Именно так называлась работа, представленная мной на Балтийском научно-инженерном конкурсе, и принёсшая мне очаровательную бумажку с римской единичкой, а также новенький ноутбук.
Работа заключалась в распознавании CAPTCHA, используемых крупными операторами сотовой связи в формах отправки SMS, и демонстрации недостаточной эффективности применяемого ими подхода. Чтобы не задевать ничью гордость, будем называть этих операторов иносказательно: красный, жёлтый, зелёный и синий.
Проект получил официальное название Captchure и неофициальное Breaking Defective Security Measures. Любые совпадения случайны.
Как ни странно, все (ну, почти все) эти CAPTCHA оказались довольно слабенькими. Наименьший результат — 20% — принадлежит жёлтому оператору, наибольший — 86% — синему. Таким образом, я считаю, что задача «демонстрации неэффективности» была успешно решена.
Причины выбора именно сотовых операторов тривиальны. Уважаемому Научному Жюри я рассказывал байку о том, что «сотовые операторы имеют достаточно денег, чтобы нанять программиста любой квалификации, и, в то же время, им необходимо минимизировать количество спама; таким образом, их CAPTCHA должны быть довольно мощными, что, как показывает моё исследование, совсем не так». На самом же деле всё было гораздо проще. Я хотел набраться опыта,взломав распознав какую-нибудь простую CAPTCHA, и выбрал жертвой CAPTCHA красного оператора. А уже после этого, задним числом родилась вышеупомянутая история.
Итак, ближе к телу. Никакого мегапродвинутого алгоритма для распознавания всех четырёх видов CAPTCHA у меня нет; вместо него я написал 4 различных алгоритма для каждого вида CAPTCHA по отдельности. Однако, несмотря на то, что алгоритмы в деталях различны, в целом они оказались очень похожими.
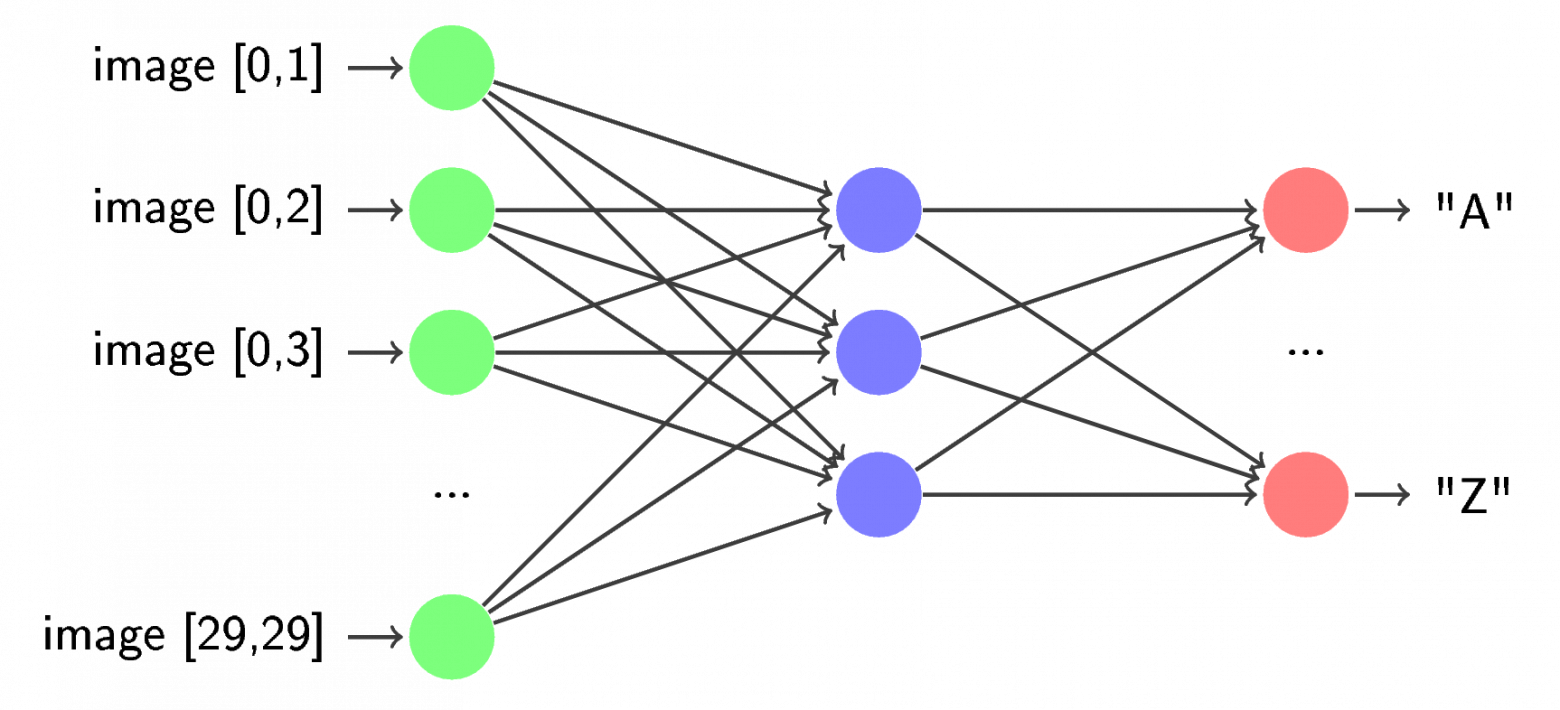
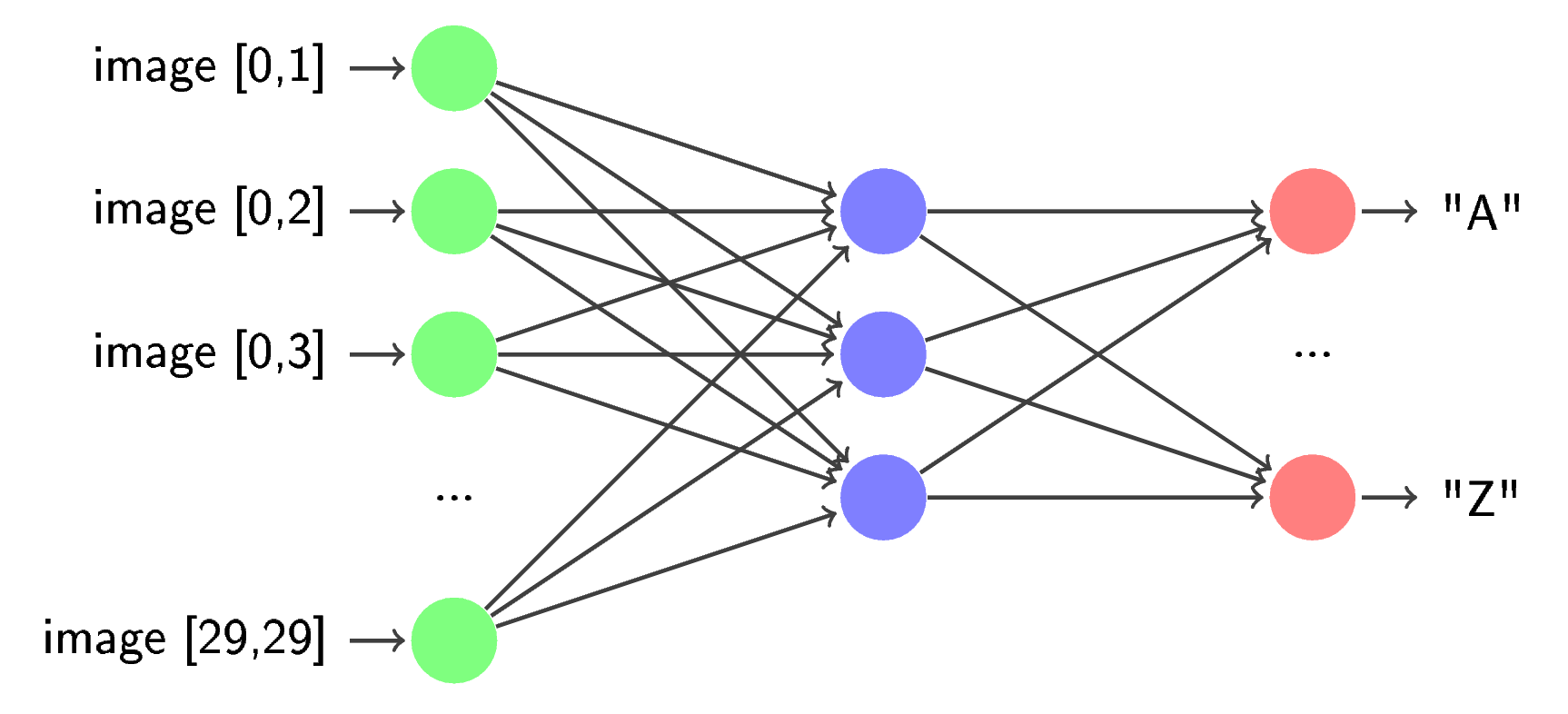
Как и многие авторы до меня, я разбил задачу распознавания CAPTCHA на 3 подзадачи: предварительную обработку (препроцесс), сегментацию и распознавание. На этапе препроцесса из исходного изображения удаляются различные шумы, искажения и пр. В сегментации из исходного изображения выделяются отдельные символы и производится из постобработка (например, обратный поворот). При распознавании символы по одному обрабатываются предварительно обученной нейросетью.
Существенно различался только препроцесс. Это связано с тем, что в различных CAPTCHA применяются различные методы искажения изображений, соответственно, и алгоритмы для удаления этих искажений сильно различаются. Сегментация эксплуатировала ключевую идею поиска компонентов связности с незначительными наворотами (значительными их пришлось сделать только у жёлто-полосатых). Распознавание было абсолютно одинаковым у трёх операторов из четырёх — опять-таки, отличался только жёлтый оператор.
Код написан на Python с применением библиотек OpenCV и FANN, которые не ставятся без напильника приличных размеров и бубна впридачу. Поэтому мои результаты будет воспроизвести непросто — по крайней мере, до тех пор, пока авторы вышеупомянутых библиотек не сделают нормальные привязки для Python.
Как я уже сказал, первым кроликом я выбрал именно эту CAPTCHA. Думаю, несколько примеров прояснят ситуацию:


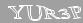
Вот-вот, и мне тоже сначала показалось, что она очень простая… Однако, это впечатление возникло не на пустом месте. Итак:
Казалось, всё это сводит на нет достоинства этой CAPTCHA:
Естественно, эти «достоинства» являются таковыми только с точки зрения сложности автоматического распознавания. В соответствии с трёхэтапной схемой, упомянутой мной ранее, начнём с предварительной обработки изображения, а именно увеличения в 2 раза.


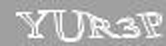
Как я уже упоминал, искажения здесь постоянны, и, даже несмотря на то, что они не являются линейными, избавиться от них нетрудно. Параметры были подобраны эмпирически.




Далее я применяю пороговое преобразование (в народе Threshold) с t=200 и инвертирую изображение:

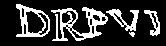

Наконец, белым закрашиваются мелкие (меньше 10px) чёрные связные области:



Далее следует сегментация. Как я уже сказал, здесь применяется поиск компонентов связности:



Иногда (редко, но бывает) буква распадается на несколько частей; для исправления этого досадного недоразумения я применяю довольно простую эвристику, оценивающую принадлежность нескольких компонентов связности к одному символу. Эта оценка зависит только от горизонтального положения и размеров описывающих прямоугольников (bounding boxes) каждого символа.

Нетрудно заметить, что многие символы оказались объединены в один компонент связности, в связи с чем надо их разделять. Здесь на помощь приходит тот факт, что на изображении всегда ровно 5 символов. Это позволяет с большой точностью вычислять, сколько символов находится в каждом найденном компоненте.
Для объяснения принципа работы такого алгоритма придётся немного углубиться в матчасть. Обозначим количество найденных сегментов за n, а массив ширин (правильно сказал, да?) всех сегментов за widths[n]. Будем считать, что если после вышеупомянутых этапов n > 5, изображение распознать не удалось. Рассмотрим все возможные разложения числа 5 на целые положительные слагаемые. Их немного — всего 16. Каждое такое разложение соответствует некоторой возможной расстановке символов по найденным компонентам связности. Логично предположить, что чем шире получившийся сегмент, тем больше символов он содержит. Из всех разложений пятёрки выберем только те, в которых количество слагаемых равно n. Поделим каждый элемент из widths на widths[0] — как бы нормализуем их. То же самое проделаем со всеми оставшимися разложениями — поделим каждое число в них на первое слагаемое. А теперь (внимание, кульминация!) заметим, что получившиеся упорядоченные n-ки можно мыслить как точки в n-мерном пространстве. С учётом этого, найдём ближайшее по Евклиду разложение пятёрки к нормализованному widths. Это и есть искомый результат.
Кстати, в связи с этим алгоритмом мне в голову пришёл ещё один интересный способ искать все разложения числа на слагаемые, который я, правда, так и не реализовал, закопавшись в питоновских структурах данных. Вкратце — он довольно очевидно вылезает, если заметить, что количество разложений определённой длины совпадает с соответствующим уровнем треугольника Паскаля. Впрочем, я уверен, что этот алгоритм давным-давно известен.
Так вот, после определения количества символов в каждом компоненте наступает следующая эвристика — мы считаем, что разделители между символами тоньше, чем сами символы. Для того чтобы воспользоваться этим сокровенным знанием, расставим по сегменту n-1 разделителей, где n — количество символов в сегменте, после чего в небольшой окрестности каждого разделителя посчитаем проекцию изображения вниз. В результате этого проецирования мы получим информацию о том, сколько в каждом столбце пикселей принадлежат символам. Наконец, в каждой проекции найдём минимум и сдвинем разделитель туда, после чего покромсаем изображение по этим разделителям.




