В продолжение моего поста "Начинающим Java программистам" публикую очередную свою шпаргалку, а именно список задач, которые я обычно даю новичкам. Опытным разработчикам они покажутся тривиальными, а только начинающим изучать Java, причём самостоятельно, надеюсь будут в самый раз. Так же если Вы используете какие-то ещё задачи для обучения, то поделитесь ими, пожалуйста.:) Так как мне, иногда, как-то не по себе в ...-цатый раз рассказывать стажёрам одну и ту же задачу — пусть даже они её слышат впервые:)

Игорь Флиста @iflista
User
Заочное обучение в ШАД Яндекса: 570 замечательных часов моей жизни
6 min
 Два года назад на меня сильное впечатление произвела хабрастатья «Стивен Вольфрам проанализировал свою жизнь». К тому времени я уже года два записывал в Google-календаре, что и когда я делал, но к тому моменту я не задумывался, о том, что можно сделать с этой информацией. После прочтения той статьи, я понял: эту информацию можно анализировать! Сейчас я могу посчитать сколько раз мы с друзьями собирались играть в баскетбол за эти годы, сколько часов я провёл в больнице и т. п.
Два года назад на меня сильное впечатление произвела хабрастатья «Стивен Вольфрам проанализировал свою жизнь». К тому времени я уже года два записывал в Google-календаре, что и когда я делал, но к тому моменту я не задумывался, о том, что можно сделать с этой информацией. После прочтения той статьи, я понял: эту информацию можно анализировать! Сейчас я могу посчитать сколько раз мы с друзьями собирались играть в баскетбол за эти годы, сколько часов я провёл в больнице и т. п.На этой неделе я сделал последнюю домашнюю работу в ШАД и решил посчитать сколько времени у меня ушло на обучение, сколько я в среднем тратил в неделю, сколько строчек кода я написал и т. д. Построил несколько графиков и гистограмм, показал их друзьям и понял, что, возможно, такая информация будет интересна кому-либо ещё. Так что если вы хотите узнать сколько страниц отчётов было написано, насколько верна оценка нагрузки в ШАД в 15–20 часов в неделю, а также моё субъективное мнение о курсах в ШАД, то добро пожаловать под хабракат.
Java по-русски. Часть первая: Книги
2 min
Не так давно я проводил опрос «Какие материалы о Java вас интересуют на русском языке?» среди посетителей Хабра. Вторым этапом моего исследования будет обзор существующих русско-язычных ресурсов.
За 2009 на Ozon.ru можно найти 8 книг по Java (всего за последние 3 года их вышло 22 — примерно по 7 в год, на books.ru набор примерно такой же, так что наша выборка довольно репрезентативна). Посмотрим, что это за книги?
Книги
За 2009 на Ozon.ru можно найти 8 книг по Java (всего за последние 3 года их вышло 22 — примерно по 7 в год, на books.ru набор примерно такой же, так что наша выборка довольно репрезентативна). Посмотрим, что это за книги?
Книги, которые должен прочитать Java программист: от новичка до профессионала
4 min
Translation
Книги, которые должен прочитать Java программист: от новичка до профессионала
[Примечание переводчика: термины градации «профессионализма» оставлены англоязычные в связи с трудностью их адекватного перевода на русский и несовпадением с привычными Junior-Middle-Senior-Lead. Перевод достаточно вольный — если знаний языка хватает, то лучше читать оригинал, как и советует автор. Оба языка для меня не родные, так что про ошибки сообщайте в личку — исправим. Здесь и далее в квадратных скобках примечания переводчика]
Я заметил, что в последние месяцы я рекомендую одни и те же книги как новичкам, так и опытным разработчикам. Поэтому я решил составить список этих книг. Они составили мне неплохую компанию в процессе моего роста от новичка до сегодняшнего уровня (какой-бы он не был :) )
Сколько английских слов вы знаете?
5 min
Оценка количества выученных и запомненных слов иностранного языка прежде всего интересна для понимания того, насколько далеко человек продвинулся в «пассивном» восприятии информации: тексты, речь, фильмы, и т.д. Предлагаю ознакомиться с несколькими способами, которые я применял, найденные в сети и «самопальные». Внизу — парочка тестов для оценки vocabulary, методика для поиска важных слов, которые пока не зацепились в мозгу, несколько рассуждений и немного ссылок.
