Я думаю, ни для ни кого не секрет, что задачи, которые включают в себя отображение чего-либо в виде сетки (датагрида) или таблицы встречаются очень часто. При этом, если данных очень много, то отображение результатов (в HTML) становится весьма нетривиальной задачей, которая обычно решается разбиением на страницы.
Давайте посмотрим, какие ещё существуют способы показать пользователю большую кучу данных, причём желательно с фильтрацией результатов и поиском, да ещё и чтобы это не слишком тормозило :).
Как правило, если отображать результат в виде HTML-таблицы, то мы упираемся в производительность отображения — рендерится сразу весь результат. Как показывает практика, в Mozilla Firefox и Internet Explorer время, которое тратится на начальный рендеринг большой таблицы, очень велико, и эту проблему хотелось бы как-нибудь решить.
Обычно эту проблему обходят разбиением на страницы и рендерингом лишь малой части таблицы за раз, но при этом пользователь должен переключать страницы вручную, что не совсем удобно. Если вы используете разбиение на страницы, то, вероятно, скорость выборки данных намного превышает скорость её рендеринга, и именно этот факт используется при создании гридов.
В случае, если у нас высота строк, которые мы хотим показывать, фиксирована, то существует множество готовых решений, например SlickGrid, и все они используют очень простую идею, что можно заранее просчитать высоту получившейся таблицы и отрисовывать строки по мере надобности, когда юзверь проскроллит в соответствующую область.
Подобные гриды существуют практически во всех GUI-библиотеках и фреймворках, например в Cocoa, WPF, Swing и т.д. В некоторых реализациях разрешен скролл только построчно (большинство решений под Windows), в других можно проскроллить в середину строки (Cocoa)
Как бы то ни было, существующие решения вполне неплохо справляются с этой задачей.
Давайте теперь рассмотрим более интересный вариант — допустим, что высота строк может быть переменной, и мы можем узнать высоту каждой строки только после того, как её отрендерим. В некоторых случаях высота нам может быть известна и без рендеринга, но в любом случае важен факт, что высота ячеек может меняться. Чтобы жизнь малиной не казалась, также поставим условие, что высоту запрещено кэшировать, поскольку мы можем менять и ширину столбцов в таблице, что вкупе с word wrap означает переменную высоту :).
Тут есть 2 подхода, один из которых используется в Numbers.app из iWork, а другой — в OpenOffice.org Calc и Microsoft Excel. Давайте рассмотрим оба и проанализируем достоинства и недостатки.
При полном рендеринге таблицы мы делаем 3 вещи:
1. Рендерим таблицу целиком, определяем её высоту и рисуем юзверю настоящий скролл
2. Всё время пересчитываем высоту редактируемой строки и обновляем состояние скролла
3. Если изменяется ширина столбца (столбцов), пересчитываем высоту всех строк и обновляем состояние скролла
Такой путь избрал для себя Numbers.app и этот же путь используется при отрисовке обычной HTML таблицы в браузерах (с некоторыми дополнениями, поскольку браузеры ещё и пытаются вписать таблицу в ширину контейнера).
Чем этот подход плох, я думаю, можно легко понять, попробовав открыть довольно большую таблицу (скажем, 10 000 записей с 10 колонками) в браузере или в Numbers.app. Всё загружается и работает ужасно медленно и намертво вешает приложение при работе с содержимым, а также при загрузке таблицы.
Подход хорош тем, что скроллинг по содержимому может быть произведен очень быстро (поскольку всё содержимое было уже отрендерено) и плавно, и высота скролла, которая показывается пользователю, соответствует настоящей высоте отображаемого содержимого.
Как вы могли уже догадаться, есть и другой путь:
Идея заключается в том, что, в случае, если данных в таблице много, пользователь вряд ли заметит тот факт, что высота скролла немного не соответствует сумме высот всех ячеек. Что это значит, и как мы можем это использовать? А очень просто:
Мы не будем вообще ничего рендерить, чтобы узнать высоту скролла — мы её посчитаем, также как и в случае с фиксированной высотой строк, по такой вот простой формуле:
Где SCROLL_HEIGHT — это высота скролла (т.е. высота «содержимого», которое мы прокручиваем с помощью скролла), N — количество строк, ROW_HEIGHT — высота одной строки (например 30px)
Возникает закономерный вопрос — а как же понять, что нам рисовать при заданном значении положения скролла (SCROLL_TOP), ведь оно не соответствует настоящей высоте содержимого? Ответ следует из использованной нами формулы для расчета высоты:
 Где [...] означает целую часть от числа, CURRENT_POSITION — индекс первой видимой на данный момент строки, если нумерация идет с нуля
Где [...] означает целую часть от числа, CURRENT_POSITION — индекс первой видимой на данный момент строки, если нумерация идет с нуля
Что нам делать с этим числом :)? Надо нарисовать все видимые строки, начиная с CURRENT_POSITION. То есть, рисуем построчно все строки, начиная с CURRENT_POSITION и до тех пор, пока мы не выйдем за границы видимости ячеек.