Наконец, распознавание. Как я уже говорил, для него я применяю нейросеть. Для её обучения сначала я прогоняю две сотни изображений под общим заголовком trainset через уже написанные и отлаженные первые два этапа, в результате чего получаю папку с большим количеством аккуратно нарезанных сегментов. Затем руками вычищаю мусор (результаты неправильной сегментации, например), после чего результат привожу к одному размеру и отдаю на растерзание FANN. На выходе получаю обученную нейросеть, которая и используется для распознавания. Эта схема дала сбой только один раз — но об этом позже.
В результате на тестовом наборе (не использованном для обучения, кодовое имя — testset) из 100 картинок были правильно распознаны 45. Не слишком высокий результат — его, конечно, можно улучшить, например, уточнив препроцесс или переделав распознавание, но, честно говоря, мне было лень с этим возиться.
Кроме того, я использовал ещё один критерий оценки производительности алгоритма — средняя ошибка. Вычислялся он следующим образом. Для каждого изображения находилось расстояние Левенштейна между мнением алгоритма об этом изображении и правильным ответом — после чего бралось среднее арифметическое по всем изображениям. Для этого вида CAPTCHA средняя ошибка составила 0.75 символа/изображение. Мне кажется, что это более точный критерий, нежели просто процент распознавания.
Кстати говоря, почти везде (кроме жёлтого оператора) у меня использовалась именно такая схема — 200 картинок в trainset, 100 — в testset.
Следующей целью я выбрал зелёных — хотелось взяться за что-то более серьёзное, чем подбор матрицы искажений.
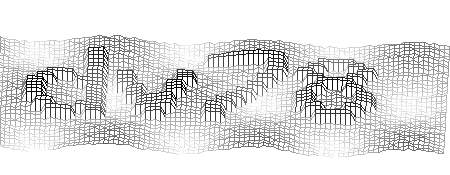
Достоинства:
Недостатки:
Оказалось, что даже несмотря на то, что эти недостатки, казалось бы, незначительны, их эксплуатация позволяет весьма эффективно расправиться со всеми достоинствами.
Опять начнём с предварительной обработки. Сначала оценим угол поворота прямоугольника, на котором лежат символы. Для этого применим к исходному изображению оператор Erode (поиск локального минимума), затем Threshold, чтобы выделить остатки прямоугольника и, наконец, инверсию. Получим симпатичное белое пятно на чёрном фоне.
Далее начинается глубокая мысль. Первое. Для оценки угла поворота всего прямоугольника достаточно оценить угол поворота его верхней стороны. Второе. Можно оценить угол поворота верхней стороны поиском прямой, параллельной этой стороне. Третье. Для описания любой прямой, кроме строго вертикальной, достаточно двух параметров — смещения по вертикали от центра координат и угла наклона, причём нас интересует только второй. Четвёртое. Задачу поиска прямой можно решить не очень большим перебором — слишком больших углов поворота там не бывает, да и сверхвысокая точность нам не нужна. Пятое. Для поиска необходимой прямой можно сопоставить каждой прямой оценку того, насколько она близка к искомой, после чего выбрать максимум. Шестое. Самое Важное. Чтобы оценить некоторый угол наклона прямой, представим, что изображения сверху касается прямая с таким углом наклона. Понятно, что из размеров изображения и угла наклона можно однозначно вычислить смещение прямой по вертикали, так что она задаётся однозначно. Далее, постепенно будем двигать эту прямую вниз. В какой-то момент она коснётся белого пятна. Запомним этот момент и площадь пересечения прямой с пятном. Напомню, что прямая имеет 8ми-связное представление на плоскости, поэтому гневные выкрики из зала о том, что прямая имеет одно измерение, а площадь — понятие двумерное, здесь неуместны. Затем ещё некоторое время будем двигать эту прямую вниз, на каждом шаге запоминая площадь пересечения, после чего просуммируем полученные результаты. Эта сумма и будет оценкой данного угла поворота.


Подводя итог вышесказанного: будем искать такую прямую, что при движении её вниз по изображению яркость пикселей, лежащих на этой прямой, возрастает наиболее резко.
Итак, угол поворота найден. Но не следует спешить тут же применить полученное знание. Дело в том, что это испорит связность изображения, а она нам ещё понадобится.
Следующий шаг — отделение символов от фона. Здесь нам здорово поможет тот факт, что символы значительно темнее фона. Вполне логичный шаг со стороны разработчиков — иначе картинку было бы очень сложно прочитать. Кто не верит — может попробовать самостоятельно бинаризовать изображение и убедиться воочию.
Однако, подход «в лоб» — попытка отсечь символы пороговым преобразованием — здесь не работает. Наилучший результат, которого мне удалось добиться — при t=140 — выглядит весьма плачевно. Остаётся слишком много мусора. Поэтому пришлось применить обходной путь. Идея здесь следующая. Символы, как правило, связны. Причём им часто принадлежат самые тёмные точки на изображении. А что если попробовать применить заливку из этих самых тёмных точек, а затем выкинуть слишком маленькие залитые области — очевидный мусор?
Результат, честно говоря, поразителен. На большинстве изображений удаётся избавиться от фона полностью. Впрочем, бывает, что символ распадается на несколько частей — в этом случае может помочь один костыль в сегментации — но об этом чуть позже.

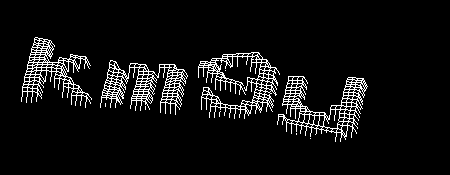
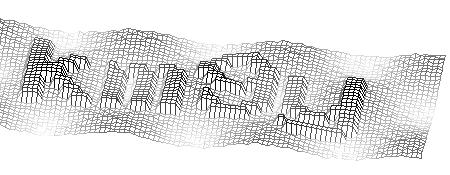
Далее, произведём поворот на найденный ранее угол.


Наконец, комбинация операторов Dilate и Erode избавляет нас от мелких дырок, оставшихся в символах, что помогает упростить распознавание.


Сегментация здесь значительно проще, чем препроцесс. В первую очередь ищем компоненты связности.


Затем объединяем близкие по горизонтали компоненты (процедура ровно та же, что и ранее):


Собственно, всё. Далее следует распознавание, но оно ничем не отличается от вышеупомянутого.
Этот алгоритм позволил достичь результата в 69% успешно распознанных изображений и получить среднюю ошибку 0.3 символа/изображение.
Итак, третьим статус «defeated» получил синий оператор. Это была, так сказать, передышка перед действительно крупной рыбой…



Здесь сложно что-то записать в достоинства, но я, всё же, попробую:
В противовес этому:
Итак, препроцесс. Начнём с отсечения фона. Поскольку изображение трёхцветное, порежем его на каналы, а затем выбросим все точки, которые ярче 116 по всем каналам. Получим вот такую симпатичную маску:



Затем преобразуем изображение в цветовое пространство HSV (Википедия). Это сохранит информацию о цвете символов, а заодно и уберёт градиент с их краёв.



Применим к результату полученную ранее маску:



На этом препроцесс заканчивается. Сегментация также весьма тривиальна. Начнём, как всегда, с компонентов связности:




Можно было бы на этом и остановиться, но так получается всего 73%, что меня совсем не устраивает — всего на 4% лучше, чем результат заведомо более сложной CAPTCHA. Итак, следующим шагом будет обратный поворот символов. Здесь нам пригодится уже упомянутый мной факт о том, что местные символы хорошо вписываются в прямоугольник. Идея состоит в том, чтобы найти описывающий прямоугольник для каждого символа, а затем по его наклону вычислить наклон собственно символа. Здесь под описывающим прямоугольником понимается такой, что он, во-первых, содержит в себе все пиксели данного символа, а, во-вторых, имеет наименьшую площадь из всех возможных. Я пользуюсь готовой реализацией алгоритма поиска такого прямоугольника из OpenCV (MinAreaRect2).

Дальше, как всегда, следует распознавание.
Этот алгоритм успешно распознаёт 86% изображений при средней ошибке в 0.16 символа/изображение, что подтверждает предположение о том, что эта CAPTCHA — действительно самая простая. Впрочем, и оператор не самый крупный…
Наступает самое интересное. Так сказать, апофеоз моей творческой деятельности :) Эта CAPTCHA — действительно самая сложная как для компьютера, так и, к сожалению для человека.



