
«ООП для меня означает лишь обмен сообщениями, локальные ограничения и защиту, сокрытие состояния процесса и крайне позднее привязывание», — Алан Кэй (человек, придумавший термин «объектно-ориентированное программирование»)1
Похоже, многим не нравится объектно-ориентированное программирование. Первое, что приходит в голову, когда слышишь эту трёхбуквенную аббревиатуру — это пример с автомобилем, наследование, геттеры, сеттеры и ObjectFactoryFactorySingleton.
Мне это всегда казалось довольно странным. Мне не только нравится ООП, я ещё и считаю, что часто это лучший/наиболее очевидный способ моделирования задачи. И ниже я расскажу, почему.
ОО-что?
Наверно, прежде чем двигаться дальше, нам нужно определиться, о чём мы говорим. К сожалению, понятие ООП определено не очень чётко. Так что давайте сначала придём к чёткому и недвусмысленному определению.
Мы много будем говорить об «объектах». Что же это такое? В большинстве введений в ООП для объяснения объектов используется что-то физическое, например, автомобили или животные. И хотя в этом нет ошибки (это в буквальном смысле источник происхождения метафоры объектов; Алан Кэй рассуждал с точки зрения биологических клеток и сетей1), такие сравнения сбивают с толку, потому что объекты — это гораздо большее.
Питер Вегнер писал: «Объекты — это коллекции операций, имеющих общее состояние»2.
Марк Стефик и Дэниел Бобров дают следующее определение: «Объекты — это сущности, сочетающие в себе свойства процедур и данных, потому что они выполняют вычисления и хранят локальное состояние. Единообразное применение объектов контрастирует с использованием отдельных процедур и данных в традиционном программировании»3.
Вот ещё одно определение банды четырёх: «Объектно-ориентированные программы состоят из объектов. Объект включает в себя и данные, и процедуры, которые могут обрабатывать данные. Процедуры обычно называют методами или операциями»4.
Неплохо для начала, но мне кажется, что здесь не хватает важной характеристики объектов. Возможно, нам поможет Тим Рентш: «Объекты — единицы состояния, в общем случае непрозрачные снаружи. На мой взгляд, это важная часть. Позже мы увидим, почему. Однако объект может предоставить возможность взаимодействия со своим состоянием при помощи передачи сообщений (= „методов“)»5.
Постойте-ка… «Коллекции операций, имеющих общее состояние»? «Сущности, сочетающие в себе свойства процедур и данных»? «Единицы состояния»? Что это всё значит? Это означает, что «объект» — это абстрактное понятие. Потенциально объектом может быть что угодно — всё, у чего есть состояние. Это может быть физический предмет, например, автомобиль, абстрактная концепция, какой-то произвольный блок данных с прикреплённым к нему поведением. ООП просто означает, что мы моделируем нашу задачу при помощи этих объектов. Вот и всё.
▍ Отдельный класс
Вы можете подумать: «Подождите, мы дали определение ООП, даже не упомянув классы. Что происходит?»
Ответ прост: классы не строго необходимы для ООП. Знаю, это может шокировать.
Разумеется, нам нужна возможность создания новых объектов, и языки на основе классов, очевидно, распространены сильнее. Однако это не единственный способ достижения цели.
В языках наподобие JavaScript (хотя ES6 добавил в язык классы6, 7) и Lua используется концепция ООП на основе прототипов или прототипного ООП. Вместо создания схемы для конструирования новых объектов мы используем существующий объект в качестве прототипа. Такой подход даже может иметь реальные преимущества, поскольку снижает сложность языка8.
Небольшое примечание: классы необязательно должны называться классами. Например, в языках наподобие Go9 или Rust10, и даже в какой-то степени C++11 они называются struct.
▍ Это наследственное
Ещё один термин, который, несмотря на его необязательность, часто ассоциируется с ООП — это наследование.
Существует две причины для использования наследования:
Первая — многократное применение уже написанного кода. Однако в современном программировании от этого обычно отказываются в пользу композиции объектов (объекта внутри другого объекта).
Вторая (на мой взгляд, более важная) — для абстрагирования и полиморфизма. Это называется техническим термином «субтипирование».
▍ Субтипирование
Да, я считаю, что эта тема настолько важна, что заслуживает отдельного заголовка.
