Так получилось, что с месяц назад передо мной выросла совершенно неожиданная задача: сконвертировать PDF в html по имеющемуся шаблону. В том числе необходимо было разбивать все на страницы и выделять в них параграфы. Да и много еще чего. И все бы ничего, и обошелся бы я какой-нибудь левой библиотечкой, но кое-какие специфичные штучки-финтеплюшки, так необходимые мне, в библиотеках не нашлись. И это было печально…
Как ни печально, но поиски хороших статей и свежей документации на русском языке привели меня всего к двум полезным источникам информации: тут и тут. И та и другая статья были очень полезны для общего понимания сути PDF но совершенно не решали поставленные передо мной задачи. И тогда на сцену вышел Он – ISO 3200-1. Этот Гигант в 756 страниц практически спас меня, сожрав, в обмен, вагон и маленькую тележку времени.
И все же всем, кто собирается работать с PDF, настоятельно рекомендую, в качестве справочника:
Купить на сайте международного стандарта ISO здесь
Скачать можно здесь
А тут с сайта самого Adobe
В кратчайшие сроки мне нужно было написать приблуду на PHP, которая более или менее экономила бы память, потому что в среднем ожидались PDFки от 6 до 40 Мб. При этом она должна была извлекать содержимое по страницам, разбивать текст на логические блоки (абзацы и заголовки), извлекать картинки и оглавление.
Для начала немного теории. Вот пример PDF файла открытого в блокноте

Даже не вооруженным глазом можно увидеть что в файле помимо странных кракозябликов есть еще и осмысленный текст и это не может не радовать. Именно он нам и поможет во всем разобраться.
Как оказалось(и помог здесь ISO 3200-1) PDF имеет примерно следующую структуру:
Первой строкой описывается версия PDF. Второй идет таинственная строка в которой я так и не разобрался за ненадобностью. Хотя я допускаю, что в ней скрыта истинная суть нашей вселенной и вообще. Дальше идет описание объектов.
Объекты – универсальные структуры описывающие все данные хранящиеся в PDF и их логические связи. Каждый объект состоит из заголовка вида «N M obj» (без кавычек), где N – номер объекта, M – его версия (чести ради замечу, что я ни разу не встретил объект где M != 0). После заголовка объекта идут его свойства в << >>. И в заключении опционально идет поток данных окруженный в пару stream, endstream. Все части объекта разделяются переносами строки. Эти элементы я рассмотрю подробнее чуть позже. А пока от объектов перейдем к заключительной части PDF документа
cross-reference table – Некая таблица хранящая в себе адреса каждого объекта в файле. Имеет эта таблица примерно следующую структуру:

Первой строкой идет ключевое слово xref. Второй – два числа, которые обозначают с какого по какой в ней описаны объекты. После чего идет непосредственно сама таблица. Каждая строка вида 0000000032 65535 f описывает объект соответствующего номера. Не забывайте, что в некоторых таблицах нумерация будет начинаться не с первого объекта, а с того, который описан в строке после ключевого слова xref. Первая группа цифр:10 цифр(значение дополняется незначащими нулями слева) обозначающие адрес в файле с которого начинается объект.
UPD: Сасибо, pleax за указание на недочеты. Поправил.
Вторая группа: 5 цифр не более 65535(int) обозначающие номер редакции объекта. и последний символ либо n(для использующихся объектов) либо f для free-объектов(которые были удалены). При удалении объекта номер его редакции(generation) увеличивается на 1, а флаг (n/f) устанавливается в f. Кроме того номер редакции может быть установлен в 65535. Такой объект считается free и никогда больше не используется. Подробнее можно прочитать на странице 40 документации на PDF
Сразу после таблицы идет ключевое слово trailer, после которого можно найти свойства таблицы. Нас будет интересовать только одно: /Prev 321249. Здесь число обозначает адрес в файле с которого начинается предшествующая таблица. Соответственно самая первая таблица такого свойства не имеет.
После свойств таблицы можно найти еще одно ключевое слово startxref, после котрого число, обозначающее адрес начала данной таблицы.