Такой способ скролла соответствует построчному скроллу, то есть, мы не сможем проскроллить в середину строки, потому что мы рисуем всегда начиная с какой-то определенной строки, а не с середины. Это будет означать, что если высота строки превышает высоту области, в которой мы рисуем, то мы увидим лишь часть строки без возможности увидеть остальное содержимое! При попытке скролла в таком случае мы сразу же попадем на следующую строку, а предыдущая ячейка полностью скроется из области видимости. Можете проверить это поведение, скажем, в Microsoft Excel, если не верите :).
После того, как пользователь отпустил скролл, можно его выровнять, согласно первой формуле:
На самом деле, определение текущего номера строки можно проводить по-разному, это лишь один из способов, который не приводит к излишнему «дерганию» скролла.
В Microsoft Excel и в OpenOffice.org Calc совершенно такой же механизм рендеринга применяется не только для строк, но и для столбцов — в этом случае рендеринг идет не построчно, а по более сложному алгоритму, в детали которого я не вдавался
Эти механизмы рендеринга я использовал сам в нескольких проектах, в том числе и в своём файловом менеджере, сайт которого сейчас отключен за неуплату :). В любом случае, если кто-то захочет реализовать приведенный выше алгоритм самостоятельно, вот несколько советов из практики:
1. Самый простой способ нарисовать грид с виртуальным скроллом — это сделать абсолютно позиционированный <div>, который будет показываться поверх какого-либо контейнера, положение которого можно легко определить с помощью метода offset() в jQuery
2. Самих <div>'ов можно сделать 2 — один с содержимым, другой исключительно со скроллом, чтобы браузер не пытался скроллить <div> с содержимым самостоятельно, иначе это приводит к неприятным эффектам при перерисовке. Также можно попробовать использовать position: fixed, но оно странно работает в IE 7
3. Положение скролла лучше всего вообще не выравнивать, ибо браузеры не дают особого контроля за скроллом
4. Максимальная высота элемента в IE 7 составляет порядка 1 млн. пикселей, поэтому, если брать 30px за виртуальную высоту строки, то получится ограничение порядка 30 000 строк. Чтобы с этим бороться, можно уменьшать виртуальную высоту строки с увеличением количества записей, если браузер — IE
5. Чтобы при прокрутке колёсиком мыши строки прокручивались, можно обрабатывать событие DOMMouseScroll в браузерах, основанных на Gecko, и mousewheel во всех остальных
6. Если вы сделаете более умную перерисовку, чем перерисовку полностью видимой области (т.е., например, динамическое удаление и добавление новых строк при скролле на небольшое количество строк), расскажите пожалуйста мне о результатах :)
Ну и если вы всё же будете реализовывать свой grid, посмотрите документацию к API грида, скажем, в Cocoa — это поможет вам лучше понять, как сделать хорошо масштабируемое решение.
Своих решений я выкладывать не хочу, всё оно писалось в спешке и под конкретные задачи, так что вряд ли кому-то из вас сгодится. Спасибо, что дочитали до конца :))
Давайте посмотрим, какие ещё существуют способы показать пользователю большую кучу данных, причём желательно с фильтрацией результатов и поиском, да ещё и чтобы это не слишком тормозило :).
Тормозит обычно «view», а не «model»
Как правило, если отображать результат в виде HTML-таблицы, то мы упираемся в производительность отображения — рендерится сразу весь результат. Как показывает практика, в Mozilla Firefox и Internet Explorer время, которое тратится на начальный рендеринг большой таблицы, очень велико, и эту проблему хотелось бы как-нибудь решить.
