Железо и рендеринг
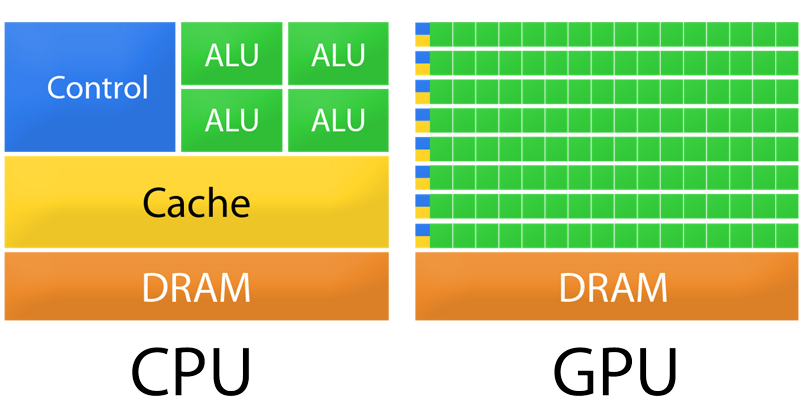
Наиболее популярные, на сегодняшний день, архитектуры процессоров — x86-64. Их относят к CISC. Они обладают огромным набором команд, что привело к большой площади ядра на кристалле. Это, в свою очередь, повлекло за собой сложность в реализации нескольких ядер на чипе. Процессоры x86 не идеальны для многопоточных вычислений, где требуются многократное выполнение небольшого набора команд (RISC).
В свою очередь, рендеринг — алгоритм, который отлично распараллеливается практически на неограниченное количество ядер.
Unbiased renders
В виду того, что производительность железа неуклонно растет — технические вопросы (например семплинг отражений материалов в V-Ray, количество биасов при антиалиасинге, размытии в движении, глубине резкости, мягких тенях) все больше переходят на плечи железа. Так, несколько лет назад появился первый коммерческий рендер «без допущений» (unbiased render) — Maxwell Render.
Основным его преимуществом было качество финальной картинки, минимум настроек, всевозможных «биасов». С течением времени качество картинки приближается к «идеальному». А недостатком было и есть — время рендеринга. Ждать, пока шум сойдет, приходилось очень долго, и многие люди после нескольких проб сразу от него отказались. Еще хуже обстояли дела с анимацией (по понятным причинам).
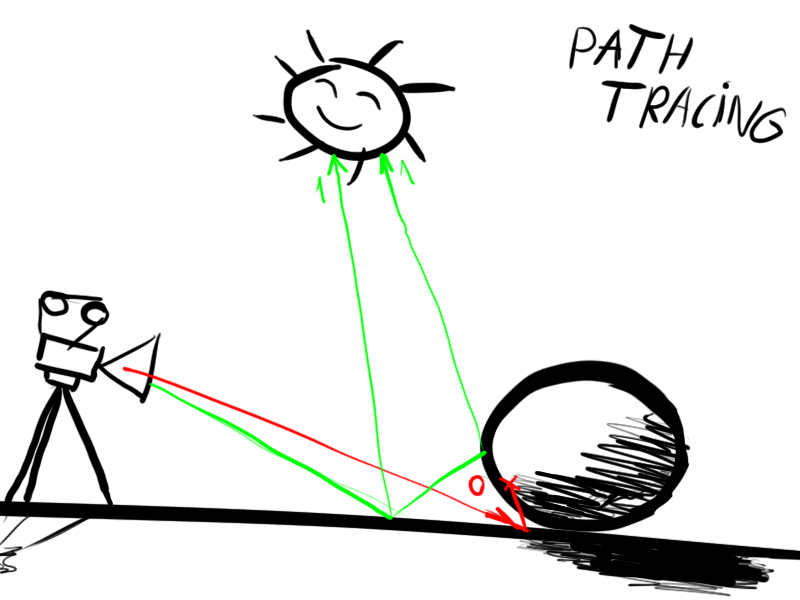
Алгоритм
1. Луч (начальная точка, соответствующая определенному пикселю на экране) выпускается из камеры.
2. Проверить, пересек ли луч один из элементов геометрии. Если нет, то перейти к п.1.
3. Определить ближайшую к камере точку пересечения луча и геометрии.
4. Выпустить из точки пересечения новый луч по направлении к источнику света.
5. Если есть препятствие у луча между точкой пересечения и источником света, то перейти к п.7
6. Закрасить пиксель цветом (упрощенно, цветом поверхности в данной точке, умноженной на интенсивность источника света в точке соприкосновения с лучем)
7. Выпустить из точки пересечения новый луч в произвольном направлении, перейти к п.2, пока не достигнуто максимальное количество отражений (в большинстве случаев 4-8, если в сцене много отражений или преломлений — то надо увеличить это число).