Поговорим о словарном запасе иностранного языка
4 min
Сколько слов в английском языке? Oxford English Dictionary содержит около 500 000 словарных статей, не учитывая специфические научные слова и выражения (которых насчитывается еще порядка 500 000). А как вы думаете, какой средний словарный запас иностранного языка дает вам средняя школа за время обучения? Правильный ответ – около 2500 слов. Мало ли этого набора? Тут уже надо исходить из ваших целей. Для общения с иностранцами на деловые темы – однозначно мало. Для чтения несложных текстов в интернете – более чем достаточно. Если быть точнее:
400–500 слов – активный словарный запас для владения языком на базовом (пороговом) уровне.
800–1000 слов – активный словарный запас для того, чтобы объясниться; или пассивный словарный запас для чтения на базовом уровне.
1500–2000 слов – активный словарный запас, которого вполне хватит для того, чтобы обеспечить повседневное общение в течение всего дня: или пассивный словарный запас, достаточный для уверенного чтения.
3000–4000 слов – в общем, достаточно для практически свободного чтения газет или литературы по специальности.
Около 8000 слов – обеспечивают полноценное общение для среднего европейца. Практически не нужно знать больше слов для того, чтобы свободно общаться как устно, так и письменно, а также читать литературу любого рода.
К этим данным пришел известный шведский полиглот Эрик Гуннемарк, основатель Международной ассоциации `Amici Linguarum` (`Друзья языков`). Более того, он составил набор минимального количества слов и выражений, которые необходимо знать, для порогового уровня владения языком, назвав их Минилекс и Минифраз.
Интересно, а какой средний уровень словарного запаса у рядового пользователя сети и у вас лично? Об этом расскажу дальше.

400–500 слов – активный словарный запас для владения языком на базовом (пороговом) уровне.
800–1000 слов – активный словарный запас для того, чтобы объясниться; или пассивный словарный запас для чтения на базовом уровне.
1500–2000 слов – активный словарный запас, которого вполне хватит для того, чтобы обеспечить повседневное общение в течение всего дня: или пассивный словарный запас, достаточный для уверенного чтения.
3000–4000 слов – в общем, достаточно для практически свободного чтения газет или литературы по специальности.
Около 8000 слов – обеспечивают полноценное общение для среднего европейца. Практически не нужно знать больше слов для того, чтобы свободно общаться как устно, так и письменно, а также читать литературу любого рода.
К этим данным пришел известный шведский полиглот Эрик Гуннемарк, основатель Международной ассоциации `Amici Linguarum` (`Друзья языков`). Более того, он составил набор минимального количества слов и выражений, которые необходимо знать, для порогового уровня владения языком, назвав их Минилекс и Минифраз.
Интересно, а какой средний уровень словарного запаса у рядового пользователя сети и у вас лично? Об этом расскажу дальше.
Heartbleed и заблуждения о Open Source
5 min
Translation
Печально известный баг Heartbleed, найденный в библиотеке OpenSSL, потряс индустрию программного обеспечения. Он также показал некоторые заблуждения о мире открытого софта.
Закон Линуса утверждает, что с достаточным количеством пользователей и достаточным количеством разработчиков, проверяющих код, ошибки в открытом коде будут найдены и постепенно исправлены, результатом чего станет более правильный и безопасный код в сравнении с закрытым/проприетарным программным обеспечением.
Книга «Факты и заблуждения профессионального программирования» ссылается на это как на восьмое заблуждение. В книге цитируется исследование, утверждающее, что частота, с которой находятся новые баги, не увеличивается линейно с количеством проверяющих. Я считаю, что факт того, что люди плохо справляются с поиском багов в программном обеспечении, должен быть очевиден любому разработчику. В то время, как очевидные баги типа синтаксических проблем или использования антипаттернов можно легко выловить на этапе проверки кода, многие другие баги могут быть раскрыты только при использовании программы.
1) Закон Линуса
«При достаточном количестве глаз баги выплывают на поверхность», — Эрик Рэймонд.
Закон Линуса утверждает, что с достаточным количеством пользователей и достаточным количеством разработчиков, проверяющих код, ошибки в открытом коде будут найдены и постепенно исправлены, результатом чего станет более правильный и безопасный код в сравнении с закрытым/проприетарным программным обеспечением.
