
Первая бестекстовая NLP-модель от FAIR, предсказание погоды от DeepMind, неожиданное применение CLIP в робототехнике и много другое в сентябрьской подборке:
Pathdreamer
Доступность: страница проекта / статья / публикация в блоге / репозиторий / колаб
Находясь в незнакомом помещении, человек способен достаточно точно предсказать планировку и понять что, скажем, справа от него находится кухня, а слева гостиная. Наш мозг воспринимает разные визуальные и семантические сигналы, чтобы эффективно перемещаться в пространстве.

Pathdreamer от Google AI пытается повторить эту человеческую способность, генерируя визуальное представление помещений с использованием только ограниченных исходных наблюдений и предлагаемой навигационной траектории. То есть, агент по разным визуальным подсказкам предсказывает, как будет выглядеть сцена, если он переместится на новую точку обзора или даже в совершенно невидимую область, например, за угол.
AI Choreographer
Доступность: публикация в блоге / репозиторий / обученная модель
Танец так или иначе представлен в любой культуре и для человека является чем-то естественным. Для модели машинного обучения поставить танец — непростая задача, которая требует непрерывного движения с высокой кинематической сложностью, взаимосвязанного с сопровождающей музыкой.

Исследователи из Google AI представили модель для генерации трехмерных танцующих моделей по звуку. Модель использует архитектуру кросс-модального трансформатора с операцией полного внимания (FACT). Для обучения использовали набор данных AIST++.
IC-GAN: Instance-Conditioned GAN
Доступность: статья / репозиторий / колаб / онлайн-демо
На сегодняшний день у генеративных состязательных сетей есть существенное ограничение: они способны генерировать только изображения объектов или сцен, которые были представлены в наборе обучающих данных. Например, сеть, обученная на датасете из автомобилей GAN, не сможет сгенерировать правдоподобное изображения цветка.

Исследователи FAIR представили новый подход обусловливания примером (instance-conditioning) для генерации изображений, даже если входного изображения не было в обучающем наборе. Таким образом можно генерировать правдоподобные нестандартные комбинации, например, зебру в городском ландшафте.
GSLM: бестекстовая NLP-модель
Доступность: публикация в блоге / статья / репозиторий
Языковые модели, такие как BERT и GPT-3, за последние годы продемонстрировали способность генерировать убедительный текст практически по любой теме. Также эти предобученные модели можно настроить для множества разных задач из области обработки естественного языка (NLP), включая анализ тональности, перевод, поиск информации, выводы и обобщение. Но все это возможно для языков с большими объемами обучающих текстовых данных.
Исследователи FAIR представили первую языковую модель, которая способна обучаться в self-supervised режиме только на сырых аудиозаписях и не требует текстовых данных. В перспективе это избавит от промежуточного ресурсоемкого автоматического распознавания речи (ASR) и позволит подавать моделям аудио данные на вход.
CLIPort
Доступность: страница проекта / статья / репозиторий
Как наделить роботов способностью точно манипулировать объектами, при этом рассуждая о них с точки зрения абстрактных концепций? — примерно таким вопросом задались исследователи NVIDIA и Вашингтонского университета.

