Disclaimer: в этой статье будет очень много бредовых примеров и сверх очевидных утверждений. Если для вас предельно очевидно, что ... внутри .reduce даёт вам O(n^2), то можно сразу прыгать к разделу "Критика" или просто проигнорировать статью. Если же нет, милости прошу под cut.
Предисловие
Все мы знаем про стандартную конструкцию for (;;) которая чаще всего, в реальном коде, имеет примерно такой вид:
for (let idx = 0; idx < arr.length; ++ idx) {
const item = arr[idx];
// ...
}Далеко не все из нас любят ей пользоваться (только давайте обойдёмся без холиваров на эту тему, статья не об этом), особенно в простых сценариях, т.к. когнитивная нагрузка довольно высока ― очень много малозначительных или даже ненужных деталей. Например в таком вот сценарии:
const result = [];
for (let idx = 0; idx < arr.length; ++ idx) {
const item = arr[idx];
result.push(something(item));
}
return result;Большинство из нас предпочтёт более компактную и наглядную версию:
return arr.map(something);
// или
return arr.map(item => something(item)); note: 2-й вариант избавит вас от потенциальных проблем в будущем, когда something может внезапно обзавестись вторым аргументом. Если он будет числовым, то даже Typescript вас не убережёт от такой ошибки.
Но не будем отвлекаться. О чём собственно речь?
Всё чаще и чаще мы видим в живом коде такие методы как:
.forEach.map.reduceи другие
В общем и в целом они имеют ту же bigO complexity, что и обыкновенные циклы. Т.е. до тех пор, пока речь не заходит об экономии на спичках, программист волен выбирать ту конструкцию, что ему ближе и понятнее.
Однако всё чаще и чаще вы можете видеть в обучающих статьях, в библиотечном коде, в примерах в документации код вида:
return source.reduce(
(accumulator, item) => accumulator.concat(...something(item)),
[]
);или даже:
return Object
.entries(object)
.reduce(
(accumulator, value, key) => ({
...accumulator,
[key]: something(value)
}),
{}
);Возможно многие из вас зададутся вопросом: а что собственно не так?
Ответ: вычислительная сложность. Вы наблюдаете разницу между O(n) и O(n^2) .
Давайте разбираться. Можно начать с ... -синтаксиса. Как эта штука работает внутри? Ответ: она просто итерирует всю коллекцию (будь то элементы массива или ключи-значения в объекте) с 1-го до последнего элемента. Т.е.:
const bArray = [...aArray, 42]это примерно тоже самое, что и:
const bArray = [];
for (let idx = 0; idx < aArray.length; ++ idx)
bArray.push(aArray[idx]);Как видите, никакой магии. Просто синтаксический сахар. Тоже самое и с объектами. На лицо очевидная сложность O(n).
Но давайте вернёмся к нашему .reduce. Что такое .reduce? Довольно простая штука. Вот упрощённый полифил:
Array.prototype.reduce = function(callback, initialValue) {
let result = initialValue;
for (let idx = 0; idx < this.length; ++ idx)
result = callback(result, this[idx], idx);
return result;
}Наблюдаем всё тот же O(n). Уточню почему - мы пробегаем ровно один раз по каждому элементу массива, которых у нас N.
Что же тогда у нас получается вот здесь:
return source.reduce(
(accumulator, item) => accumulator.concat(...something(item)),
[]
);Чтобы это понять надо, ещё посмотреть, а что такое .concat. В документации вы найдёте, что он возвращает новый массив, который состоит из переданных в него массивов. По сути это поэлементное копирование всех элементов. Т.е. снова O(n).
Так чем же плох вышеприведённый код? Тем что на каждой итерации в .reduce происходит копирование всего массива accumulator. Проведём мысленный эксперимент. Заодно упростим пример (но проигнорируем существование .map, так как с ним такой проблемы не будет):
return source.reduce(
(accumulator, item) => accumulator.concat(something(item)),
[]
);Допустим наш source.length === 3. Тогда получается, что .reduce сделает 3 итерации.
На 1-й итерации наш
accumulatorпуст, поэтому по сути мы просто создаём новый массив из одного элемента.// []на 2-й итерации наш
accumulatorуже содержит один элемент. Мы вынуждены скопировать его в новый массив.// [1]на 3-й итерации уже 2 лишних элемента.
// [1, 2]
Похоже на то, что мы делаем лишнюю работу. Представьте что length === 1000. Тогда на последней итерации мы будем впустую копировать уже 999 элементов. Напоминает алгоритм маляра Шлемиля, не так ли?
