Привет. Я хочу показать вам небольшой фокус. Для начала вам потребуется скачать архив с двумя файлами. Оба имеют одинаковый размер и одну и ту же md5 сумму. Проверьте никакого обмана нет. Md5 хеш обоих равен ecea96a6fea9a1744adcc9802ab7590d. Теперь запустите программу good.exe и вы увидите на экране следующее.
Попробуйте запустить программу evil.exe.
Что-то пошло не так? Хотите попробовать сами?
На самом деле ничего нового во всем этом нет. В действительности данный эффект достигается за счет методов быстрого поиска коллизий для хеш функции разработанных еще в 2004-2006 годах. Если кто не знает, коллизия это два разных набора данных, имеющих одно и тоже хеш-значение. Так вот, в 2004 году группа китайских исследователей разработала алгоритм, основанный на дифференциальном криптоанализе, позволяющий за относительно небольшое время находить два различных случайных блока данных, размером по 128 байт каждый, имеющих одну и ту же md5 сумму. И хотя алгоритм этот в свое время произвел эффект взорвавшейся бомбы быстродействие его оставляло желать лучшего. Но уже в 2006 году чешский криптограф Властимил Клима предложил для поиска коллизий новый метод, позволяющий найти разную пару случайных 128 байтных блоков с одной md5 суммой на персональном компьютере меньше чем за минуту.
Вы спросите, но что нам даст обладание такой парой сообщений, мало того что они короткие(всего 128 байт), так еще, в добавок, и случайные, т.е. метод не позволяет для заданного сообщения подобрать другое, с идентичным хешем. Однако это открывает огромный простор для различного рода атак на выполняемые файлы. И виной тому служит следующая особенность работы любой хеш функции: Хеш функция по своей природе итеративна. Это означает, что при подсчете хеша сообщение разбивается на блоки, к каждому блоку применяется функция сжатия, зависящая от некоторой переменной, называемой вектор инициализации. Результат этой функции будет являться вектором инициализации для следующего блока. Результат функции после работы с последним блоком и будет окончательным хеш значением нашего сообщения.
Схематично это можно представить следующим образом:
si+1 = f(si, Mi), где si вектор инициализации для i-го блока.
Метод Властимила Клима позволяет для любого заданного значения si подобрать два 128-байтных блока M,M` и N,N` таких, что f(f(s, M), M') = f(f(s, N), N').
Таким образом, с помощью данной методики можно сконструировать два файла с одинаковой md5 суммой, но имеющих различные 128 байт в середине.
M0, M1, ..., Mi-1, Mi, Mi+1, Mi+2, ..., Mn,
M0, M1, ..., Mi-1, Ni, Ni+1, Mi+2, ..., Mn.
Обратите внимание что хеши обоих этих файлов совпадут, т.к. различающиеся блоки Mi, Mi+1 и
Ni, Ni+1 вернут в качестве si+2 одно и тоже значение, т.к. f(f(s, Mi), Mi+1) = f(f(s, Ni), Ni+1), а поскольку все последующие данные идентичны то последующие значения функции сжатия для обоих файлов будут совпадать.
Теперь перейдем от вещей абстрактных и отдаленных к вопросу практическому. Предположим, что у нас есть исполняемый файл M0, M1, X, X, …, Mn. Но его основе мы можем создать два разных файла M0, M1, N1, N1, …, Mn и M0, M1, N2, N1,…, Mn(просто меняем блоки X на N1 и N2). Если блоки N1 и N2 – это коллизии то хеш-сумма этих файлов будет совпадать.
Теперь представим, что этот исполняемый файл имеет следующую структуру:
if (X == X) then { good_program } else { evil_program }
Вот собственно и весь секрет данного фокуса.
Теперь немного поговорим о том как это сделать самому.
Шаг первый: пишем программу с двойным дном.
Особое внимание прошу обратить на переменные str1 и str2. Они служат для того, чтобы их можно было быстро найти в hex-редакторе и заменить нужными данными.
Функция main в зависимости от содержимого переменных s вызывает хорошую или плохую версию программы.
Шаг второй: После компиляции программы нужно будет немного поработать с hex-редактором для того чтобы найти в .exe файле наши строки str1 и str2. Скопируй полученный .exe файл. Пусть копия будет называется «обрезанная версия». Откройте копию в hex-редакторе и найди в ней строки str1 и str2. Удалите все данные идущие после первых 64 байт первой из строк. Последние строки полученного файла будут выглядеть вот таким образом: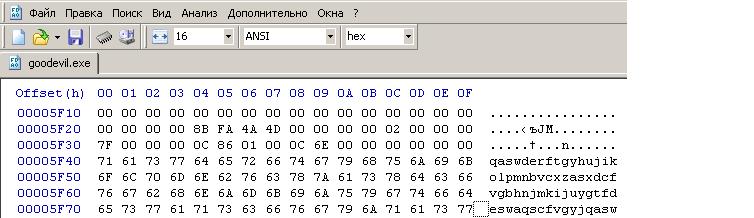 . Сохраните данный файл.