Субтипирование — не уникальная для ООП особенность, но имеет в нём особое значение, потому что это основной способ моделирования полиморфизма. Смысл его заключается в объединении нескольких классов, имеющих общие сообщения (например, обладающие методами со схожей семантикой) в один супертип, определяющий эти сообщения. Супертип можно использовать вместо указания субтипа.
Мой любимый пример применения субтипирования на практике — это фреймворк коллекций Java. Он определяет интерфейсы (позже мы поговорим, что это такое) для распространённых сценариев использования, например, списков, очередей, множеств, Map, а также различные реализации с разными характеристиками, поддерживающие эти сценарии использования.

Граф сгенерирован из JavaDocs при помощи скрэйпинга всех известных подклассов Collection и Map с удалением всех нерелевантных узлов
Допустим, мне нужно обработать список данных, тогда я просто буду использовать везде интерфейс List. Там, где я создаю экземпляр List, я выбираю ArrayList, потому что обычно это более высокопроизводительная реализация. Позже оказывается, что программа выполняет множество вставок/удалений в начале списка, а эти операции с массивами происходят довольно медленно. Чтобы ускорить программу, я могу перейти на LinkedList, не меняя никакие сигнатуры типов.
Примечание: при вызове метода нам нужно знать реальный класс объекта, а не только его объявляемый класс, в противном случае субтипирование будет работать неправильно. Это называется поздним/динамическим связыванием. Его техническая реализация немного сложна и является основной причиной различия поведений объектов и указателей на объекты в C++ (см. vtables).
▍ Странное поведение
Я считаю, что мы не можем (и не должны) говорить об субтипировании без упоминания поведенческого субтипирования и Барбары Лисков. Основная идея поведенческого субтипирования заключается в том, что субтип должен вести себя схоже с родительским типом.
Барбара Лисков (позже получившая премию Тьюринга за свою работу в сфере языков программирования и в частности ООП) формализовала эту концепцию в 1987 году в виде «строгого поведенческого субтипирования»: субтип должен иметь возможность использования во всех ситуациях, в которых можно использовать его родительский тип.
«Требование от субтипов: пусть φ(x) — свойство, доказуемое относительно объектов x типа T. Тогда φ(y) должно быть истинно для объектов y типа S, где S — субтип T»12.
Это называется принципом подстановки Лисков. Я не буду вдаваться в подробности, но основной смысл в том, что любое предусловие (для типов, данных или состояния) параметров не может быть строже, чем для супертипа, а любое постусловие не может быть слабее, чем у супертипа13. Эта формулировка связана с методологией контрактного программирования, зародившегося примерно в то же время.
▍ Слишком абстрактно
В некоторых случаях нам не важно, что наследование связано с одинаковым кодом, но мы всё равно хотим воспользоваться преимуществами субтипирования — мы можем вообще не использовать реализацию методов супертипа, а значит, полностью от него отказаться. На самом деле, это встречается так часто, что имеет собственное название: виртуальные или абстрактные методы.
Мы даже можем удалить всё состояние из нашего абстрактного супертипа и использовать его только как шаблон для определения методов. Это называется интерфейсом.
Некоторые языки даже сделали ещё один шаг и полностью отделили интерфейсы от классов. Они имеют две разные философии:
- Структурная типизация (как противоположность обычной номинальной типизации) — это когда реализации интерфейсов вообще не объявляются. Можно просто использовать объект как реализацию при условии, что определены необходимые методы. Это статически проверяется во время компиляции. Примерами языков с поддержкой структурной типизации являются Go (и для самих интерфейсов, и для ограничений типов) и C++ (для концептов). Утиная типизация тоже на это похожа, но существование методов проверяется только в среде исполнения. Этот паттерн используют такие языки, как Python и JavaScript. Его недостаток, о котором часто говорят, заключается в том, что сложнее понять, какие классы можно ожидать в конкретной точке программы14.
- У второго паттерна, похоже, пока нет какого-то устоявшегося названия. Смысл заключается в том, чтобы объявлять то, что класс реализует интерфейс, уже после определения класса. Примером языка, в котором это используется, может быть Rust с его трейтами. К сожалению, «трейт» — ужасное название для этой концепции, потому что «трейты» обычно просто ссылаются на примеси15. Я слышал термин «расширяемые трейты» (extension traits) по отношению к «методам расширения» в C#/Kotlin16 17, но он, похоже, тоже используется не очень широко18. Ещё один язык, поддерживающий эту возможность — Haskell (там он называется «классами типов», type class, но Haskell, пожалуй, не является объектно-ориентированным)19.
