 Неоднократно слышал утверждение, что язык программирования изучать лучше всего в процессе создания чего-либо. Не мог с этим не согласиться, и решил, что это распространяется не только на язык, но и на всякие технологии сосуществующие с этим языком.
Неоднократно слышал утверждение, что язык программирования изучать лучше всего в процессе создания чего-либо. Не мог с этим не согласиться, и решил, что это распространяется не только на язык, но и на всякие технологии сосуществующие с этим языком. Протаптывать неизведанную дорожку самому непросто, гораздо легче изучить, как кто-то протаптывает эту дорожку перед тобой. К изучению документаций у меня не лежит душа, ей я пользуюсь как справочником, а изучать что то с нуля отнимает слишком много времени и сил, так как авторы оной обычно предполагают, что у читателя знания обширнее, практически все что нужно он уже знает. Велосипедные темы же освещают именно процесс обучения, хождение по граблям и все прочее. К сожалению, на интересные мне темы достаточно подробных статей не нашел, изучал урывками, и решил все-таки написать статью сам, в надежде упростить жизнь тем, кто может пойти следом.
Больше всего мне хотелось освоить процесс, или подход, ну или идеологию, если хотите, которая именуется TDD, aka Test-Driven Development. Также, в качестве вспомогательной технологии, в части тестов был использован тестовый фреймворк Moq. Забегая вперед, скажу, что полностью правильно разрабатывать не получилось, поскольку навыки «архитектора» у меня также нуждаются в опыте. Приходилось переделывать некоторые блоки, да и сами тесткейсы, которые я писал, еще не полностью осознавая, что и как класс должен делать. Однако дело сдвинулось с мертвой точки, опыт получен, и в следующий раз уже должно быть проще. Вторая технология, которую давно руки чесались освоить, это внедрение зависимостей и IoC контейнеры. В разработке я использовал наиболее импонирующий мне Autofac.
Тема для велосипедостроения
Выбирать долго не пришлось, решение пришло буквально само — писать свой логгер с фильтрацией и конфигурируемым форматом вывода. Свою первую статью я хотел написать об ASP.Net, и фреймворке MVC3. Хотя теперь уже имеет смысл перемещаться в сторону MVC4. Среди технологий, кстати, предполагалось использовать Entity Framework. На хабре уже есть статья на эту тему, но автор исчез, так и не доделав обещанного.
Итак, почему я прервался на логгер? В процессе создания того приложения, естественно, возникла необходимость логгирования. Мне посоветовали взять имеющийся в NuGet-ах NLog, но поизучав его, я пришел к выводу, что написание своего логгера не только интересно, но еще и оправдано. Сам не проверял, но, судя по отзывам в интернетах, log4net работает медленнее его, посему рассматривать его я не стал.
Сам я работаю в телекоме, и с логгером поработать мне уже пришлось, когда появилась необходимость в функциональности, которая в стандартных сислогах отсутствовала. Это фильтрация по идентификатору. Когда сайт обрабатывает 30 тысяч звонков в час, то, даже если баг воспроизводим на нем на 100%, найти ее в мегабайтах и даже гигабайтах логов не так уж просто. Да и не все системы позволяют хранить гигабайты логов, кое где есть системы, у которых в ротацию логов попадает лишь несколько минут траффика в час пик и сам звонок может быть больше по длине, то есть в лог может не попасть начало звонки или конец. Посему «сверху» и пришла идея — выделить нужное, пометив звонок, чтобы в логи попал только он один. Ну, или несколько звонков, но только на тот номер, где периодически случается этот баг. Сислог был успешно заменен на макрос, который сравнивает идентификатор в сессии со списком заданных оператором идентификаторов. Идентификатор привязывался как к уникальному адресу терминала, так и к набираемому номеру. В моем же ASP.Net приложении фильтровать предполагалось по userid. Конечно, тут это может быть и не очень оправдано, но раз уж я решил, что логгеру нужна эта фича, то так тому и быть.
Второй вело-повод я нашел, поизучав исходники NLog-а. В нем практически все действия совершаются в контексте вызывающего потока, асинхронно производится лишь непосредственная запись в target. Что, в чем я позже убедился, наносит немалый ущерб производительности.
Вынесение операций в отдельный поток
Эту операцию я сразу же инкапсулировал в отдельный класс. Класс запустит поток, в котором все сообщения будут обрабатываться, и позволит в этот поток эти сообщения передавать. Сообщение будет содержать текст лога, уровень, и прочую информацию. Нужно это для решения поставленной задачи — минимизировать количество действий в контексте потока, отправляющего логи.