Книга «Факты и заблуждения профессионального программирования» ссылается на это как на восьмое заблуждение. В книге цитируется исследование, утверждающее, что частота, с которой находятся новые баги, не увеличивается линейно с количеством проверяющих. Я считаю, что факт того, что люди плохо справляются с поиском багов в программном обеспечении, должен быть очевиден любому разработчику. В то время, как очевидные баги типа синтаксических проблем или использования антипаттернов можно легко выловить на этапе проверки кода, многие другие баги могут быть раскрыты только при использовании программы.
Джон Резиг: Пишите код каждый день
5 min
Translation
Прошлой осенью работа над моими побочными проектами зашла в тупик: я практически не продвигался вперёд и у меня никак не получалось делать больше, не принося в жертву свою основную работу в Khan Academy.
В моей организации работы обнаружилось несколько серьёзных проблем. В основном я работал по выходным и иногда по вечерам. Как оказалось, это не самая лучшая для меня стратегия. Необходимость сделать за выходные как можно больше и лучше сильно давила на меня, а если мне не удавалось доделать задуманное, это ощущалось как провал. Проблему усугубляло и то, что не было никакой гарантии, что очередные выходные будут свободны, и даже если так — не факт, что я захочу кодить с утра до вечера все эти два дня — надо ведь иногда как-то развлечься или просто расслабиться.
Кроме того, недельный перерыв — это слишком много, очень легко забыть, над чем ты работал и на чём остановился, даже если делать заметки. А уж если в выходные поработать не удавалось — то перерыв растягивался на две недели. Такие многонедельные переключения контекста могут быть смертельными — многие мои проекты погибли, не родившись, от такого недостатка внимания.
Услышав о невероятном эксперименте Дженнифер Девальт, которая решила изучить программирование, создав 180 сайтов за 180 дней, я отважился испробовать сходную тактику: работать над побочными проектами каждый день.

Иллюстрация Стивена Резига
В моей организации работы обнаружилось несколько серьёзных проблем. В основном я работал по выходным и иногда по вечерам. Как оказалось, это не самая лучшая для меня стратегия. Необходимость сделать за выходные как можно больше и лучше сильно давила на меня, а если мне не удавалось доделать задуманное, это ощущалось как провал. Проблему усугубляло и то, что не было никакой гарантии, что очередные выходные будут свободны, и даже если так — не факт, что я захочу кодить с утра до вечера все эти два дня — надо ведь иногда как-то развлечься или просто расслабиться.
Кроме того, недельный перерыв — это слишком много, очень легко забыть, над чем ты работал и на чём остановился, даже если делать заметки. А уж если в выходные поработать не удавалось — то перерыв растягивался на две недели. Такие многонедельные переключения контекста могут быть смертельными — многие мои проекты погибли, не родившись, от такого недостатка внимания.
Услышав о невероятном эксперименте Дженнифер Девальт, которая решила изучить программирование, создав 180 сайтов за 180 дней, я отважился испробовать сходную тактику: работать над побочными проектами каждый день.
Иллюстрация Стивена Резига
Необычный способ изучения иностранного языка
1 min
На Хабре уже много раз обсуждались способы изучения английского языка, в этом топике представлен еще один. Некий словацкий веб-разработчик Vojtech Rinik предлагает запоминать новые слова книги (или главы) до ее прочтения. При этом способе не придется прерывать чтение поиском перевода для неизвестных слов, а значит можно в полной мере насладиться книгой в оригинале.
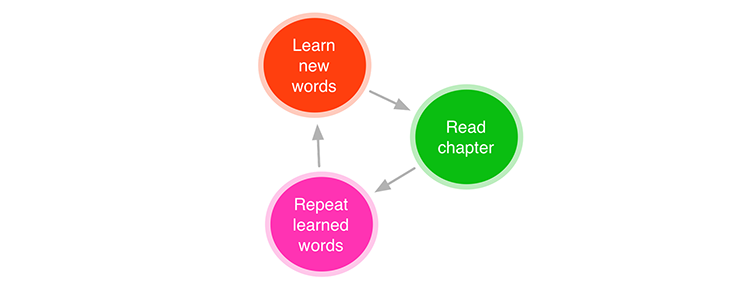
Также Войцех утверждает, что так слова учить намного проще, ведь сначала их нужно запомнить, а потом «распознать» в тексте.