Достоинства:
Недостатки:
Над первым шагом я думал долго. Первое, что приходило в голову — поиграться с локальными максимумами (Dilate), чтобы удалить мелкий шум. Однако, такой подход приводил к тому, что и от букв мало что оставалось — только рваные очертания. Проблема усугублялась тем, что текстура самих символов неоднородная — это хорошо видно при большом увеличении. Чтобы от неё избавиться, я решил выбрать самый тупой способ — открыл Paint и записал коды всех цветов, встречающихся в изображениях. Оказалось, что всего в этих изображениях встречаются четыре различных текстуры, причём на три из них приходится по 4 различных цвета, а на последнюю — 3; более того, все компоненты этих цветов оказались кратными 51. Далее я составил таблицу цветов, при помощи которой удалось избавиться от текстуры. Впрочем, перед этим «ремапом» я ещё затираю все слишком светлые пиксели, которые обычно находятся по краям символов — иначе приходится помечать их как шум, а потом с ними бороться, в то время как информации в них содержится немного.
Итак, после этого преобразования на изображении находится не более 6 цветов — 4 цвета символов (будем их условно называть серым, синим, светло-зелёным и тёмно-зелёным), белый (цвет фона) и «неизвестный», обозначающий, что цвет пикселя на его месте не удалось отождествить ни с одним из известных цветов. Называть условно — потому что к этому моменту я избавляюсь от трёх каналов и перехожу к привычному и удобному монохромному изображению.



Следующим шагом стала очистка изображения от линий. Здесь ситуацию спасает тот факт, что эти линии очень тонкие — всего 1 пиксель. Напрашивается простой фильтр: пройтись по всему изображению, сравнивая цвет каждого пикселя с цветами его соседей (парами — по вертикали и горизонтали); если соседи по цвету совпадают, и при этом не совпадают с цветом самого пикселя — сделать его таким же, как и соседи. Я применяю чуть более навороченную версию того же фильтра, который работает в два этапа. На первом он оценивает соседей на расстоянии 2, на втором — на расстоянии 1. Это позволяет добиться вот такого эффекта:

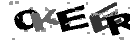

Далее я избавляюсь от большинства пятен, а также от «неизвестного» цвета. Для этого я сначала ищу все мелкие связные области (меньшие 15 по площади, если быть точным), наношу их на чёрно-белую маску, после чего результат объединяю с областями, занятыми «неизвестным» цветом.


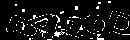
При помощи этих масок я натравливаю на изображение алгоритм Inpaint (а точнее, его реализацию в OpenCV). Это позволяет весьма эффективно вычистить большую часть мусора из изображения.



Однако, реализация этого алгоритма в OpenCV была создана для работы с фотографиями и видео, а не распознавания искусственно созданных изображений с зашумлённым текстом. После его применения появляются градиенты, чего хотелось бы избежать, чтобы упростить сегментацию. Таким образом, приходится производить дополнительную обработку, а именно — повышение резкости. Для цвета каждого пикселя я вычисляю ближайший к нему из вышеупомянутой таблицы (напомню, там 5 цветов — по одному на каждую из текстур символов и белый).



Наконец, последним шагом препроцесса будет удаление всех оставшихся мелких связных областей. Появляются они после применения Inpaint, поэтому никакого повторения здесь нет.



Переходим к сегментации. Её сильно усложняет тот факт, что символы находятся очень близко друг к другу. Может случиться такая ситуация, что за одним символом не видно половину другого. Совсем плохо становится, когда эти символы ещё и одного цвета. Кроме того, остатки мусора также играют свою роль — может случиться так, что на исходном изображении линии в большом количестве пересекались в одном месте. В этом случае тот алгоритм, который я описал ранее, окажется неспособным от них избавиться.
После недели, проведённой в бесплодных попытках написать сегментацию так же, как и в предыдущих случаях, я забил на это дело и сменил тактику. Моя новая стратегия заключалась в том, чтобы разделить весь процесс сегментации на две части. В первой оценивается угол поворота символов и выполняется обратный поворот. Во второй из уже развёрнутого изображения заново выделяются символы. Итак, приступим. Начнём, как всегда, с поиска компонентов связности.



Затем нужно оценить угол поворота каждого символа. Ещё при работе с оператором-фанатом-гринписа я придумал алгоритм для этого, но написал и применил его только здесь. Для того чтобы проиллюстрировать его работу, проведу аналогию. Представьте себе поршень, который движется на чёрно-белое изображение символа снизу вверх. Ручка поршня, за которую его толкают, расположена вертикально, рабочая площадка, которой он толкает — горизонтально, параллельно нижней части изображения и перпендикулярно ручке. Ручка прикреплена к площадке посередине, и в месте присоединения находится подвижное сочленение, в результате чего площадка может поворачиваться. Да простят меня специалисты по терминологии.
Пусть ручка двигается вверх, толкая перед собой площадку по законам физики. Будем считать, что материальным является только белое изображение символа, а сквозь чёрный фон поршень с лёгкостью проходит. Тогда поршень, дойдя до белого цвета, начнёт с ним взаимодействовать, а именно, поворачиваться — при условии, что сила к ручке всё ещё прикладывается. Остановиться он может в двух случаях: если он упёрся в символ по обе стороны от точки приложения силы, или если он упёрся в символ самой точкой приложения силы. Во всех остальных случаях он сможет продолжать движение. Внимание, кульминация: будем считать, что угол поворота символа — это угол наклона поршня в тот момент, когда он остановился.

Этот алгоритм довольно точен, но заведомо слишком большие результаты (больше 27 градусов) я не учитываю. Из оставшихся я нахожу среднее арифметическое, после чего целиком всё изображение поворачиваю на минус этот угол. Затем выполняю поиск компонентов связности ещё раз.


