Предисловие
Я уже долгое время ничего не исследую, так сказать ушел на покой. Но тут мне на глаза попалась очередная поделка немало известного в определенных кругах PE_Kill'a. Т.к. мне довелось решать его предыдущую поделку в рамках CRACKL@B Contest 2010, которая в свою очередь была довольно интересна, я решил взглянуть на его новое «детище».
Что вас ждет под катом: подделка CRC32, брут ключа для RC4, факторизация для RSA, а также использование коллизии для MD4 и генерация двух разных сообщений с одинаковыми хешеми. Всё это и многое другое под катом.
Статья рассчитана не на новичка, я не буду разжевывать все действия. Целью которой является написание кейгена.
Введение
Как уже говорилось выше, я долгое время не занимался ресёчем. Потому пришлось потратить некоторое время на «раскачку». Также частично восстановить свой инструментарий, т.к. у меня осталась только OllyDbg и IDA. Последнее использоваться не будет. И вспоминая его задание с контеста, я ждал чего-то интересного, что заставит меня активизировать свой мозг намного больше чем обычно. И я не ошибся.
В бой
Получение разведданных
Ну, для начала нам понадобится сам crackme. Открываем его в Ollydbg и видим, что он упакован с помощью UPX, ну им сейчас вряд ли кого испугаешь. Я пошел по пути наименьшего сопротивления, и распаковал его при помощи QUnpack. Далее следуя своей технике выработанной годами, я решил проанализировать его на использование различных крипто, хеш, чексум алгоритмов. Для этого я воспользовался SnD Reverser Tool, которая мне сообщила, что нашла CRC32, RC4, MD4. Теперь зная всё это можно приступить к более активным действиям.
В тылу врага
Итак, закончив статический анализ, переходим к динамическому анализу, т.е. айда дебажить. Снова открываем crackme (далее — крякми) в OllyDbg (далее — олька), но уже не оригинал, а распакованный. Жмем Ctrl+G и вводим GetDlgItemTextA, так мы перейдем к началу этой функции, ставим точку остановки и запускаем его. Вводим имя и некую лицензию для теста и нажимаем Check. Вот мы и стали по нашей точке остановки, жмем Alt+F9 и попадаем в код нашего крякми сразу после вызова функции получения имени.
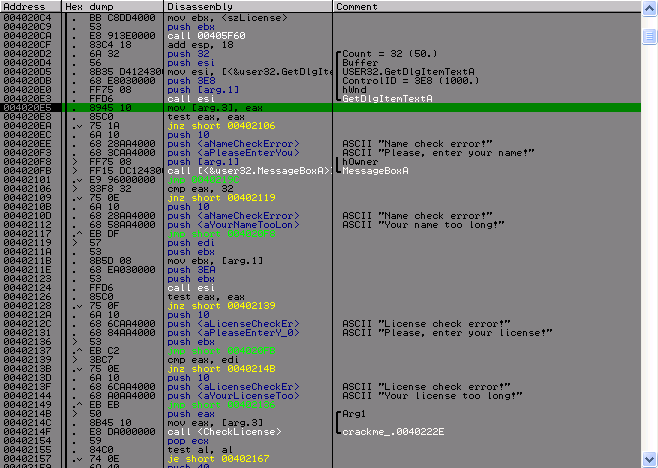
После чего идут две проверке длины имени, первая это на то, что имя было введено, а вторая бессмысленная. Во второй проверки, если длина имени равна 50 нам сообщается, что имя длинное и выходим. Почему она бессмысленная, а потому что имя получается следующим образом:
GetDlgItemTextA(hDlg, IDC_NAME, szName, 50);
А это значит, что максимум оно может считать строку длиной не больше 50 символов, где 50-ый символ – это символ конца строки, и того мы имеем, что длина строки никогда не будет превышать 49 символов. Точно тоже и с лицензией, но это не критично. После всего этого идет заветная функция, в которой и происходит всё самое интересное, я назвал ее – CheckLicense.
Во вражеских окопах
И так мы в самом сердце. Первые пару функций это перевод символов лицензии в верхний регистр, а далее перевод лицензии в массив байт и там уже идет проверка на длину лицензии.
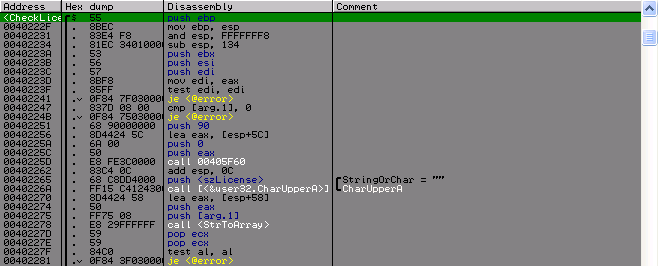
В функции перевода строки будет видно, что она проверяет лицензию на соответствие алфавиту (0–9, A-F), т.е. лицензия это какой-то массив данных, переведенный в хекс строку, и в конце проверяется, не равна ли длина полученного массива 0×90 байт. Отсюда следует, что лицензия должна иметь длину 0×90 * 2 = 0×120 (288) символов.