Как нетрудно догадаться, чем больше length , тем больше лишней работы выполняет процессор. А это в свою очередь:
замедляет программу
т.к. Javascript однопоточный - препятствует работе пользователя с UI
тратит батарейку ноутбука или телефона на бесполезную работу
греет ваше устройство и заставляет работать кулер
В случае объектов ситуация ещё хуже, т.к. там речь идёт не о быстрых массивах, которые имеют многоуровневые оптимизации, а о dictionaries, с которыми, если кратко, всё сложно.
Но что можно с этим поделать? Много чего. Самое главное - переиспользовать тот же самый массив\объект:
// вместо
(accumulator, item) => accumulator.concat(...something(item))
// вот так
(accumulator, item) => {
accumulator.push(...something(item));
return accumulator; // это ключевая строка
}// вместо
(accumulator, value, key) => ({
...accumulator,
[key]: something(value)
},
// вот так
(accumulator, value, key) => {
accumulator[key] = something(value);
return accumulator;
}Стало чуть менее нагляднее (возможно), но разительно быстрее. Или нет? Давайте разбираться.
Как я уже сказал выше, всё зависит от размера коллекции. Чем больше итераций, тем больше разница. Я провёл пару простых тестов в Chrome и Firefox:
Firefox
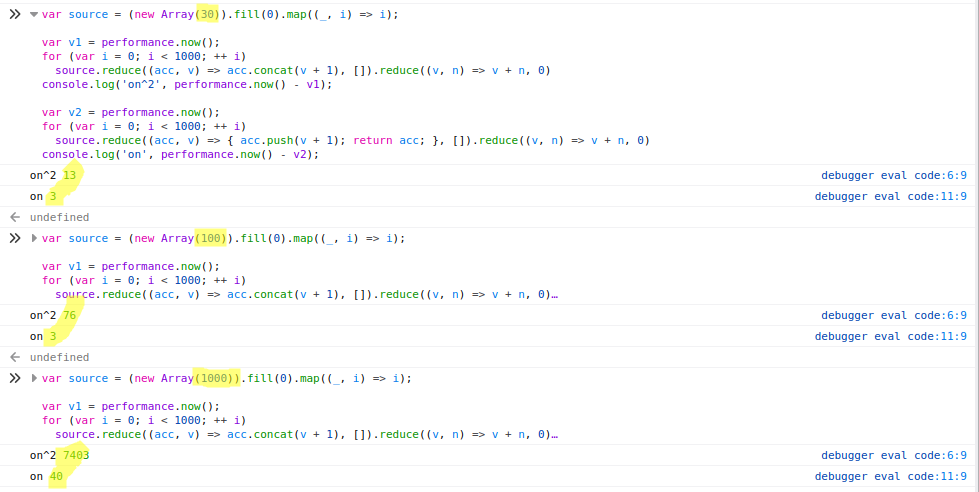
Chrome

При length=30 разница не очень убедительная (13 vs 3). При length=1000 уже становится особенно больно (2600 vs 30).
Критика
Я понимаю, что к этому моменту будет уже много недовольных моими обобщениями. Простите, я попытался написать максимально просто. Но давайте пройдёмся по наиболее популярным аргументам против:
1. При малых N вы не заметите разницу
Что же, это valid point. Если N=3, то разница столь невелика, что едва ли вы хоть когда-нибудь столкнётесь с её последствиями. Правда ваши друзья из мира C++ перестанут с вами здороваться. Особенно в мире Javascript, который как известно скриптовый язык с динамической типизацией, и, поэтому, не предназначен для решения задач, которые требуют настоящей производительности. Что впрочем не мешает ему проникать даже в эти отрасли, вызывая потоки гнева
А что если у нас не 3 элемента, а скажем 30. На моих синтетических "наколеночных" тестах получилась разница в 4 раза. Если этот участок кода выполняется единожды, а не, скажем, в цикле, то вы, скорее всего, точно также не сможете ничего заметить. Ещё бы, ведь речь идёт о долях миллисекунды.
Есть ли тут подводные камни? На самом деле да. Я бы сказал, что тут возможны (как минимум) две проблемы.
Первая проблема: сегодня ваш код исполняется единожды. Завтра вы запускаете его для какого-нибудь большого списка. Скорее всего даже не заглянув внутрь (в больших проектах это может быть очень непросто). В итоге та изначально небольшая разница, может начать играть весомую роль. И моя практика показывает, что
хочешь рассмешить бога, расскажи ему о своих планахмы слишком часто ошибаемся в своих суждениях относительно того, как наш код будет использоваться в будущем.Вторая проблема: у вас ваш код запускается для 30 элементов. Okay. Но среди ваших пользователей есть 5% таких, у которых немного нестандартные потребности. И у них уже почему-то не 30, а 300. Кстати, возможно эти 5% пользователей делают 30% вашей выручки.