Дальше становится всё интереснее и интереснее. В предыдущих примерах я начинал различные махинации с полученными сегментами, после чего передавал их нейросети. Здесь всё иначе. Сначала, для того чтобы хотя бы частично восстановить информацию, утраченную после разделения изображения на компоненты связности, я на каждом из них тёмно-серым цветом (96) дорисовываю «фон» — то, что было рядом с вырезанным сегментом, но в него не попало, после чего сглаживаю очертания символов, применяя ту же процедуру, что и в препроцессе для линий (с расстоянием до соседа, равным единице).
Формально (с точки зрения модулей программы) здесь сегментация заканчивается. Внимательный читатель, должно быть, заметил, что нигде не упоминалось разделение слипшихся символов. Да, это так — на распознавание я их передаю именно в таком виде, а допиливаю уже на месте.
Причина заключается в том, что тот метод разделения слипшихся символов, который был описан ранее (с наименьшей проекцией) здесь не работает — шрифт выбран авторами весьма удачно. Поэтому приходится применять другой, более сложный подход. В основе этого подхода лежит идея, что нейросеть можно использовать для сегментации.
В самом начале я описывал алгоритм, позволяющий найти количество символов в сегменте при известой ширине этого сегмента и общем количестве символов. Этот же алгоритм используется и здесь. Для каждого сегмента вычисляется количество символов в нём. Если он там один — ничего допиливать не нужно, и этот сегмент сразу отправляется>>= в нейросеть. Если же символ там не один, то вдоль сегмента на равных расстояниях расставляются потенциальные разделители. Затем каждый разделитель двигается в своей небольшой окрестности, и попутно вычисляется реакция нейросети на символы около этого разделителя, после чего остаётся лишь выбрать максимум (на самом деле, там всё это делает довольно тупой алгоритм, но, в принципе, всё действительно приблизительно так).
Естественно, участие нейросети в процессе сегментации (или досегментации, если угодно) исключает возможность использовать ту схему обучения нейросети, которую я уже описывал. Если точнее, он не позволяет получить самую первую нейросеть — для обучения других может использоваться она. Поэтому я поступаю довольно просто — использую обычные методы сегментации (проекция) для обучения нейросети, в то время как при её использовании в работу вступает вышеописанный алгоритм.
Есть ещё одна тонкость, связанная с использованием нейросети в этом алгоритме. В предыдущих примерах нейросеть обучалась на почти необработанных результатах препроцесса и сегментации. Здесь это позволяло получить не более 12% успешного распознавания. Меня это категорически не устраивало. Поэтому, прежде чем начинать очередную эпоху обучения нейросети, я вносил в исходные изображения различные искажений, грубо моделирующие реальные: добавить белых/серых/чёрных точек, серых линий/кругов/прямоугольников, повернуть. Также я увеличил trainset с 200 изображений до 300 и добавил так называемый validset для проверки качества обучения во время обучения на 100 изображений. Это позволило добиться увеличения производительности где-то процентов на пять, а вкупе с сегментацией нейросетью как раз и дало тот результат, о котором я говорил в начале статьи.
Предоставление статистики осложнено тем, что у меня в итоге получилось две нейросети: одна давала больший процент распознавания, а другая — меньшую ошибку. Здесь я привожу результаты первой.
Всего, как я уже говорил неоднократно, в testset насчитывалось 100 изображений. Из них успешно распознано было 20, неудачно, соответственно, 80, а ошибка составила 1.91 символа на изображение. Заметно хуже, чем у всех других операторов, но и CAPTCHA соответствующая.
Всё, что относится к этой работе, я выложил в специальной ветке форума на своём сайте, в частности: исходный код, файлы нейросетей и изображения.
Хотелось бы и в следующем году в чём-нибудь поучаствовать — хотя бы в том же Балтийском конкурсе (а после него, желательно, и в Intel ISEF), но творческий кризис даёт о себе знать — не получается придумать вменяемую тему для проекта, а продолжать возиться с капчами нет никакого желания. Возможно, хабрасообщество сможет мне помочь…
Идеи, которые у меня были, но ни одна из которых мне не нравится — эти функциональная ОС и распределённые (и/или анонимные) сети. К сожалению, первое, вероятно, для меня будет слишком сложно (да и кому они нужны, эти функциональные оси?), а второе уже сделано, и сделано неплохо (I2P, Netsukuku). В то же время, хочется чего-то, что, во-первых, возможно сделать за год (хотя бы вдвоём), и во-вторых, серьёзно претендовало бы на высокое место на том же ISEF. Может быть, вы сможете подсказать, в каком направлении мне следует двигаться?
UPD 2015-04-09: репозиторий на Github.
Работа заключалась в распознавании CAPTCHA, используемых крупными операторами сотовой связи в формах отправки SMS, и демонстрации недостаточной эффективности применяемого ими подхода. Чтобы не задевать ничью гордость, будем называть этих операторов иносказательно: красный, жёлтый, зелёный и синий.
Проект получил официальное название Captchure и неофициальное Breaking Defective Security Measures. Любые совпадения случайны.
Как ни странно, все (ну, почти все) эти CAPTCHA оказались довольно слабенькими. Наименьший результат — 20% — принадлежит жёлтому оператору, наибольший — 86% — синему. Таким образом, я считаю, что задача «демонстрации неэффективности» была успешно решена.
Причины выбора именно сотовых операторов тривиальны. Уважаемому Научному Жюри я рассказывал байку о том, что «сотовые операторы имеют достаточно денег, чтобы нанять программиста любой квалификации, и, в то же время, им необходимо минимизировать количество спама; таким образом, их CAPTCHA должны быть довольно мощными, что, как показывает моё исследование, совсем не так». На самом же деле всё было гораздо проще. Я хотел набраться опыта,
Итак, ближе к телу. Никакого мегапродвинутого алгоритма для распознавания всех четырёх видов CAPTCHA у меня нет; вместо него я написал 4 различных алгоритма для каждого вида CAPTCHA по отдельности. Однако, несмотря на то, что алгоритмы в деталях различны, в целом они оказались очень похожими.
Как и многие авторы до меня, я разбил задачу распознавания CAPTCHA на 3 подзадачи: предварительную обработку (препроцесс), сегментацию и распознавание. На этапе препроцесса из исходного изображения удаляются различные шумы, искажения и пр. В сегментации из исходного изображения выделяются отдельные символы и производится из постобработка (например, обратный поворот). При распознавании символы по одному обрабатываются предварительно обученной нейросетью.
Существенно различался только препроцесс. Это связано с тем, что в различных CAPTCHA применяются различные методы искажения изображений, соответственно, и алгоритмы для удаления этих искажений сильно различаются. Сегментация эксплуатировала ключевую идею поиска компонентов связности с незначительными наворотами (значительными их пришлось сделать только у жёлто
Код написан на Python с применением библиотек OpenCV и FANN, которые не ставятся без напильника приличных размеров и бубна впридачу. Поэтому мои результаты будет воспроизвести непросто — по крайней мере, до тех пор, пока авторы вышеупомянутых библиотек не сделают нормальные привязки для Python.
Red
Как я уже сказал, первым кроликом я выбрал именно эту CAPTCHA. Думаю, несколько примеров прояснят ситуацию:


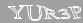
Вот-вот, и мне тоже сначала показалось, что она очень простая… Однако, это впечатление возникло не на пустом месте. Итак:
- Цвета исчерпываются градациями серого, причём символы — светлые, фон — тёмный
- Отсутствует дополнительный шум
- Постоянные искажения (то есть не изменяющиеся от картинки к картинке)
- Символов всегда ровно пять
- Размеры символов приблизительно одинаковы
- Символы почти всегда связны
Казалось, всё это сводит на нет достоинства этой CAPTCHA:
- Слипающиеся буквы
- Мерзкий дырявый шрифт
- Очень маленький размер (83x23 px)
Естественно, эти «достоинства» являются таковыми только с точки зрения сложности автоматического распознавания. В соответствии с трёхэтапной схемой, упомянутой мной ранее, начнём с предварительной обработки изображения, а именно увеличения в 2 раза.


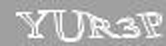
Как я уже упоминал, искажения здесь постоянны, и, даже несмотря на то, что они не являются линейными, избавиться от них нетрудно. Параметры были подобраны эмпирически.




Далее я применяю пороговое преобразование (в народе Threshold) с t=200 и инвертирую изображение:

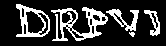

Наконец, белым закрашиваются мелкие (меньше 10px) чёрные связные области:



Далее следует сегментация. Как я уже сказал, здесь применяется поиск компонентов связности:



Иногда (редко, но бывает) буква распадается на несколько частей; для исправления этого досадного недоразумения я применяю довольно простую эвристику, оценивающую принадлежность нескольких компонентов связности к одному символу. Эта оценка зависит только от горизонтального положения и размеров описывающих прямоугольников (bounding boxes) каждого символа.

