Всем привет! Меня зовут Сергей, я математик, и я определяю развитие рекомендательной системы Surfingbird. Этой статьёй мы открываем цикл, посвящённый машинному обучению и рекомендательным системам в частности – пока не знаю, сколько в цикле будет инсталляций, но постараюсь писать их регулярно. Сегодня я расскажу вам, что такое рекомендательные системы вообще, и поставлю задачу чуть более формально, а в следующих сериях мы начнём говорить о том, как её решать и как учится наша рекомендательная система Tachikoma.

Рекомендательные системы – это модели, которые лучше вас знают, чего вам хочется. Недавно слышал показательный анекдот: как известно, сети супермаркетов обычно стараются предсказать, чего вам хочется, чтобы вам это рекламировать (и это пример рекомендательной системы); в частности, супермаркет может попытаться распознать по изменившимся предпочтениям, что женщина забеременела, и начать это использовать. Так вот, рассказывают, что однажды в офис одного супермаркета ворвался разъярённый отец, чьей дочери-школьнице начали приходить по почте купоны на памперсы и детскую одежду; менеджеру пришлось долго извиняться и рассказывать, что все рекомендательные модели вероятностные, и ошибки вполне возможны. Через пару месяцев отец пришёл ещё раз и извинился сам – оказалось, что он далеко не всё знал о собственной дочери…
Системы коллаборативной фильтрации – это модели, которые пытаются предсказать, насколько вам понравится тот или иной продукт, получая на вход данные о том, как вы и другие пользователи оценивали этот и другие продукты в прошлом. Коллаборативная фильтрация – это самый популярный ныне вид рекомендательных систем. В Surfingbird, например, ваши оценки – это кнопки like и dislike (а также тот факт, что вы посмотрели страницу и никакой оценки не поставили, но об этом позже). Чем больше у нас данных о ваших предпочтениях, тем более интересные страницы мы можем вам порекомендовать!
Вот несколько других примеров широко известных рекомендательных систем.
Итак, возвращаемся к нашим баранам. Представим себе, что у нас есть множество пользователей и множество продуктов (для Surfingbird это веб-страницы, для Netflix – фильмы, для Last.fm – композиции), причём некоторые пользователи как-то оценили некоторые продукты. Формально говоря, данные состоят из троек вида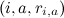 , где i обозначает пользователя, a – продукт, а
, где i обозначает пользователя, a – продукт, а 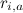 – рейтинг, который пользователь i поставил продукту a.
– рейтинг, который пользователь i поставил продукту a.
Можно представить себе эти данные как матрицу, каждая строка которой соответствует пользователю, а столбец – продукту. Наша задача – предсказать неизвестные элементы матрицы; если быть точным, наша задача – предсказать, какие из неизвестных элементов будут максимальными в своей строке, то есть какие продукты больше всего понравятся тому или иному пользователю.
У систем коллаборативной фильтрации есть несколько общих проблем, которые должна так или иначе решать любая модель.
В следующих сериях мы поговорим о том, что делать с этими и другими проблемами, а также о том, как вообще можно предсказывать неизвестные рейтинги – следите за развитием событий!

Рекомендательные системы – это модели, которые лучше вас знают, чего вам хочется. Недавно слышал показательный анекдот: как известно, сети супермаркетов обычно стараются предсказать, чего вам хочется, чтобы вам это рекламировать (и это пример рекомендательной системы); в частности, супермаркет может попытаться распознать по изменившимся предпочтениям, что женщина забеременела, и начать это использовать. Так вот, рассказывают, что однажды в офис одного супермаркета ворвался разъярённый отец, чьей дочери-школьнице начали приходить по почте купоны на памперсы и детскую одежду; менеджеру пришлось долго извиняться и рассказывать, что все рекомендательные модели вероятностные, и ошибки вполне возможны. Через пару месяцев отец пришёл ещё раз и извинился сам – оказалось, что он далеко не всё знал о собственной дочери…
Системы коллаборативной фильтрации – это модели, которые пытаются предсказать, насколько вам понравится тот или иной продукт, получая на вход данные о том, как вы и другие пользователи оценивали этот и другие продукты в прошлом. Коллаборативная фильтрация – это самый популярный ныне вид рекомендательных систем. В Surfingbird, например, ваши оценки – это кнопки like и dislike (а также тот факт, что вы посмотрели страницу и никакой оценки не поставили, но об этом позже). Чем больше у нас данных о ваших предпочтениях, тем более интересные страницы мы можем вам порекомендовать!
Вот несколько других примеров широко известных рекомендательных систем.
- Amazon – один из лидеров области; Amazon рекомендует вам книги и другие товары, основываясь на том, что вы покупали, что просматривали, какие рейтинги ставили, какие оставляли отзывы… Да, как это обычно и бывает, Большой Брат собирает всё, даже если кое-что пока не умеет использовать.