Этих знаний нам хватит, чтобы выгрузить таблицу всех объектов PDF, благодаря чему в дальнейшем нам не придется загружать весь PDF в память. А теперь глотнем пивка и к практике.
Нусс. Давайте с места в карьер. Вот немного моего говнокода:
Я думаю, что в целом в коде все понятно: Находим адрес последней таблицы, сохраняем её значения в массив, читаем адрес след таблицы. Последнюю таблицу мы создаем только потому, что в PHP сложно узнать следующий элемент массива. И в моем случае мне легче было хранить лишнюю таблицу, чем каждый раз пробегать весь массив в поисках нужного элемента.
Теперь, когда у нас есть массив RefTable[‘номер объекта’]=’Адрес объекта’ Мы можем использовать простую функцию для чтения файлов пообъектно. Например так:
Вернемся к нашим объектам, а точнее к их свойствам. В PDF существут 9 основных типов данных:
Boolean – True, False;
Numeric – int(623, +17, -98), real(34.5, -3.62)
LiteralString – Набор символов в круглых скобках (abcd)
Hexademical Strings – <4E6F7620> Строка из шестнадцатеричных значений.
Name — /Prev набор символов поле слэша
Array – [/name 1 /name1 /name2] массив объектов произвольного типа
Dictionary – Набор типа ключ-значение, где ключом всегда является объект типа Name (/Prev), а значение – объект любого типа в том числе и др. словари. Словари всегда окружены в << >>
Stream – Некоторые данные, которые могут быть закодированы так или иначе.
NULL – Говорит сам за себя
Подробнее смотрите на 14ой странице документации
Так вот свойства объекта хранятся в словарях(Dictionary). И в первую очередь нас будут интересовать свойство /Type в котором, как ни странно, находится тип объекта. Для начала мы найдем два объекта: /Type/Catalog и /Type/Pages в первом, в виде свойств, хранятся ссылки на объекты со служебной информацией и структуры данных, в том числе на /Pages 2 0 R (Это для примера). Здесь видно, что свойству /Pages сопоставляется номер объекта 2 0 R типа /Type/Pages.
Объект /Type/Pages, который мы найдем под номером 2 в нашей таблице ценен тем, что содержит в свойствах массив /Kids[ 3 0 R 29 0 R] с номерами. Объекты, которые мы найдем в этом массиве могут быть как еще одним узлом /Type/Pages со своими /Kids, так и искомыми нами объектами /Type/Page то бишь страницами.
И тут приходит время еще для бутылочки холодного темного.
Вот функция, которая получит
Далее – вспомогательная функция, которая рекурсивно помогает нам в поиске страниц-детишек.
Что ж свершилось чудо: у нас Есть таблица номерОбъекта->Адррес объекта и есть таблица НомерСтраницы->НомерОбъекта. Дело осталось за малым: Получить содержимое страниц и разбить его на логические структуры.
Иногда после объектов вы можете найти кучу непонятных символов, а иногда их можно найти в объекта на которые можно найти ссылки в свойстве /Resources объекта. Это закодированные данные. В словаре таких объектов вы найдете свойство /Filter которому может быть присвоено как единственное значение, так и массив (Важно! Вполне может быть, что данные после объекта не будут зашифрованы. В этом случае свойства /Filter не будет. А поток сможет прочитать даже жошкольник). Список всех возможных фильтров вы найдете в документации на странице 22, однако же на одном я остановлюсь. /Filter/FlateDecode – это самый распространённый фильтр и в 99% случаев хватит только его. FlateDecode есть ни что иное, как обычный gzip и все что нам потребуется это gzuncompress($stream). Здесь есть одно но. По стандарту FlateDecode первые 4 бита данных имеют служебный характер и не интерпретируются, но в некоторых PDF эти биты отсутствуют и могут возникать gzuncompress() data error. Могу Вас обрадывать: один мОлодец написал для нас заплатку. Идем сюда и читаем
И вот значит мы молодцы такие взяли да и извлекли данные из потока, а там:

А там текст. Нас пока будут интересовать следующие строки:
Строка которая заканчивается на BT. Вполне может оказаться, что в строке будет только BT
Строка, которая заканчивается на Tf. Она описывает шрифты использующиеся в блоке текста
Строка заканчивающаяся на TJ. В ней мы найдем непосредственно текст(почти).