Нетрудно заметить, что многие символы оказались объединены в один компонент связности, в связи с чем надо их разделять. Здесь на помощь приходит тот факт, что на изображении всегда ровно 5 символов. Это позволяет с большой точностью вычислять, сколько символов находится в каждом найденном компоненте.
Для объяснения принципа работы такого алгоритма придётся немного углубиться в матчасть. Обозначим количество найденных сегментов за n, а массив ширин (правильно сказал, да?) всех сегментов за widths[n]. Будем считать, что если после вышеупомянутых этапов n > 5, изображение распознать не удалось. Рассмотрим все возможные разложения числа 5 на целые положительные слагаемые. Их немного — всего 16. Каждое такое разложение соответствует некоторой возможной расстановке символов по найденным компонентам связности. Логично предположить, что чем шире получившийся сегмент, тем больше символов он содержит. Из всех разложений пятёрки выберем только те, в которых количество слагаемых равно n. Поделим каждый элемент из widths на widths[0] — как бы нормализуем их. То же самое проделаем со всеми оставшимися разложениями — поделим каждое число в них на первое слагаемое. А теперь (внимание, кульминация!) заметим, что получившиеся упорядоченные n-ки можно мыслить как точки в n-мерном пространстве. С учётом этого, найдём ближайшее по Евклиду разложение пятёрки к нормализованному widths. Это и есть искомый результат.
Кстати, в связи с этим алгоритмом мне в голову пришёл ещё один интересный способ искать все разложения числа на слагаемые, который я, правда, так и не реализовал, закопавшись в питоновских структурах данных. Вкратце — он довольно очевидно вылезает, если заметить, что количество разложений определённой длины совпадает с соответствующим уровнем треугольника Паскаля. Впрочем, я уверен, что этот алгоритм давным-давно известен.
Так вот, после определения количества символов в каждом компоненте наступает следующая эвристика — мы считаем, что разделители между символами тоньше, чем сами символы. Для того чтобы воспользоваться этим сокровенным знанием, расставим по сегменту n-1 разделителей, где n — количество символов в сегменте, после чего в небольшой окрестности каждого разделителя посчитаем проекцию изображения вниз. В результате этого проецирования мы получим информацию о том, сколько в каждом столбце пикселей принадлежат символам. Наконец, в каждой проекции найдём минимум и сдвинем разделитель туда, после чего покромсаем изображение по этим разделителям.




Наконец, распознавание. Как я уже говорил, для него я применяю нейросеть. Для её обучения сначала я прогоняю две сотни изображений под общим заголовком trainset через уже написанные и отлаженные первые два этапа, в результате чего получаю папку с большим количеством аккуратно нарезанных сегментов. Затем руками вычищаю мусор (результаты неправильной сегментации, например), после чего результат привожу к одному размеру и отдаю на растерзание FANN. На выходе получаю обученную нейросеть, которая и используется для распознавания. Эта схема дала сбой только один раз — но об этом позже.
В результате на тестовом наборе (не использованном для обучения, кодовое имя — testset) из 100 картинок были правильно распознаны 45. Не слишком высокий результат — его, конечно, можно улучшить, например, уточнив препроцесс или переделав распознавание, но, честно говоря, мне было лень с этим возиться.
Кроме того, я использовал ещё один критерий оценки производительности алгоритма — средняя ошибка. Вычислялся он следующим образом. Для каждого изображения находилось расстояние Левенштейна между мнением алгоритма об этом изображении и правильным ответом — после чего бралось среднее арифметическое по всем изображениям. Для этого вида CAPTCHA средняя ошибка составила 0.75 символа/изображение. Мне кажется, что это более точный критерий, нежели просто процент распознавания.
Кстати говоря, почти везде (кроме жёлтого оператора) у меня использовалась именно такая схема — 200 картинок в trainset, 100 — в testset.
Green
Следующей целью я выбрал зелёных — хотелось взяться за что-то более серьёзное, чем подбор матрицы искажений.

Достоинства:
- Эффект трёхмерности
- Поворот и смещение
- Неравномерная яркость
Недостатки:
- Символы заметно темнее фона
- Верхнюю сторону прямоугольника хорошо видно — можно использовать для обратного поворота
Оказалось, что даже несмотря на то, что эти недостатки, казалось бы, незначительны, их эксплуатация позволяет весьма эффективно расправиться со всеми достоинствами.
Опять начнём с предварительной обработки. Сначала оценим угол поворота прямоугольника, на котором лежат символы. Для этого применим к исходному изображению оператор Erode (поиск локального минимума), затем Threshold, чтобы выделить остатки прямоугольника и, наконец, инверсию. Получим симпатичное белое пятно на чёрном фоне.
Далее начинается глубокая мысль. Первое. Для оценки угла поворота всего прямоугольника достаточно оценить угол поворота его верхней стороны. Второе. Можно оценить угол поворота верхней стороны поиском прямой, параллельной этой стороне. Третье. Для описания любой прямой, кроме строго вертикальной, достаточно двух параметров — смещения по вертикали от центра координат и угла наклона, причём нас интересует только второй. Четвёртое. Задачу поиска прямой можно решить не очень большим перебором — слишком больших углов поворота там не бывает, да и сверхвысокая точность нам не нужна. Пятое. Для поиска необходимой прямой можно сопоставить каждой прямой оценку того, насколько она близка к искомой, после чего выбрать максимум. Шестое. Самое Важное. Чтобы оценить некоторый угол наклона прямой, представим, что изображения сверху касается прямая с таким углом наклона. Понятно, что из размеров изображения и угла наклона можно однозначно вычислить смещение прямой по вертикали, так что она задаётся однозначно. Далее, постепенно будем двигать эту прямую вниз. В какой-то момент она коснётся белого пятна. Запомним этот момент и площадь пересечения прямой с пятном. Напомню, что прямая имеет 8ми-связное представление на плоскости, поэтому гневные выкрики из зала о том, что прямая имеет одно измерение, а площадь — понятие двумерное, здесь неуместны. Затем ещё некоторое время будем двигать эту прямую вниз, на каждом шаге запоминая площадь пересечения, после чего просуммируем полученные результаты. Эта сумма и будет оценкой данного угла поворота.


Подводя итог вышесказанного: будем искать такую прямую, что при движении её вниз по изображению яркость пикселей, лежащих на этой прямой, возрастает наиболее резко.
Итак, угол поворота найден. Но не следует спешить тут же применить полученное знание. Дело в том, что это испорит связность изображения, а она нам ещё понадобится.
Следующий шаг — отделение символов от фона. Здесь нам здорово поможет тот факт, что символы значительно темнее фона. Вполне логичный шаг со стороны разработчиков — иначе картинку было бы очень сложно прочитать. Кто не верит — может попробовать самостоятельно бинаризовать изображение и убедиться воочию.
Однако, подход «в лоб» — попытка отсечь символы пороговым преобразованием — здесь не работает. Наилучший результат, которого мне удалось добиться — при t=140 — выглядит весьма плачевно. Остаётся слишком много мусора. Поэтому пришлось применить обходной путь. Идея здесь следующая. Символы, как правило, связны. Причём им часто принадлежат самые тёмные точки на изображении. А что если попробовать применить заливку из этих самых тёмных точек, а затем выкинуть слишком маленькие залитые области — очевидный мусор?
Результат, честно говоря, поразителен. На большинстве изображений удаётся избавиться от фона полностью. Впрочем, бывает, что символ распадается на несколько частей — в этом случае может помочь один костыль в сегментации — но об этом чуть позже.