Пример «шумной» картинки.
Количество выборок на пиксель для достижения хорошего качества может измеряться тысячами. К примеру, 10 тысяч (зависит от сцены)
Количество лучей на изображение FullHD 2мпикс*10тыс — 20 млрд.
Существуют несколько видов оптимизации трассировки пути: Bi-Directional Path Tracing, Metropolis Light Transport, Energy Redistribution Path Tracing, призванные пускать лучи «куда надо». Большинство рендеров на CPU используют для этой цели алгоритм MLT (Maxwell, Fry, Lux)
Роль GPU
В алгоритме многократно используются операции с плавающей точкой, и многопоточность для этого алгоритма жизненно необходима. Поэтому эту задачу постепенно принимается себя GPU.
Существующие технологии: CUDA, FireStream, OpenCL, DirectCompute, а также есть возможность написания программ непосредственно на шейдерах.
Ситуация обстоит так:
CUDA – пишут все, кому не лень (iRay, Octane Render, Arion Render, Cycles, etc).
FireStream – вообще ничего не видно.
OpenCL – SmallLuxGPU, Cycles, Indigo Render. Похоже, никто всерьез не принимает.
DirectCompute – ничего не видно.
Шейдеры — только один пример. WebGL реализация трассировки пути на шейдерах.
Сравнение рендеров будет в части 2.
Наиболее популярные, на сегодняшний день, архитектуры процессоров — x86-64. Их относят к CISC. Они обладают огромным набором команд, что привело к большой площади ядра на кристалле. Это, в свою очередь, повлекло за собой сложность в реализации нескольких ядер на чипе. Процессоры x86 не идеальны для многопоточных вычислений, где требуются многократное выполнение небольшого набора команд (RISC).
В свою очередь, рендеринг — алгоритм, который отлично распараллеливается практически на неограниченное количество ядер.
Unbiased renders
В виду того, что производительность железа неуклонно растет — технические вопросы (например семплинг отражений материалов в V-Ray, количество биасов при антиалиасинге, размытии в движении, глубине резкости, мягких тенях) все больше переходят на плечи железа. Так, несколько лет назад появился первый коммерческий рендер «без допущений» (unbiased render) — Maxwell Render.
Основным его преимуществом было качество финальной картинки, минимум настроек, всевозможных «биасов». С течением времени качество картинки приближается к «идеальному». А недостатком было и есть — время рендеринга. Ждать, пока шум сойдет, приходилось очень долго, и многие люди после нескольких проб сразу от него отказались. Еще хуже обстояли дела с анимацией (по понятным причинам).
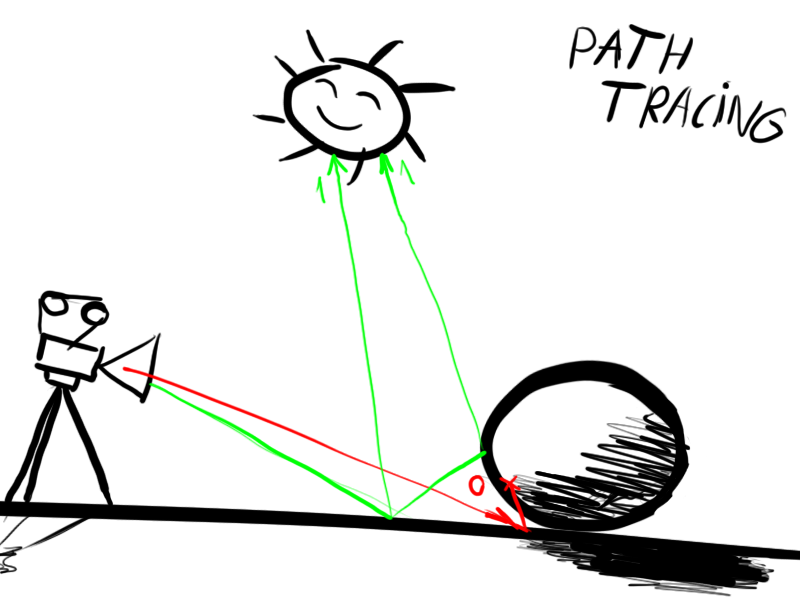
Алгоритм
1. Луч (начальная точка, соответствующая определенному пикселю на экране) выпускается из камеры.
2. Проверить, пересек ли луч один из элементов геометрии. Если нет, то перейти к п.1.
3. Определить ближайшую к камере точку пересечения луча и геометрии.
4. Выпустить из точки пересечения новый луч по направлении к источнику света.
5. Если есть препятствие у луча между точкой пересечения и источником света, то перейти к п.7
6. Закрасить пиксель цветом (упрощенно, цветом поверхности в данной точке, умноженной на интенсивность источника света в точке соприкосновения с лучем)
7. Выпустить из точки пересечения новый луч в произвольном направлении, перейти к п.2, пока не достигнуто максимальное количество отражений (в большинстве случаев 4-8, если в сцене много отражений или преломлений — то надо увеличить это число).

Пример «шумной» картинки.
Количество выборок на пиксель для достижения хорошего качества может измеряться тысячами. К примеру, 10 тысяч (зависит от сцены)
Количество лучей на изображение FullHD 2мпикс*10тыс — 20 млрд.
Существуют несколько видов оптимизации трассировки пути: Bi-Directional Path Tracing, Metropolis Light Transport, Energy Redistribution Path Tracing, призванные пускать лучи «куда надо». Большинство рендеров на CPU используют для этой цели алгоритм MLT (Maxwell, Fry, Lux)
Роль GPU
В алгоритме многократно используются операции с плавающей точкой, и многопоточность для этого алгоритма жизненно необходима. Поэтому эту задачу постепенно принимается себя GPU.
Существующие технологии: CUDA, FireStream, OpenCL, DirectCompute, а также есть возможность написания программ непосредственно на шейдерах.

Ситуация обстоит так:
CUDA – пишут все, кому не лень (iRay, Octane Render, Arion Render, Cycles, etc).
FireStream – вообще ничего не видно.
OpenCL – SmallLuxGPU, Cycles, Indigo Render. Похоже, никто всерьез не принимает.
DirectCompute – ничего не видно.
Шейдеры — только один пример. WebGL реализация трассировки пути на шейдерах.
Сравнение рендеров будет в части 2.