Ну и закончится все ET
Разберем все подробнее на примере
/P <</MCID 0>> BDC BT
/F1 13.56 Tf
1 0 0 1 245.69 760.8 Tm
0 g
0 G
[<0245>-2<0278>4<025B>5<0268>-3<025C>12<0276>-3<000F0003>4<025E>5<025F0265>5<0276>-3<026E0262>6<0267>4<00030262>6<00030266>7<0268>-3<026A>-3<025F0011>] TJ
ET
BT и ET это ни что иное, как begin of text и end of text. Перед BT есть маркер, который собственно помогает выделить логические структуры в тексте(Абзацы и заголовки) В этой статье я не буду подробно на этом останавливаться. Пока можете каждый такой блок <</MCID 0>>, <</MCID 1>> итд считать началом параграфа или почитать про них в документации на странице 556 раздел Logical Structure. Если кому интересно будет – могу дополнить статью.
В строке шрифтов нас интересует /F1 и цифирки. /F1 – наименование шрифта, которое понадобится нам для декодирования текста (да, да наши мучения еще не кончились) и получения стилей текста
Перед TJ в [] расположился вожделенный текст. Сейчас нам может повезти и мы увидим текст. Чистый текст всегда находится в круглых скобках. Если же нам не везет, а так и будет, то мы найдем группы цифр в треугольных скобках. Каждые 4 цифры – один символ, шестнадцатеричное значение которого можно найти в таблице соответствия, а таблицу соответствия в объекте шрифта который мы находили ранее, заяц в утке, а утка в яйце… Упс меня понесло…
Найти таблицу кодов символов не сложно: у страницы, которую мы декодировали есть свойство /Resources, а в нем <</Font<</F1 5 0 R/F2 10 0 R/F3 12 0 R………… Что делать вы уже догадались: идем к номеру объекта соответствующего шрифта, а в том объекте(это не шутка) есть свойство /ToUnicode 98 0 R Там вы и найдете таблицу. Что с ней делать неплохо описывалось на хабре. Кому не хватит – можете посмотреть в исходники, которые я приложу.
Пока все. Это был лишь общий обзор. Если будет интерес – расскажу подробней как извлекать изображения, каталог, таблицы, стили другие плюшки. Если будут вопросы, you are welcome. И да, прошу не тролить код сильно он не претендует на читстоту он лишь для того, чтоб в целом объяснить суть.
И на последок Немного кода для общего понимания.
0.Сначала было слово и было это слово: «документация»
Как ни печально, но поиски хороших статей и свежей документации на русском языке привели меня всего к двум полезным источникам информации: тут и тут. И та и другая статья были очень полезны для общего понимания сути PDF но совершенно не решали поставленные передо мной задачи. И тогда на сцену вышел Он – ISO 3200-1. Этот Гигант в 756 страниц практически спас меня, сожрав, в обмен, вагон и маленькую тележку времени.
И все же всем, кто собирается работать с PDF, настоятельно рекомендую, в качестве справочника:
Купить на сайте международного стандарта ISO здесь
Скачать можно здесь
А тут с сайта самого Adobe
1. От слов к делу. Внимание! Задача
В кратчайшие сроки мне нужно было написать приблуду на PHP, которая более или менее экономила бы память, потому что в среднем ожидались PDFки от 6 до 40 Мб. При этом она должна была извлекать содержимое по страницам, разбивать текст на логические блоки (абзацы и заголовки), извлекать картинки и оглавление.
2а. Немного теории. Получаем таблицу объектов.
Для начала немного теории. Вот пример PDF файла открытого в блокноте

Даже не вооруженным глазом можно увидеть что в файле помимо странных кракозябликов есть еще и осмысленный текст и это не может не радовать. Именно он нам и поможет во всем разобраться.
