Введение
Добрый день.
В заключительной части про написание собственного генератора LALR-парсеров я бы хотел описать возможные особенности и фичи. Кроме того я опишу чего мне не хватало в существующих решениях и ради чего я начал писать свой велосипед.
Дабы задать контекст, сообщу, что грамматика для анализа — это ECMAScript, так же известный как JavaScript. Конкретная спецификация — ECMA-262, редакция 5.1 от июня 2011 года.
Когда я впервые столкнулся с сложностями написания, я не сразу бросился писать код компилятора. Вначале я изучил как решили данные проблемы крупные компании: Mozilla и Google (исходников Opera и IE — нету в открытом доступе). Как оказалось, они не особо парились с формализацией грамматики и писали код как есть, то есть так, как я предостерегал делать в первой части. Пример обработки if'a в v8 (JS-движок Chrome):
IfStatement* Parser::ParseIfStatement(ZoneStringList* labels, bool* ok) {
// IfStatement ::
// 'if' '(' Expression ')' Statement ('else' Statement)?
Expect(Token::IF, CHECK_OK);
Expect(Token::LPAREN, CHECK_OK);
Expression* condition = ParseExpression(true, CHECK_OK);
Expect(Token::RPAREN, CHECK_OK);
Statement* then_statement = ParseStatement(labels, CHECK_OK);
Statement* else_statement = NULL;
if (peek() == Token::ELSE) {
Next();
else_statement = ParseStatement(labels, CHECK_OK);
} else {
else_statement = factory()->NewEmptyStatement();
}
return factory()->NewIfStatement(condition, then_statement, else_statement);
}
Зачем они так сделали? Есть несколько причин:
- Скорость работы. Хотя и FSM очень быстр, но «линейное» исполнение всё же быстрее.
- Гибкость. То что не использовался bison/ANTLR/boost::spirit/собственная разработка косвенно утведрило меня в той мысли, что не всё так просто с этой грамматикой и не я один напоролся на ограничения.
- Они не разработчики языка с нуля (как с Dart'ом, к примеру), поэтому достаточно один раз написать и забыть на пару лет до новых изменений в стандарте. Из этого следует то, что изменения в грамматике не проводятся каждый день.
Конечно, есть и ряд минусов:
- 5-10 тысяч строк кода только на парсинг это многовато.
- Без спецификации не прожить. Так как код очень разрознен, то схему языка очень трудно собрать в систему с нуля только по исходникам.
- Обработка ошибок раздувает код, несмотря на хитрые макросы:
#define CHECK_OK ok); \ if (!*ok) return NULL; \ ((void)0
Требования к парсеру/генератору парсеров
Теперь можно и перейти к тем подводным камням грамматики и моим ожиданиям. Сразу скажу, что некоторые пункты вполне выполняются сторонним софтом. Но в сумме нет целостной программы, да и есть пункты, на которые я не нашёл решения.
Комментарии полезны!
В своей задаче мне нужно было сохранить текст и позицию комментариев, а не отбрасывать их. ANTLR и bison/flex это умеют. Первый за счет мультиплексирования лексера, второй — за счет мощности flex'a. Так как писать свой лексер я пока не начал, я использую flex. И решил данную задачу следующим образом:
/* [Comment] = [MultiLineComment] | [SingleLineComment] */
/* [MultiLineComment] */
/* start of multiline, grab whole comment, that's why i use yymore() */
"/*" {
BEGIN(multilinecomment);
yymore();
m_loc.setMore(true);
}
/* skip all comments chars except "*" */
<multilinecomment>[^*\n\r]* { yymore(); }
/* skip all "*", that not followed by "/" */
<multilinecomment>"*"+[^*/\n\r]* { yymore(); }
/* end of comment */
<multilinecomment>"*"+"/" {
m_comments.push_back(CParser::Comment(yytext, m_loc.tokenLine(), m_loc.tokenCol()));
m_loc.setMore(false);
BEGIN(INITIAL);
}
/* [SingleLineComment] increment lineNo */
("//"([^\r\n])*{LineTerminator})|("//"([^\r\n])*) {
m_comments.push_back(CParser::Comment(yytext, m_loc.tokenLine(), m_loc.tokenCol()));
m_loc.linc();
}
Ничего особенного здесь нет. Используем внутренние состояния лексера и yymore() который позволяет создать целостную лексему из нескольких правил.
