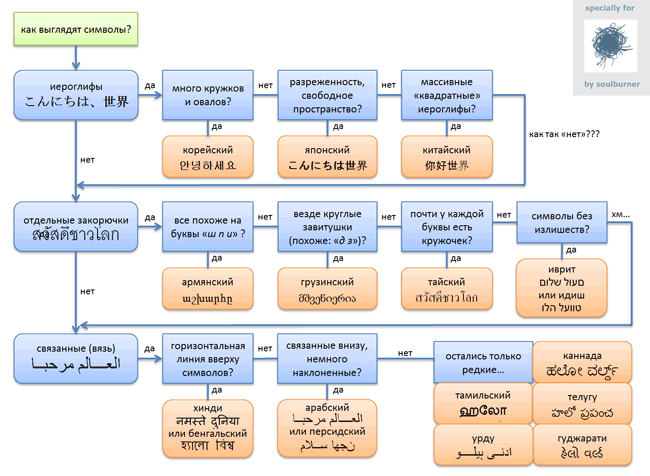
soulburner Jul 15 2012 at 17:19Как определить язык по виду иероглифов/закорючек?Reading time1 minViews188KTypography*Вот, задался таким вопросом… С помощью гугл транслейта и такой-то матери, родилась такая блок-схемка: картинка кликабельна Кому нужен сорец (в .docx): тутTags:иероглифышрифтыкитайцыяпонцыэто канал об анимеHubs:Typography