Как оказалось(и помог здесь ISO 3200-1) PDF имеет примерно следующую структуру:
Первой строкой описывается версия PDF. Второй идет таинственная строка в которой я так и не разобрался за ненадобностью. Хотя я допускаю, что в ней скрыта истинная суть нашей вселенной и вообще. Дальше идет описание объектов.
Объекты – универсальные структуры описывающие все данные хранящиеся в PDF и их логические связи. Каждый объект состоит из заголовка вида «N M obj» (без кавычек), где N – номер объекта, M – его версия (чести ради замечу, что я ни разу не встретил объект где M != 0). После заголовка объекта идут его свойства в << >>. И в заключении опционально идет поток данных окруженный в пару stream, endstream. Все части объекта разделяются переносами строки. Эти элементы я рассмотрю подробнее чуть позже. А пока от объектов перейдем к заключительной части PDF документа
cross-reference table – Некая таблица хранящая в себе адреса каждого объекта в файле. Имеет эта таблица примерно следующую структуру:

Первой строкой идет ключевое слово xref. Второй – два числа, которые обозначают с какого по какой в ней описаны объекты. После чего идет непосредственно сама таблица. Каждая строка вида 0000000032 65535 f описывает объект соответствующего номера. Не забывайте, что в некоторых таблицах нумерация будет начинаться не с первого объекта, а с того, который описан в строке после ключевого слова xref. Первая группа цифр:10 цифр(значение дополняется незначащими нулями слева) обозначающие адрес в файле с которого начинается объект.
UPD: Сасибо, pleax за указание на недочеты. Поправил.
Вторая группа: 5 цифр не более 65535(int) обозначающие номер редакции объекта. и последний символ либо n(для использующихся объектов) либо f для free-объектов(которые были удалены). При удалении объекта номер его редакции(generation) увеличивается на 1, а флаг (n/f) устанавливается в f. Кроме того номер редакции может быть установлен в 65535. Такой объект считается free и никогда больше не используется. Подробнее можно прочитать на странице 40 документации на PDF
Сразу после таблицы идет ключевое слово trailer, после которого можно найти свойства таблицы. Нас будет интересовать только одно: /Prev 321249. Здесь число обозначает адрес в файле с которого начинается предшествующая таблица. Соответственно самая первая таблица такого свойства не имеет.
После свойств таблицы можно найти еще одно ключевое слово startxref, после котрого число, обозначающее адрес начала данной таблицы.
Этих знаний нам хватит, чтобы выгрузить таблицу всех объектов PDF, благодаря чему в дальнейшем нам не придется загружать весь PDF в память. А теперь глотнем пивка и к практике.
2б. Теория на практике. Получаем таблицу объектов.
Нусс. Давайте с места в карьер. Вот немного моего говнокода:
private function get_ref_table(){
$currentString = '';
$matches=NULL;
$tableLength = 0;
$lastTable = false;
/*Читаем последние 32 байта среди которых, так или иначе, попадется адрес на начало последней таблицы*/
fseek($this->filePointer, -32, SEEK_END);
$nextTableLink='';
/*начиная с -32 байта читаем построчно, пока не найдем startxref и не возьмем нужное нам значение*/
while(preg_match('/startxref/', $nextTableLink)!=1 && $nextTableLink!==false){
$nextTableLink = fgets($this->filePointer);
}
$nextTableLink = fgets($this->filePointer);
while($lastTable!== true){
//Читаем таблицу
fseek($this->filePointer, $nextTableLink, SEEK_SET);
//Пропускаем бесполезную строчку
fgets($this->filePointer);
$currentString = fgets($this->filePointer);
// читаем диапозон номеров объектов представленных в таблице
preg_match('/(\d+)\x20(\d+)/', $currentString, $matches);
$tableLength = $matches[2];
$startIndex = $matches[1];
//читаем объекты
for($i=0; $i<$tableLength; $i++){
$currentString = fgets($this->filePointer);
preg_match('/(\d+)\x20\d+\x20\x6E/', $currentString, $matches);
if(isset($matches[1]))
$this->RefTable[$startIndex+$i]=$matches[1];
}
fgets($this->filePointer);
$currentString = fgets($this->filePointer);
//Если есть предыдущая таблица, кладем её адрес в переменную
//И не ругаем мой говнокод
if(preg_match('/\x2FPrev\x20(\d+)/', $currentString, $matches)==1)
$nextTableLink = $matches[1]+0;
else
$lastTable = true;
}
//сортируем объекты по Адресу
asort($this->RefTable, SORT_NUMERIC);
reset($this->RefTable);
$pointerKey=NULL;
//Создаем таблицу чтобы знать следующий объект
//Она как первая, только каждому объекту присвоен
//Адрес начала след объекта.