После всего этого возвращаемся в основную функцию. Далее идет подсчет контрольной сумы первых 0×8С байт этого массива (далее этот массив будем называть — лицензия) с 4 байтовым числом, которое находится в конце лицензии.

А далее идет 10 кругов манипуляций с именем, результат каждого круга помещается в отдельный элемент массива 4-х байтовых чисел. Забегая наперед скажу, что этот массив будет ключом для RC4, поэтому буду называть его ключом.
Round 0–2:

Все круги кроме Round1 используются один раз, потому и воспринялись компилятором как инлайн-функции, а вот сам round1 будет еще использоваться в конце дважды как некая функция для получения контрольной сумы данных.
Round 3–4:
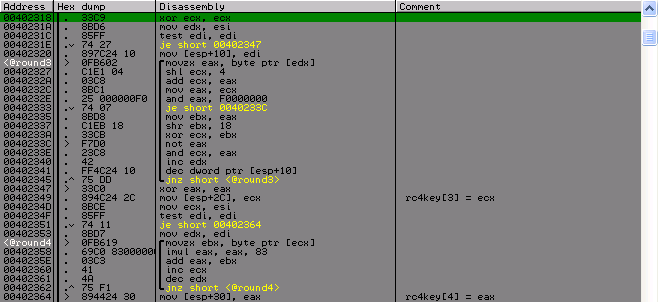
Round 5–7:
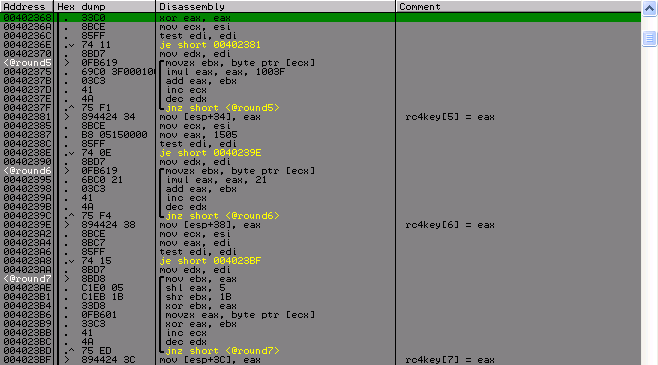
Round 8–9:

Как вы могли заметить, что round9 идентичен подсчету контрольной сумы лицензии, которая была в самом начале.
После всего этого с ключа несложными манипуляциями находим значения для последующего ксора этого же ключа. Также это значение будет использоваться еще в одной проверке после расшифровки тех самых первых 0×8С байт лицензии с помощью RC4 и с ключом, которое мы получили с имени. И еще в одной манипуляции, результата которой нам понадобится дальше.
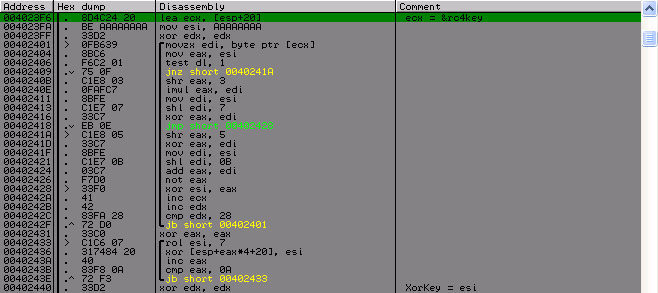
Дальше получаем еще два значения, которые нам понадобятся дальше. С XorKey получим количество бит для сдвига, а с ключа нужный байт, который мы должны получить при сдвиги определенного значения на то количество бит, что получили выше. Ну и собственно сама расшифровка по RC4. Как я определил, что это именно оно, ну, во-первых я знаю список возможных алгоритмов, которые тут используются, во вторых по алгоритму инициализации ключа, кто не раз встречал этот алгоритм, тоже думаю, что быстро бы узнали его.
