Вместо вступления
Лень — двигатель прогресса. Не хочешь сам молоть зерно — сделай мельницу, не хочешь сам кидать во врагов камни — сооруди катапульту, надоело гореть на кострах инквизиции и гнуть спину под феодалом — замути с ребятами ренессанс… впрочем, о чем это я.
Автоматизация, господа. Берешь какой-нибудь полезный процесс, в котором участвует человек, заменяешь человека на сложный механизм, получаешь профит. Относительно недавно также стало модно заменять человека куском кода. О, сколько благородных профессий может пасть под натиском информатизации. Особенно если учесть, что кусок кода в наше время способен не только на заранее определенное поведение, но и на «обучение» какому-то поведению.
Немного обобщим
Вообще говоря, такие сверхспособности для алгоритма, который олицетворяет наш кусок кода, называются не просто обучением, а машинным обучением (machine learning). Обычно мы подразумеваем, что только нечто, наделенное интеллектом, способно обучаться. И, как неудивительно, дисциплина машинного обучения входит в куда более общую дисциплину искусственного интеллекта (artificial intelligence a.k.a. AI)

Как явствует из картинки, многие задачи AI основываются на алгоритмах машинного обучения. Остается только выбрать что-нибудь веселое и не менее весело решить.
И пофантазируем
Допустим тебя, %username%, наняли специалистом по машинному обучению в компанию, которая владеет сайтом IMDb . И говорят мол, вот хотим, чтобы аки у русских иванов на их Кинопоиске, рецензии пользователей помечались цветом зеленым али красным в зависимости от того позитивная или негативная рецензия. И тут вы как бы понимаете, что необходимо взять неприличных размеров базу с рецензиями и выдать на-гора алгоритм, который хорошенько обучится и все их множество разобьет на два непересекающихся подмножества (класса), да так, чтобы вероятность ошибки была минимальна.
Как и человек, наш алгоритм может учиться либо на своих ошибках (обучение без учителя, unsupervised learning), либо на чужом примере (обучение с учителем, supervised learning). Но, в данном случае, сам он различить позитив и негатив не может, т.к. его никогда не звали на вечеринки и он мало общался с другими людьми. Стало быть, нужно раздобыть выборку уже размеченных на классы рецензий (обучающую выборку), дабы осуществить обучение на готовых примерах (прецедентах).
Итого, мы хотим решить задачу анализа мнений (sentiment analysis), относящуюся к задачам обработки естественного языка (natural language processing), обучив некий классификатор, который для каждой новой рецензии будет говорить нам позитивная она или негативная. Теперь нужно выбрать классификатор и закодить все это дело.
Боже, как наивно
Вообще, в дикой природе водится огромное количество разных классификаторов. Самое простое, что мы могли бы здесь придумать — это отнести все статьи, например, к позитивным. Результат: обучаться не нужно, точность классификатора 50%, интересность 0%.
А вот если подумать… Как мы выбираем класс, к которому отнесем очередной объект? Мы выбираем его так, чтобы вероятность принадлежности объекта к этому классу была максимальна (капитан!), т.е.

, где С это какой-то класс, а d — объект, в нашем случае это рецензия. Таким образом, мы пытаемся максимизировать апостериорную вероятность принадлежности рецензии к позитивному или негативному классу.
Увидев условную вероятность, сразу напрашивается применить к ней теорему Байеса, а так как мы все равно ищем максимум, то еще напрашивается отбросить, за ненадобностью, знаменатель, получив в итоге:

Все это классно, скажете вы, но откуда получать эти чудо-вероятности в реальной жизни? Ну с P все просто: если у вас есть обучающая выборка, которая адекватно отображает распределение классов, можете оценить:

, где n — количество объектов, относящихся к классу С, N — размер выборки.
С P(d|C) все чуть сложнее. Тут мы должны сделать «наивное» предположении о независимости отдельных слов в документе друг от друга:

и понять, что восстановление n одномерных плотностей задача куда более простая, чем одной n-мерной.
При этом по обучающей выборке можно оценить:

, где m — количество слов w в классе С, М — количество слов(а точнее говоря, токенов) в классе С. Так мы получили:

а вот уже такой классификатор называется наивным байесовским (naive Bayes classifier).
Пару слов о валидности наивного предположения о независимости. Такое предположение редко бывает верным, в данном случае оно, например, явно неверно. Но, как показывает практика, наивные байесовские классификаторы показывают на удивление хорошие результаты во многих задачах, в том числе в тех, где предположение о независимости, строго говоря, не выполняется.
Достоинствами наивного байесовского классификатора являются нечувствительность к размерам обучающей выборки, высокая скорость обучения и устойчивость к так называемому переобучению (overfitting — явление, при котором алгоритм очень хорошо работает на тренировочной выборке и плохо на тестовой). Поэтому их применяют либо когда исходных данных очень мало, либо когда таких данных очень много, и на первое место выходит скорость обучения. Недостатки: не самая лучшая точность, особенно если нарушается предположение о независимости.
Developers, developers, developers
А теперь для тех кто уже отчаялся увидеть код. В качестве обучающей выборки взята коллекция рецензий IMDb, подготовленная университетом Cornell (сотрудники которого и сами провели с этими данными занимательное исследование).
Самые интересные методы add_example и classify. Первый, соответственно, занимается обучением, восстанавливая нужные плотности вероятностей, второй — применяет полученную модель.
def add_example(self, klass, words):
"""
* Builds a model on an example document with label klass ('pos' or 'neg') and
* words, a list of words in document.
"""
self.docs_counter_for_klass[klass] += 1
for word in words:
self.token_counter_for_klass[klass] += 1
self.word_in_klass_counter_for[klass][word] += 1
Обучение весьма незамысловато — получаем слова из рецензии и ее помеченный класс. Считаем количество документов в классе n, количество слов в классе М и количество слов w в классе — m. Все, дальше классифицируем.
def classify(self, words):
"""
'words' is a list of words to classify. Return 'pos' or 'neg' classification.
"""
score_for_klass = collections.defaultdict(lambda: 0)
num_of_docs = sum(self.docs_counter_for_klass.values())
for klass in self.klasses:
klass_prior = float(self.docs_counter_for_klass[klass]) / num_of_docs
score_for_klass[klass] += math.log(klass_prior)
klass_vocabulary_size = len(self.word_in_klass_counter_for[klass].keys())
for word in words:
score_for_klass[klass] += math.log(self.word_in_klass_counter_for[klass][word] + 1)
score_for_klass[klass] -= math.log(self.token_counter_for_klass[klass] + klass_vocabulary_size)
sentiment = max(self.klasses, key=lambda klass: score_for_klass[klass])
return sentiment
Т.к. вероятности могут быть числами весьма маленькими, а мы все равно занимаемся максимизацией, то можно без зазрения совести все прологарифмировать:
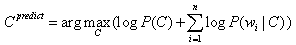
— это объясняет происходящее. Результирующим классов, соответственно, становится тот, что получил максимальный score.
def cross_validation_splits(self, train_dir):
"""Returns a lsit of TrainSplits corresponding to the cross validation splits."""
print '[INFO]\tPerforming %d-fold cross-validation on data set:\t%s' % (self.num_folds, train_dir)
splits = []
for fold in range(0, self.num_folds):
split = TrainSplit()
for klass in self.klasses:
train_file_names = os.listdir('%s/%s/' % (train_dir, klass))
for file_name in train_file_names:
example = Example()
example.words = self.read_file('%s/%s/%s' % (train_dir, klass, file_name))
example.klass = klass
if file_name[2] == str(fold):
split.test.append(example)
else:
split.train.append(example)
splits.append(split)
return splits
Для наиболее полного использования имеющихся данных применена перекрестная проверка (k-fold cross-validation): имеющиеся в наличии данные разбиваются на k частей, затем на k−1 частях данных производится обучение модели, а оставшаяся часть данных используется для тестирования. Процедура повторяется k раз, в итоге каждая из k частей данных используется для тестирования. Результирующая эффективность классификатора вычисляется просто как среднее.
Ну и дабы полностью достичь дзэна, прилагаю картинку, изображающую процесс обучения с учителем (в общем случае):

