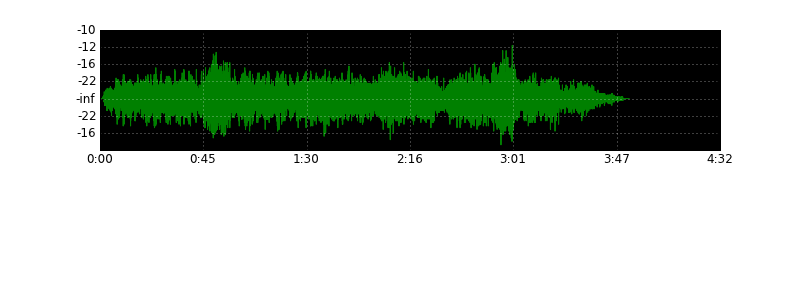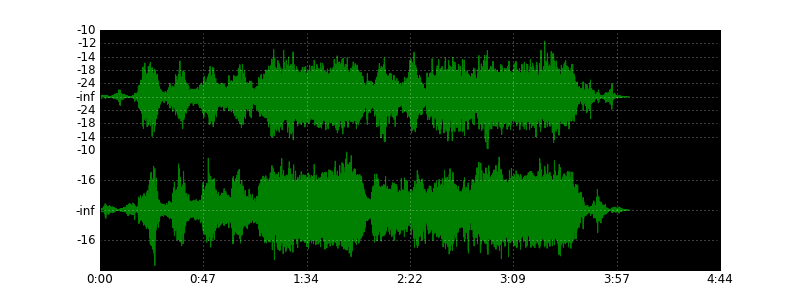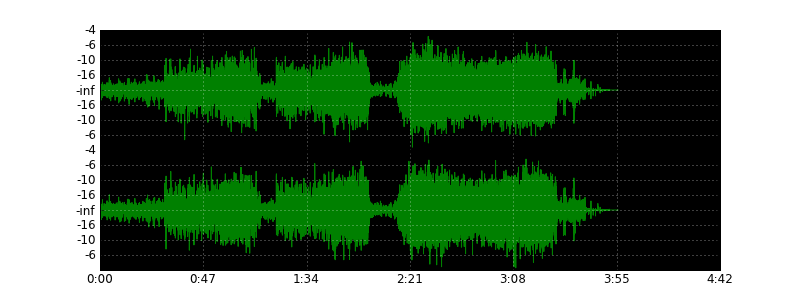
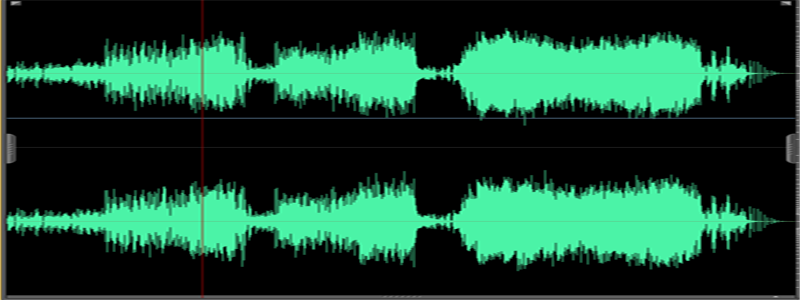
Некоторое время назад я решил посвятить себя решению экзотической задачи — нарисовать волну wave-файла, как это делают аудио- и видеоредакторы, используя для этого Питон. В результате у меня получился небольшой скрипт, который вполне с этим справляется. Так, картинка выше сгенерирована им из песни «Under Pressure» группы Queen. Для сравнения — вид волны в аудиоредакторе:
Для разбора звука я использовал библиотеку numpy, а для построения графика — matplotlib. Под катом я изложу основы работы с wav-файлами и алгоритм скрипта.
UPD1: коэффициент прореживания k лучше брать примерно k = nframes/w/32, подобрал эмпирически. Обновил картинки с новым коэффициентом.
WAV — это формат для хранения несжатого аудиопотока, широко используемый в медиаиндустрии. Его особенность в том, что для кодирования амплитуды выделяется фиксированное число бит. Это сказывается на размере выходного файла, но делает его очень удобным для чтения. Типичный wave-файл состоит из заголовочной части, тела с аудиопотоком и хвоста для дополнительной информации, куда аудиоредакторы могут записывать собственные метаданные.
Из заголовочной части извлекаются основные параметры — число каналов, битрейт, число фреймов — на основании которых осуществляется разбор аудиопотока. Wave-файл хранит в себе 1 или 2 канала, каждый из которых кодируется 8, 16, 24 или 32 битами. Последовательность бит, описывающая амплитуду волны в момент времени, называется сэмплом. Последовательность сэмплов для всех каналов в определенный момент называется фреймом.
Например, \xe2\xff\xe3\xfа — это фрейм 16-битного wav-файла. Значит, \xe2\xff — сэмпл первого (левого) канала, а \xe3\xfа — второго (правого). Сэмплы представляют собой целые знаковые числа (исключение — файлы с сэмплами в 8 бит, беззнаковые числа).
В богатой питоновской библиотеке есть модуль wave, предназначенный для парсинга wav-файлов. Он позволяет получить основные характеристики звука и читать его по отдельным фреймам. На этом его возможности кончаются и парсить аудиопоток придется самостоятельно.
import wave
wav = wave.open("music.wav", mode="r")
(nchannels, sampwidth, framerate, nframes, comptype, compname) = wav.getparams()
content = wav.readframes(nframes)
Этими строками мы создаем объект для чтения wav-файла (если параметр «r» опустить, то будет создан объект для записи, что нам не подходит). Метод getparams() возвращает кортеж основных параметров файла (по порядку): число каналов, число байт на сэмпл, число вреймов в секунду, общее число фреймов, тип сжатия, имя типа сжатия. Я вынес их всё в отдельные переменные, чтобы не обращаться каждый раз к полям объекта.