За основу я взял пример ThreadSync из Language Samples, которые имеются в составе Visual Studio. Сначала интерфейс класса:
public delegate void ReceiveHandler<T>(T item);
public interface IQueued<T>
{
event ReceiveHandler<T> OnReceive;
event Action OnTimeout;
bool Active { get; }
void setTimeout(int timeout);
void Send(T msg);
void Terminate();
}
Флаг выставляется в начале внутреннего метода ThreadRun, и сбрасывается в конце. Событие OnReceive наступает в случае, когда потоком получено новое сообщение. Тип делегата события создан, чтобы избежать приведения типа аргумента. Таймаут создан для того, чтобы позволить не писать сразу на диск, а сначала в буфер, например в StringBuilder. Через указанное время после получения последнего сообщения будет один раз вызвано событие OnTimeout, чтобы последний полученный лог гарантированно попал на диск.
Варианта у класса два, можно выбрать в зависимости от каких либо причин. Один вариант запускает свой поток, но нуждается в вызове Terminate.
thread = new Thread(ThreadRun);
thread.Start();
Второй класс, реализующий тот же интерфейс, добавляет свой метод в стандартный ThreadPool. У него свои недостатки, в частности если основное приложение уже использует несполько потоков из пула, то этот поток может очень задержаться со стартом. Одна радость – его не надо завершать вызовом Terminate(), он закроется сам по закрытию приложения.
ThreadPool.QueueUserWorkItem(ThreadRun);
На вход конструктор принимает ManualResetEvent, который можно скормить нескольким классам, орудующим с потоками, а потом использовать его, как централизованное событие завершения приложения. В логгере я не стал этим пользоваться, но на всякий случай добавил такую возможность. Кроме события завершения, для работы также используется событие, означающее, что в очередь попало новое сообщение. Выглядит это так
EventWaitHandle[] events = new EventWaitHandle[2];
...
events[0] = new AutoResetEvent(false);
events[1] = terminateEvent ?? new ManualResetEvent(false);
Тут вполне очевидно, что задача метода Terminate в том, чтобы установить events[1] в единицу.
Для хранения переданных сообщений я использовал Queue queue; Метод Send() просто срисован с примера:
lock (queSync)
{
queue.Enqueue(msg);
}
events[0].Set();
Для приема же сообщений на другой стороне я решил прибегнуть к небольшой хитрости, чтобы максимально снизить время блокировки очереди «собирающим» потоком. Именно поэтому lock производится не на самой очереди, а на отдельно созданном объекте. Принимающий поток крутится внутри бесконечного цикла, выход из которого будет произведен, если индекс будет равен единице, что означает, что сработал events[1], вызванный либо из метода Terminate, либо извне, как я говорил ранее.
while ((index = WaitHandle.WaitAny(events, currentTimeout)) != 1)
Метод WaitAny блокирует поток до срабатывания одного из событий, либо таймаута, по умолчанию равного Infinite. То есть поток логгера будет спать и никак не влиять на производительность приложения, пока то не начнет посылать логи. При срабатывании в первую очередь мы проверяем был ли таймаут, и активируем соответствующее событие.
if (index == WaitHandle.WaitTimeout)
{
OnTimeout();
currentTimeout= Timeout.Infinite;
}
Вторая строчка здесь появилась именно благодяря юнит-тестам, при кодировании я ее проморгал. Далее, в противном случае, сообщения из очереди надо извлечь, и с каждым из них вызвать событие OnReceive. «Хитрость», о которой я говорил ранее, видна в коде.
Queue<T> replacement = new Queue<T>();
Queue<T> items;
lock (queSync)
{
items = queue;
queue = replacement;
}
foreach (T t in items)
{
OnReceive(t);
}
currentTimeout = timeout;
По всем критичным моментам этого класса, ну или модуля, я прошелся, полностью его код, как и всех остальных классов, можно будет найти в репозитории, ссылку повешу в конце статьи и далее этот дисклеймер повторять не буду,
Уже во время написания статьи в голову пришла шальная идея сделать тоже самое используя ConcurrentQueue, естественно уже без вышеописанной хитрости, но зато полностью без блокировки. И при этом надо как то оставить возможность создания обоих типов потоков. Поэтому принято решение инкапсулировать создание потока позади своего интерфейса, который я назову IStarter, состоять классы будут из единственного метода каждый. Кстати, тут вполне можно было бы воспользоваться лямбда-выражением, но эстет во мне воспротивился этому. В результате то, что должно получиться будет похоже на известный паттерн бридж, где «по эту сторону моста» два класса, один с блокировками, другой с интерлоком, а «по ту сторону моста» два варианта запуска потока для них, и использоваться они между собой смогут в любых комбинациях. Вся прелесть идеологии «взаимодействовать с интерфейсом, а не с реализацией»(с)GoF тут выражается не только в том, что остальные классы, взаимодействующие с данным не надо будет трогать, но и в том, что юнит-тесты так же не надо менять. Совсем-совсем. Нужно только лишь изменить полиморфный метод создания конкретных объектов, который этим тестам скормит все варианты.
