется распределенная система Ganglia, логи агрегируются в Elastic, для алертинга используется – Nagios. Вся информация выводится на видеостену, состоящую из больших телевизоров под управлением микрокомпьютеров Raspberry Pi. Каждый из них отвечает за отдельный фрагмент общего большого изображения. Эффективное и очень доступное решение: на панель выводится общая наглядная картина состояния сред и процесса непрерывной поставки. Достаточно одного взгляда, чтобы получить точную информацию том, как проходит процесс разработки, как чувствуют себя сервисы в промышленной эксплуатации.
Метрики
Объем обрабатываемых нами данных превышает 500 000 сообщений в секунду. По 50 000 из них система реагирует менее чем за секунду. Накопленная база данных для анализа занимает около 5 петабайт, в перспективе она вырастет до 10 петабайт.
Каждый из серверов отправляет в мониторинг в среднем 50 метрик в минуту. Количество показателей, по которым осуществляется контроль допустимых параметров и алертинг — более 1600.
Использование результатов анализа
Большие Данные – бесценный источник информации: превращая цифры в знания, можно развивать новые продукты для абонентов, улучшать уже существующие, оперативно реагировать на изменение обстановки или, например, поведенческих моделей пользователей.
Вот лишь несколько примеров из достаточно большого списка применимости Больших Данных:
• Геопространственный анализ распределения нагрузки на сеть: где, как и почему возрастает нагрузка на сеть.
• Поведенческий анализ устройств в сотовой сети.
• Динамика появления новых устройств.
В частности, мы используем результаты анализа Больших Данных при радиопланировании и модернизации собственной сетевой инфраструктуры. Также нами создан ряд сервисов, предоставляющих различную аналитику в режиме реального времени.
Для открытого рынка мы (впервые на телекоммуникационном рынке России!) запустили в ноябре 2013 года геопространственный сервис анализа городских потоков, включая пешеходов и общественный транспорт. Примеров таких коммерческих сервисов, не основанных на GPS, в мире — единицы.
Команда
Отдельно немного расскажем о нашей команде. Кроме команды R&D, занимающейся непосредственно разработкой сервисов, у нас существует направление DevOps, которое отвечает за работоспособность всех решений.
Они наравне с заказчиками участвуют в процессе постановки задач, предлагают свои доработки для каждого из сервисов. Они также предъявляют требования к качеству и функционалу разработок и участвуют в тестировании и приёмке. Чуть подробнее про это направление можно почитать тут.
Про наш московский офис уже не раз писали в разных изданиях (например, тут), но следует отметить, что разработчики, DevOps и аналитики трудятся на расстоянии друг от друга): в Москве, Нижнем Новгороде и Екатеринбурге. Для того, чтобы процесс не страдал, мы используем много платных и бесплатных инструментов, значительно облегчающих всем жизнь.
Нам очень помогает Slack для общения как внутри команды разработчиков, так и с подрядчиками. Сейчас это вообще модный хипстерский тренд, но как инструмент для общения он очень и очень хорош. Кроме того, мы перешли на внутренний GitLab, интегрировали все процессы с Jira и Confluence. Для всех офисов внедрен единый стандарт разработки, единые правила оформления задач, единый подход к обеспечению сотрудников оборудованием и прочими вещами, необходимыми в работе.
С течением времени перед нами становится все больше задач. Поэтому наша команда пополняется новыми профессионалами, способными приносить пользу в самых различных областях. Работать с Большими Данными в крупном телекоммуникационном операторе – это интересная, амбициозная задача. И мы с оптимизмом смотрим в будущее – впереди нас ждет много интересного.
P.S. НА ОДНИ РЕЛЬСЫ
«Дочки» РЖД получили в пользование разработанную «МегаФоном» тестовую версию сервиса для анализа пассажироперевозок. Это инструмент, который помогает определить размер и подробные характеристики рынка перевозок. Предположительно коммерческий запуск проекта состоится в 2016 году.
Предлагаемый «МегаФоном» сервис дает возможность РЖД управлять пассажиропотоком: мотивировать людей приобретать билеты на то или иное направление, анализировать падение или рост уровня продаж, наполняемость вагонов. Анализ полученной информации позволяет оперативно вносить коррективы: варьировать цены на билеты (например, делая их привлекательными как в определенное время суток, так и в «низкий» сезон), оптимизировать расписание электричек (добавлять дополнительные поезда в часы пик и, напротив, убирать не пользующиеся спросом в определенные часы составы).
Например, сервис «МегаФона» проанализировал маршрут Москва — Волгоград — Москва в майские праздники этого года: спрос вырос на 6,8% по сравнению с тем же периодом прошлого года. При этом сервис показал, что потеря постоянных клиентов на маршруте Москва — Волгоград за последний год составила 8,3%.
В «МегаФоне» подсчитали, что транспортные компании в России тратят на подобные исследования более 1,2 млрд. руб. ежегодно. При этом сами компании могут собирать лишь часть доступных им данных, а сервис сотового оператора дает возможность увидеть всю картину рынка в целом, благодаря чему перевозчик увеличивает свою долю на общем рынке пассажироперевозок на 1,5–2%. А это миллиарды рублей.