▍ Прятки
Ещё один термин, который часть употребляют вместе с ООП — это инкапсуляция. На самом деле, у этого термина есть два действующих определения. Первое относится к объединению данных с поведением (= метафора объекта). Второе относится к ограничению доступа к состоянию только самим объектом. Я бы хотел подробнее остановиться на втором, потому что, как мне кажется, многие не понимают его полностью.
«Инкапсуляция — методика минимизации взаимозависимостей между отдельно написанными модулями при помощи задания строгих внешних интерфейсов», — Алан Снайдер, 1986 год20.
Почему же так важно ограничивать доступ к состоянию? На то есть несколько причин. Можно заявить, что это нарушает ограничение Лисков12. Но я считаю, что гораздо практичнее посмотреть на это с точки зрения разработчика, желающего провести рефакторинг кодовой базы. Допустим, мы хотим изменить внутреннюю структуру объекта (например, как в примере со списком, возможно, мы хотим перейти от ArrayList к LinkedList). Но если другие компоненты зависят от внутреннего состояния (в случае ArrayList это может быть внутренний примитивный массив), то его нельзя будет изменить с лёгкостью. Нам нужно будет найти все места вне класса, где есть ссылки на внутреннюю структуру. Проблема становится ещё серьёзнее, когда класс экспортируется и используется модулями, которые, возможно, мы не контролируем.
При обсуждении инкапсуляции часто упоминают «связи (объектов)» и «связности (классов)». «Связь объектов» описывает количество зависящих друг от друга объектов. Высокая степень связи объектов подразумевает, что рассматриваемые объекты сильно зависят друг от друга, и обычно это означает, что они должны быть одним объектом. Если объекты зависят от внутренней структуры друг друга, то они сильно связаны. Связность классов описывает ту же характеристику, но с другой точки зрения. Это мера связности обязанностей класса. В идеале класс должен обозначать одну идею и выполнять только то, что связано с этой идеей. Низкая связность классов обычно означает сильную связь объектов, и наоборот21.
Я уверен, что если вы занимались объектно-ориентированным программированием, то слышали что-то наподобие «не используйте публичные свойства» (свойства в смысле переменных-членов). И это правда, потому что публичные свойства раскрывают внутреннее состояние, что потенциально может привести к сильной связи объектов. Однако, как и в случае с любой догмой, всегда стоит подвергать это сомнению. В данном случае полностью «рекомендация» звучит так: «Не используйте публичные свойства, пользуйтесь вместо них геттерами и сеттерами», что совершенно неверно. С точки зрения инкапсуляции геттеры и сеттеры столь же плохи, как и публичные свойства, потому что они никак не предотвращают связь объектов. Если у вас есть класс без методов (за исключением геттеров и сеттеров), то он не соответствует нашему определению объекта. Для этого использовался термин «запись».
▍ };
Ну ладно, так что же такое ООП? ООП — это когда связанные состояние и поведение объединены в единицы (= блоки). Объектно-ориентированные языки могут иметь и другие свойства: классы, прототипы, инкапсуляцию, субтипирование, наследование и так далее.
Давайте рассмотрим некоторые современные языки (это 15 самых популярных языков из StackOverflow Developer Survey 2023, исключая HTML и тому подобное):
| Язык | Объекты | Создание объектов | Инкапсуляция | Субтипирование |
|---|---|---|---|---|
| JavaScript | ✔️ | Классы/прототипы |
✔️ (с ES2022) | Наследование/утиная типизация |
| Python | ✔️ | Классы | ❌ (не на уровне языка) | Наследование/утиная типизация |
| TypeScript | ✔️ | Классы/прототипы | ✔️ | Наследование/структурная типизация/утиная типизация |
| ShellScript | ❌ | ❌ | ❌ | ❌ |
| Java | ✔️ | Классы | ✔️ | Наследование/номинальная типизация |
| C# | ✔️ | Классы | ✔️ | Наследование/номинальная типизация |
| C++ | ✔️ | Классы + Struct | ✔️ | Наследование/номинальная типизация + структурная типизация (концепты) |
| C | ❌ (нет методов) | Struct | ✔️ (что-то типа незавершённых типов) | ❌ (единое «наследование» при помощи встраивания struct; нет настоящего субтипирования) |
| PHP | ✔️ | Классы | ✔️ | Наследование/утиная типизация |
| PowerShell | ✔️ | Классы | ❌ | Наследование/утиная типизация (не уверен) |
| Go | ✔️ | Struct | ✔️ (на уровне пакетов) | Структурная типизация |
| Rust | ✔️ | Struct | ✔️ | Расширяемые трейты/номинальная типизация |
| Kotlin | ✔️ | Классы | ✔️ | Наследование/номинальная типизация |
| Ruby | ✔️ | Классы | ✔️ (принудительная) | Наследование/утиная типизация |
| Lua | ✔️ | Таблицы (прототипы) | ❌ | Наследование/утиная типизация |
Недостатки
Ну ладно. Теперь, когда у нас есть хорошее понимание того, что же такое ООП и чего можно ожидать от языков, реализующих парадигму ООП, давайте рассмотрим её самую популярную критику. (Большинство из претензий я нагло позаимствовал, спросив у своих друзей, что им не нравится в ООП.)