Зачатки TDD
Немного потеоретизирую на тему. Поначалу, на примере класса, который был первым, да и со вторым было то же самое, поведение разработки не получилось подвести под TDD, где сначала тесты, потом сам код. Путь моей разработки проходил через следующие этапы — написание рабочего кода, затем написание тесткейсов, затем корректирование, как первого, так и второго, доведение до кондиции. После чего тесты «признаются верными», и рефакторинг, который позже следует, вполне может на них опираться. Почему я считаю, что этот подход имеет право на жизнь, по крайней мере, для новичка: Если рассмотреть простейшую функцию A = B + C, то тестирование данной функции напрашивается формулой С1 = А — В, и далее вывод успешности теста на основе сравнения С == С1. Ошибки тут могут содержаться как в тестируемой функции, так и в тестирующей. Даже более того, поскольку в ней больше действий, ошибка более вероятна. На этом моменте можно задаться вопросом, зачем вообще тогда нужно тестирование, но ответ естественно уже есть, все сформулировано до нас. Чтобы тест показал «пройдено», нужно чтобы выполнилось одно из условий. Отсутствие ошибок в обеих функциях, или одновременное наличие ошибки и там и там. Вероятность того, что возникнут обе ошибки меньше, чем вероятность каждой ошибки в отдельности, тем более самого наличия тут недостаточно, надо еще, чтобы ошибки были синергичны, то есть компенсировали влияние друг друга, вероятность чего еще ниже. То есть, все усилия по написанию тестов напрямую направлены на снижение вероятности ошибок. Правда, при написании и тестов и кода одним и тем же человеком, вероятность того, что он допустит одну и ту же ошибку несколько выше. Ну да ладно, как мне кажется, для велосипеда и то, что есть — уже хорошо.
Перейдем к написанию первых тестов. Для этого сначала создаем шаблон теста, нажав на имени интерфейса IQueued правой кнопкой и выбрав соответствующий пункт меню. Итак, что же нужно, чтобы протестировать этот класс. Тестировать его предполагается в изоляции, то нужно сделать моки(имитаторы) классов, которые с сабжевым классом взаимодействуют. Еще один момент — поскольку целью теста выбран интерфейс, а конкретных классов, которые надо протестировать, вначале было два, а позднее стало 4 комбинации 2 по 2, то свежесозданный тестовый класс имеет смысл сразу наградить модификатором abstract и добавить ему generic параметр .
[TestClass()]
public abstract class IQueuedTest<T>
Поскольку класс абстрактный, непосредственно на нем тесты производиться, естественно, не будут, вместо этого будут выполняться все тестовые классы, унаследованные от него.
В первую очередь нам нужен имитатор класса потребителя услуги.
class Tester<T1>
Класс этот будет подписываться на события тестируемого класса, считать срабатывания событий, и запоминать, что в этом событии пришло.
public Tester(IQueued<T1> tested)
{
tested.OnReceive += Received;
tested.OnTimeout += TimeOut;
}
void TimeOut()
{
timedCount++;
}
void Received(T1 item)
{
Thread.Sleep(delay);
receivedCount++;
lastItem = item;
}
Кроме этого внутреннего класса, понадобятся методы для создания конкретных объектов, которые мы обяжем всех наследников переопределить.
protected abstract IQueued<T> createSubject();
protected abstract T CreateItem();
Итак, собственно к написанию тестов. Кстати, при прочтении подобных статей, я замечал, что авторы опускают грабли, и приводят уже готовое решение. Я же постараюсь на некоторых граблях остановиться чуть подробнее. Первая проблема, с которой я столкнулся, это та самая задержа старта в пуле потоков. При запуске приложения, пул держит лишь несколько потоков, а новые запускает лишь с задержкой, которая измеряется в десятых долях секунды. А тестовый фреймворк, похоже исполняет тесты параллельно. Из-за этого тесты с «ручным» потоком проходили успешно, а с потоком из пула некоторые проходили, некоторые валились. Посему есть два варианта, выделить все тесты в один и тот же «длинный» метод, который будет исполняться быстрее, но выдаст лишь один общий вердикт, либо придумывать обходные маневры. Я придумал следущее:
void ActivationTestHelper(Tester<T> tester, IQueued<T> subject)
{
int retry = 30;
while (!subject.Active && retry > 0)
{
retry--;
Thread.Sleep(SleepDelay);
}
Assert.AreEqual(true, subject.Active);
}
30 попыток «подождать» пока поток не активируется, после чего только приступать к тесту. Хелпер будет вызываться непосредственно после создания.
И, еще раз – итак, к написанию тестов. Первый тест на отправку-получения сообщения. Поскольку мы знаем, что задача класса – передать другому потоку, то надо убедиться, что класс тестер не получает сообщение в контексте передающего потока, потом убедиться, что успешно получает после. Именно для этого(для первого), кстати, в коде метода Received у тестера стоит задержка, в 50мс. Если эта задержка произойдет в вызывающем потоке, то первый Assert зафейлит тест.