- Netflix – в России мало знают эту компанию, да она и не работает на Россию, однако именно Netflix громче всех заявила о себе в научном сообществе, когда объявила знаменитый Netflix Prize, пообещав $1M за то, чтобы улучшить качество их алгоритма предсказаний на 10% (о Netflix Prize и уроках, которые из него удалось извлечь, мы поговорим в одной из следующих серий). Основа бизнеса Netflix – аренда фильмов; сейчас компания перешла на потоковое видео, однако первые десять лет своей жизни они рассылали по почте физические DVD, которые потом нужно было отсылать обратно, чтобы получить следующий (деньги при этом брались за подписку). Русскому человеку, конечно, трудно понять, как это – платить деньги за то, чтобы скачать фильм, или даже не скачать, а посмотреть онлайн – но модель оказалась очень успешной, а опубликованный для Netflix Prize набор данных на несколько лет стал главным тестовым примером для систем коллаборативной фильтрации (сейчас Netflix убрала его из открытого доступа по причине возможной деанонимизации, и на смену ему пришёл Yahoo! KDD Cup Dataset).
- Last.fm и Pandora рекомендуют музыку. Они придерживаются разных стратегий рекомендации: Last.fm использует, кроме собственно рейтингов других пользователей, исключительно “внешние” данные о музыке – автор, стиль, дата, тэги и т.п., а Pandora основывается на “содержании” музыкальной композиции, используя очень интересную идею – Music Genome Project, в котором профессиональные музыканты анализируют композицию по нескольким сотням атрибутов (к сожалению, сейчас Pandora недоступна в России). Анализировать композиции автоматически пока, правда, никто хорошо не умеет – и это ещё одно интересное приложение усилий для машинного обучения...
- Google, Yahoo!, Яндекс – можно сказать, что они тоже рекомендуют пользователям сайты? Формально — да, но в реальности это другие системы: поисковики пытаются предсказать, насколько данный документ релевантен данному запросу, а рекомендатели – пытаются предсказать, какой рейтинг данный пользователь поставит данному продукту. Конечно, в успехе поисковиков есть немалая заслуга моделей, основанных на данных от пользователей (click logs), и, конечно, поисковая выдача часто бывает персонализованной, но всё-таки задача немножко другая. Несколько ближе к нашей задаче проблема того, какую рекламу показывать пользователю (AdSense, Яндекс.Директ и т.д.) – здесь пользователи действительно «голосуют ногами» за рекламные объявления, и нужно «порекомендовать» те из них, которые скорее всего вызовут положительную реакцию. Но дело осложняется экономической стороной вопроса (рекламодатели платят деньги, между ними нужно устроить аукцион за право разместить рекламу), так что эти задачи мы тоже рассматривать сейчас не будем. Однако у ведущих поисковиков есть масса побочных проектов, основанных на рекомендательных системах – например, мы уже упоминали Yahoo! Music.
Итак, возвращаемся к нашим баранам. Представим себе, что у нас есть множество пользователей и множество продуктов (для Surfingbird это веб-страницы, для Netflix – фильмы, для Last.fm – композиции), причём некоторые пользователи как-то оценили некоторые продукты. Формально говоря, данные состоят из троек вида
 , где i обозначает пользователя, a – продукт, а
, где i обозначает пользователя, a – продукт, а  – рейтинг, который пользователь i поставил продукту a.
– рейтинг, который пользователь i поставил продукту a.Можно представить себе эти данные как матрицу, каждая строка которой соответствует пользователю, а столбец – продукту. Наша задача – предсказать неизвестные элементы матрицы; если быть точным, наша задача – предсказать, какие из неизвестных элементов будут максимальными в своей строке, то есть какие продукты больше всего понравятся тому или иному пользователю.
У систем коллаборативной фильтрации есть несколько общих проблем, которые должна так или иначе решать любая модель.
- Матрица рейтингов, как правило, очень разреженная (sparse) – обычно и пользователей, и продуктов много, а рейтингов на деле гораздо меньше, чем их произведение, ведь средний пользователь оценивает совсем немного продуктов; остальные же элементы матрицы нам неизвестны, и как раз их-то и надо предсказывать.
- Проблема холодного старта (cold start). Для пользователей – когда приходит новый пользователь, у которого ещё нет рейтингов, что с ним делать? Ну хорошо, когда совсем нет, это ещё ничего – можно просто рекомендовать самые популярные продукты; а что делать, если пользователь уже что-то оценил, но пока очень мало чего? Для продуктов – сколько нужно рейтингов для нового продукта, прежде чем его можно будет уверенно рекомендовать? И откуда вообще возьмутся эти рейтинги, если не рекомендовать его никому?
В следующих сериях мы поговорим о том, что делать с этими и другими проблемами, а также о том, как вообще можно предсказывать неизвестные рейтинги – следите за развитием событий!