Приведу пример. На немецком сайте Ikea (надеюсь они это уже исправили) была проблема: при попытке купить больше 10-12 товаров корзина заказа начинала настолько люто тормозить, что почти любая операция с ней сводилась к 40 секундным задержкам. Т.е. до глупого забавная ситуация: человек хочет купить больше, т.е. отдать компании больше денег, но т.к. где-то внутри сокрыты алгоритмы маляра Шлемиля, он не может этого сделать. Полагаю разработчики ничего об этом не знали. И QA отдел тоже (если он у них есть). Не переоценивайте ваших посетителей, далеко не каждый будет готов ждать по 40 секунд на действие. Признаю, что пример экстремальный. Зато показательный.
Итого: в принципе всё верно. Для большинства ситуаций вы и правда не заметите разницы. Но стоит ли это того, чтобы экономить одну единственную строку? Ведь для того, чтобы избежать этой проблемы, не требуется менять алгоритм, не требуется превращать код в нечитаемый ад. Достаточно просто мутировать итерируемую коллекцию, а не создавать новую.
По сути всё сводится к: каковы мои трудозатраты и каков мой результат. Трудозатраты - одна строка. Результат - гарантия того, что у вас не возникнут "тормоза" на абсолютно ровном месте.
2. Чистые функции в каждый дом
Кто-то может возразить, что пока мы возвращаем в каждой итерации новый массив наша функция чиста, а как только мы начинаем в ней что-нибудь мутировать, мы теряем драгоценную purity. Ребята, любящие FP, у меня для вас замечательная новость: вы можете сколько угодно мутировать в своих чистых функциях state. Они от этого не перестают быть чистыми. И тут в меня полетели камни.
Да, это не шутка (собственно настоящие FP-ы об этом прекрасно знают). Ваша функция должна удовлетворять всего двум критериям, чтобы оставаться чистой:
быть детерминированной
не вызывать side effect-ов
И да, мутация это effect. Но обратите внимание на слово "side". В нём вся соль. Если вы мутируете то, что было целиком и полностью создано внутри вашей функции, то вы не превращаете её в грязную. Условно:
const fn = () => {
let val = 1;
val = 2;
val = 2;
return val;
}Это всё ещё чистая функция. Т.к. val существует только в пределах конкретного вызова метода и он для неё локален. А вот так уже нет:
let val = 1;
const fn = () => {
val = 2;
return val;
}Т.е. не нужно идти ни на какие сделки с совестью (а лучше вообще избегать всякого догматизма), даже если чистота ваших функций вам важнее чистоты вашего тела.
3. Умный компилятор всё оптимизирует
Тут я буду краток: нет, не оптимизирует. Попробуйте написать свой, и довольно быстро поймёте, что нет никакой магии. Да внутри v8 есть разные оптимизации, вроде этой (Fast_ArrayConcat). И да, они не бесполезны. Но не рассчитывайте на магию. Увы, но мы не в Хогвартсе. Математические законы превыше наших фантазий.
По сути для того чтобы избежать O(n^2) в такой ситуации, компилятору необходимо догадаться, что сия коллекция точно никому не нужна и не будет нужна в текущем виде. Как это гарантировать в языке, в котором почти ничего нельзя гарантировать (из-за гибкости и обилия абстракций)?
Причина
Зачем эта статья? От безысходности и отчаяния. Мне кажется основной причиной этой широко распространённой проблемы является React и Redux, с их любовью к иммутабельности. Причём не сами эти библиотеки, а различные материалы к ним (коих тысячи), где встречается этот "паттерн". Если по началу это можно было объяснить тем, что хочется приводить максимально простые примеры, то сейчас это стало mainstream-ом.
Вот например:
PS: coming-out - часто делаю concat внутри reduce 🙂 в 99% задач вроде не сильно афектит
Или вот:
getDependencies(nodes) {
this.processQueue();
return nodes.reduce(
(acc, node) => acc.concat(Array.from(this.dependencies.get(node) || [])),
[]
);
}I'm pretty surprised that this has any impact, I don't have a good rationale for why but it appears to be dramatically faster to update the array in place.
Складывается ощущение, что этот "паттерн" применяется почти в каждой второй статье про Javascript. Я думаю настало время что-то с этим делать. Люди на собеседованиях не видят никакой проблемы в вызове .includes внутри .filter и подобных штуках. ...-синтаксис по их мнению работает за O(1). А v8 переполнен магией. Люди с 7-ю+ годами боевого опыта делают удивлённые глаза и не понимают, что может пойти не так. Впрочем это уже другая история.
P.S. по вопросам опечаток и стилистических ошибок просьба обращаться в личку.