Также Войцех утверждает, что так слова учить намного проще, ведь сначала их нужно запомнить, а потом «распознать» в тексте.
Google Chrome — убираем рутину с помощью кастомного поиска
1 min
Disclaimer: речь — о давно существующей функции, но, судя по комментам на Хабре, недооцененной, поэтому решил все-таки написать.
Google Chrome позволяет очень сильно ускорить рутинные задачи, связанные с различным поиском. используя адресную строку.
Google Chrome позволяет очень сильно ускорить рутинные задачи, связанные с различным поиском. используя адресную строку.
Например:
- "
ru nightingale" показывает русский перевод «nightingale» в Google Translate - "
ан соловей" или "fy соловей" переводит «соловей» на английский там же - "
j click" открывает документацию по jQuery.click - "
m Лесная 6" открывает адрес адрес «Лесная 6» на Яндекс.Картах
DevDocs: вся документация разработчика в одном месте, с быстрым и удобным интерфейсом
1 min
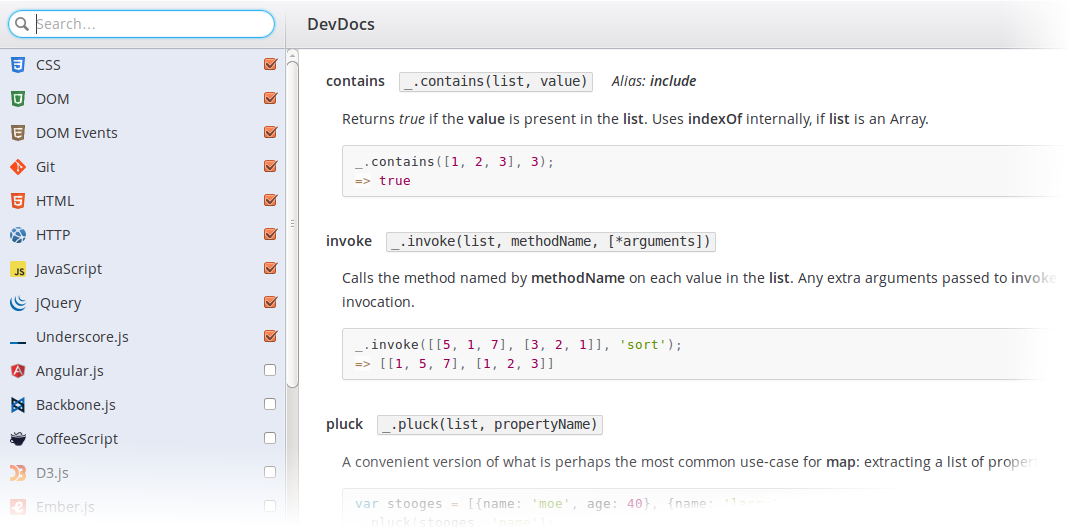
Сайт devdocs.io — проект французского программиста Тибо Курубля. Здесь собрана и упорядочена документация по наиболее популярным веб-технологиям, фреймворкам и API, и многим другим средствам разработки. DOM, HTML, JavaScript, jQuery, Node.js, PHP, Ruby, Python, Git, Angular, Backbone, CoffeScript, Less, Sass, Redis и много чего ещё… Всё оформлено в едином стиле, по всей базе документации работает поиск, в том числе нечёткий. Есть возможность выбрать только необходимые технологии, по которым надо искать. Вообще, интерфейс DevDocs радует — ничего лишнего, всё очень понятно и функционально, доступно множество клавиатурных сокращений.
Обзор материалов для изучения Drupal
2 min
 «Одна голова хорошо, а много лучше» — подумала я и решила спросить у Drupal-разработчиков, откуда они черпали свои знания.
«Одна голова хорошо, а много лучше» — подумала я и решила спросить у Drupal-разработчиков, откуда они черпали свои знания.Так появился проект «3 ссылки, которые сделали вас друпалером» на базе Drupal-сообщества в Санкт-Петербурге: опытные и начинающие друпалеры делятся материалами, которые помогли лично им в изучении этой замечательной CMS.
В этом посте мы собрали ссылки на лучшие ресурсы для изучения Drupal.
Алгоритмы и структуры данных поиска. Лекции и курсы от Яндекса
4 min
Tutorial
Сегодня мы завершаем новогоднюю серию постов, посвященных лекциям Школы анализа данных. Последний по порядку, но никак не по важности курс — «Алгоритмы и структуры данных поиска».
