Постепенное развитие проекта шло своим чередом.
На часть полученных по гранту средств было произведено обновление парка личной вычислительной техники. В итоге расчёты сейчас осуществляются не на многострадальном ноутбуке, а на вполне приемлемой машине с псевдовосьмиядерным Intel Core i7-2600 и 8 Gb оперативной памяти на борту. А разработка производится под Visual Studio 2005 (получена по программе DreamSpark) с подключенной триал-версией Intel FORTRAN Compiler 12 / Intel Parallel Studio XE 2011 (всё это крутится под Win 7). В качестве параллельного API задействован OpenMP.
Ввиду явно заметного роста доступных мощностей, обнаружились и новые негативные особенности написанного ранее алгоритма. Прежде всего, с марта месяца была проведена глубокая оптимизация вычислительной части кода, что позволило выиграть в производительности около 70%. Такой прирост обеспечила прежде всего ликвидация операций деления, а также увеличение количества предвычисляемых переменных.
upd: Пост, в общем-то, о серой рабочей повседневности, и никаких открытий в себе не содержит.
Программа исправно использовалась и выдавала хорошие результаты, пока в один прекрасный день не было решено проверить, насколько эффективно выполнено распараллеливание. И, скорее даже ожидаемо, чем удивительно, исполнение в один поток оказалось в среднем вдвое быстрее многопоточных запусков, причём независимо от количества потоков.
Ответ, в общем-то, лежит на поверхности. Алгоритм с математической точки зрения оказался оптимизирован настолько, что его узким местом стал обмен данными между отдельными потоками, что подтвердилось даже при беглом анализе в Intel Vtune Amplifier. Наибольших временных затрат потребовала инициализация потоков и их локальных переменных, а также обращение к общим переменным и массивам. Немалую роль в заметности проявившейся пакости сыграл и тот факт, что до сих пор применялась грубая расчётная сетка, всего 3х200 пространственных узлов (своего рода имитация одномерной задачи), и время вычислений оказалось относительно малым.
Что же было сделано для оптимизации?
В первую очередь, подкорректированы директивы и разделение переменных по классам. В частности, основные рабочие массивы, в которых хранятся величины, являющиеся целью расчёта, из
Здесь опущены списки переменных, т.к. с ними код занимает около десятка строчек.
Всего же таких мест в коде девять. Девять бутылочных горлышек, через которые программа, цитируя М. Евдокимова, «Пищит, но лезет».
Перекидывание разных переменных туда-сюда продолжалось пару вечеров, однако об оптимальности работы не могло быть и речи. Запуск на полной загрузке процессора показывал, что в среднем одновременно существуют только 2.1 — 2.3 потока. Процессорное время же расходовалось исправно в восьмикратном размере. Для наглядности, гистограммы из VTune Amplifier для сетки 3х200:

Для 100х100:

Для 200х200:

Очевидно, что по мере увеличения доли вычислений, результаты улучшаются, однако высокой эффективностью называть такое желания нет.
Применение к потокам принудительного лишения сна посредством увеличения значения KMP_BLOCKTIME с 200 мс до 10 с точно так же помогло лишь чуточку.
Неожиданно был брошен суровый взгляд на «пространственно-временную» структуру, образуемую в алгоритме потоками. И всё сразу встало на свои места. Слабым местом оказалась директива
Ключевое слово
Была проведена полная реорганизация структуры параллельной части программы. Теперь схема потоков выглядит так:
Вертикальные штриховые линии условно показывают границы параллельных циклов, а ближе к концу использована директива
А в исходном тексте структура директив выглядит так:
Т.е., всё тело цикла по времени (программа производит прямое численное моделирование эволюции гидродинамической системы) теперь находится в параллельной области, потоки создаются в начале итерации и уничтожаются только при её завершении, а не воскрешаются неоднократно. Обёртывать в параллельную область и временной цикл уже не представляется возможным, поскольку каждая его итерация, естественно, полностью зависит от предыдущей (прошу поправить, ежели не так — моя логика здесь даёт определённый сбой).
Финальным улучшением, направленным на ускорение работы, явилось отключение барьерной синхронизации между потоками в некоторых циклах, где это не повлияет на последующие вычисления.
В результате, время действительно параллельного исполнения кода как будто бы увеличивается. На сетке 3х200 узел VTune изображает такой результат:

На сетке 100х100 — такой:

Наконец, на 200х200 — такой:

Таким образом, подтверждаем давнюю истину, что на больших сетках, когда вычислений реально много, они занимают большую часть времени и параллелизм эффективен. На маленьких же сетках требуется оптимизировать обмен между процессами, иначе результаты оказываются не радостными. Да и несмотря на это, последовательные этапы занимают преобладающую часть рабочего времени.
Возникает вопрос, стоит ли проделанная работа по оптимизации потраченного времени и сил? Проверим реальную скорость выполнения программы. Запуск осуществлён на тех же трёх разных сетках с восемью потоками, и измерено время до некоторой контрольной точки. Контрольные точки во всех случаях разные, посему проводить сравнение по абсолютным величинам между разными сетками будет некорректно — 1 млн. итераций для 3 х 200, 500 тыс. для 100 х 100 и 200 тыс. для 200 х 200 узлов. Во второй строчке в скобках приводится относительное различие времени исполнения двумя вариантами программы.
Вполне очевидно, что проведённая оптимизация обеспечила неплохой прирост производительности.
Попутно сравним качество распараллеливания, определив таким же способом прирост производительности по мере увеличения числа потоков. Сразу следует оговориться, что на одном потоке вычисления могут оказаться быстрее, чем на двух-трёх, в силу, во-первых, отсутствия необходимости обмениваться данными с соседями, а во-вторых, работы TurboBoost, поднимающей тактовую частоту на 400 МГц. Также напомним, что физических ядер у упомянутого в начале процессора всего 4, и ускорение на 8 потоках — результат работы Hyper-Threading.
Сетка 3х200, 1 млн. итераций:
Сетка 100х100, 500 тыс. итераций:
Если на малом числе узлов результаты, мягко говоря, неоднозначные, хотя и свидельствующие в пользу многопоточности и успешности оптимизации, то на большом их количестве — всё вновь очевидно.
Выводы? Основной вывод один — следите за тем, как рождаются и умирают потоки в программе. Продление их жизни может оказаться полезным.
Реализованная перекомпоновка пространственно-временной структуры потоков описана, в частности, здесь:
Эффективное распределение нагрузки между потоками с помощью OpenMP*. Вот только прочитано оно было уже после придумывания решения. Сэкономил бы пару дней, эх.
На часть полученных по гранту средств было произведено обновление парка личной вычислительной техники. В итоге расчёты сейчас осуществляются не на многострадальном ноутбуке, а на вполне приемлемой машине с псевдовосьмиядерным Intel Core i7-2600 и 8 Gb оперативной памяти на борту. А разработка производится под Visual Studio 2005 (получена по программе DreamSpark) с подключенной триал-версией Intel FORTRAN Compiler 12 / Intel Parallel Studio XE 2011 (всё это крутится под Win 7). В качестве параллельного API задействован OpenMP.
Ввиду явно заметного роста доступных мощностей, обнаружились и новые негативные особенности написанного ранее алгоритма. Прежде всего, с марта месяца была проведена глубокая оптимизация вычислительной части кода, что позволило выиграть в производительности около 70%. Такой прирост обеспечила прежде всего ликвидация операций деления, а также увеличение количества предвычисляемых переменных.
upd: Пост, в общем-то, о серой рабочей повседневности, и никаких открытий в себе не содержит.
Мелкие пакости
Программа исправно использовалась и выдавала хорошие результаты, пока в один прекрасный день не было решено проверить, насколько эффективно выполнено распараллеливание. И, скорее даже ожидаемо, чем удивительно, исполнение в один поток оказалось в среднем вдвое быстрее многопоточных запусков, причём независимо от количества потоков.
Ответ, в общем-то, лежит на поверхности. Алгоритм с математической точки зрения оказался оптимизирован настолько, что его узким местом стал обмен данными между отдельными потоками, что подтвердилось даже при беглом анализе в Intel Vtune Amplifier. Наибольших временных затрат потребовала инициализация потоков и их локальных переменных, а также обращение к общим переменным и массивам. Немалую роль в заметности проявившейся пакости сыграл и тот факт, что до сих пор применялась грубая расчётная сетка, всего 3х200 пространственных узлов (своего рода имитация одномерной задачи), и время вычислений оказалось относительно малым.
Мелкие исправления
Что же было сделано для оптимизации?
В первую очередь, подкорректированы директивы и разделение переменных по классам. В частности, основные рабочие массивы, в которых хранятся величины, являющиеся целью расчёта, из
SHARED были превращены в THREADPRIVATE посредством задания атрибута COMMON (что попутно оптимизировало их размещение в памяти) и директивы COPYIN. Предвычисляемые переменные были оставлены в виде SHARED, т.к. применение к ним FIRSTPRIVATE или COPYIN заметного эффекта не только не давали, но и ухудшали результаты. Итого, директива перед основными рабочими циклами приняли примерно такой вид:!$OMP PARALLEL DO NUM_THREADS(Threads_number) SCHEDULE(DYNAMIC) &
!$OMP PRIVATE(...) &
!$OMP COPYIN(...) &
!$OMP DEFAULT(SHARED)
Здесь опущены списки переменных, т.к. с ними код занимает около десятка строчек.
Всего же таких мест в коде девять. Девять бутылочных горлышек, через которые программа, цитируя М. Евдокимова, «Пищит, но лезет».
Перекидывание разных переменных туда-сюда продолжалось пару вечеров, однако об оптимальности работы не могло быть и речи. Запуск на полной загрузке процессора показывал, что в среднем одновременно существуют только 2.1 — 2.3 потока. Процессорное время же расходовалось исправно в восьмикратном размере. Для наглядности, гистограммы из VTune Amplifier для сетки 3х200:

Для 100х100:
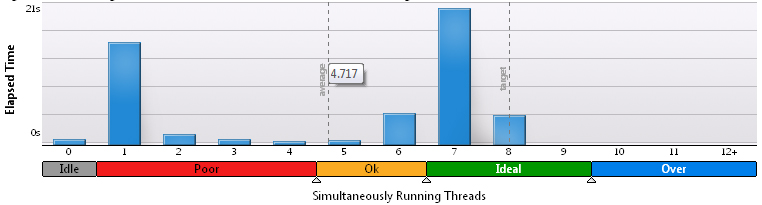
Для 200х200:
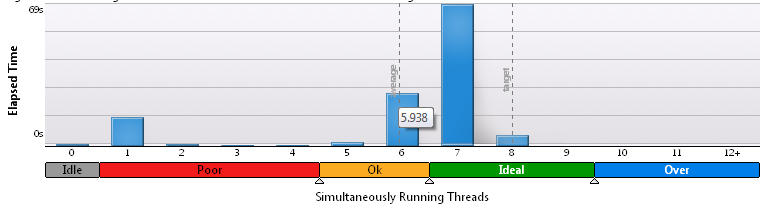
Очевидно, что по мере увеличения доли вычислений, результаты улучшаются, однако высокой эффективностью называть такое желания нет.
Применение к потокам принудительного лишения сна посредством увеличения значения KMP_BLOCKTIME с 200 мс до 10 с точно так же помогло лишь чуточку.
Глупости мелкими бывают редко
Неожиданно был брошен суровый взгляд на «пространственно-временную» структуру, образуемую в алгоритме потоками. И всё сразу встало на свои места. Слабым местом оказалась директива
!$OMP PARALLEL DO NUM_THREADS(Threads_number) SCHEDULE(DYNAMIC)
Ключевое слово
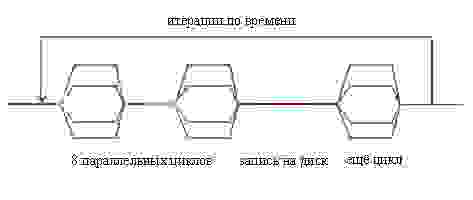
PARALLEL отвечает, как известно, за границы параллельной и последовательной области кода. По её достижении, происходит создание новых нитей, перераспределение локальных переменных в их памяти и прочие процедуры, требующие немалого времени. Таких мест, как уже говорилось, было девять. Соответственно, девять раз потоки создавались и уничтожались, а при этом между ними кое-где даже не было последовательных участков. Схематически, это можно представить на такой картинке: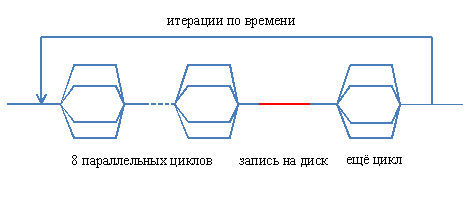
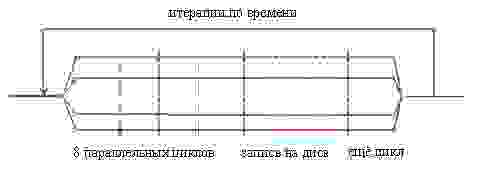
Была проведена полная реорганизация структуры параллельной части программы. Теперь схема потоков выглядит так:

Вертикальные штриховые линии условно показывают границы параллельных циклов, а ближе к концу использована директива
SINGLE — там осуществляется запись результатов расчёта на диск, для чего работа всех потоков, кроме одного, приостанавливается. Распараллелить её как минимум затруднительно, хотя есть идея записывать в одном потоке и выполнять дальнейший цикл в остальных, т.к. он от записи на диск не зависит, либо переставить их местами. Но это уже детали, к делу отношения не имеющие.А в исходном тексте структура директив выглядит так:
Time_cycle: do n = 0, Nt, 1
!$OMP PARALLEL NUM_THREADS(Threads_number) &
!$OMP PRIVATE(...) &
!$OMP COPYIN(...) &
!$OMP DEFAULT(SHARED)
!$OMP DO SCHEDULE(DYNAMIC)
...
!$OMP END DO
... ещё 7 таких параллельных циклов
!$OMP SINGLE
... запись на диск
!$OMP END SINGLE
!$OMP DO SCHEDULE(DYNAMIC)
...
!$OMP END DO
!$OMP END PARALLEL
enddo Tyme_Cycle
Т.е., всё тело цикла по времени (программа производит прямое численное моделирование эволюции гидродинамической системы) теперь находится в параллельной области, потоки создаются в начале итерации и уничтожаются только при её завершении, а не воскрешаются неоднократно. Обёртывать в параллельную область и временной цикл уже не представляется возможным, поскольку каждая его итерация, естественно, полностью зависит от предыдущей (прошу поправить, ежели не так — моя логика здесь даёт определённый сбой).
Финальным улучшением, направленным на ускорение работы, явилось отключение барьерной синхронизации между потоками в некоторых циклах, где это не повлияет на последующие вычисления.
В результате, время действительно параллельного исполнения кода как будто бы увеличивается. На сетке 3х200 узел VTune изображает такой результат:

На сетке 100х100 — такой:

Наконец, на 200х200 — такой:

Таким образом, подтверждаем давнюю истину, что на больших сетках, когда вычислений реально много, они занимают большую часть времени и параллелизм эффективен. На маленьких же сетках требуется оптимизировать обмен между процессами, иначе результаты оказываются не радостными. Да и несмотря на это, последовательные этапы занимают преобладающую часть рабочего времени.
Возникает вопрос, стоит ли проделанная работа по оптимизации потраченного времени и сил? Проверим реальную скорость выполнения программы. Запуск осуществлён на тех же трёх разных сетках с восемью потоками, и измерено время до некоторой контрольной точки. Контрольные точки во всех случаях разные, посему проводить сравнение по абсолютным величинам между разными сетками будет некорректно — 1 млн. итераций для 3 х 200, 500 тыс. для 100 х 100 и 200 тыс. для 200 х 200 узлов. Во второй строчке в скобках приводится относительное различие времени исполнения двумя вариантами программы.
| Размер сетки | Время выполнения, с |
|---|---|
| 3 х 200, до оптимизации | 94.4 |
| 3 х 200, оптимизировано | 70.0 (-26 %) |
| 100 х 100, до оптимизации | 352 |
| 100 х 100, оптимизировано | 285 (-19 %) |
| 200 х 200, до оптимизации | 543 |
| 200 х 200, оптимизировано | 436 (-19 %) |
Вполне очевидно, что проведённая оптимизация обеспечила неплохой прирост производительности.
Попутно сравним качество распараллеливания, определив таким же способом прирост производительности по мере увеличения числа потоков. Сразу следует оговориться, что на одном потоке вычисления могут оказаться быстрее, чем на двух-трёх, в силу, во-первых, отсутствия необходимости обмениваться данными с соседями, а во-вторых, работы TurboBoost, поднимающей тактовую частоту на 400 МГц. Также напомним, что физических ядер у упомянутого в начале процессора всего 4, и ускорение на 8 потоках — результат работы Hyper-Threading.
Сетка 3х200, 1 млн. итераций:
| Число потоков, до оптимизации | Время выполнения, с |
|---|---|
| 1 | 80.9 |
| 2 | 88.7 |
| 3 | 84.4 |
| 4 | 83.7 |
| 8 | 94.4 |
| Число потоков, после оптимизации | Время выполнения, с |
| 1 | 87.9 |
| 2 | 145 |
| 3 | 113 |
| 4 | 97.8 |
| 8 | 70.0 |
Сетка 100х100, 500 тыс. итераций:
| Число потоков, до оптимизации | Время выполнения, с |
|---|---|
| 1 | 918 |
| 2 | 736 |
| 3 | 536 |
| 4 | 431 |
| 8 | 352 |
| Число потоков, после оптимизации | Время выполнения, с |
| 1 | 845 |
| 2 | 528 |
| 3 | 434 |
| 4 | 381 |
| 8 | 285 |
Если на малом числе узлов результаты, мягко говоря, неоднозначные, хотя и свидельствующие в пользу многопоточности и успешности оптимизации, то на большом их количестве — всё вновь очевидно.
Выводы? Основной вывод один — следите за тем, как рождаются и умирают потоки в программе. Продление их жизни может оказаться полезным.
Реализованная перекомпоновка пространственно-временной структуры потоков описана, в частности, здесь:
Эффективное распределение нагрузки между потоками с помощью OpenMP*. Вот только прочитано оно было уже после придумывания решения. Сэкономил бы пару дней, эх.
