 Всем доброго времени суток!
Всем доброго времени суток!Сегодня я расскажу вам об одной интересной структуре данных, про которую слышали лишь немногие и про которую очень незаслуженно мало написано в рунете, да и в англоязычном информации, в общем-то, тоже негусто. Решено было исправить ситуацию и поделиться с общественностью в доступной форме этой достаточно экзотической структурой данных.
Дерево ван Эмде Боаса (van Emde Boas tree) — ассоциативный массив, который позволяет хранить целые числа в диапазоне [0; U), где U = 2k, проще говоря, числа, состоящие не более чем из k бит. Казалось бы, зачем нужно еще какое-то дерево, да еще позволяющее хранить только целые числа, когда существует множество различных сбалансриованных двоичных деревьев поиска, позволяющих выполнять операции вставки, удаления и прочие за O(log n), где n — количество элементов в дереве?
Главная особенность этой структуры — выполнение всех операций за время O(log(log(U))) независимо от количества хранящихся в ней элементов.
Собственно, вот небольшой список поддерживающихся операций:
- Insert(x) — Вставка числа в дерево
- Remove(x) — Удаление числа
- GetMin(), GetMax() — Нахождение минимума и максимума в дереве
- Find(x) — Поиск числа в дереве
- FindNext(x) — Поиск следующего числа после x, которое содержится в дереве
- FindPrevious(x) — Поиск предшествующего x числа
Итак, приступим к построению нашей структуры, причем строить ее будем рекурсивно.
Пусть k-дерево будет хранить числа в интервале [0; 2k), то есть, состоящие из k бит. При этом само число k будет степенью двойки, позже будет понятно, зачем нам необходимо такое условие. Тогда очевидно, как построить 1-дерево, оно будет лишь хранить информацию о том, существуют ли числа 0 или 1 в нем или нет.
Теперь построим k-дерево. В нем будет храниться:
- 2k / 2 штук (k / 2)-дервьев
- Вспомогательное (k / 2)-дерево
- Минимальное и максимальное число, содержащееся в этом дереве (если оно не является пустым)
Представим теперь, что мы пытаемся вставить число x, состоящее из k бит в k-дерево, содержащее поддеревья children[0..2k / 2 — 1]. Например, пусть x = 93. Посмотрим на его двоичное представление:
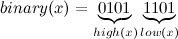
Разобъем наше число на две равных части high и low, каждая по (k / 2) бит. Вспоминаем, что в нашем дереве содержится 2k / 2 деревьев, которые хранят числа из (k / 2) бит. А теперь возьмем из всех этих деревьев high-тое по счету (т. е. children[high]) и рекурсивно вставим в него число low.
Таким образом получаем простой алгоритм вставки и поиска в дереве T числа x, псевдокод:
insert(T, x):
if T.k == 1:
T.exist[x] = True # обрабатываем отдельно случай вставки в 1-дерево
else:
insert(T.children[high(x)], low(x))
find(T, x):
if T.k == 1:
return T.exist[x]
else:
return find(T.children[high(x)], low(x))
Оценим асимптотически время работы этих функций. Пусть T(k) — количество операций, требующихся для вставки/поиска числа в k-дереве. Для вставки/поиска в 1-дереве нам необходимо O(1) операций, получаем, что T(1) = O(1). Если же мы рассмотрим k-дерево (k > 1), то получим, что распил числа с помощью битовых операций в нем происходит за O(1), после чего мы выполняем операцию вставки/поиска для (k / 2)-дерева, получаем, что T(k) = O(1) + T(k / 2). Очевидное решение этого уравнения T(k) = O(log(k)) = O(log(log(U)). Получается, что мы добились требуемой асимптотики для вставки и поиска.
К сожалению, такая структура с одними лишь операциями вставки, поиска и удаления, мягко говоря, в большинстве случаев бессмысленна, учитывая то, что в данном случае проще было создать обычный массив A, в x-ом элементе которого хранится, существует ли число x в нашем множестве или нет.
Пришло время исправлять ситуацию! Для этого реализуем, скажем, операцию FindNext(x). Напомню, что эта операция ищет минимальное число q, содержащееся в нашем дереве, такое, что q >= x.
Для этого немного дополним нашу структуру. Напомню, что в самом начале я сказал, что мы будем хранить в k-дереве не только 2k / 2 штук (k / 2)-деревьев, но минимум в нём, максимум и еще одно вспомогательное (k / 2)-дерево, назовем его aux (от англ. auxiliary — вспомогательный). Чем же оно будет нам так помогать?
Возьмем k-дерево с его поддеревьями children[0..2k / 2 — 1] и вспомогательным деревом aux. В aux мы будем хранить все такие числа p, что дерево children[p] не является пустым, т. е. содержит хотя бы одно число. Соответственно, если p-ое дерево children[p] является пустым, то число p не содержится в aux.
Также, произведем незначительную модификацию: для любого дерева T мы не будем хранить минимальное число в его поддеревьях T.children, будем просто записывать его в переменную T.min. Когда в запросе вставки нам придется вставить в него число x, меньшее, чем T.min, то так как T.min не содержится в наших поддеревьях, вставим его в поддеревья, после чего присвоим T.min = x.
Заметим, что теперь мы не будем отдельно рассматривать случай k = 1, так как у нас присутствуют переменные T.min и T.max. И если, скажем, 1-дерево содержало числа 0 и 1, то у него просто будет T.min = 0, а T.max = 1. Если же, например, оно содержало только число 1, то у него будет T.min = T.max = 1.
Теперь рассмотрим алгоритм вставки в дерево с учетом всего вышеперечисленного:
insert(T, x):
if T.is_empty():
T.min = T.max = x
else:
if x < T.min:
swap(x, T.min) # мы не храним минимум в поддеревьях, придется вставить старый минимум
if x > T.max:
T.max = x
if T.k != 1: # если это 1-дерево, то не имеет смысла дальше что-то пропихивать
if T.children[high(x)].is_empty():
insert(T.aux, high(x)) # если так, то следующий insert выполнится за O(1)
insert(T.children[high(x)], low(x))
Асимптотика времени его работы будет все так же O(log(log(U))), она оценивается аналогично предыдущей версии функции insert. Необходимо лишь заметить, что если мы выполним вставку в aux, то следующий за ним insert будет работать за O(1), так как это поддерево будет пустым.
Функция поиска немного поменяется:
find(T, x):
if T.is_empty():
return False
else if T.min == x or T.max == x: # условие T.max == x можно было и не добавлять
return True
else:
return find(T.children[high(x)], low(x))
Теперь рассмотрим функцию FindNext(x), вот её псевдокод с комментариями:
find_next(T, x):
if T.is_empty() or x > T.max:
return None # следующего числа за x в этом дереве не существует
if x <= T.min:
return T.min # так как оно минимальное, оно и будет следующим
if T.k == 1: # рассмотрим случай 1-дерева
if T.max == x:
return T.max
else:
return None
if not T.children[high(x)].is_empty() and low(x) <= T.children[high(x)].max:
# случай, когда число, которое мы ищем, начинается на high(x)
return merge(high(x), find_next(T.children[high(x)], low(x)))
else:
# иначе найдем первое возможное начало числа, которое мы ищем
next_high = find_next(aux, high(x) + 1) # найдем следующее непустое поддерево
if next_high != None:
return merge(next_high, T.children[next_high].min) # дерево непусто, возьмем его минимум
return None
merge(high, low):
return результат склеивания (k / 2)-битовых чисел high и low
Асимптотика её работы, очевидно, O(log(log(U)).
Думаю, написание таких функций как Remove, FindPrevious и прочих не должно вызвать особого труда, ибо пишутся они все аналогично, поэтому их псевдокод я опущу.
Применение
Кроме очевидного применения дерева ван Эмде Боаса можно придумать множество неожиданных, например:
Сортировка последовательности из N чисел за O(n * log(log(U)))
Действительно, вставим все наши числа в дерево. После чего возьмем минимальное число в дереве и будем последовательно выполнять операцию x = FindNext(x + 1), в результате чего в переменной x побывают все наши числа в отсортированном порядке. Заметим, что можно написать различные реализации этой сортировки, в том числе и те, которая заодно удаляет повторяющиеся элементы. Основное приемущество этой сортировки в том, что по асимптотике этот алгоритм обгоняет даже цифровую сортировку.
Нахождение наидлиннейшей возрастающей подпоследовательности за O(n * log(log(U)))
Некоторые наверняка слышали о такой задаче, как нахождение НВП и ее решении за O(n * log(n)). Для тех, кто не слышал, могут прочитать об этом здесь. Основная идея оптимизации заключается в том, что бинарный поиск в массиве можно заменить на операцию FindPrevious в дереве ван Эмде Боаса.
Алгоритм Дейкстры за O(E * log(log(U)))
Для тех, кто не знаком с алгоритмом Дейкстры поиска кратчайшего пути во взвешенном графе, предлагаю ознакомиться с этой, а также с этой статьей. Реализация алгоритма Дейкстры с помощью кучи, как известно, работает за O(E * log(V)), где V — количество вершин, а E — количество ребер. Но если теперь вместо кучи применить всем нам уже известную структуру данных, то получим асимптотику O(E * log(log(U))), что не может не радовать.
- И еще много-много задач, количество которых ограничено лишь вашей фантазией :)
Минус всех этих алгоримтов заключается в том, что для слишком больших U дерево ван Эмде Боаса будет занимать большее количество памяти (грубая оценка — O(U)), чего, впрочем, можно попытаться частично избежать, создавая необходимые поддеревья «лениво», то есть только тогда, когда они нам потребуются.
Вместо заключения
Здесь находится моя реализация дерева ван Эмде Боаса на C++. Она не претендует на безупречность, но свою работу должна выполнять. Дополнения и комментарии приветствуются.
Всем спасибо за внимание!