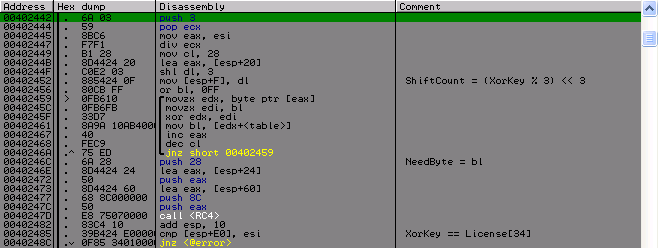
А вот и та проверка, где было нужно это значение. После расшифровки у нас должен находится в License[34] (если рассматривать лицензию как массив 4-х байтоных значений, что мы и будем дальше делать) значение идентичное XorKey. На этом заканчивается самая легкая часть в этом крякми. На то, что идет дальше мне потребовалось значительно больше времени и усилий.
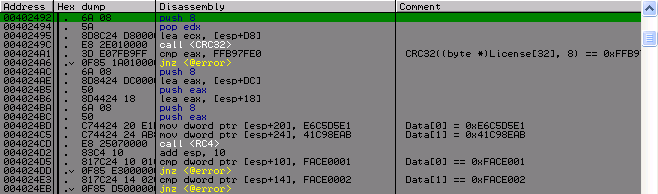
Дальше идет подсчет CRC32 8 байт лицензии, которое должно равняться 0xFFB97FE0. Если всё проходит, то дальше эти 8 байт служат ключом для расшифровки двух захардкоденых значений по алгоритму RC4 и на выходе должны получить два фейса. Итак, вот первое интересное место, что есть в крякми. Погуглив я не нашел коллизий для RC4, которые бы мне помогли найти ключ, потому было принято решение брутить. Но брутить в лоб 8 байтов это немного глупо и долго. Хорошо, что я уже имел дело с подделкой CRC32 и я понял в какую сторону шагать. Для тех кто не в курсе, то в пару словах это звучит так – «с любых данных можно получить нужное нам CRC32, достаточно только дописать/заменить 4 нужных байта». Подробно об этом можно почитать тут. Отсюда имеем, что теперь нужно брутить не 8 байт, а 4, что значительно облегчает нам жизнь. Я решил не писать заумных брутеров с использованием разных технологий, многопоточности, распараллеливания вычислений. Я написал простой однопоточный брутер, который на моем AMD II X2 250 нашел ключ за 15 минут.
Вот так выглядит мой брутер:
int main() { uint32_t key[2] = {0, 0}; uint8_t *pkey = (uint8_t *)&key; rc4_key skey; uint32_t rc4_data[2]; do { fix_crc_end(pkey, 8, 0xFFB97FE0); prepare_key(pkey, 8, &skey); rc4_data[0] = 0xE6C5D5E1; rc4_data[1] = 0x41C98EAB; rc4((uint8_t *)rc4_data, 8, &skey); if (rc4_data[0] == 0xFACE0001 && rc4_data[1] == 0xFACE0002) { printf("Key: "); for (int i = 0; i < 8; i++) { printf("%02X", *pkey++); } printf("\n"); break; } } while (key[0]++ <= 0xFFFFFFFF); printf("\n\n\t\tFin!\n"); return 0; }
Я нашел правильный ключ, теперь я могу генерировать ключи, которые будут проходить все выше пройдённые проверки. Зная всё это можно представить общий вид лицензии:
typedef struct _LICENSE { unsigned char M1[0x40]; unsigned char M2[0x40]; unsigned int FaceKey1; unsigned int FaceKey2; unsigned int AfterXorKey; unsigned int LicenseCheckSum; } LICENSE, *LPLICENSE;
Последние 4 значения уже разобраны, остается только первые 0×80 байт лицензии, забегая немного наперед скажу, что это два сообщения по 0×40 байт.
После фейсов сразу идет вызов функции, в которую передается указатель на лицензию, у меня она уже подписана как RSA. Я постараюсь немного объяснить, как я это понял. После входа внутрь этой функции идут подряд 3 одинаковых функции, в которые передается указатель на массив данных, его размер и указатель на буфер с результатом. Эта функция читает с массива побайтово и в обратном порядке, т.е. от последнего элемента массива к первому. Это очень похоже на инициализацию больших чисел. Это первое, что пришло мне в голову.

Второй вызов этой функции только подтвердил мою догадку, когда я посмотрел в дамп на массив, с которого идет инициализация, я увидел эти заветные три байта 01 00 01. Это значение очень часто используется как экспонента в реализации RSA-расшифровке. Отсюда следует, что первая функция инициализировала открытый ключ N. После чего я его выдернул с дампа и факторизовал, для факторизации я использовал msieve под GPU. Ключ небольшой, всего 256 бит на его факторизацию ушло чуть более 4 минут.