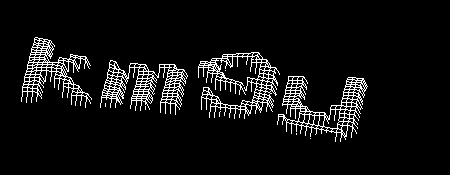
Далее, произведём поворот на найденный ранее угол.


Наконец, комбинация операторов Dilate и Erode избавляет нас от мелких дырок, оставшихся в символах, что помогает упростить распознавание.


Сегментация здесь значительно проще, чем препроцесс. В первую очередь ищем компоненты связности.


Затем объединяем близкие по горизонтали компоненты (процедура ровно та же, что и ранее):


Собственно, всё. Далее следует распознавание, но оно ничем не отличается от вышеупомянутого.
Этот алгоритм позволил достичь результата в 69% успешно распознанных изображений и получить среднюю ошибку 0.3 символа/изображение.
Blue
Итак, третьим статус «defeated» получил синий оператор. Это была, так сказать, передышка перед действительно крупной рыбой…



Здесь сложно что-то записать в достоинства, но я, всё же, попробую:
- Поворот символов — единственное более-менее серьёзное препятствие
- Фоновый шум в виде символов
- Символы иногда касаются друг друга
В противовес этому:
- Фон значительное светлее символов
- Символы хорошо вписываются в прямоугольник
- Разный цвет символов позволяет легко отделять их друг от друга
Итак, препроцесс. Начнём с отсечения фона. Поскольку изображение трёхцветное, порежем его на каналы, а затем выбросим все точки, которые ярче 116 по всем каналам. Получим вот такую симпатичную маску:



Затем преобразуем изображение в цветовое пространство HSV (Википедия). Это сохранит информацию о цвете символов, а заодно и уберёт градиент с их краёв.



Применим к результату полученную ранее маску:



На этом препроцесс заканчивается. Сегментация также весьма тривиальна. Начнём, как всегда, с компонентов связности:




Можно было бы на этом и остановиться, но так получается всего 73%, что меня совсем не устраивает — всего на 4% лучше, чем результат заведомо более сложной CAPTCHA. Итак, следующим шагом будет обратный поворот символов. Здесь нам пригодится уже упомянутый мной факт о том, что местные символы хорошо вписываются в прямоугольник. Идея состоит в том, чтобы найти описывающий прямоугольник для каждого символа, а затем по его наклону вычислить наклон собственно символа. Здесь под описывающим прямоугольником понимается такой, что он, во-первых, содержит в себе все пиксели данного символа, а, во-вторых, имеет наименьшую площадь из всех возможных. Я пользуюсь готовой реализацией алгоритма поиска такого прямоугольника из OpenCV (MinAreaRect2).

Дальше, как всегда, следует распознавание.
Этот алгоритм успешно распознаёт 86% изображений при средней ошибке в 0.16 символа/изображение, что подтверждает предположение о том, что эта CAPTCHA — действительно самая простая. Впрочем, и оператор не самый крупный…
Yellow
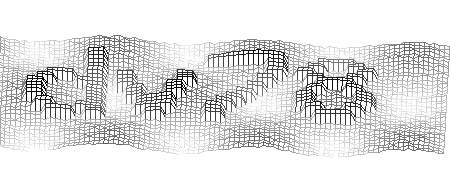
Наступает самое интересное. Так сказать, апофеоз моей творческой деятельности :) Эта CAPTCHA — действительно самая сложная как для компьютера, так и, к сожалению для человека.



Достоинства:
- Шум в виде пятен и линий
- Поворот и масштабирование символов
- Близкое расположение символов
Недостатки:
- Очень ограниченная палитра
- Все линии очень тонкие
- Пятна часто не пересекаются с символами
- Угол поворота всех символов приблизительно одинаков
Над первым шагом я думал долго. Первое, что приходило в голову — поиграться с локальными максимумами (Dilate), чтобы удалить мелкий шум. Однако, такой подход приводил к тому, что и от букв мало что оставалось — только рваные очертания. Проблема усугублялась тем, что текстура самих символов неоднородная — это хорошо видно при большом увеличении. Чтобы от неё избавиться, я решил выбрать самый тупой способ — открыл Paint и записал коды всех цветов, встречающихся в изображениях. Оказалось, что всего в этих изображениях встречаются четыре различных текстуры, причём на три из них приходится по 4 различных цвета, а на последнюю — 3; более того, все компоненты этих цветов оказались кратными 51. Далее я составил таблицу цветов, при помощи которой удалось избавиться от текстуры. Впрочем, перед этим «ремапом» я ещё затираю все слишком светлые пиксели, которые обычно находятся по краям символов — иначе приходится помечать их как шум, а потом с ними бороться, в то время как информации в них содержится немного.
Итак, после этого преобразования на изображении находится не более 6 цветов — 4 цвета символов (будем их условно называть серым, синим, светло-зелёным и тёмно-зелёным), белый (цвет фона) и «неизвестный», обозначающий, что цвет пикселя на его месте не удалось отождествить ни с одним из известных цветов. Называть условно — потому что к этому моменту я избавляюсь от трёх каналов и перехожу к привычному и удобному монохромному изображению.



Следующим шагом стала очистка изображения от линий. Здесь ситуацию спасает тот факт, что эти линии очень тонкие — всего 1 пиксель. Напрашивается простой фильтр: пройтись по всему изображению, сравнивая цвет каждого пикселя с цветами его соседей (парами — по вертикали и горизонтали); если соседи по цвету совпадают, и при этом не совпадают с цветом самого пикселя — сделать его таким же, как и соседи. Я применяю чуть более навороченную версию того же фильтра, который работает в два этапа. На первом он оценивает соседей на расстоянии 2, на втором — на расстоянии 1. Это позволяет добиться вот такого эффекта:

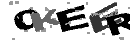

Далее я избавляюсь от большинства пятен, а также от «неизвестного» цвета. Для этого я сначала ищу все мелкие связные области (меньшие 15 по площади, если быть точным), наношу их на чёрно-белую маску, после чего результат объединяю с областями, занятыми «неизвестным» цветом.


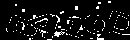
При помощи этих масок я натравливаю на изображение алгоритм Inpaint (а точнее, его реализацию в OpenCV). Это позволяет весьма эффективно вычистить большую часть мусора из изображения.



Однако, реализация этого алгоритма в OpenCV была создана для работы с фотографиями и видео, а не распознавания искусственно созданных изображений с зашумлённым текстом. После его применения появляются градиенты, чего хотелось бы избежать, чтобы упростить сегментацию. Таким образом, приходится производить дополнительную обработку, а именно — повышение резкости. Для цвета каждого пикселя я вычисляю ближайший к нему из вышеупомянутой таблицы (напомню, там 5 цветов — по одному на каждую из текстур символов и белый).



Наконец, последним шагом препроцесса будет удаление всех оставшихся мелких связных областей. Появляются они после применения Inpaint, поэтому никакого повторения здесь нет.