[TestMethod()]
public void SendTest()
{
var subject = createSubject();
var tester = new Tester<T>(subject);
ActivationTestHelper(tester, subject);
T item = CreateItem();
tester.delay = SleepDelay;
subject.Send(item);
Assert.AreEqual(0, tester.receivedCount);
Далее, чтобы убедиться, что сообщение передано, мы подождем 100мс и проверим полученное. В принципе эти значения можно и уменьшить, главное, чтоб вторая задержка была больше первой, но тут, я думаю это непринципиально. Не забыть завершить поток, чтобы «дать дорогу» следующим тестам.
Thread.Sleep(SleepDelay2);
Assert.AreEqual(1, tester.receivedCount);
Assert.IsTrue(tester.lastItem.Equals(item));
subject.Terminate();
}
Далее, тест таймаута. Также создадим объекты, выполним хелпер активации. Зададим таймаут и проверим также, что он не вызвался в контексте вызывающего потока, но вызвался после. Причем только один раз.
[TestMethod()]
public void TimeoutTest()
{
var subject = createSubject();
var tester = new Tester<T>(subject);
subject.setTimeout(SleepDelay);
ActivationTestHelper(tester, subject);
T item = CreateItem();
subject.Send(item);
Assert.AreEqual(0, tester.timedCount);
Thread.Sleep(SleepDelay3);
Assert.AreEqual(1, tester.timedCount);
}
Для этого теста задана задержка в 200мс, вчетверо больше значения таймаута, и именно этот тест у меня поймал мою первую ошибку-недопечатку, о которой я говорил ранее. Этим и приятны оказались юнит-тесты, что абсолютное большинство ошибок не доходит не только до «продакшена», а даже до альфа триала. Эти ошибки, естественно, были бы там обнаружены, но работу, потраченную на написание тестов, все равно бы пришлось совершить уже для отладки. Получился этакий прием тайм-менеджмента, который перемещает некий объем работ из периода, когда аврал, в период «ленивой» разработки. И это все даже без упоминания о неоценимом подспорье в рефакторинге, который я сам себе придумывал по ходу дела.
Оставшийся тест – завершение потока. Надо убедиться, что поток остановлен и ничего никуда не передается. Опустив общие для всех тестов шаги, получаем следующее:
public void TerminateTest()
{
...
subject.Terminate();
subject.Send(item);
Thread.Sleep(SleepDelay3);
Assert.AreEqual(0, tester.receivedCount);
Assert.AreEqual(0, tester.timedCount);
}
В интерфейсе всего три теста, но конкретных класса два, еще два варианта запуска потока и сверх этого, я решил раздельно проверить, как оно работает и с классами и со структурами в качестве передаваемого сообщения. Для чего создаются 8 конкретных тестовых классов, один из которых я приведу, а количество конкретных тесткейсов получается 24. Тестовая структура:
public struct TestMessageStruct
{
public string message; //object reference field
public int id; //value field
}
И собственно конкретный тестовый класс, который тестирует вариант: блокируемая очередь, обычный поток, структура.
[TestClass()]
public class IQueuedLockRegTest : IQueuedTest<TestMessageStruct>
{
protected override IQueued<TestMessageStruct> createSubject()
{
return new LockQueued<TestMessageStruct>(new RegularThreadStarter());
}
protected override TestMessageStruct CreateItem()
{
var item = new TestMessageStruct();
var rnd = new Random();
item.id = rnd.Next();
item.message = string.Format("message {0}", item.id);
return item;
}
}
Именно конкретные тестовые классы, создающие конкретные подопытные объекты и пришлось переделать в связи с этим, если это можно так назвать, рефакторингом. И еще пришлось увеличить их количество вдвое, но, как видно, это занимает существенно меньше времени и сил, чем при написании и обдумывании самих тестов.
Интерфейс логгера и первый слой фильтрации
Интерфейс наружу я решил сделать как у NLog, не мудрствуя лукаво. Только назвал статический класс LogAccess, почему-то по смыслу он мне показался более логичным. Сам он ничего не делает, только проксирует вызовы. В тестах он по этой причине не участвует, посему останавливаться на нем не буду, лишь перечислю основные из методов видных «снаружи», первый метод позволяет получить собственно логгер, чтобы спамить сообщения, следующие два управляют фильтрацией по уровню, последние по id. Имя, или категория, логгера, присутствующая в первом слое фильтрации, означает, что выполнение этой фильтрации до прохождения через класс, описанный в предыдущем разделе, то есть уровень можно отдельно задавать для каждой категории логов. Отсутствие же категории на втором слое фильтрации соответственно означает, что это фильтрация производится уже позади, в потоке логгера.
Logger GetLogger(string category)
void SetLevel(string category, int level)
void SetLevelForAll(int level)
void FilterAddID(int id)
void FilterRemoveID(int id)
Второй класс, который виден извне, это LogLevel. Уровни по смыслу я взял из телекома. Тут решил относительно NLog упростить, и использовать обычный int в качестве уровня, чтобы не мудрить со сравнением уровней и т.п.