foreach($this->RefTable as $key => $value){
if($pointerKey!=NULL)
$this->RefTableNext[$pointerKey]=&$this->RefTable[$key];
$pointerKey = $key;
}
if($pointerKey!=NULL)
$this->RefTableNext[$pointerKey]= $nextTableLink;
}Я думаю, что в целом в коде все понятно: Находим адрес последней таблицы, сохраняем её значения в массив, читаем адрес след таблицы. Последнюю таблицу мы создаем только потому, что в PHP сложно узнать следующий элемент массива. И в моем случае мне легче было хранить лишнюю таблицу, чем каждый раз пробегать весь массив в поисках нужного элемента.
Теперь, когда у нас есть массив RefTable[‘номер объекта’]=’Адрес объекта’ Мы можем использовать простую функцию для чтения файлов пообъектно. Например так:
public function get_obj_by_key($key){
fseek($this->filePointer, $this->RefTable[$key]);
return fread($this->filePointer, $this->RefTableNext[$key]-$this->RefTable[$key]);
}3а. Еще немного теории. Получаем таблицу страниц.
Вернемся к нашим объектам, а точнее к их свойствам. В PDF существут 9 основных типов данных:
Boolean – True, False;
Numeric – int(623, +17, -98), real(34.5, -3.62)
LiteralString – Набор символов в круглых скобках (abcd)
Hexademical Strings – <4E6F7620> Строка из шестнадцатеричных значений.
Name — /Prev набор символов поле слэша
Array – [/name 1 /name1 /name2] массив объектов произвольного типа
Dictionary – Набор типа ключ-значение, где ключом всегда является объект типа Name (/Prev), а значение – объект любого типа в том числе и др. словари. Словари всегда окружены в << >>
Stream – Некоторые данные, которые могут быть закодированы так или иначе.
NULL – Говорит сам за себя
Подробнее смотрите на 14ой странице документации
Так вот свойства объекта хранятся в словарях(Dictionary). И в первую очередь нас будут интересовать свойство /Type в котором, как ни странно, находится тип объекта. Для начала мы найдем два объекта: /Type/Catalog и /Type/Pages в первом, в виде свойств, хранятся ссылки на объекты со служебной информацией и структуры данных, в том числе на /Pages 2 0 R (Это для примера). Здесь видно, что свойству /Pages сопоставляется номер объекта 2 0 R типа /Type/Pages.
Объект /Type/Pages, который мы найдем под номером 2 в нашей таблице ценен тем, что содержит в свойствах массив /Kids[ 3 0 R 29 0 R] с номерами. Объекты, которые мы найдем в этом массиве могут быть как еще одним узлом /Type/Pages со своими /Kids, так и искомыми нами объектами /Type/Page то бишь страницами.
И тут приходит время еще для бутылочки холодного темного.
3б. Вернемся к коду. Получаем таблицу страниц.
