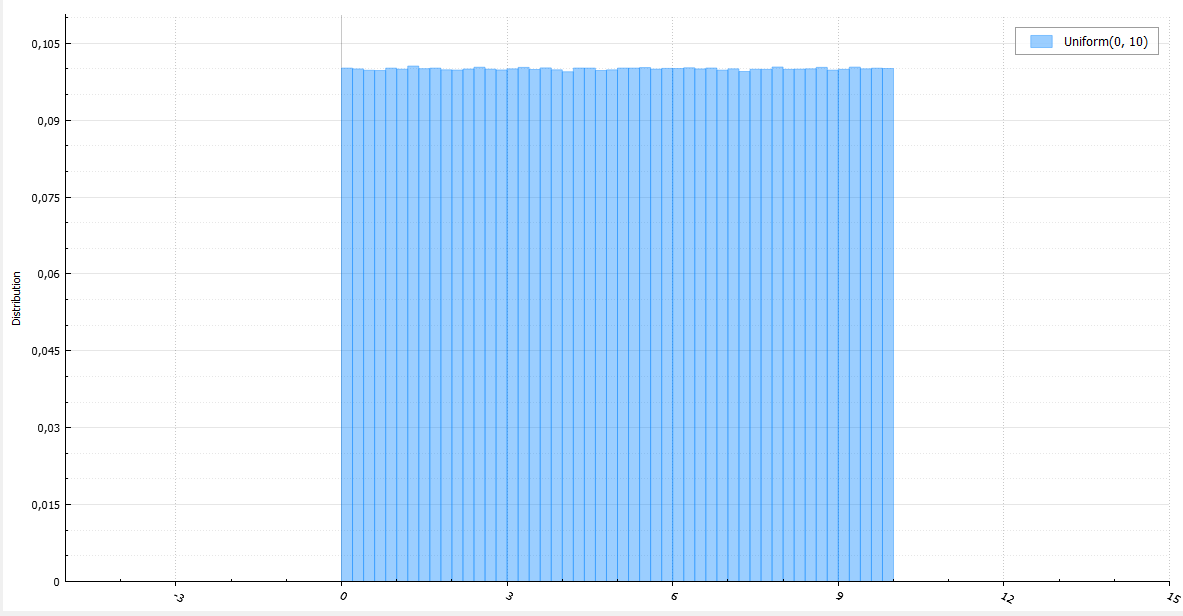
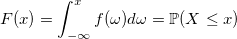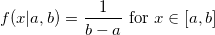Рассказывая о вероятностном программировании и Байесовской статистике, я обычно не уделяю особого внимания тому, как, на самом деле, выполняется вероятностный вывод, рассматривая его как некий «чёрный ящик». Вся прелесть вероятностного программирования заключается в том, что, на самом деле, для того, чтобы строить модели, не обязательно понимать, как именно делается вывод. Но это знание, безусловно, весьма полезно.

Как-то раз я рассказывал о новой Байесовской модели человеку, который не особенно разбирался в предмете, но очень хотел всё понять. Он-то и спросил меня о том, чего я обычно не касаюсь. «Томас, — сказал он, — а как, на самом деле, выполняется вероятностный вывод? Как получаются эти таинственные сэмплы из апостериорной вероятности?».
Как-то раз я рассказывал о новой Байесовской модели человеку, который не особенно разбирался в предмете, но очень хотел всё понять. Он-то и спросил меня о том, чего я обычно не касаюсь. «Томас, — сказал он, — а как, на самом деле, выполняется вероятностный вывод? Как получаются эти таинственные сэмплы из апостериорной вероятности?».
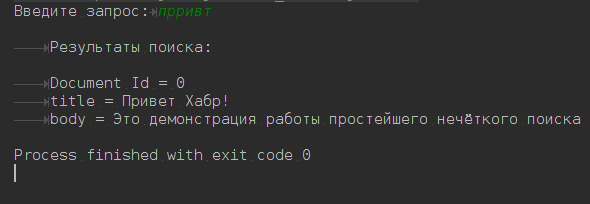 Пост расcчитан на начинающих, на людей незнакомых с технологией Apache Lucene. В нем нет материала о том, как устроен Apache Lucene внутри, какие алгоритмы, структуры данных и методы использовались для создания фреймворка. Пост является обучающим материалом-тизером, написанным для того, чтобы показать, как организовать простейший нечёткий поиск по тексту.
Пост расcчитан на начинающих, на людей незнакомых с технологией Apache Lucene. В нем нет материала о том, как устроен Apache Lucene внутри, какие алгоритмы, структуры данных и методы использовались для создания фреймворка. Пост является обучающим материалом-тизером, написанным для того, чтобы показать, как организовать простейший нечёткий поиск по тексту.