Я раньше всегда старался придерживаться правила, что в кейгене нужно использовать такие же библиотеки и классы, что и в жертве. Поэтому я решил поискать подсказок, что за библиотека для больших чисел была использована. Немного потрейсив наткнулся вот на такое сообщение, вбив текст сообщения в гугл быстро нашел библиотеку, которая используется, ей оказалась BigDigits.

После идет проверка на то что бы 6 элемент первого сообщения равнялся такому же элементу второго. А также чтобы это значение при сдвиги вправо на ShiftCount бит имело младший байт такой же, как и NeedByte. Все эти два значения мы получали выше.
После этого идет проверка на то, что CRC32 первого и второго сообщения не были равны, дальше такое же сравнение только функцией round1. После того ка всё разобрано можно увидить, что в этой части крякми вроде нет ничего особенного, также как и в следующей.
И в самом конце находятся MD4 хеши первого и второго сообщения, и если они равны, то мы удачно прошли проверку. Но подождите, если эти сообщения должны иметь разную контрольную суму по двум функциям значит сообщения должны быть разными, но при этом они должны иметь одинаковые хеши, что тут не вяжется.
И тут в игру снова вступает гугл с запросом «md4 collisions», и правда инфа по коллизиям для MD4 есть, и разная, есть статьи объемные, а есть поверхностные. И в одной с этих статей нахожу, что китайцы смогли создать два разных сообщения по 0×40 байт с одинаковыми хешами, вот оно. Теперь идем в гугл со следующем запросом «md4 collisions sources» и правда, есть исходники нахождения двух таких сообщений, но они были написаны под линукс, где функция random возвращает 4-х байтовое число, а в винде rand возвращает всего от 0 да RAND_MAX (32767). Из-за чего у меня и были долго проблемы, почему оно генерит мне неправильные сообщения. После подсказки я переписал функцию random с Delphi, и всё заработало на ура.
Пишем кейген
Я не буду описывать все шаги в написании кейгена, а только обращу внимание на некоторые важные моменты. Сперва создаем ключ для RC4 с имени, это я опущу, там нет ничего сложного, для ленивых можно просто всю эту часть рипнуть. Дальше нужно найти значение для ксора ключа и поксорить сам ключ, после чего с этого значения найти ShiftCount и NeedByte. Эту часть тоже можно рипнуть, для нахождения нужного байта нужно еще рипнуть таблицу размерностью 256 байт. Записываем XorKey значение в лицензию согласно структуры, которая приведенна выше. Также можно записать два значения, которые являются ключом для нахождения фейсов, они будут постоянны и одинаковы для всех. После чего нужно сгенерировать два сообщения, но дело в том, что там, если вы помните, 6 элемент должен иметь определенный формат. Сама функция генерирование сообщений не имеет никаких параметров, но так как нужно передать в нее два значения, это ShiftCount и NeedByte. Меняем прототип и дописываем еще пару строк в сам код этой функции. Было:
if(X0[ 5] != X1[ 5]) continue;
А стало:
if(X0[ 5] != X1[ 5]) continue; else if (((X0[5] >> c) & 0xFF) != b) continue;
где c – ShiftCount, b – NeedByte.
После чего сообщения помещаются в Х0 и Х1 соответственно. Дальше соединяем эти сообщение в одно большое и засовываем его в RSACrypt. Сама расшифровка идет блоками по 0×20 байт, поэтому так и будем шифровать. Но вот из-за этого тоже было у меня проблем, кто не знает, то сообщение (М – наш блок в 0×20 байт) должен быть меньше открытого ключа (N), в крякми это не учитывается, и он расшифровывает всё подряд. Поэтому это должны учесть мы. Я добавил проверку в функцию шифровки, если N < M, то выходим и генерируем новые сообщения, из-за чего время генерации лицензии затягивается до 15 секунд. После того как всё удачно зашифровали по RSA шифруем всю лицензию без последнего значения в структуре с помощью RC4 с ключом, которое получили с имени. И последний шаг – это подсчет контрольной сумы той части лицензии, что зашифровали по RC4 и запись его в последние значение структуры и перевод всей этой лицензии хекс-строку.
Вот и всё!
Материалы
• www.rsdn.ru/article/files/classes/SelfCheck/crcrevrs.pdf – подделка CRC32
• www.en.wikipedia.org/wiki/MD4#Collision_Attacks – MD4 коллизии
• www.google.com
• www.wikipedia.org
Исходники
• github.com/reu-res/Keygen-for-CrackMe-1-by-PE_Kill – Брутер и кейген
P.S. Кейген принимает кириллицу, но это зависит от того как настроена консоль. У меня лично не принимала с консоли, а если захардкодить, то всё отлично. Мне лениво было переписывать под окошки.