Сквозные сети продемонстрировали свою способность к различным навыкам, требующим точного пространственного мышления, но до сих пор это удавалось реализовать только для отдельных задач без возможности к обобщению. При этом генерализация семантических представлений в CV и NLP возможна благодаря обучению на объемных датасетах. Чтобы объединить эти достижения в разных областях, исследователи совместили CLIP с TransporterNets. На практике это означает, что агент теперь понимает не только где расположен предмет, но и что это за предмет. Например, робот способен понять команду «положи игрушечную машинку в коробку».
Skillful Precipitation Nowcasting
Доступность: публикация в блоге / репозиторий
Современные прогнозы погоды с помощью решений физических уравнений обеспечивают относительно точные прогнозы на несколько дней вперед в масштабах планеты, но не справляются с высокой детализацией и более короткими сроками. При этом прогнозирование текущей погоды на ближайшие два часа важно для авиации, планирования действий при ЧС и многих других областей. DeepMind поделилась моделью, которая составляет метеорологические прогнозы с высокой точностью на короткое время.
VGPNN: Diverse Generation from a Single Video
Доступность: страница проекта / статья
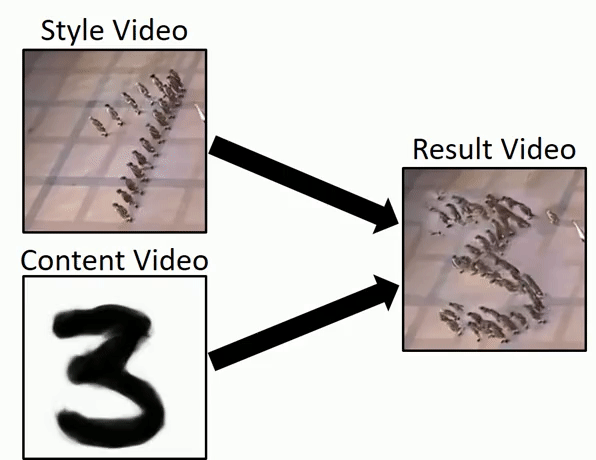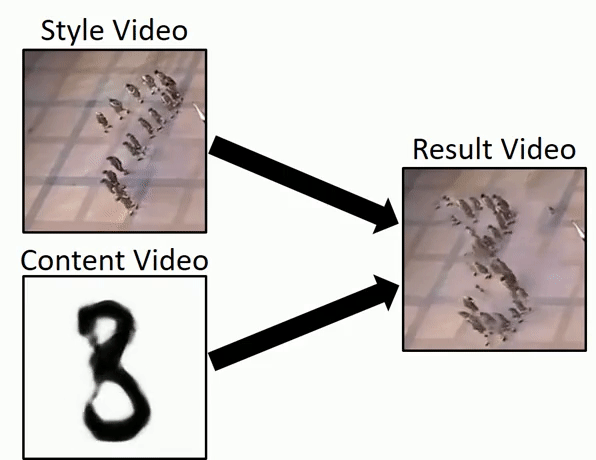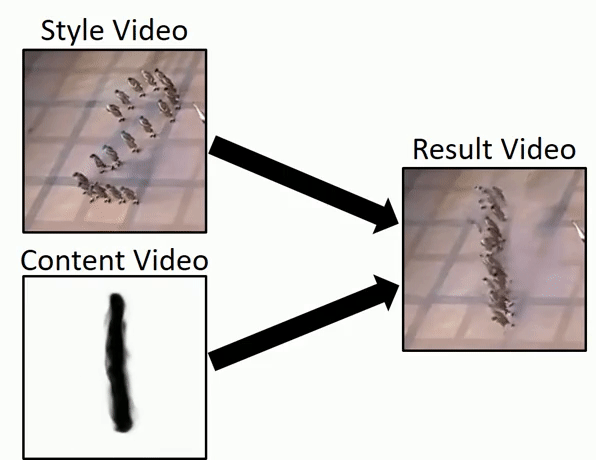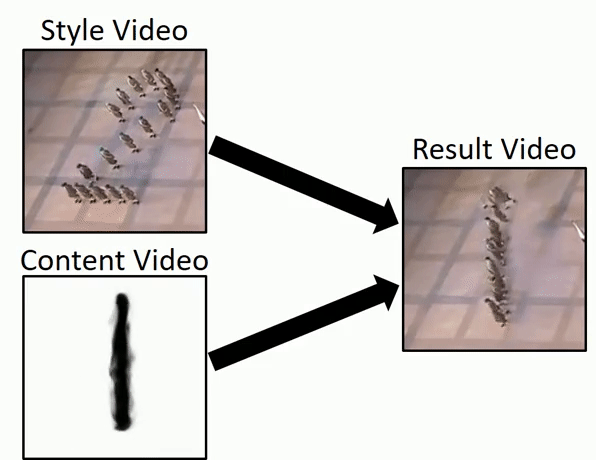
Исследователи Института Вейцмана представили быстрый способ генерации видео из одного исходного видео в высоком разрешении за считанные минуты. Это позволит создавать аугментированные наборы данных для обучения. Также модель умеет ряд других вещей — например, переносить стили, переносить движения из видео поданного на вход в отдельные области видео, которое отдается на выходе и т.д.
StyleCariGAN
Доступность: страница проекта / статья / репозиторий
Новая модель для генерации карикатур. На вход принимает портретное фото человека, а на выходе отдает шарж. При этом можно управлять степенью преувеличения форм и стилизацией цвета. В основе, как можно догадаться по названию, StyleGAN.
Texformer
Доступность: статья / репозиторий

Фреймворк на архитектуре трансофмер для восстановления 3D модели человека по одной фотографии, который демонстрирует результаты лучше, чем модели, основанные на сверточных нейросетях.
UOAIS: Unseen Object Amodal Instance Segmentation
Доступность: страница проекта / статья / репозиторий

До сих пор сегментация невидимых объектов в неструктурированной среде в лучшем случае позволяла определить только видимые области невидимых объектов. Данная модель представляет амодальное восприятие, которое позволяет агенту сегментировать загороженные другими объекты.
В сентябре стал доступен исходный код DeepSIM, GAN-модели для манипуляции фотоизображениями на основе упрощенных представлений, о которой мы писали в июле 2020.
На этом все, спасибо за внимание!