Режимы работы лексера, контролируемые парсером
JS имеет особую форму задания reg-exp'ов. Их можно писать просто так в исходном коде, и сигналом является "/". Но одновременно это еще и знак деления. Соответственно и поток лексем сильно отличается в этих случаях. Слэш трактуется как знак деления если парсер в данной позиции разрешает его увидеть. И как знак начала reg-exp — во всех остальных случаях:
// здесь слэш означает начало regexp'a
/asd[^c]/i.match(s);
// а уже здесь - знак деления
a = b / c;
То есть парсер должен уметь ставит флажок, если в данный момент может придти оператор деления. На уровне flex'a решается просто:
/* [RegularExpressionLiteral] it has more length then [DivPunctor] (at least 3 == "/X/" versus 2 == "/="), that's why it would be proceeded first, before [DivPunctor] */
"/"{RegularExpressionFirstChar}({RegularExpressionFirstChar}|"*")*"/"({IdentifierStart}|[0-9])* {
if (m_mode != Mode::M_REGEXP)
REJECT;
yylval->assign(yytext, yyleng);
return token::T_REGEXP;
}
/* [DivPunctuator]: "/" or "/=" */
"/" return token::T_DIV;
"/=" return token::T_DIVAS;
Так как flex жадный лексер и старается обработать как можно более длинные лексемы, то сначала он попадёт в правило для regexp'ов, а там если задан режим для деления он перейдет к следующему правилу.
Parser tree на выходе
Мне очень хотелось бы получить именно parser tree в результате анализа. С ним очень удобно работать в рамках моей задачи. AST тоже подходит, но увы единственный поддерживающий данный формат ANTLR требует задавать явные правила для его постройки поверх грамматики. Каких-либо особых действий не требовалось. Разве что небольшие добавления к алгоритму анализатора:
while (!accepted && !error)
{
...
switch (act.type)
{
...
case Action::ACTION_SHIFT:
...
node.col = m_loc.tokenCol();
node.line = m_loc.tokenLine();
node.type = ParseNode::NODE_TERM;
node.termVal = s;
node.symb.term = tok;
nodes.push(tree.create(node));
break;
case Action::ACTION_REDUCE:
...
node.type = ParseNode::NODE_NONTERM;
node.symb.nonTerm = (Symbols::SymbolsType)act.reduce.nonTerm;
CTree<ParseNode>::TreeNode * parent = tree.create(node);
unsigned long ruleLen = act.reduce.ruleLength;
while (ruleLen)
{
tree.add(parent, nodes.top(), true);
nodes.pop();
ruleLen--;
}
nodes.push(parent);
break;
}
}
if (nodes.top())
tree.SetRoot(nodes.top());
Нестандартный lookahead
В грамматике можно встретить вот такую штуку
ExpressionStatement = [lookahead ∉ {{, function}] Expression ; Нет, это не стандартный expect-символ свертки, о котором я говорил в предыдущей части. Это наоборот попытка фильтрации первого символа Expression. То есть по этому правилу мы должны из Expression выкинуть лишние дочерние продукции, которые начинаются с терминала "{". В данном случае это сделано для того чтобы избежать конфликта между Block, который может выглядеть как "{}" и одним из порождений просто Expression: "{}" как задание пустого javascript-объекта Object. Аналогично для «function».
Решение можно сделать и без магии парсера, а только подправив грамматику:
ExpressionStatement = ExpressionWithoutBracket
ExpressionWithoutBracket = ... | AssignmentExpressionWithoutBracket | ...
...
Технически же в моём парсере это решается довольно просто:
ExpressionStatement = Expression {filter: [objectLiteral, functionDeclaration]}
...
ObjectLiteral = {commonId: objectLiteral} '{' '}' | '{ 'PropertyNameAndValueList '}' | '{' ',' '}'
Выключение некоторых дочерних правил
Это почти что подвид предыдущего пункта, но здесь нужно смотреть не только на первый символ, но и на произвольный. Иллюстрация — вышеупомянутый ExpressionNoIn и схожий с ним VariableDeclarationListNoIn. Если разобраться подробнее, то корни проблемы уходят в 2 вида for'a для примера:
// первый синтаксис
for (var id in obj) alret(id);
// второй синтаксис
for (var id = 1; id < 10; id) alert(id);
В обычных условиях при инициализации переменных мы можем использовать in, а-ля a = 'eval' in window; Этот оператор проверяет существование члена в заданном объекте (гусары, молчать!). Однако в цикле он используется для перебора всех членов объекта. И, собственно, очень легко может возникнуть путаница, поэтому внутри второго синтаксиса запрещено использовать in. На самом деле LALR-парсер легко всё это разрулит благодаря свертке с проверкой следующего символа (';' или ')'), но создатели грамматики видно ориентировались на более широкий класс парсеров и поэтому введи дублирующие 20 правил для случая без оператора «in». Однако нужно следовать грамматике, поэтому также необходим механизм выключения неугодных дочерних (пра-пра-...) правил.