Метод readframes() считывает указанное число фреймов относительно внутреннего указателя объекта и инкрементирует его. В данном случае, мы за один раз считали все фреймы в одну байтовую строку в переменную content.
Теперь нужно разобрать эту строку. Параметр sampwidth определяет, сколько байт уходит на кодирование одного сэмпла:
- 1 = 8 бит, беззнаковое целое (0-255),
- 2 = 16 бит, знаковое целое (-32768-32767)
- 4 = 32 бит, знаковое длинное целое (-2147483648-2147483647)
Разбор осуществляется следующим образом:
import numpy as np
types = {
1: np.int8,
2: np.int16,
4: np.int32
}
samples = np.fromstring(content, dtype=types[sampwidth])
Здесь задействуется библиотека numpy. Ее основное предназначение — математические действия с массивами и матрицами. Numpy оперирует своими собственными типами данных. Функция fromstring() создает одномерный массив из байтовой строки, при этом параметр dtype определяет, как будут интерпретированы элементы массива. В нашем примере, тип данных берется из словаря «types», в котором сопоставлены размеры сэмпла и типы данных numpy.
Теперь у нас есть массив сэмплов аудиопотока. Если в нем один канал, весь массив будет представлять его, если два (или несколько), то нужно «проредить» массив, выбрав для каждого канала каджый n-ый элемент:
for n in range(nchannels):
channel = samples[n::nchannels]
В этом цикле в массив channel выбирается каждый аудиоканал при помощи среза вида [offset::n], где offset — индекс первого элемента, а n — шаг выборки. Но массив канала содержит огромное количество точек, и вывод графика для 3-минутного файла потребует огромных затрат памяти и времени. Введем в код некоторые дополнительные переменные:
duration = nframes / framerate
w, h = 800, 300
DPI = 72
peak = 256 ** sampwidth / 2
k = nframes/w/32
duration — длительность потока в секундах, w и h — ширина и высота выходного изображения, DPI — произвольное значение, необходимое для перевода пикселей в дюймы, peak — пиковое значение амплитуды сэмпла, k — коэффициент прореживания канала, зависящий от ширины изображения; подобран эмпирически.
Скорректируем отображение графика:
plt.figure(1, figsize=(float(w)/DPI, float(h)/DPI), dpi=DPI)
plt.subplots_adjust(wspace=0, hspace=0)
Теперь цикл с выводом каналов будет выглядеть так:
for n in range(nchannels):
channel = samples[n::nchannels]
channel = channel[0::k]
if nchannels == 1:
channel = channel - peak
axes = plt.subplot(2, 1, n+1, axisbg="k")
axes.plot(channel, "g")
axes.yaxis.set_major_formatter(ticker.FuncFormatter(format_db))
plt.grid(True, color="w")
axes.xaxis.set_major_formatter(ticker.NullFormatter())
В цикле делается проверка на число каналов. Как я уже говорил, 8-битный звук хранится в беззнаковых целых, поэтому его необходимо нормализовать, отняв от каждого сэмпла половину амплитуды.
Напоследок, установим формат нижней оси
axes.xaxis.set_major_formatter(ticker.FuncFormatter(format_time))
Сохраним график в картинку и покажем его:
plt.savefig("wave", dpi=DPI)
plt.show()
format_time и format_db — это функции для форматирования значений шкал осей абсцисс и ординат.
format_time форматирует время по номеру сэмпла:
def format_time(x, pos=None):
global duration, nframes, k
progress = int(x / float(nframes) * duration * k)
mins, secs = divmod(progress, 60)
hours, mins = divmod(mins, 60)
out = "%d:%02d" % (mins, secs)
if hours > 0:
out = "%d:" % hours
return out
Функция format_db форматирует громкость звука по его амплитуде:
def format_db(x, pos=None):
if pos == 0:
return ""
global peak
if x == 0:
return "-inf"
db = 20 * math.log10(abs(x) / float(peak))
return int(db)
Весь скрипт:
import wave
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import math
types = {
1: np.int8,
2: np.int16,
4: np.int32
}
def format_time(x, pos=None):
global duration, nframes, k
progress = int(x / float(nframes) * duration * k)
mins, secs = divmod(progress, 60)
hours, mins = divmod(mins, 60)
out = "%d:%02d" % (mins, secs)
if hours > 0:
out = "%d:" % hours
return out
def format_db(x, pos=None):
if pos == 0:
return ""
global peak
if x == 0:
return "-inf"
db = 20 * math.log10(abs(x) / float(peak))
return int(db)
wav = wave.open("music.wav", mode="r")
(nchannels, sampwidth, framerate, nframes, comptype, compname) = wav.getparams()
duration = nframes / framerate
w, h = 800, 300
k = nframes/w/32
DPI = 72
peak = 256 ** sampwidth / 2
content = wav.readframes(nframes)
samples = np.fromstring(content, dtype=types[sampwidth])
plt.figure(1, figsize=(float(w)/DPI, float(h)/DPI), dpi=DPI)
plt.subplots_adjust(wspace=0, hspace=0)
for n in range(nchannels):
channel = samples[n::nchannels]
channel = channel[0::k]
if nchannels == 1:
channel = channel - peak
axes = plt.subplot(2, 1, n+1, axisbg="k")
axes.plot(channel, "g")
axes.yaxis.set_major_formatter(ticker.FuncFormatter(format_db))
plt.grid(True, color="w")
axes.xaxis.set_major_formatter(ticker.NullFormatter())
axes.xaxis.set_major_formatter(ticker.FuncFormatter(format_time))
plt.savefig("wave", dpi=DPI)
plt.show()
Еще примеры: