
Tsung — это распределенная система нагрузочного тестирования, написанная на Erlang'е. Заявлена поддержка HTTP, WebDAV, SOAP, PostgreSQL, MySQL, LDAP and XMPP/Jabber. В этой статье я опишу как протестировать обычный web сайт на нагрузку.
Почему Tsung
Во первых это приложение бесплатно. Во вторых приложение написано на Erlang'e, что дает ему преимущество перед другими продуктами, в способности симулировать огромное количество одновременных запросов.
Установка
Для установки вам потребуется Linux дистрибутив, я использовал debian. Необходимо проделать следующую последовательность действий:
- apt-get install erlang
- apt-get install gnuplot-nox libtemplate-perl libhtml-template-perl libhtml-template-expr-perl
- Скачать последнюю версию tsung-1.4.1.tar.gz
- Распаковать tar -zxvf tsung-1.4.1 .tar.gz
- Установить ./configure && make && make install
- Также необходимо создать каталог с именем .tsung в root директории и конфигурационный файл tsung.xml внутри него (подробнее о нем ниже)
Вот и все установка завершена!
Настройка
Все настройки хранятся в xml файле tsung.xml. Прежде всего нужно указать тестируемый сервер, следующим образом:
<servers>
<server host="example.com" port="80" type="tcp"></server>
</servers>
Далее адрес эмулируемого клиента, для масштабных тестов рекомендуется менять порог maxusers:
<clients>
<client host="localhost" use_controller_vm="true" maxusers="7000"/>
</clients>
И самое интересное, желаемая нагрузка. Tsung симулирует посещения юзеров. Следующий пример иллюстрирует 2 фазы. Первая длится 5 минут и каждую секунду сайт посещает 10 новых пользователей, итого 5 минут x 10 юзеров/сек = 3000 юзеров. Вторая фаза еще более повышает нагрузку и длится 10 минут, каждую секунду приходит 25 юзеров, в сумме 15 000 юзеров.
<load>
<arrivalphase phase="1" duration="5" unit="minute">
<users arrivalrate="10" unit="second"/>
</arrivalphase>
<arrivalphase phase="2" duration="10" unit="minute">
<users arrivalrate="25" unit="second"/>
</arrivalphase>
</load>
Вместо arrivalrate можно также использовать
<users interarrival="2" unit="second"/>Следующий этап наиболее важен, это создание последовательности действий которую будет проделывать симулируемый юзер, так называемой сессии. Чтобы наиболее полно протестировать возможности сайта, нужно стараться чтобы юзеры постоянно что то делали, то есть не простаивали.
<sessions>
<session name="rec20111101-1537" probability="100" type="ts_http">
<request><http url="/test/test.html" version="1.1" method="GET"/></request>
<request><http url="/css/global_mainPage.css" version="1.1" method="GET"/></request>
...
<thinktime random="true" value="15"/>
</session>
<session>
....
</session>
<sessions>
Автоматическая генерация сессии
Сессию можно создавать вручную, но есть более простой способ — использовать прокси tsung'а для записи ваших действий на сайте. Для этого нужно только прописать в настройках вашего браузера ip сервера где установлен tsung и порт 8090. Далее необходимо выполнить команду tsung-recorder start побродить по сайту, сэмулировать поведение обычного посетителя. Чтобы остановить запись tsung-recorder stop. После этого сгенерированная последовательность появится в ~/.tsung/tsung_recorderyyyymmdd-HH:MM.xml. Далее неоходимо просто скопировать эту сессию в основной файл tsung.xml.
Запуск
Вот наконец когда проделаны все подготовительные действия можно и запустить наш тест. Для этого необходимо ввести команду tsung start , для остановки соответственно tsung stop. Tsung будет записывать log в каталог ~/.tsung/log/yyyymmdd-HH:MM. Очень важный момент при масштабных тестах, перед запуском установить значение ulimit больше стандартного в моем случае 1024, ulimit -n 100000. Для просмотра статуса о количестве юзеров на сайте, можно использовать команду tsung status. Сгенерированный лог помещается в каталог .tsung/log/yyyymmdd-HH:MM.
Генерация отчета и диаграмм
Для генерации отчетов используется скрипт на perl идущий вместе с программой — tsung_stats.pl. Скрипт необходимо запускать из директории с логом, командой perl tsung_stats.pl. После чего сгенерируется замечательный html отчет и диаграммы.
Tsung предоставляет статистику:
- Производительность: время ответа, время присоединения, транзакции, запросы в секунду
- Ошибки: статистика по возвращенным ошибкам
- Поведение сервера: График занятости CPU и памяти, сети. SNMP
Вот пример одной из диаграмм (количество юзеров на сайте, и количество сгенерированных юзеров):
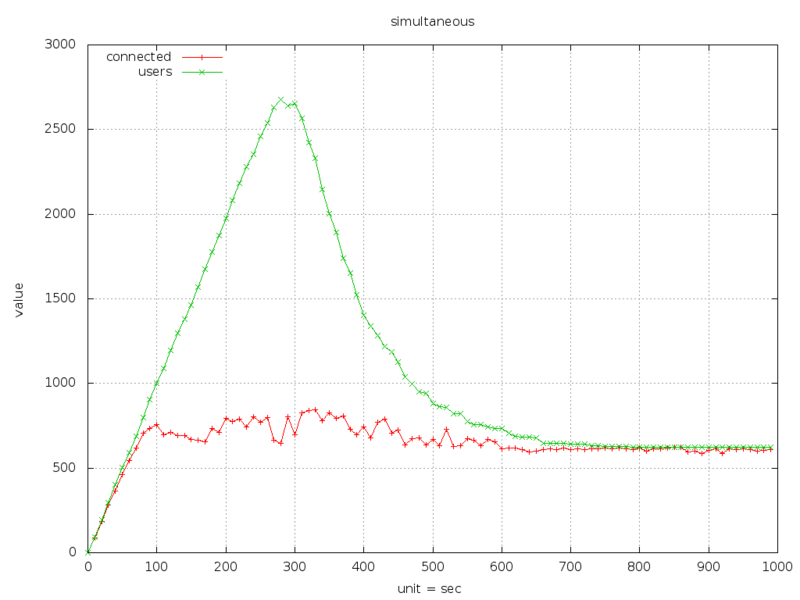
Больше диаграмм на сайте разработчиков
Источники:
Руководство Tsung