Обычно эту проблему обходят разбиением на страницы и рендерингом лишь малой части таблицы за раз, но при этом пользователь должен переключать страницы вручную, что не совсем удобно. Если вы используете разбиение на страницы, то, вероятно, скорость выборки данных намного превышает скорость её рендеринга, и именно этот факт используется при создании гридов.
Самый распространненый случай — фиксированная высота строк
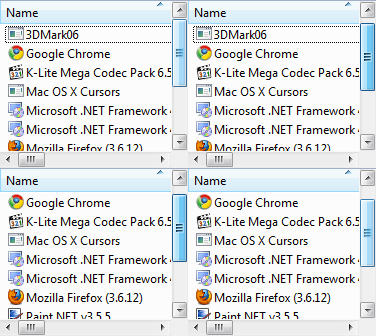
В случае, если у нас высота строк, которые мы хотим показывать, фиксирована, то существует множество готовых решений, например SlickGrid, и все они используют очень простую идею, что можно заранее просчитать высоту получившейся таблицы и отрисовывать строки по мере надобности, когда юзверь проскроллит в соответствующую область.
Подобные гриды существуют практически во всех GUI-библиотеках и фреймворках, например в Cocoa, WPF, Swing и т.д. В некоторых реализациях разрешен скролл только построчно (большинство решений под Windows), в других можно проскроллить в середину строки (Cocoa)
 |
 |
Как бы то ни было, существующие решения вполне неплохо справляются с этой задачей.
Менее типичный и более сложный случай — переменная высота строк
Давайте теперь рассмотрим более интересный вариант — допустим, что высота строк может быть переменной, и мы можем узнать высоту каждой строки только после того, как её отрендерим. В некоторых случаях высота нам может быть известна и без рендеринга, но в любом случае важен факт, что высота ячеек может меняться. Чтобы жизнь малиной не казалась, также поставим условие, что высоту запрещено кэшировать, поскольку мы можем менять и ширину столбцов в таблице, что вкупе с word wrap означает переменную высоту :).
Тут есть 2 подхода, один из которых используется в Numbers.app из iWork, а другой — в OpenOffice.org Calc и Microsoft Excel. Давайте рассмотрим оба и проанализируем достоинства и недостатки.
Простой способ. Полный рендеринг таблицы
При полном рендеринге таблицы мы делаем 3 вещи:
1. Рендерим таблицу целиком, определяем её высоту и рисуем юзверю настоящий скролл
2. Всё время пересчитываем высоту редактируемой строки и обновляем состояние скролла
3. Если изменяется ширина столбца (столбцов), пересчитываем высоту всех строк и обновляем состояние скролла
Такой путь избрал для себя Numbers.app и этот же путь используется при отрисовке обычной HTML таблицы в браузерах (с некоторыми дополнениями, поскольку браузеры ещё и пытаются вписать таблицу в ширину контейнера).
Чем этот подход плох, я думаю, можно легко понять, попробовав открыть довольно большую таблицу (скажем, 10 000 записей с 10 колонками) в браузере или в Numbers.app. Всё загружается и работает ужасно медленно и намертво вешает приложение при работе с содержимым, а также при загрузке таблицы.
Подход хорош тем, что скроллинг по содержимому может быть произведен очень быстро (поскольку всё содержимое было уже отрендерено) и плавно, и высота скролла, которая показывается пользователю, соответствует настоящей высоте отображаемого содержимого.