Переходим к сегментации. Её сильно усложняет тот факт, что символы находятся очень близко друг к другу. Может случиться такая ситуация, что за одним символом не видно половину другого. Совсем плохо становится, когда эти символы ещё и одного цвета. Кроме того, остатки мусора также играют свою роль — может случиться так, что на исходном изображении линии в большом количестве пересекались в одном месте. В этом случае тот алгоритм, который я описал ранее, окажется неспособным от них избавиться.
После недели, проведённой в бесплодных попытках написать сегментацию так же, как и в предыдущих случаях, я забил на это дело и сменил тактику. Моя новая стратегия заключалась в том, чтобы разделить весь процесс сегментации на две части. В первой оценивается угол поворота символов и выполняется обратный поворот. Во второй из уже развёрнутого изображения заново выделяются символы. Итак, приступим. Начнём, как всегда, с поиска компонентов связности.



Затем нужно оценить угол поворота каждого символа. Ещё при работе с оператором-фанатом-гринписа я придумал алгоритм для этого, но написал и применил его только здесь. Для того чтобы проиллюстрировать его работу, проведу аналогию. Представьте себе поршень, который движется на чёрно-белое изображение символа снизу вверх. Ручка поршня, за которую его толкают, расположена вертикально, рабочая площадка, которой он толкает — горизонтально, параллельно нижней части изображения и перпендикулярно ручке. Ручка прикреплена к площадке посередине, и в месте присоединения находится подвижное сочленение, в результате чего площадка может поворачиваться. Да простят меня специалисты по терминологии.
Пусть ручка двигается вверх, толкая перед собой площадку по законам физики. Будем считать, что материальным является только белое изображение символа, а сквозь чёрный фон поршень с лёгкостью проходит. Тогда поршень, дойдя до белого цвета, начнёт с ним взаимодействовать, а именно, поворачиваться — при условии, что сила к ручке всё ещё прикладывается. Остановиться он может в двух случаях: если он упёрся в символ по обе стороны от точки приложения силы, или если он упёрся в символ самой точкой приложения силы. Во всех остальных случаях он сможет продолжать движение. Внимание, кульминация: будем считать, что угол поворота символа — это угол наклона поршня в тот момент, когда он остановился.

Этот алгоритм довольно точен, но заведомо слишком большие результаты (больше 27 градусов) я не учитываю. Из оставшихся я нахожу среднее арифметическое, после чего целиком всё изображение поворачиваю на минус этот угол. Затем выполняю поиск компонентов связности ещё раз.
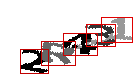


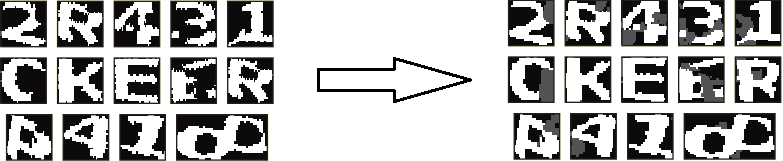
Дальше становится всё интереснее и интереснее. В предыдущих примерах я начинал различные махинации с полученными сегментами, после чего передавал их нейросети. Здесь всё иначе. Сначала, для того чтобы хотя бы частично восстановить информацию, утраченную после разделения изображения на компоненты связности, я на каждом из них тёмно-серым цветом (96) дорисовываю «фон» — то, что было рядом с вырезанным сегментом, но в него не попало, после чего сглаживаю очертания символов, применяя ту же процедуру, что и в препроцессе для линий (с расстоянием до соседа, равным единице).
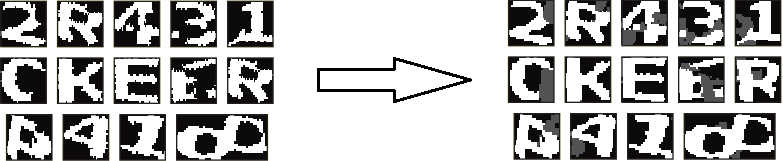
Формально (с точки зрения модулей программы) здесь сегментация заканчивается. Внимательный читатель, должно быть, заметил, что нигде не упоминалось разделение слипшихся символов. Да, это так — на распознавание я их передаю именно в таком виде, а допиливаю уже на месте.
Причина заключается в том, что тот метод разделения слипшихся символов, который был описан ранее (с наименьшей проекцией) здесь не работает — шрифт выбран авторами весьма удачно. Поэтому приходится применять другой, более сложный подход. В основе этого подхода лежит идея, что нейросеть можно использовать для сегментации.
В самом начале я описывал алгоритм, позволяющий найти количество символов в сегменте при известой ширине этого сегмента и общем количестве символов. Этот же алгоритм используется и здесь. Для каждого сегмента вычисляется количество символов в нём. Если он там один — ничего допиливать не нужно, и этот сегмент сразу отправляется
Естественно, участие нейросети в процессе сегментации (или досегментации, если угодно) исключает возможность использовать ту схему обучения нейросети, которую я уже описывал. Если точнее, он не позволяет получить самую первую нейросеть — для обучения других может использоваться она. Поэтому я поступаю довольно просто — использую обычные методы сегментации (проекция) для обучения нейросети, в то время как при её использовании в работу вступает вышеописанный алгоритм.
Есть ещё одна тонкость, связанная с использованием нейросети в этом алгоритме. В предыдущих примерах нейросеть обучалась на почти необработанных результатах препроцесса и сегментации. Здесь это позволяло получить не более 12% успешного распознавания. Меня это категорически не устраивало. Поэтому, прежде чем начинать очередную эпоху обучения нейросети, я вносил в исходные изображения различные искажений, грубо моделирующие реальные: добавить белых/серых/чёрных точек, серых линий/кругов/прямоугольников, повернуть. Также я увеличил trainset с 200 изображений до 300 и добавил так называемый validset для проверки качества обучения во время обучения на 100 изображений. Это позволило добиться увеличения производительности где-то процентов на пять, а вкупе с сегментацией нейросетью как раз и дало тот результат, о котором я говорил в начале статьи.
Предоставление статистики осложнено тем, что у меня в итоге получилось две нейросети: одна давала больший процент распознавания, а другая — меньшую ошибку. Здесь я привожу результаты первой.
Всего, как я уже говорил неоднократно, в testset насчитывалось 100 изображений. Из них успешно распознано было 20, неудачно, соответственно, 80, а ошибка составила 1.91 символа на изображение. Заметно хуже, чем у всех других операторов, но и CAPTCHA соответствующая.
Вместо заключения
Всё, что относится к этой работе, я выложил в специальной ветке форума на своём сайте, в частности: исходный код, файлы нейросетей и изображения.
Хотелось бы и в следующем году в чём-нибудь поучаствовать — хотя бы в том же Балтийском конкурсе (а после него, желательно, и в Intel ISEF), но творческий кризис даёт о себе знать — не получается придумать вменяемую тему для проекта, а продолжать возиться с капчами нет никакого желания. Возможно, хабрасообщество сможет мне помочь…
Идеи, которые у меня были, но ни одна из которых мне не нравится — эти функциональная ОС и распределённые (и/или анонимные) сети. К сожалению, первое, вероятно, для меня будет слишком сложно (да и кому они нужны, эти функциональные оси?), а второе уже сделано, и сделано неплохо (I2P, Netsukuku). В то же время, хочется чего-то, что, во-первых, возможно сделать за год (хотя бы вдвоём), и во-вторых, серьёзно претендовало бы на высокое место на том же ISEF. Может быть, вы сможете подсказать, в каком направлении мне следует двигаться?
UPD 2015-04-09: репозиторий на Github.