▍ Но что же ТАКОЕ объекты?
Итак, объекты могут быть чем угодно, так? Как же мне понять, что должно быть объектом? Когда мне следует объединять, а когда разделять?
В конечном итоге, это вопрос лишь практики и опыта. Со временем у вас появится понимание, что должно быть объектом, а что нет. Однако, чтобы с чего-то начать, есть несколько трюков, которые могут вам помочь. Вот, что нам говорит банда четырёх:
«Методологии объектно-ориентированного проектирования способствуют множеству различных подходов. Можно написать формулировку задачи, выделить существительные и глаголы, а затем создать соответствующие классы и операции. Или можно сосредоточиться на взаимодействиях и обязанностях в системе. Или можно смоделировать реальный мир и перенести обнаруженные объекты в архитектуру. Всегда будут разногласия о том, какой подход лучше»4.
▍ Тесты
ДОПОЛНЕНИЕ: мне сообщили, что при проектировании бенчмарков я совершил несколько ошибок. Благодарю NoNaeAbC в Github за указание на то, что я распределяю и очищаю слишком много памяти в тестах ООП и структурного программирования (SP), а также u9vata в Youtube за критику архитектуры моего бенчмарка. Что касается последнего: хотя я и не согласен со всем, что он сказал, определённо справедливо то, что я сделал необоснованные допущения о компиляторной оптимизации. Не знаю, когда у меня будет время на изменение архитектуры бенчмарков, так что пока воспринимайте их с большой долей скепсиса. И заодно скажу, что я нашёл ещё одно объяснение медленности тестов функционального программирования (FP): полоса хранится как замыкания с постепенно усиливающимся вложением, которые должны хранить свои аргументы в куче, а версии ООП и SP могут работать только со стеком.
ООП медленное. Ну, или, по крайней мере, так мне говорили. Обосновывается это тем, что поиск в vtable тратит лишние ресурсы по сравнению с прямыми вызовами функций. Я не знаю, так ли это, поэтому решил проверить.
Тест имеет следующую структуру: я три раза написал одну и ту же программу (машину Тьюринга, проверяющую двоичные палиндромы) при помощи объектно-ориентированного, структурного (с использованием только функций, циклов, кортежей, массивов и тому подобного) и функционального программирования.
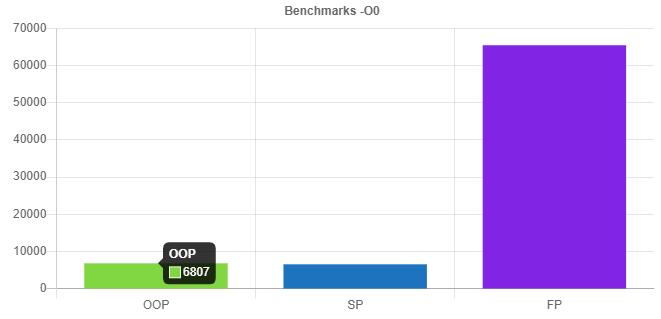
Я реализовал всё на C++, так что условия будут равными (кроме того, в C++ есть функции первого класса/лямбда-выражения для функциональной версии). Используется 100 000 тестовых случаев, замеряется суммарное время. Применён компилятор clang 14.0.3, целевая платформа — Apple Silicon (M1). Я запускал каждый тест с -O0 и -O3.
При реализации ООП я сделал так, чтобы не использовались распределения кучи, потому что переключения контекста, скорее всего, сильно испортят результаты. Однако я использовал наследование (если точнее, шаблонный метод), чтобы сделать поиск в vtable максимально реалистичным.