Добавил лишь уровень All, чтобы сделать два уровня дебага, сокращенный и подробный, чего порой не хватало на практике.
public const int Invalid = 0;
public const int Always = 1;
public const int Fatal = 2;
public const int Error = 3;
public const int Warning = 4;
public const int Info = 5;
public const int Event = 6;
public const int Debug = 7;
public const int All = 8;
public const int Total = 9;
Также включил в класс свойство Default, для задания уровня из LogAccess.
Ну и самое главное, что видно снаружи, это интерфейс Logger. Умышленно не стал добавлять ему приставку I. Некоторые методы из него приведу.
public interface Logger
{
/// <summary>
/// Method for unrecoverable errors.
/// </summary>
/// <param name="message"></param>
/// <param name="ex"></param>
void Fatal(string message, Exception ex = null);
/// <summary>
/// Method for external errors, such as user input or file access.
/// </summary>
/// <param name="message"></param>
/// <param name="id"></param>
/// <param name="ex"></param>
void Warning(string message, int id = 0, Exception ex = null);
/// <summary>
/// Method for regular debug logging.
/// </summary>
/// <param name="message"></param>
/// <param name="id"></param>
void Debug(string message, int id = null);
}
Методы для ошибок не привязаны к идентификаторам, только уровни Warning и выше.
Далее, рассмотрю класс конкретного логгера, чтобы показать. каким способом достигается собственно минимализация производительности, отнимаемой логгером у вызывающего потока. Кстати у интерфейса логгера есть расширенная версия, не видная снаружи, добавляющая метод SetLevel.
class CheckingLogger : InternalLogger
{
bool[] levels = new bool[LogLevel.Total];
Sender send;
string category;
public CheckingLogger(string category, Sender sender, int level)
{
this.send = sender;
this.category = category;
SetLevel(level);
}
public void SetLevel(int level)
{
for (int n = LogLevel.Fatal; n < LogLevel.Total; n++)
{
levels[n] = (n <= level);
}
}
public void Error(string message, Exception ex = null)
{
if (levels[LogLevel.Error])
{
send(new LogItem(category, LogLevel.Error, message, ex: ex));
}
}
Для рассмотрения достаточно одного спамящего метода, видно, что он проверяет булевое значение из массива, и отсылает посредством делегата Sender. Второй вариант логгера вместо булевого массива использует массив Sender-ов, в выключенный уровень вставляется делегат на пустой метод, а в методе отсылки отсутствует проверка, сразу посылка. По результатам тестирования разница в производительности незначительная, возможно тестирование на разных платформах тут дало бы ответ. Тесты логгеров достаточно просты, проверяется ушло ли в Sender сообщение, тогда, когда должно, и когда не должно. Тут я тоже наткнулся на опечатки и ошибки копипаста, т.к. много почти одинаковых методов, разницы беглым взглядом не видно.
Не придумал в какой раздел вписать класс, точнее структуру LogItem, использующуюся для собственно передачи логов, приведу здесь, опуская конструктор, только наполнение. Из него, кстати, видно, что id для одного сообщения можно задать более одного, это нужно либо для броадкаста, либо, в случае звонка, чтобы указать два идентификатора: звонящего и отвечающего на звонок. Методы в предыдущих классах продублированы с этой целью, только обделены вниманием.
struct LogItem
{
public readonly String category;
public readonly String message;
public readonly int[] ids;
public readonly int level;
public readonly Exception ex;
public readonly DateTime time;
}
Внедрение зависимостей
В этом разделе я приведу пример использования IoC контейнера. Следующий на очереди рассматриваемый класс — контейнер логгеров. Имя с контейнером IoC не связано, просто совпало. Он предоставляет метод GetLogger, куда и проксируется метод класса LogAccess. NLog, судя по комментариям в коде, не гарантирует того, что дважды вызванный метод GetLogger с одной и той же категорией даст один и тот же экземпляр логгера. Я же подумал и решил, что этот метод не будет узким местом, и поставил общую синхронизацию на нем, в этом случае экземпляр должен быть гарантировано одним и тем же. Контейнер логов хранит все ранее созданные логгеры и раздает им SetLevel, так же проксируемый из LogAccess.
Итак, создаем IoC контейнер, дальнейшая конфигурация помещается между следующими двумя строчками:
var builder = new ContainerBuilder();
IContainer container = builder.Build();
Из вышеописанного понятно, что класс должен быть синглтоном. Достигается это достаточно просто:
builder
.RegisterType<LoggerContainer>()
.SingleInstance();
И следующим методом мы можем получить ссылку на наш синглтон.