. Сохраните данный файл.
Шаг третий: Созданный на втором шаге файл будет служить так называемым префиксом для поиска коллизий. Чтобы найти коллизию с заданным префиксом нужно скачать отсюда программу fastcoll(Спасибо ее автору Marc Stevens). Исходники лежат тут.
Запустите программу с параметром –p. В качестве префикса укажите «обрезанную версию». В результате работы программы будут созданы два файла «обрезанная версия_msg1» и «обрезанная версия_msg2».
Шаг четвертый: создайте еще одну копию вашей программы. Пусть оригинал будет называться good.exe, а копия evil.exe. Откройте файлы msg1 и msg2 в hex редакторе. Сперва замените блок в котором хранится str2 данными из блока str1. Пусть теперь в них будет одинаковая информация. После этого скопируйте из файла msg1 последние 128 байт и вставьте их в ваш good файл так как показано на рисунке.

Обратите внимание, отступы должны соответствовать следующим параметрам: первый блок вставляется прямо в том месте где заканчивается файл «обрезанная версия», второй блок располагается в 96 байтах от первого. Важно: блоки вставлять одни и те же. Это будет доброй версией нашей программы. Сохраняем файл good.exe и открываем файл evil.exe. Блоки в файл evil.exe нужно будет вставить в те же места, что и в good.exe, единственное отличие заключается в том, что первый блок мы берем из файла msg2, а второй из файла msg1. Это различие и обеспечит нам невыполнение условия программы if (s==s2) и соответственно запустит злую версию программы.
Шаг пятый: Profit! Сравниваем md5 суммы файлов, наслаждаемся полученным результатом.
Список литературы:
1. Замечательный сайт с описанием данного метода
2. Сайт Властимила Клима
3. Сайт автора программы findcoll

Попробуйте запустить программу evil.exe.

Что-то пошло не так? Хотите попробовать сами?
О хешах и колллизиях
На самом деле ничего нового во всем этом нет. В действительности данный эффект достигается за счет методов быстрого поиска коллизий для хеш функции разработанных еще в 2004-2006 годах. Если кто не знает, коллизия это два разных набора данных, имеющих одно и тоже хеш-значение. Так вот, в 2004 году группа китайских исследователей разработала алгоритм, основанный на дифференциальном криптоанализе, позволяющий за относительно небольшое время находить два различных случайных блока данных, размером по 128 байт каждый, имеющих одну и ту же md5 сумму. И хотя алгоритм этот в свое время произвел эффект взорвавшейся бомбы быстродействие его оставляло желать лучшего. Но уже в 2006 году чешский криптограф Властимил Клима предложил для поиска коллизий новый метод, позволяющий найти разную пару случайных 128 байтных блоков с одной md5 суммой на персональном компьютере меньше чем за минуту.
Вы спросите, но что нам даст обладание такой парой сообщений, мало того что они короткие(всего 128 байт), так еще, в добавок, и случайные, т.е. метод не позволяет для заданного сообщения подобрать другое, с идентичным хешем. Однако это открывает огромный простор для различного рода атак на выполняемые файлы. И виной тому служит следующая особенность работы любой хеш функции: Хеш функция по своей природе итеративна. Это означает, что при подсчете хеша сообщение разбивается на блоки, к каждому блоку применяется функция сжатия, зависящая от некоторой переменной, называемой вектор инициализации. Результат этой функции будет являться вектором инициализации для следующего блока. Результат функции после работы с последним блоком и будет окончательным хеш значением нашего сообщения.
Схематично это можно представить следующим образом:
si+1 = f(si, Mi), где si вектор инициализации для i-го блока.
Метод Властимила Клима позволяет для любого заданного значения si подобрать два 128-байтных блока M,M` и N,N` таких, что f(f(s, M), M') = f(f(s, N), N').
Таким образом, с помощью данной методики можно сконструировать два файла с одинаковой md5 суммой, но имеющих различные 128 байт в середине.
M0, M1, ..., Mi-1, Mi, Mi+1, Mi+2, ..., Mn,
M0, M1, ..., Mi-1, Ni, Ni+1, Mi+2, ..., Mn.
Обратите внимание что хеши обоих этих файлов совпадут, т.к. различающиеся блоки Mi, Mi+1 и
Ni, Ni+1 вернут в качестве si+2 одно и тоже значение, т.к. f(f(s, Mi), Mi+1) = f(f(s, Ni), Ni+1), а поскольку все последующие данные идентичны то последующие значения функции сжатия для обоих файлов будут совпадать.
Что это нам дает
Теперь перейдем от вещей абстрактных и отдаленных к вопросу практическому. Предположим, что у нас есть исполняемый файл M0, M1, X, X, …, Mn. Но его основе мы можем создать два разных файла M0, M1, N1, N1, …, Mn и M0, M1, N2, N1,…, Mn(просто меняем блоки X на N1 и N2). Если блоки N1 и N2 – это коллизии то хеш-сумма этих файлов будет совпадать.