Структурная версия тоже распределяет всё в стек. Я создал две разные версии. Первая использует кортежи при поиске в таблице переходов, однако я не знал точно внутреннее устройство кортежей и хотел по возможности избежать случайного использования объектов, поэтому написал ещё одну версию, где применяются только функции. Но оказалось, что результаты настолько близки, что почти неразличимы.

Как видно, без использования оптимизаций структурная версия чуть быстрее (примерно на 5%) объектно-ориентированной (хотя стоит отметить, что в разных прогонах значения скакали довольно сильно). При использовании -O3 производительность практически одинакова (разница около 1%), так что предположу, что оптимизатор C++ смог избавиться от того, что влияло на производительность.
Функциональная реализация от этих показателей очень далека. В какой-то степени это может быть вызвано выбранным мной бенчмарком. Машины Тьюринга сохраняют состояние, и это довольно неудобно моделировать функциональным образом. Ещё одна особенность заключается в том, что хотя я пользовался C++14 (который поддерживает вывод возвращаемых типов22), мне пришлось использовать шаблон std::function23 в качестве обёртки для лямбда-выражений (анонимные типы — это настоящее мучение), которые (согласно моим тестам) сильно медленнее, чем нативные лямбда-выражения.
Вероятно, мне стоило провести тщательные статистические тесты, или, по крайней мере, вычислить дисперсию. Но, честно говоря, мне было лениво. Возможно, потом я напишу дополнение с качественным анализом.
Если вы захотите провести собственные тесты, то можете отправить мне результаты. Исходный код выложен на Github (наверно, мне стоит извиниться за ужасный код, C++ — не мой родной язык и я написал его примерно за час).
Без подробной статистики могу сделать вывод, что существует лишь очень небольшая разница в производительности. Добавление новых уровней абстракции (для использования разных структур данных), вероятно, повлияет сильнее.
Однако другие бенчмарки для встроенных систем показали снижение производительности примерно на 10% по сравнению с процедурной реализацией24.
В ещё одной статье, сравнивающей производительность различных аспектов ООП, а также разные шаблоны проектирования, показано, что виртуальные функции (которые я использовал в своей реализации) могут отрицательно сказаться на производительности (около 5%). Шаблонный метод (который я тоже применил) также способен понизить производительность примерно на 3-4% (но это может быть и просто связано с тем, что он использует виртуальные функции)25.
▍ Абстрактная чушь
По какой-то причине ООП приводит к переусложнению всего. Мы без необходимости надстраиваем абстракции поверх абстракций, похоже, только ради создания красивых UML-диаграмм.
Дело в том, как мы пользуемся инструментами, а не в самих инструментах. Подозреваю, что большинство этих проблем вызвано тем, что разработчики хотят предусмотреть всё и создавать обобщённые решения, учитывающие любые возможные расширения в будущем.
Думаю, этого можно избежать, правильно настроив рабочий процесс. В частности, если конечная цель не определена с самого начала, то не следует планировать каждое непредвиденное обстоятельство изначально, а планировать только то, что точно понадобится. В дальнейшем требования могут поменяться, поэтому ваше потрясающее решение с высокой степенью универсальности, над которым вы работали четыре недели, в конечном итоге могут и не использовать, оно окажется пустой тратой времени.
▍ Опасность геттеров и сеттеров
ООП настолько многословно, в нём много бойлерплейт-кода, например, геттеры и сеттеры.
И для меня это больная мозоль. Мы касались этого ранее, но я бы хотел донести максимально чётко: если вам действительно нужны геттеры и сеттеры для каждой отдельной переменной-члена, то, вероятно, вы выбрали неподходящий объект. Я крайне рекомендую переосмыслить свою модель объектов, попытаться снизить их связь. Если это действительно класс-запись без внутреннего поведения, то всё вполне может быть публичным, вряд ли есть смысл в использовании геттеров и сеттеров. Аналогичное можно сказать про свойства в языках наподобие C# и, разумеется, о генераторах кода наподобие печально известного Lombok26.
Единственная реальная причина использовать геттеры и сеттеры вместо публичных членов — это наличие дополнительной логики, например, валидации инвариантов.
Тоже немного по теме: если у вас есть объект-значение без сеттеров, но с большим количеством геттеров, то убедитесь, что случайно не раскрываете изменяемую ссылку на внутреннее состояние. В противном случае у вас ненамеренно получатся сеттеры.