Как вы могли уже догадаться, есть и другой путь:
Хитрый способ. Рендеринг видимой части с фальшивым скроллом
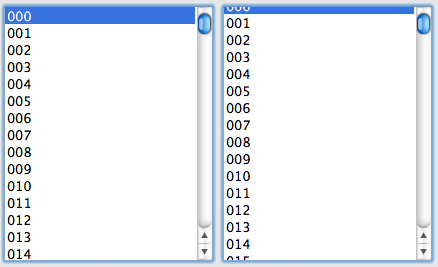
Идея заключается в том, что, в случае, если данных в таблице много, пользователь вряд ли заметит тот факт, что высота скролла немного не соответствует сумме высот всех ячеек. Что это значит, и как мы можем это использовать? А очень просто:
Мы не будем вообще ничего рендерить, чтобы узнать высоту скролла — мы её посчитаем, также как и в случае с фиксированной высотой строк, по такой вот простой формуле:
SCROLL_HEIGHT = N * ROW_HEIGHT
Где SCROLL_HEIGHT — это высота скролла (т.е. высота «содержимого», которое мы прокручиваем с помощью скролла), N — количество строк, ROW_HEIGHT — высота одной строки (например 30px)
Возникает закономерный вопрос — а как же понять, что нам рисовать при заданном значении положения скролла (SCROLL_TOP), ведь оно не соответствует настоящей высоте содержимого? Ответ следует из использованной нами формулы для расчета высоты:
CURRENT_POSITION = [ SCROLL_TOP / ROW_HEIGHT ]
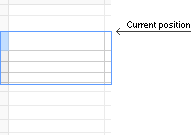 Где [...] означает целую часть от числа, CURRENT_POSITION — индекс первой видимой на данный момент строки, если нумерация идет с нуля
Где [...] означает целую часть от числа, CURRENT_POSITION — индекс первой видимой на данный момент строки, если нумерация идет с нуляЧто нам делать с этим числом :)? Надо нарисовать все видимые строки, начиная с CURRENT_POSITION. То есть, рисуем построчно все строки, начиная с CURRENT_POSITION и до тех пор, пока мы не выйдем за границы видимости ячеек.
Такой способ скролла соответствует построчному скроллу, то есть, мы не сможем проскроллить в середину строки, потому что мы рисуем всегда начиная с какой-то определенной строки, а не с середины. Это будет означать, что если высота строки превышает высоту области, в которой мы рисуем, то мы увидим лишь часть строки без возможности увидеть остальное содержимое! При попытке скролла в таком случае мы сразу же попадем на следующую строку, а предыдущая ячейка полностью скроется из области видимости. Можете проверить это поведение, скажем, в Microsoft Excel, если не верите :).
После того, как пользователь отпустил скролл, можно его выровнять, согласно первой формуле:
SCROLL_TOP = CURRENT_POSITION * ROW_HEIGHT
На самом деле, определение текущего номера строки можно проводить по-разному, это лишь один из способов, который не приводит к излишнему «дерганию» скролла.
В Microsoft Excel и в OpenOffice.org Calc совершенно такой же механизм рендеринга применяется не только для строк, но и для столбцов — в этом случае рендеринг идет не построчно, а по более сложному алгоритму, в детали которого я не вдавался
Пособие для начинающих гридописателей
Эти механизмы рендеринга я использовал сам в нескольких проектах, в том числе и в своём файловом менеджере, сайт которого сейчас отключен за неуплату :). В любом случае, если кто-то захочет реализовать приведенный выше алгоритм самостоятельно, вот несколько советов из практики:
1. Самый простой способ нарисовать грид с виртуальным скроллом — это сделать абсолютно позиционированный <div>, который будет показываться поверх какого-либо контейнера, положение которого можно легко определить с помощью метода offset() в jQuery
2. Самих <div>'ов можно сделать 2 — один с содержимым, другой исключительно со скроллом, чтобы браузер не пытался скроллить <div> с содержимым самостоятельно, иначе это приводит к неприятным эффектам при перерисовке. Также можно попробовать использовать position: fixed, но оно странно работает в IE 7
3. Положение скролла лучше всего вообще не выравнивать, ибо браузеры не дают особого контроля за скроллом
4. Максимальная высота элемента в IE 7 составляет порядка 1 млн. пикселей, поэтому, если брать 30px за виртуальную высоту строки, то получится ограничение порядка 30 000 строк. Чтобы с этим бороться, можно уменьшать виртуальную высоту строки с увеличением количества записей, если браузер — IE
5. Чтобы при прокрутке колёсиком мыши строки прокручивались, можно обрабатывать событие DOMMouseScroll в браузерах, основанных на Gecko, и mousewheel во всех остальных
6. Если вы сделаете более умную перерисовку, чем перерисовку полностью видимой области (т.е., например, динамическое удаление и добавление новых строк при скролле на небольшое количество строк), расскажите пожалуйста мне о результатах :)
Ну и если вы всё же будете реализовывать свой grid, посмотрите документацию к API грида, скажем, в Cocoa — это поможет вам лучше понять, как сделать хорошо масштабируемое решение.
Своих решений я выкладывать не хочу, всё оно писалось в спешке и под конкретные задачи, так что вряд ли кому-то из вас сгодится. Спасибо, что дочитали до конца :))