Container
.Resolve<LoggerContainer>();
Чтобы контейнер логов сам мог воспользоваться услугами IoC контейнера из которого создан, я добавил ему в конструктор параметр IComponentContext. Это позволяет вынести создание класса наружу, и менять конкретные классы, например на классы с расширенной функциональностью, не меняя использующий код, а лишь изменением конфигурации, которую в т.ч. можно и не задавать в коде вообще, а подгружать из xml. Собственно эта замена внутреннего создания на внешнее создание и называется внедрением зависимости. Собственно, метод, который получает с контекста конкретный логгер:
private InternalLogger CreateLogger(string category)
{
return context
.Resolve<InternalLogger>(new NamedParameter[]{
new NamedParameter("category", category),
new NamedParameter("level",LogLevel.Default)
});
}
Кроме этого, данный пример показывает, как задать конкретному классу параметры для конструктора из места вызова, а не в конфигурации контейнера, которая в данном случае остается такой же простой, как и в предыдущем случае. Отличие лишь в том, что у нас не синглтон и точка доступа здесь интерфейс, а не сам класс.
builder
.RegisterType<CheckingLogger>()
.As<InternalLogger>();
Тут виден некоторый негатив, с которым я не знаю, как дальше жить, разве что в комментариях к интерфейсу писать какие входные параметры по имени и типу должны присутствовать в конструкторе конкретного класса. Трудно диагностируемые ошибки, которые в обычном случае отсеял бы компилятор, просто таки ждут, чтобы тут случиться. Изменяя конфигурацию контейнера, об этом можно и не узнать, ибо для этого нужно будет делать поиск референсов на интерфейс. Вероятно в этом случае лучше использовать «классическую» фабрику.
Далее о том, что дает использование IoC: контейнера при юнит-тестировании. Для теста можно и нужно создать свой контейнер:
[TestClass()]
public class LoggerContainerTest
{
IContainer testContainer;
public LoggerContainerTest()
{
var builder = new ContainerBuilder();
builder
.Register<LoggerContainer>((c, p) => new LoggerContainer(c.Resolve<IComponentContext>()));
builder
.RegisterType<LoggerMock>()
.As<InternalLogger>();
testContainer = builder.Build();
}
Здесь проиллюстрирована еще одна фича, которая есть в Autofac, он позволяет сконфигурировать старый добрый new, который собственно и будет вызываться при Resolve, что работает, естественно, существенно быстрее, чем рефлексия.
Осталось привести фрагмент одного из тестовых методов.
LoggerContainer lc=
testContainer
.Resolve<LoggerContainer>();
var logger1 = lc.GetLogger(cat1);
var logger2 = lc.GetLogger(cat2);
var logger3 = lc.GetLogger(cat1);
Assert.AreEqual(logger1, logger3);
Assert.AreNotEqual(logger1, logger2);
Тестовый фреймворк Moq
Еще одна полезная технология, позволяющая упростить написание тестов. Я покажу ее применение на примере следующего класса, который я назвал сборщиком логов или LogCollector-ом. Он использует тот самый IQueued для развязки с отсылающими потоками, осуществляет фильтрацию по идентификатору, и второй зависимостью имеет класс записывающий в файл и осуществляющий ротацию.
Не буду подробно расписывать, как он работает, все достаточно просто и очевидно, остановлюсь в общих чертах еще на одном классе, который перед записью в файл осуществляет конструирование строки из LogItem. Его я решил сделать конфигурируемым, давно было интересно решить такую задачу.
Пример конфигурации NLog: layout="${longdate} ${uppercase:${level}} ${message}".
И пример конфигурации моего логгера LogMessageFormat=\d \l \m\r\n.
Выводится в точно таком же виде, дата, уровень, само сообщение и перевод строки. Специально подгонял формат вывода, чтобы можно было непосредственно сравнивать производительность. Также именно в этой строке я сделал возможность добавлять идентификатор, исключение с его стектрейсом, ну и прозвольные строки между всеми этими идентификаторами. Конструирование идет по цепочке, каждый следующий конструктор накидывает в StringBuilder из передаваемого LogItem свою часть сообщения. Цепочка выстраивается один раз, при распарсивании задающей строки.
Основная задача класса достаточно проста, поэтому не буду приводить код, ее осуществляющий, немного остановлюсь на фильтрации. Поскольку тут также стоит задача синхронизации, то есть вызов метода, добавляющего или удаляющего идентификатор, происходит из другого потока. Один способ — блокировать список, ну или HashSet, окажет влияние на производительность. Я же пошел немного другим путем, тоже давно видел такую возможность, предоставляемую языком и хотел найти ей применение. Суть решения в передаче анонимного метода Action через неблокируемую очередь. filterQue = new ConcurrentQueue<Action<HashSet>>();
Фильтрующий метод при каждой попытке фильтрации проверяет пуста ли очередь, что должно работать быстрее, чем захват монитора, и если она не пуста, то выполняет полученный метод в контексте потока логгера.