▍ ObjectFactoryFactorySingleton
Я думаю, к этому заголовку подходят две темы. Первая — безумие с наименованиями, распространённое в корпоративной разработке ПО. Это тоже само по себе не является проблемой ООП, хотя и по какой-то причине происходит намного чаще с ООП. Я фанат Кевлина Хенни, он сделал потрясающий доклад о присваивании имён в программировании на DevWeek 2015. Среди прочего он рассказывает о том, как присваивание имён может влиять на моделирование. Рекомендую посмотреть этот доклад.
Вторая тема — это кроличья нора шаблонов проектирования, которые часто применяются слепо, практически без рассуждений о необходимости. В частности, шаблон «Фабрика» вполне имеет допустимые способы применения, но из-за того, что его используют слишком часто, он стал синонимом ненужных абстракций.
Разумеется, есть и другие шаблоны, для применения которых необходима очень весомая причина, по крайней мере, в строго объектно-ориентированном контексте. Например, синглтоны. «Синглтон» — это, по сути, красивое название для глобальной переменной, просто замечательно. Забавное примечание: во фреймворке Spring бины (Bean) по умолчанию получают область видимости Singleton, то есть, если не сказано иное, каждый отдельный бин глобален27.
▍ Мечты о Spring
Ещё в современных «корпоративных» приложениях я заметил то, что они на самом не являются объектно-ориентированными. Сущности, DTO и так далее — это записи, а не объекты. Бины, сервисы, репозитории не хранят состояния и вполне могут быть простыми функциями в модулях.
Мы используем языки, которые заставляют нас думать с точки зрения классов с архитектурами, не требующими объектов — Spring Boot вполне можно было написать на C.
Заключение
Путешествие выдалось захватывающим. Кажется, это пока мой самый длинный пост, возможно, даже слишком.
Ещё мне показался очень интересным доклад Барбары Лисков об абстракциях, но я не знал, куда его вставить, так что просто положу сюда. (Лично мне особенно понравилась претензия к Python за отказ от инкапсуляции.)
Надеюсь, я пролил свет на тему ООП; возможно, вы чему-то научились, или мои бредни хотя бы были немного увлекательными.
Примечания
- 1. Dr. Alan Kay on the Meaning of “Object-Oriented Programming”, Alan Kay & Stefan Ram, 2003
- 2. Concepts and paradigms of object-oriented programming, Peter Wegner, 1990
- 3. Object-Oriented Programming: Themes and Variations, Mark Stefik & Daniel G. Bobrow, 1985
- 4. Design Patterns: Elements of Reusable Object-Oriented Software, Erich Gamma et al., 1994
- 5. Object Oriented Programming, Tim Rentsch, 1982
- 6. Using Classes, Mozilla Web Docs
- 7. ECMAScript 6 and the evolution of JavaScript, Marc-André Leprohon, 2017
- 8. Classes vs Prototypes In Object-Oriented Languages, A. H. Borning, 1986
- 9. FAQ on the Go website
- 10. The Rust Programming Language: Object-Oriented Programming Features of Rust
- 11. Difference Between Structure and Class in C++, GeeksForGeeks
- 12. A behavioral notion of subtyping, Barbara Liskov & Jeannette Wing, 1994
- 13. Making the liskov substitution principle happy and sad, Elisa Baniassad, 2018
- 14. It’s Duck (Typing) Season!, Nevena Milojković, et al., 2017
- 15. Traits: Composable units of behaviour, Nathanael Schärli et al., 2002
- 16. Extension Methods, C# Programming Guide
- 17. Extensions, Kotlin Documentation
- 18. Extension traits in Rust, Karol Kuczmarski
- 19. Type Classes and Overloading, A Gentle Introduction to Haskell
- 20. Encapsulation and Inheritance in Object-Orlented Programming Languages, Alan Snyder, 1986
- 21. Coupling and Cohesion in Object-Oriented Systems, Johann Eder et al., 1994
- 22. New function return type deduction in C++14, all4coders
- 23. std::function, cplusplusreference
- 24. Evaluating Performance and Power of Object-Oriented Vs. Procedural Programming in Embedded Processors, Alexander Chatzigeorgiou & George Stephanides, 2002
- 25. Understanding the Impact of Object Oriented Programming and Design Patterns on Energy Efficiency, Sepideh Maleki et al., 2017
- 26. Project Lombok Website
- 27. Bean Scopes, Spring Documentation
Скидки, итоги розыгрышей и новости о спутнике RUVDS — в нашем Telegram-канале 🚀