В этом курсе рассматриваются базовые алгоритмы и структуры данных, включая хешировани, сложность и модели вычислений, деревья поиска, B-деревья, задачи геометрического поиска, динамическую связность в графах и другое.
Мы учли то, о чём нас просили в комментариях к прошлым курсам — теперь при желании можно не только смотреть/скачивать лекции по отдельности, но и загрузить всё разом в виде открытой папки на Яндекс.Диске. Кстати — в предыдущих постах тоже появились такие же апдейты (вот ссылки для удобства: «машинное обучение», «дискретный анализ и теория вероятностей», «параллельные и распределённые вычисления»).
Лекции читает Максим Александрович Бабенко, заместитель директора отделения computer science, ассистент кафедры математической логики и теории алгоритмов механико-математического факультета МГУ им. М. В. Ломоносова, кандидат физико-математических наук.
В этом курсе рассматриваются базовые алгоритмы и структуры данных, включая хешировани, сложность и модели вычислений, деревья поиска, B-деревья, задачи геометрического поиска, динамическую связность в графах и другое.
Мы учли то, о чём нас просили в комментариях к прошлым курсам — теперь при желании можно не только смотреть/скачивать лекции по отдельности, но и загрузить всё разом в виде открытой папки на Яндекс.Диске. Кстати — в предыдущих постах тоже появились такие же апдейты (вот ссылки для удобства: «машинное обучение», «дискретный анализ и теория вероятностей», «параллельные и распределённые вычисления»).
Лекции читает Максим Александрович Бабенко, заместитель директора отделения computer science, ассистент кафедры математической логики и теории алгоритмов механико-математического факультета МГУ им. М. В. Ломоносова, кандидат физико-математических наук.
Machine Learning. Курс от Яндекса для тех, кто хочет провести новогодние каникулы с пользой
8 min
Tutorial
Новогодние каникулы – хорошее время не только для отдыха, но и для самообразования. Можно отвлечься от повседневных задач и посвятить несколько дней тому, чтобы научиться чему-нибудь новому, что будет помогать вам весь год (а может и не один). Поэтому мы решили в эти выходные опубликовать серию постов с лекциями курсов первого семестра Школы анализа данных.
Сегодня — о самом важном. Современный анализ данных без него представить невозможно. В рамках курса рассматриваются основные задачи обучения по прецедентам: классификация, кластеризация, регрессия, понижение размерности. Изучаются методы их решения, как классические, так и новые, созданные за последние 10–15 лет. Упор делается на глубокое понимание математических основ, взаимосвязей, достоинств и ограничений рассматриваемых методов. Отдельные теоремы приводятся с доказательствами.
Читает курс лекций Константин Вячеславович Воронцов, старший научный сотрудник Вычислительного центра РАН. Заместитель директора по науке ЗАО «Форексис». Заместитель заведующего кафедрой «Интеллектуальные системы» ФУПМ МФТИ. Доцент кафедры «Математические методы прогнозирования» ВМиК МГУ. Эксперт компании «Яндекс». Доктор физико-математических наук.
Сегодня — о самом важном. Современный анализ данных без него представить невозможно. В рамках курса рассматриваются основные задачи обучения по прецедентам: классификация, кластеризация, регрессия, понижение размерности. Изучаются методы их решения, как классические, так и новые, созданные за последние 10–15 лет. Упор делается на глубокое понимание математических основ, взаимосвязей, достоинств и ограничений рассматриваемых методов. Отдельные теоремы приводятся с доказательствами.
Читает курс лекций Константин Вячеславович Воронцов, старший научный сотрудник Вычислительного центра РАН. Заместитель директора по науке ЗАО «Форексис». Заместитель заведующего кафедрой «Интеллектуальные системы» ФУПМ МФТИ. Доцент кафедры «Математические методы прогнозирования» ВМиК МГУ. Эксперт компании «Яндекс». Доктор физико-математических наук.
Лекции от Яндекса для тех, кто хочет провести каникулы с пользой. Дискретный анализ и теория вероятностей
3 min
Tutorial
Для тех, кому одного курса на праздники мало и кто хочет больше, продолжаем нашу серию курсов от Школы анализа данных Яндекса. Сегодня подошла очередь курса «Дискретный анализ и теория вероятностей» – даже более фундаментального, чем предыдущий. Но без него нельзя представить ещё большую часть современной обработки данных.