Что же из всего этого получилось?
$python NaiveBayes.py ../data/imdb1
[INFO] Performing 10-fold cross-validation on data set: ../data/imdb1
[INFO] Fold 0 Accuracy: 0.765000
[INFO] Fold 1 Accuracy: 0.825000
[INFO] Fold 2 Accuracy: 0.810000
[INFO] Fold 3 Accuracy: 0.800000
[INFO] Fold 4 Accuracy: 0.815000
[INFO] Fold 5 Accuracy: 0.810000
[INFO] Fold 6 Accuracy: 0.825000
[INFO] Fold 7 Accuracy: 0.825000
[INFO] Fold 8 Accuracy: 0.765000
[INFO] Fold 9 Accuracy: 0.820000
[INFO] Accuracy: 0.806000
С фильтрацией стоп-слов:
$python NaiveBayes.py -f ../data/imdb1
[INFO] Performing 10-fold cross-validation on data set: ../data/imdb1
[INFO] Fold 0 Accuracy: 0.770000
[INFO] Fold 1 Accuracy: 0.815000
[INFO] Fold 2 Accuracy: 0.810000
[INFO] Fold 3 Accuracy: 0.825000
[INFO] Fold 4 Accuracy: 0.810000
[INFO] Fold 5 Accuracy: 0.800000
[INFO] Fold 6 Accuracy: 0.815000
[INFO] Fold 7 Accuracy: 0.830000
[INFO] Fold 8 Accuracy: 0.760000
[INFO] Fold 9 Accuracy: 0.815000
[INFO] Accuracy: 0.805000
Оставляю читателю на подумать, почему фильтрация стоп-слов так повлияла на результат (ну т.е. почему почти вообще никак не повлияла).
Примеры
Если отойти от скупых цифр, что же мы получили на самом деле?
Для затравки:
"Yes, it IS awful! The books are good, but this movie is a travesty of epic proportions! 4 people in front of me stood up and walked out of the movie. It was that bad. Yes, 50 minutes of wedding...very schlocky accompanied by sappy music. I actually timed the movie with a stop watch I was so bored. There is about 20 minutes of action and the rest is Bella pregnant and dying. The end. No, seriously. One of the worst movies I have ever see"
Такая рецензия однозначно распознается, как негативная, что неудивительно. Интересней посмотреть на ошибки.
" `Strange Days' chronicles the last two days of 1999 in los angeles. as the locals gear up for the new millenium, lenny nero (ralph fiennes) goes about his business of peddling erotic memory clips. He pines for his ex-girlfriend, faith (juliette lewis ), not noticing that another friend, mace (angela bassett) really cares for him. This film features good performances, impressive film-making technique and breath-taking crowd scenes. Director kathryn bigelow knows her stuff and does not hesitate to use it. But as a whole, this is an unsatisfying movie. The problem is that the writers, james cameron and jay cocks ,were too ambitious, aiming for a film with social relevance, thrills, and drama. Not that ambitious film-making should be discouraged; just that when it fails to achieve its goals, it fails badly and obviously. The film just ends up preachy, unexciting and uninvolving."
Эта рецензия помечена, как положительная, но была распознана, как отрицательная. Тут можно задаться вопрос о корректности исходной пометки, потому что даже человеку, на мой взгляд, трудновато определить позитивна или негативна эта рецензия. Неудивительно, по крайне мере, почему классификатор отнес ее к негативной: unsatisfying, fails, badly, unexciting, uninvolving,- достаточно сильные индикаторы негатива, перевешивающие остальное.
Ну и, конечно, классификатор не понимает сарказма и с легкостью в таком случае принимает отрицательное за положительное:
"This is what you call a GREAT movie? AWESOME acting you say?Oh yeah! Robert is just so great actor that my eyes bleeding when I'm see him. And the script is so good that my head is exploding. And the ending..ohhh, you gonna love it! Everything is so perfect and nice - I dont got words to describe it!"
Заключение
Классификаторы, в том числе наивный байесовский, применяются во многих областях помимо анализа мнений: фильтрация спама, распознавание речи, кредитный скоринг, биометрическая идентификация и т.д.
Кроме наивного байесовского существует еще множество других классификаторов: перцептроны, деревья решений, классификаторы, основанные на методе опорных векторов(SVM), ядерные классификаторы (кernel сlassifiers) и т.д. А ведь кроме обучения с учителем есть еще обучение без учителя, обучение с подкреплением (reinforcement learning ), обучение ранжированию (learning to rank) и многое другое… но это уже совсем другая история
Данная статья написана в рамках конкурса статей студентов проекта Технопарк@ Mail.Ru
