«Преждевременная оптимизация есть корень всех зол»
Энтони Хоар
 Приветствую всех пользователей Хабра!
Приветствую всех пользователей Хабра!
Данная статья возникла как полезный побочный продукт моих научных изысканий. Буду рад, если идеи, изложенные ниже, покажутся для вас интересными и полезными, а еще лучше, если получат своё применение и дальнейшее развитие в реально существующих проектах.
Производительность программного обеспечения (ПО) является важным аспектом в разработке любого программного продукта. Актуальность вопроса объясняется постоянно возрастающей сложностью и значимостью программных средств. Особое внимание производительности уделяется:
Понятие производительности с точки зрения ПО означает либо продуктивность, либо реактивность:
При анализе ПО самой очевидной и логичной задачей, стоящей перед исследователем будет увеличение производительности. Формально, мы имеем задачу оптимизации, а в контексте данного исследования – задачу минимизации времени обработки входящей информации программной системой. Таким образом, критерием оптимизации является некоторая функция
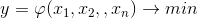 , где (1)
, где (1)
Для примера рассмотрим программу, работающую с базой данных (БД), и производящую статистическую обработку хранимой в ней информации. Примерами влияющих на производительность факторов могут быть:
Для поиска оптимальных значений влияющих факторов, т.е. для решения задачи оптимизации (1) можно предложить следующие варианты:
 , где (2)
, где (2)
 комбинаций.
комбинаций.
При случайном выборе оптимальной комбинации велика вероятность того, что полученное решение будет очень далеко от глобального оптимума.
Аналитическое исследование системы часто или сложно или невозможно при анализе уже существующих продуктов, без исходного кода. К тому же, подобный подход требует полного понимания исследователем всех используемых в ПО алгоритмов, связей и зависимостей компонентов.
Специальные программные средства, такие как профилировщики [5] позволяют получить лишь некоторую статистическую информацию о выполнении программного кода: число вызовов методов, среднее время выполнения методов и т.д. Оптимизация в данном случае сводится к выявлению т.н. «узких мест» и оптимизации используемых алгоритмов. Подобный подход является достаточно популярным, но не позволяет получить искомое решение задачи (1).
Математические модели анализа производительности ПО неоднократно рассматривались зарубежными и отечественными авторами. Так в работах [1], [2] предложены оригинальные подходы к решению этой задачи на разных этапах разработки ПО.
Подводя итог, следует отметить, что основными недостатками предложенных методов решения являются:
Остановимся подробнее на вопросе применимости МПЭ к анализу производительности ПО. Одна из основных идей планирования эксперимента состоит в использовании для исследуемого объекта кибернетической абстракции черного ящика [3] (см. рис. 1).

Рис. 1. Абстракция черного ящика.
Такая абстракция предполагает отказ от рассмотрения внутренних механизмов исследуемого явления или объекта из-за большой сложности. Анализ явления сводится к анализу входящих параметров, воздействующих на объект (факторов) и выходных характеристик (откликов) [3].
Для применимости МПЭ необходимо соблюдение ряда условий [3]:
В качестве примера и для отработки методики использования МПЭ для анализа производительности программной системы рассмотрим web-приложение, являющееся частью проекта «Профессиональные клубы» [4].
При анализе априорной информации о программном продукте стало известно:
 уравнения регрессии
уравнения регрессии
 . (3)
. (3)
Факторы с самыми большими значениями будут наибольшим образом влиять на выходную характеристику.
В таблице 1 представлен набор влияющих факторов, выбранных в результате анализа априорной информации о ПО.
Таблица 1.
Теперь необходимо выбрать верхний и нижний уровень для каждого фактора[3]. Здесь и далее будем использовать обозначения, принятые в МПЭ:
В таблице 3 представлены результаты проведения серии экспериментов.
Таблица 3.
Коэффициенты уравнения регрессии (3) могут быть найдены как
 . (4)
. (4)
Результаты представлены в таблице 4 и на рис. 2.
Таблица 4.
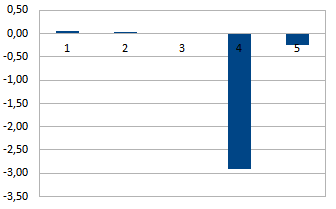
Рис. 2. Коэффициенты уравнения регрессии.
Из рис. 2 видно, что основной вклад в время генерации web-страницы вносит фактор , характеризующий кэширование данных в приложении. Отрицательное значение коэффициента регрессии
, характеризующий кэширование данных в приложении. Отрицательное значение коэффициента регрессии  означает, что данный параметр уменьшает функцию отклика черного ящика. В нашем примере это означает уменьшение времени генерации страницы.
означает, что данный параметр уменьшает функцию отклика черного ящика. В нашем примере это означает уменьшение времени генерации страницы.
Строго говоря, такие результаты являются очевидными, так как включение кэширования данных приложением влечет за собой минимальное число запросов к СУБД. Таким образом, влияние параметров настройки СУБД становится несущественным. Полученные результаты подтверждают возможность использования МПЭ применительно к анализу производительности ПО.
В данной статье я попытался рассмотреть возможность применения существующего уже давно метода математического планирования эксперимента применительно к анализу производительности ПО. Такой подход позволяет преодолеть ряд трудностей, возникающих при анализе программных систем, выявить факторы, наиболее сильно влияющие на анализируемую характеристику, выявить зависимости между факторами.
Разумеется, представленная методология не претендует на замену существующих методов анализа производительности, например, профилирования. Однако существует ряд задач, в которых применение подобной техники способно существенно облегчить задачи исследователя.
Спасибо за внимание!
Энтони Хоар
 Приветствую всех пользователей Хабра!
Приветствую всех пользователей Хабра!Данная статья возникла как полезный побочный продукт моих научных изысканий. Буду рад, если идеи, изложенные ниже, покажутся для вас интересными и полезными, а еще лучше, если получат своё применение и дальнейшее развитие в реально существующих проектах.
Производительность программного обеспечения (ПО) является важным аспектом в разработке любого программного продукта. Актуальность вопроса объясняется постоянно возрастающей сложностью и значимостью программных средств. Особое внимание производительности уделяется:
- в инженерных и научных разработках, где часто производятся сложные длительные вычисления, а процессорное время на кластерных системах дорого и ограничено;
- в web-приложениях, в которых время генерации страницы критично для пользователя и напрямую зависит от объемов серверных мощностей;
- в встраиваемых программных продуктах, и т.д.
Понятие производительности с точки зрения ПО означает либо продуктивность, либо реактивность:
- продуктивность – объем информации, обрабатываемой системой в единицу времени;
- реактивность – время между предъявлением системе входных данных и появлением соответствующей выходной информации.
При анализе ПО самой очевидной и логичной задачей, стоящей перед исследователем будет увеличение производительности. Формально, мы имеем задачу оптимизации, а в контексте данного исследования – задачу минимизации времени обработки входящей информации программной системой. Таким образом, критерием оптимизации является некоторая функция
, где (1) – время обработки информации;
– время обработки информации; – все параметры (факторы или влияющие факторы), которые прямым или косвенным образом могут влиять на производительность системы;
– все параметры (факторы или влияющие факторы), которые прямым или косвенным образом могут влиять на производительность системы; – область определения i-го фактора, являющаяся ограничением задачи.
– область определения i-го фактора, являющаяся ограничением задачи.
Для примера рассмотрим программу, работающую с базой данных (БД), и производящую статистическую обработку хранимой в ней информации. Примерами влияющих на производительность факторов могут быть:
- объем оперативной памяти компьютера;
- скорость доступа к жесткому диску;
- максимальная частота работы и средняя загрузка процессора;
- настройки СУБД, и т.д.
Для поиска оптимальных значений влияющих факторов, т.е. для решения задачи оптимизации (1) можно предложить следующие варианты:
- полный перебор всех возможных комбинаций значений влияющих факторов;
- случайный выбор некоторого числа комбинаций и последующий выбор самого лучшего варианта;
- аналитическое исследование системы;
- применение специализированных программных средств;
- использование математических моделей.
, где (2) – число вариантов значений i-го фактора.
– число вариантов значений i-го фактора.
комбинаций.При случайном выборе оптимальной комбинации велика вероятность того, что полученное решение будет очень далеко от глобального оптимума.
Аналитическое исследование системы часто или сложно или невозможно при анализе уже существующих продуктов, без исходного кода. К тому же, подобный подход требует полного понимания исследователем всех используемых в ПО алгоритмов, связей и зависимостей компонентов.
Специальные программные средства, такие как профилировщики [5] позволяют получить лишь некоторую статистическую информацию о выполнении программного кода: число вызовов методов, среднее время выполнения методов и т.д. Оптимизация в данном случае сводится к выявлению т.н. «узких мест» и оптимизации используемых алгоритмов. Подобный подход является достаточно популярным, но не позволяет получить искомое решение задачи (1).
Математические модели анализа производительности ПО неоднократно рассматривались зарубежными и отечественными авторами. Так в работах [1], [2] предложены оригинальные подходы к решению этой задачи на разных этапах разработки ПО.
Подводя итог, следует отметить, что основными недостатками предложенных методов решения являются:
- чрезмерно большое время проведения измерений;
- опора на способности исследователя, делающего выводы на основе анализа программы;
- сложность применения и использования.
Остановимся подробнее на вопросе применимости МПЭ к анализу производительности ПО. Одна из основных идей планирования эксперимента состоит в использовании для исследуемого объекта кибернетической абстракции черного ящика [3] (см. рис. 1).

Рис. 1. Абстракция черного ящика.
Такая абстракция предполагает отказ от рассмотрения внутренних механизмов исследуемого явления или объекта из-за большой сложности. Анализ явления сводится к анализу входящих параметров, воздействующих на объект (факторов) и выходных характеристик (откликов) [3].
Для применимости МПЭ необходимо соблюдение ряда условий [3]:
- воспроизводимость опытов;
- управляемость факторов;
- измеримость выходных характеристик и возможность выразить её одним числом;
- однозначность и совместимость факторов и т.д.
В качестве примера и для отработки методики использования МПЭ для анализа производительности программной системы рассмотрим web-приложение, являющееся частью проекта «Профессиональные клубы» [4].
Этап 1. Анализ априорной информации.
При анализе априорной информации о программном продукте стало известно:
- ПО является web-приложением, написанным на языке программирования PHP;
- ПО выполняется на web-сервере Apache, интерпретатор PHP подключен в качестве модуля;
- ПО использует СУБД MySQL для хранения данных;
- существует возможность включения кэширования данных средствами самого приложения.
уравнения регрессии. (3)Факторы с самыми большими значениями будут наибольшим образом влиять на выходную характеристику.
Этап 2. Выбор влияющих факторов.
В таблице 1 представлен набор влияющих факторов, выбранных в результате анализа априорной информации о ПО.
Таблица 1.
| Фактор | Описание |
|---|---|
 |
MySQL key_buffer_size Параметр настройки СУБД, определяющий объем памяти, выделенной для хранения индексов [6]. |
 |
MySQL table_cache Параметр настройки СУБД, определяющий число постоянно открытых таблиц базы данных [6]. |
 |
MySQL query_cache_limit Параметр настройки СУБД, определяющий максимальный объем памяти для кэширования результатов запросов [6]. |
|
Кэширование данных приложением. Может быть или включено или выключено. |
 |
Web-сервер и метод запуска интерпретатора PHP. Исследуемое приложение способно запускаться двумя способами:
|
Этап 3. Выбор верхнего и нижнего уровня для факторов.
Теперь необходимо выбрать верхний и нижний уровень для каждого фактора[3]. Здесь и далее будем использовать обозначения, принятые в МПЭ:
- +1 соответствует верхнему уровню фактора;
- -1 соответствует нижнему уровню фактора.
| Фактор | Верхний уровень (+1) | Нижний уровень (-1) |
|---|---|---|
|
265 Mb. | 16 Mb. |
|
300 | 64 |
|
64 Mb. | 1 Mb. |
|
Кэш включен. | Кэш выключен. |
|
Nginx + php-fpm. | Apache + mod_php. |
Этап 4. Составление матрицы планирования и проведение экспериментов.
В таблице 3 представлены результаты проведения серии экспериментов.
Таблица 3.
| № | |
|
|
|
|
y | № | |
|
|
|
|
y |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | -1 | -1 | -1 | -1 | -1 | 6,909456902 | 17 | +1 | -1 | -1 | -1 | -1 | 6,956250343 |
| 2 | -1 | -1 | -1 | -1 | +1 | 6,265920885 | 18 | +1 | -1 | -1 | -1 | +1 | 6,27117213 |
| 3 | -1 | -1 | -1 | +1 | -1 | 1,046864681 | 19 | +1 | -1 | -1 | +1 | -1 | 1,049605346 |
| 4 | -1 | -1 | -1 | +1 | +1 | 0,959287777 | 20 | +1 | -1 | -1 | +1 | +1 | 0,960128005 |
| 5 | -1 | -1 | +1 | -1 | -1 | 6,922491238 | 21 | +1 | -1 | +1 | -1 | -1 | 6,94905457 |
| 6 | -1 | -1 | +1 | -1 | +1 | 6,292138541 | 22 | +1 | -1 | +1 | -1 | +1 | 6,288483698 |
| 7 | -1 | -1 | +1 | +1 | -1 | 1,047327693 | 23 | +1 | -1 | +1 | +1 | -1 | 1,048429732 |
| 8 | -1 | -1 | +1 | +1 | +1 | 0,959178464 | 24 | +1 | -1 | +1 | +1 | +1 | 0,959984639 |
| 9 | -1 | +1 | -1 | -1 | -1 | 6,947828159 | 25 | +1 | +1 | -1 | -1 | -1 | 6,944574752 |
| 10 | -1 | +1 | -1 | -1 | +1 | 6,269961421 | 26 | +1 | +1 | -1 | -1 | +1 | 6,281574535 |
| 11 | -1 | +1 | -1 | +1 | -1 | 1,047032595 | 27 | +1 | +1 | -1 | +1 | -1 | 1,047937875 |
| 12 | -1 | +1 | -1 | +1 | +1 | 0,960076244 | 28 | +1 | +1 | -1 | +1 | +1 | 0,960813348 |
| 13 | -1 | +1 | +1 | -1 | -1 | 6,954160943 | 29 | +1 | +1 | +1 | -1 | -1 | 6,952602925 |
| 14 | -1 | +1 | +1 | -1 | +1 | 6,278223336 | 30 | +1 | +1 | +1 | -1 | +1 | 6,284795263 |
| 15 | -1 | +1 | +1 | +1 | -1 | 1,048019483 | 31 | +1 | +1 | +1 | +1 | -1 | 1,047952991 |
| 16 | -1 | +1 | +1 | +1 | +1 | 0,960559206 | 32 | +1 | +1 | +1 | +1 | +1 | 0,960591927 |
Этап 5. Анализ результатов.
Коэффициенты уравнения регрессии (3) могут быть найдены как
. (4)Результаты представлены в таблице 4 и на рис. 2.
Таблица 4.
 |
 |
 |
 |
 |
 |
|---|---|---|---|---|---|
| 3,97361211 | 0,0519711 | 0,0245041 | 0,0034686 | -2,9182692 | -0,2483070 |
Рис. 2. Коэффициенты уравнения регрессии.
Этап 6. Вывод.
Из рис. 2 видно, что основной вклад в время генерации web-страницы вносит фактор
, характеризующий кэширование данных в приложении. Отрицательное значение коэффициента регрессии означает, что данный параметр уменьшает функцию отклика черного ящика. В нашем примере это означает уменьшение времени генерации страницы.Строго говоря, такие результаты являются очевидными, так как включение кэширования данных приложением влечет за собой минимальное число запросов к СУБД. Таким образом, влияние параметров настройки СУБД становится несущественным. Полученные результаты подтверждают возможность использования МПЭ применительно к анализу производительности ПО.
В данной статье я попытался рассмотреть возможность применения существующего уже давно метода математического планирования эксперимента применительно к анализу производительности ПО. Такой подход позволяет преодолеть ряд трудностей, возникающих при анализе программных систем, выявить факторы, наиболее сильно влияющие на анализируемую характеристику, выявить зависимости между факторами.
Разумеется, представленная методология не претендует на замену существующих методов анализа производительности, например, профилирования. Однако существует ряд задач, в которых применение подобной техники способно существенно облегчить задачи исследователя.
Спасибо за внимание!
Список литературы
- Дубаков С.А. Информационная технология анализа производительности в процессе разработки программного обеспечения: дис. канд. техн. наук / Дубаков С.А. – Томск, 2005. – 135 с.
- Мойсейчук Л.Д. Разработка моделей и методов анализа производительности программного обеспечения на основе строго иерархических стохастических сетей Петри: дис. канд. техн. наук / Мойсейчук Л.Д. – Санкт-Петербург, 2002. – 152 с.
- Адлер Ю.П., Маркова Е.В., Грановский Ю.В. Планирование эксперимента при поиске оптимальных условий. – М.: Наука, 1976. – 279 с.
- ООО «Профессиональные Клубы». – URL:http://prof-club.ru/. Дата обращения: 25.09.2011.
- Касперски К. Техника оптимизации программ. Эффективное использование памяти. – СПб.: БХВ-Петербург, 2003. – 464 с.
- MySQL Server System Variables. – URL:http://dev.mysql.com/doc/refman/5.0/en/server-system-variables.html. Дата обращения: 25.09.2011.