Вот функция, которая получит
private function get_page_table(){
$currentObj = '';
reset($this->RefTable);
$key = key($this->RefTable);
$matches = NULL;
$nextPage = NULL;
$pages = array();
//Перебираем все объекты, пока не найдем /Type/Catalog while((preg_match('/\x2F\x54\x79\x70\x65\x2F\x43\x61\x74\x61\x6C\x6F\x67/',$currentObj) != 1) ||
($currentObj === false)
){
$currentObj = $this->get_obj_by_key($key);
next($this->RefTable);
$key = key($this->RefTable);
}
//Находим ссылку на объект вида /Pages N 0 R
preg_match('/\x2F\x50\x61\x67\x65\x73\x20(\d+)\x20\x30\x20\x52/', $currentObj, $matches);
$currentObj = $this->get_obj_by_key($matches[1]);
preg_match('/\x2FKids\[(.*)\]/',$currentObj, $kids);
//Получаем детей
preg_match_all('/\s?(\d+)\s\d+\sR/',$kids[1], $matches);
foreach($matches[1] as $value){
$pages[] = $value;
}
foreach($pages as $key => $value){
if(isset($this->RefTable[$value])){
$page=$this->get_obj_by_key($value);
//Если объект – страница, то помещаем его в массив
if(preg_match('/\/Type\/Page\W/',$page) == 1){
$this->pageTable[] = $value;
}
//В противном случае находим еще детей
$this->pageTable = array_merge($this->pageTable,$this->getChildren($value));
}
}
return true;
}
Далее – вспомогательная функция, которая рекурсивно помогает нам в поиске страниц-детишек.
private function getChildren($Obj){
$pages = array();
$pagesArr = array();
$currentObj = $this->get_obj_by_key($Obj);
preg_match('/\x2FKids\[(.*)\]/',$currentObj, $kids);
if(isset($kids[1])){
if(preg_match_all('/\s?(\d+)\s\d+\sR/',$kids[1], $matches) > 0){
foreach($matches[1] as $value){
$pages[] = $value;
}
foreach($pages as $key => $value){
if(isset($this->RefTable[$value])){
$page=$this->get_obj_by_key($value);
if(preg_match('/\/Type\/Page\W/',$page) == 1){
$pagesArr[] = $value;
}
$pagesArr = array_merge($pagesArr,$this->getChildren($value));
}
}
return $pagesArr;
}
else return array();
}
return array();
}
Что ж свершилось чудо: у нас Есть таблица номерОбъекта->Адррес объекта и есть таблица НомерСтраницы->НомерОбъекта. Дело осталось за малым: Получить содержимое страниц и разбить его на логические структуры.
4а. Теория возвращается. Извлекаем данные из потоков.
Иногда после объектов вы можете найти кучу непонятных символов, а иногда их можно найти в объекта на которые можно найти ссылки в свойстве /Resources объекта. Это закодированные данные. В словаре таких объектов вы найдете свойство /Filter которому может быть присвоено как единственное значение, так и массив (Важно! Вполне может быть, что данные после объекта не будут зашифрованы. В этом случае свойства /Filter не будет. А поток сможет прочитать даже жошкольник). Список всех возможных фильтров вы найдете в документации на странице 22, однако же на одном я остановлюсь. /Filter/FlateDecode – это самый распространённый фильтр и в 99% случаев хватит только его. FlateDecode есть ни что иное, как обычный gzip и все что нам потребуется это gzuncompress($stream). Здесь есть одно но. По стандарту FlateDecode первые 4 бита данных имеют служебный характер и не интерпретируются, но в некоторых PDF эти биты отсутствуют и могут возникать gzuncompress() data error. Могу Вас обрадывать: один мОлодец написал для нас заплатку. Идем сюда и читаем