У меня он полностью аналогичен предыдущему пункту, разве что отличия в мелочах:
ExpressionNoIn = Expression {filter: [RelationalExpression_6]}
...
RelationalExpression = ShiftExpression | RelationalExpression '<' ShiftExpression | RelationalExpression '>' ShiftExpression | RelationalExpression '<=' ShiftExpression | RelationalExpression '>=' ShiftExpression | RelationalExpression 'instanceof' ShiftExpression | {id: RelationalExpression_6} RelationalExpression 'in' ShiftExpression
Это опциональная фича, которая просто облегчает жизнь. А насколько именно показывают примеры ошибок. В самой грамматике забыли добавить NoIn в одном из правил:
ConditionalExpressionNoIn = LogicalORExpressionNoIn ? AssignmentExpression : AssignmentExpressionNoIn
Автоматическая вставка ';'
Еще одна занятная фишка JavaScript'a — это необязательность завершения Statement'ов точкой с запятой. Даже в тех местах где этого требует грамматика. Правила вставки одновременно просты в описание и сложны в реализации:
- Если парсер вернул ошибку на очередном токене и этот токен '{' либо он отделён от предыдущего хотя бы одним переводом строки.
- Встретили EOF и это было неожиданно.
- Для for'a правила не действуют. Точки с запятыми между скобками в заголовке for'a.
Вставка же происходит довольно просто — если определили необходимость данного действия, то просто заходим на новый круг FSM'a, подменив последний считанный токен точкой с запятой. Ну и в следующем shift'е не читаем новый токен, а используем тот, который вызвал ошибку.
Поддержка Unicode
JS очень грамотный в этом плане язык. Поддержка utf16 прописана жестко в стандарте. Вплоть до того, что перед парсингом весь исходник должен быть переконвертирован в utf16. Однако, к сожалению, flex не умеет такого (не, \xXX не подходит. навскидку, порядка тысячи символов нужно будет кодировать). Поэтому, пока данное условие не выполнено.
Поддержка квантификаторов
Еще одна довольно большая тема, которая облегчает работу с грамматикой. Мне в первую очередь нужны были следующие квантификаторы: "|" — варианты правил, где левая часть общая, а правые различны; "?" — опциональность символа в правиле; "*" — символ повторяется 1 или более раз. Да они вполне разрешаются на уровне BNF-грамматик:
A = B | C
// превращается в
A = B
A = C
A = B? C
// превращается в
A = B C
A = C
A = B*
// превращается в
A = A B
A = B
Здесь всё отлично за исключением последнего примера. В данном случае мы получаем ступеньки в дереве. То есть если B повторится 5 раз, то получим узел A с глубиной равной 5. Это весьма неудобно. Поэтому опять же я решил ввести модификации в парсер обеспечивающие удобное линейное представление — B B B B B образуют один узел A с 5 листьями B. На практике это выглядит как введение нового типа операций — ReduceRepeated. И модификации функций замыкания и определения сверток. В closeItem() закольцовываем элемент.
А вот, что получится, если сделать как принято:
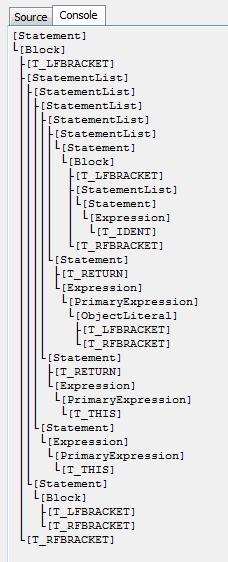
На этом всё. Спасибо за то, что читали эту статью.
Части статьи
- Часть 1. Базовая теория
- Часть 2. Описание LR-генераторов
- Часть 3. Особенности написания и возможные фичи LR-генераторов