Теперь представим, что этот исполняемый файл имеет следующую структуру:
if (X == X) then { good_program } else { evil_program }
Вот собственно и весь секрет данного фокуса.
Как сделать самостоятельно
Теперь немного поговорим о том как это сделать самому.
Шаг первый: пишем программу с двойным дном.
#include <stdafx.h>
#include<iostream>
#include <string>
using namespace std;
//переменные str1 и str2 в данном примере являются теми самыми элементами X.
static char *str1="qwertyuioplkjhgfdaszxcvbnmkjhgfdsaqwertyuikjh"\
"gbvfdsazxdcvgbhnjikmjhbgfvcdsazxdcfrewqikolkjnhgfqwertyuioplkjh"\
"gfdaszxcvbnmkjhgfdsaqwertyuikjhgbvfdsazxdcvgbhnjikmjhbgfvcdsa"\
"zxdcfrewqikolkjnhgfq123";
static char *str2="qaswderftgyhujikolpmnbvcxzasxdcfvgbhnjmkijuy"\
"gtfdeswaqscfvgyjqaswderftgyhujikolpmnbvcxzasxdcfvgbhnjmkijuyg"\
"tfdeswaqscfvgyjqaswderftgyhujikolpmnbvcxzasxdcfvgbhnjmkijuygt"\
"fdeswaqscfvgyjqwertyuikja2";
int good()
{
int a;
std::cout<<"Good, nice programme!";
std::cin>>a;
return 0;
}
int bed()
{
int a;
for(int i=0; i<1000; i++)
{
std::cout<<"Evil, evil code!";
}
std::cin>>a;
return 0;
}
int _tmain(int argc, _TCHAR* argv[])
{
//строки s и s2 содержат только блоки с коллизиями без лишних элементов
string s=str1;
string s2=str2;
s.erase(0,56);
s.erase(128,8);
s2.erase(0,64);
if (s==s2) {
return good();
} else {
return bed();
}
return 0;
}
* This source code was highlighted with Source Code Highlighter.Особое внимание прошу обратить на переменные str1 и str2. Они служат для того, чтобы их можно было быстро найти в hex-редакторе и заменить нужными данными.
Функция main в зависимости от содержимого переменных s вызывает хорошую или плохую версию программы.
Шаг второй: После компиляции программы нужно будет немного поработать с hex-редактором для того чтобы найти в .exe файле наши строки str1 и str2. Скопируй полученный .exe файл. Пусть копия будет называется «обрезанная версия». Откройте копию в hex-редакторе и найди в ней строки str1 и str2. Удалите все данные идущие после первых 64 байт первой из строк. Последние строки полученного файла будут выглядеть вот таким образом:
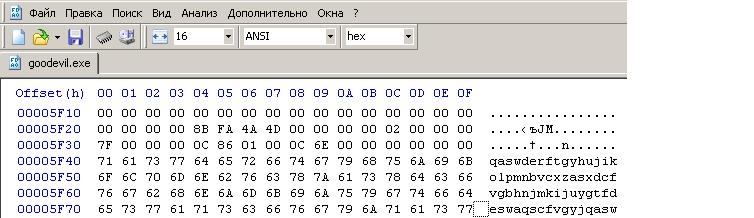 . Сохраните данный файл.
. Сохраните данный файл. Шаг третий: Созданный на втором шаге файл будет служить так называемым префиксом для поиска коллизий. Чтобы найти коллизию с заданным префиксом нужно скачать отсюда программу fastcoll(Спасибо ее автору Marc Stevens). Исходники лежат тут.
Запустите программу с параметром –p. В качестве префикса укажите «обрезанную версию». В результате работы программы будут созданы два файла «обрезанная версия_msg1» и «обрезанная версия_msg2».
Шаг четвертый: создайте еще одну копию вашей программы. Пусть оригинал будет называться good.exe, а копия evil.exe. Откройте файлы msg1 и msg2 в hex редакторе. Сперва замените блок в котором хранится str2 данными из блока str1. Пусть теперь в них будет одинаковая информация. После этого скопируйте из файла msg1 последние 128 байт и вставьте их в ваш good файл так как показано на рисунке.

Обратите внимание, отступы должны соответствовать следующим параметрам: первый блок вставляется прямо в том месте где заканчивается файл «обрезанная версия», второй блок располагается в 96 байтах от первого. Важно: блоки вставлять одни и те же. Это будет доброй версией нашей программы. Сохраняем файл good.exe и открываем файл evil.exe. Блоки в файл evil.exe нужно будет вставить в те же места, что и в good.exe, единственное отличие заключается в том, что первый блок мы берем из файла msg2, а второй из файла msg1. Это различие и обеспечит нам невыполнение условия программы if (s==s2) и соответственно запустит злую версию программы.
Шаг пятый: Profit! Сравниваем md5 суммы файлов, наслаждаемся полученным результатом.
Список литературы:
1. Замечательный сайт с описанием данного метода
2. Сайт Властимила Клима
3. Сайт автора программы findcoll