И вот значит мы молодцы такие взяли да и извлекли данные из потока, а там:
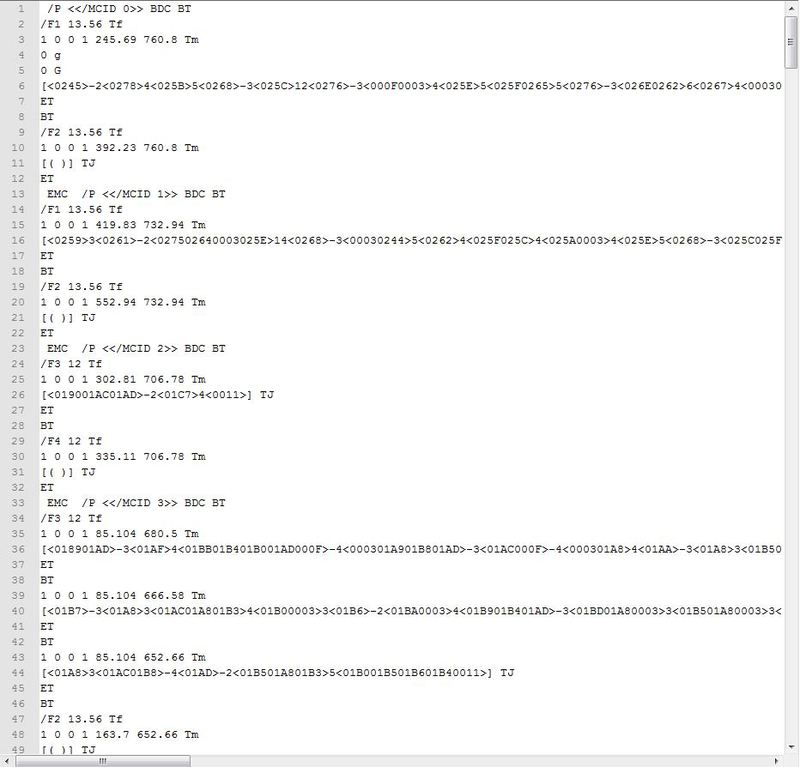
А там текст. Нас пока будут интересовать следующие строки:
Строка которая заканчивается на BT. Вполне может оказаться, что в строке будет только BT
Строка, которая заканчивается на Tf. Она описывает шрифты использующиеся в блоке текста
Строка заканчивающаяся на TJ. В ней мы найдем непосредственно текст(почти).
Ну и закончится все ET
Разберем все подробнее на примере
/P <</MCID 0>> BDC BT
/F1 13.56 Tf
1 0 0 1 245.69 760.8 Tm
0 g
0 G
[<0245>-2<0278>4<025B>5<0268>-3<025C>12<0276>-3<000F0003>4<025E>5<025F0265>5<0276>-3<026E0262>6<0267>4<00030262>6<00030266>7<0268>-3<026A>-3<025F0011>] TJ
ET
BT и ET это ни что иное, как begin of text и end of text. Перед BT есть маркер, который собственно помогает выделить логические структуры в тексте(Абзацы и заголовки) В этой статье я не буду подробно на этом останавливаться. Пока можете каждый такой блок <</MCID 0>>, <</MCID 1>> итд считать началом параграфа или почитать про них в документации на странице 556 раздел Logical Structure. Если кому интересно будет – могу дополнить статью.
В строке шрифтов нас интересует /F1 и цифирки. /F1 – наименование шрифта, которое понадобится нам для декодирования текста (да, да наши мучения еще не кончились) и получения стилей текста
Перед TJ в [] расположился вожделенный текст. Сейчас нам может повезти и мы увидим текст. Чистый текст всегда находится в круглых скобках. Если же нам не везет, а так и будет, то мы найдем группы цифр в треугольных скобках. Каждые 4 цифры – один символ, шестнадцатеричное значение которого можно найти в таблице соответствия, а таблицу соответствия в объекте шрифта который мы находили ранее, заяц в утке, а утка в яйце… Упс меня понесло…
Найти таблицу кодов символов не сложно: у страницы, которую мы декодировали есть свойство /Resources, а в нем <</Font<</F1 5 0 R/F2 10 0 R/F3 12 0 R………… Что делать вы уже догадались: идем к номеру объекта соответствующего шрифта, а в том объекте(это не шутка) есть свойство /ToUnicode 98 0 R Там вы и найдете таблицу. Что с ней делать неплохо описывалось на хабре. Кому не хватит – можете посмотреть в исходники, которые я приложу.
Пока все. Это был лишь общий обзор. Если будет интерес – расскажу подробней как извлекать изображения, каталог, таблицы, стили другие плюшки. Если будут вопросы, you are welcome. И да, прошу не тролить код сильно он не претендует на читстоту он лишь для того, чтоб в целом объяснить суть.
И на последок Немного кода для общего понимания.