Action<HashSet<int>> refresh;
while (!filterQue.IsEmpty)
{
if (filterQue.TryDequeue(out refresh) && refresh != null)
{
refresh(filter);
}
}
Вызывающий же метод, вместо обращения непосредственно к сету, кладет нужный делегат в очередь.
filterQue.Enqueue((x)=>
{
x.Add(id);
});
Возвращаясь к Moq — в вышеописанных классах я создавал моки самостоятельно, что требует достаточно много дополнительного кода, и может быть неудобно, да и некрасиво, в особенности когда нужно протестировать единственный метод класса. Moq позволяет автоматически создать класс либо реализующий заданный интерфейс, либо наследующий заданный класс с переопределением всех виртуальных методов. Тут сразу видно ограничение — нельзя сделать мок на класс с невиртуальными методами. Но, как завещали нам GoF, программировать нужно «к интерфейсу», то есть желательно все классы должны быть снабжены оным, что, вобщем-то и позволяет применять все вышеописанные приемы и технологии, не считая того, что облегчает, и формализует чтоли, разработку вообще.
Еще один нюанс работы с Moq — при создании тестов, в некоторых случаях студия сама вносит в сборку атрибут, позволяющий доступ к internal классам из сборки тестового проекта, иногда надо вносить самому, а для того, чтобы Moq также имел доступ к классам и интерфейсам, которые нужно сымитировать, надо добавить доступ и для него. Для этого в проекте надо найти файл AssemblyInfo.cs и добавить, либо модифицировать строчку, чтобы она выглядела следующим образом:
[assembly: System.Runtime.CompilerServices.InternalsVisibleTo("LoggerTest"),
System.Runtime.CompilerServices.InternalsVisibleTo("DynamicProxyGenAssembly2")]
Первое, что нужно протестировать, это чтобы сборщик передал полученное сообщение в класс, создающий развязку потока.
На само сообщение мок решил не делать, поскольку он этим классом только передается туда-сюда, и никак с ним не контактирует, не вызывает его методы, не считывает его поля.
LogItem message = new LogItem(category, level, msg, ids, GetException());
var qThread = new Mock<IQueued<LogItem>>(MockBehavior.Strict);
var writer = new Mock<ILogWriter>(MockBehavior.Strict);
qThread
.Setup(s => s.Send(It.IsAny<LogItem>()));
writer
.Setup(s => s.GetTimeout())
.Returns(timeout);
qThread
.Setup(s => s.SetTimeout(It.IsAny<int>()));
LogCollector target = new LogCollector(qThread.Object, writer.Object);
qThread
.Verify(s => s.SetTimeout(It.Is<int>(a => a == timeout)));
target.Send(message);
qThread
.Verify(s => s.Send(It.Is<LogItem>(i => i.Equals(message))), Times.Once());
}
На случай, если нужны пояснения: первые две строчки создают ими таторы зависимостей. Параметр Strict означает, что мок выбросит исключение, если у классов будут вызваны методы, которые не сконфигурены перед использованием, тем самым зафейлив тест.
Следующий вызов маркирует метод Send у IQueued мока, обозначая, что он будет вызван в процессе теста. Тут также можно указать предусловия, если методов несколько, то после теста можно все предусловия проверить вызовом VerifyAll(). Я же остановился на подробном, избыточном описании теста. Следующая строчка означает, что должен быть вызван метод GetTimeout, и также указывает моку, что он должен вернуть. Следующая строчка также маркирует метод SetTimeout.
Далее мы создаем объект сборщика, и скармливаем ему его зависимости, после чего убеждаемся, что сборщик вызвал GetTimeout у одной зависимости и передал значение в другую зависимость. Тут лучше было создать отдельный тестметод для тестирования конструктора, но я оставил как есть, беспричинно, спонтанно. Далее мы посылаем сообщение, и убеждаемся, что оно было переправлено в развязку.
Тут уже видно, что код теста является законченным, и не вынуждает при ревью или редизайне смотреть дополнительные файлы с объявленными вручную моками, а зачит сокращает потенциальные временные издержки, что само по себе уже достаточно веская причина использовать Moq.
Нагрузочное тестирование
Я ожидал увидеть превосходство своего подхода перед NLog, готов был корпеть над микрооптимизациями, экономить копейки ради того, чтобы оправдать ожидания еще чуть лучше. Но результаты уже первых тестов меня поразили, отбив такое желание.
Для нагрузочного теста я создал консольное приложение в котором брал логгер и в цикле слал в него сообщения.
var log = SharpLogger.LogAccess.GetLogger("flooder " + tid);
foreach (var x in Enumerable.Range(0, messageCount))
{
log.Info("Message", x);
if (x % 1000 == 0)
Thread.Sleep(0);
}
И точно такой же метод для NLog.
var log = NLog.LogManager.GetLogger("flooder " + tid);
foreach (var x in Enumerable.Range(0, messageCount))
{
log.Info("Message");
if (x % 1000 == 0)
Thread.Sleep(0);
}
В методе виден tid, означающий, что выполнение происходит в несколько потоков.