В рамках курса рассматриваются основные понятия и методы комбинаторного, дискретного и асимптотического анализа, теории вероятностей, статистики и на примере решения классических задач демонстрируется их применение.

Читает курс Андрей Райгородский. Доктор физико-математических наук. Профессор кафедры математической статистики и случайных процессов механико-математического факультета МГУ им. М. В. Ломоносова. Заведующий кафедрой Дискретной математики ФИВТ МФТИ. Профессор и научный руководитель бакалавриата кафедры «Анализ данных» факультета инноваций и высоких технологий МФТИ. Руководитель отдела теоретических и прикладных исследований компании «Яндекс». (Ещё больше можно узнать в статье о нём на Википедии).
В рамках курса рассматриваются основные понятия и методы комбинаторного, дискретного и асимптотического анализа, теории вероятностей, статистики и на примере решения классических задач демонстрируется их применение.
Читает курс Андрей Райгородский. Доктор физико-математических наук. Профессор кафедры математической статистики и случайных процессов механико-математического факультета МГУ им. М. В. Ломоносова. Заведующий кафедрой Дискретной математики ФИВТ МФТИ. Профессор и научный руководитель бакалавриата кафедры «Анализ данных» факультета инноваций и высоких технологий МФТИ. Руководитель отдела теоретических и прикладных исследований компании «Яндекс». (Ещё больше можно узнать в статье о нём на Википедии).
Параллельные и распределенные вычисления. Лекции от Яндекса для тех, кто хочет провести праздники с пользой
3 min
Tutorial
Праздничная неделя подходит к концу, но мы продолжаем публиковать лекции от Школы анализа данных Яндекса для тех, кто хочет провести время с пользой. Сегодня очередь курса, важность которого в наше время сложно переоценить – «Параллельные и распределенные вычисления».
Что внутри: знакомство с параллельными вычислениями и распределёнными системами обработки и хранения данных, а также выработка навыков практического использования соответствующих технологий. Курс состоит из четырех основных блоков: concurrence, параллельные вычисления, параллельная обработка больших массивов данных и распределенные вычисления.
Лекции читает Олег Викторович Сухорослов, старший научный сотрудник Центра грид-технологий и распределенных вычислений ИСА РАН. Доцент кафедры распределенных вычислений ФИВТ МФТИ. Кандидат технических наук.
Что внутри: знакомство с параллельными вычислениями и распределёнными системами обработки и хранения данных, а также выработка навыков практического использования соответствующих технологий. Курс состоит из четырех основных блоков: concurrence, параллельные вычисления, параллельная обработка больших массивов данных и распределенные вычисления.
Лекции читает Олег Викторович Сухорослов, старший научный сотрудник Центра грид-технологий и распределенных вычислений ИСА РАН. Доцент кафедры распределенных вычислений ФИВТ МФТИ. Кандидат технических наук.
Настройка IDEA для чистокодеров
4 min
Я люблю две вещи: Intellij IDEA и чистый код (Clean Code).
IDEA создана для чистого кода. Многие настройки по умолчанию уже стимулируют вас писать как надо.

Но она всё ещё не идеальна.
Когда я устанавливаю новую копию IDEA, я пробегаю по настройкам и выставляю свои любимые галочки.
Хочу ими с вами поделиться в надежде, что когда-нибудь и они станут стандартом.
IDEA создана для чистого кода. Многие настройки по умолчанию уже стимулируют вас писать как надо.
Но она всё ещё не идеальна.
Когда я устанавливаю новую копию IDEA, я пробегаю по настройкам и выставляю свои любимые галочки.
Хочу ими с вами поделиться в надежде, что когда-нибудь и они станут стандартом.
Python на Хабре
7 min
Некоторое время назад, в силу определенных причин, мне пришла в голову мысль о том, чтобы начать изучать какой-нибудь новый язык программирования. В качестве альтернатив для этого начинания я определил два языка: Java и Python. После продолжительного метания между ними и сопутствующих нытья и долбежки головой о стену (у меня с новыми языками всегда так — сомнения, раздумья, проблема выбора и т.д.), я все-таки остановился на Python. Окей, выбор сделан. Что дальше? А дальше я стал искать материал для изучения…