Тестов я, конечно же, провел немало, но думаю, что вполне достаточно привести один тест. Три потока посылают по 200 тысяч сообщений. На скриншоте таскменеджера загрузка процессора. Первый маленький всплеск — мой логгер, далее, через 5 секунд задержки — работа NLog. Результирующие логфайлы получились идентичны, за исключением несовпадающего времени.
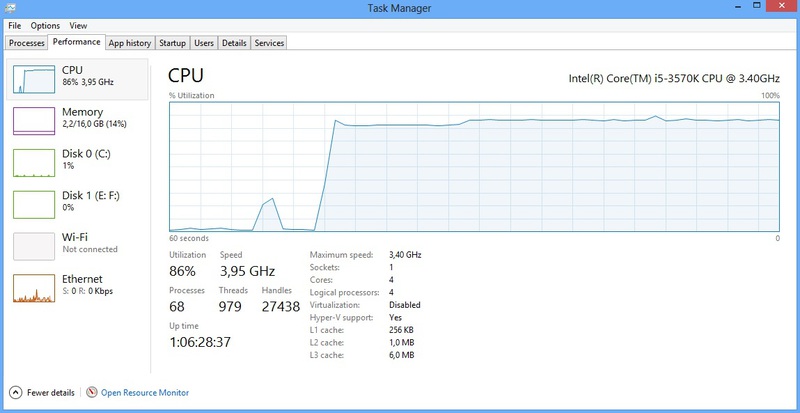
Еще также приведу говорящий сам за себя результат замера самой тестовой программой.
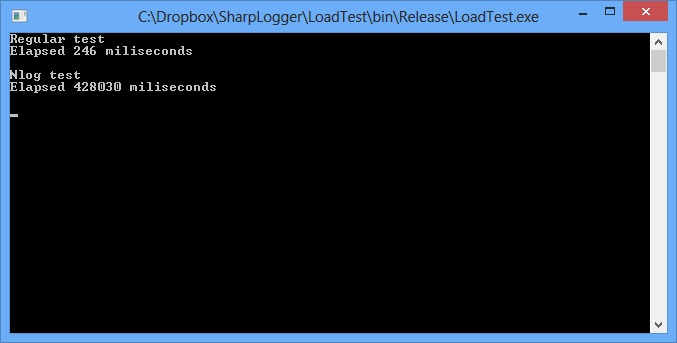
При перекомпиляции под x64 результат почти не меняется.
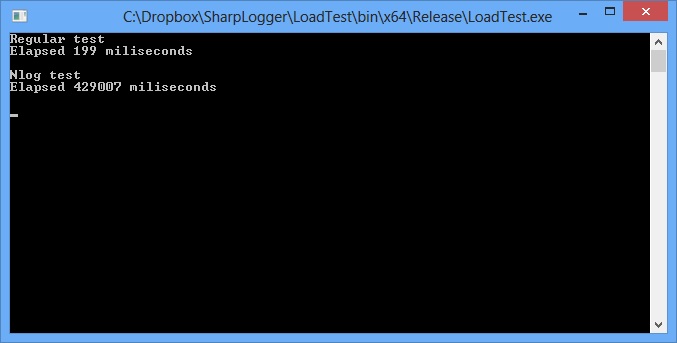
Конечно нужно упомянуть один нюанс — ведь я использую дополнительный поток, который не использует Nlog, и замеряю я только то процессорное время, которое операция отсылки отняла у вызывающих потоков, а процессорную нагрузку, которую создает этот поток, обхожу стороной. На это я тоже решил посмотреть, запустив тест уже из 40 потоков, отсылающих по полмиллиона сообщений.

Результат, который выдала программа — 7.15 секунд., но на графике видно, что поток логгера еще примерно 25 секунд отрабатывал запись в файл. Это, несомненно, недостаток, поскольку и программа может завершиться раньше логгера, до полной записи, что исключено в случае NLog и, дополнительно к этому, поток будет есть один процессор полностью даже тогда, когда нагрузка в основной программе уже кончилась. Утешительным моментом тут является то, что NLog при таком количество логов убъет процессор на шесть часов по примерным прикидкам, что дает основание с указанным недостатком примириться.
И еще один момент, который надо бы упомянуть — влияние неблокирующей очереди на производительность относительно обычной очереди с блокировкой.
Делал два теста, в первом 3 потока слали по 15 миллионов сообщений, неблокирующая очередь сократила замеренное время с 22.2 секунды до 17.8. При увеличении количества потоков до 30, и при сохранении общего количества сообщений, то есть по 1.5 миллиона на поток, очередь с блокировкой еще чуть замедлила выполнение теста до 23.7 секунд, а неблокирующая же наоборот немного ускорила до 17.4, увеличив разрыв.
Как видно по скриншотам, тестирование проводилось на 4х ядерном i5 с частотой 4ГГц, на windows 8.
Проект можно скачать с гитхаба по ссылке https://github.com/repinvv/SharpLogger
Ошибки, опечатки и прочие комментарии – велкам.
