В последнее время термин “NoSQL” стал очень модным и популярным, активно развиваются и продвигаются всевозможные программные решения под этой вывеской. Синонимом NoSQL стали огромные объемы данных, линейная масштабируемость, кластеры, отказоустойчивость, нереляционность. Однако, мало у кого есть четкое понимание, что же такое NoSQL хранилища, как появился этот термин и какими общими характеристиками они обладают. Попробуем устранить этот пробел.

Самое интересное в термине, что при том, что впервые он стал использоваться в конце 90-х, реальный смысл в том виде, как он используется сейчас, приобрел только в середине 2009. Изначально так называлась опенсорсная база данных, созданная Карло Строззи, которая хранила все данные как ASCII файлы и использовала шелловские скрипты вместо SQL для доступа к данным. С “NoSQL” в его нынешнем виде она ничего общего не имела.
В июне 2009 в Сан-Франциско Йоханом Оскарссоном была организована встреча, на которой планировалось обсудить новые веяния на ИТ рынке хранения и обработки данных. Главным стимулом для встречи стали новые опенсорсные продукты наподобие BigTable и Dynamo. Для яркой вывески для встречи требовалось найти емкий и лаконичный термин, который отлично укладывался бы в Твиттеровский хэштег. Один из таких терминов предложил Эрик Эванс из RackSpace — «NoSQL». Термин планировался лишь на одну встречу и не имел под собой глубокой смысловой нагрузки, но так получилось, что он распространился по мировой сети наподобие вирусной рекламы и стал де-факто названием целого направления в ИТ-индустрии. На конференции, к слову, выступали Voldemort (клон Amazon Dynamo), Cassandra, Hbase (аналоги Google BigTable), Hypertable, CouchDB, MongoDB.
Стоит еще раз подчеркнуть, что термин “NoSQL” имеет абсолютно стихийное происхождение и не имеет общепризнанного определения или научного учреждения за спиной. Это название скорее характеризует вектор развития ИТ в сторону от реляционных баз данных. Расшифровывается как Not Only SQL, хотя есть сторонники и прямого определения No SQL. Сгруппировать и систематизировать знания о NoSQL мире попытались сделать Прамод Садаладж и Мартин Фаулер в своей недавней книге “NoSQL Distilled”.
Общих характеристик для всех NoSQL немного, так как под лэйблом NoSQL сейчас скрывается множество разнородных систем (самый полный, пожалуй, список можно найти на сайте http://nosql-database.org/). Многие характеристики свойственны только определенным NoSQL базам, это я обязательно упомяну при перечислении.
1. Не используется SQL
Имеется в виду ANSI SQL DML, так как многие базы пытаются использовать query languages похожие на общеизвестный любимый синтаксис, но полностью его реализовать не удалось никому и вряд ли удастся. Хотя по слухам есть стартапы, которые пытаются реализовать SQL, например, в хадупе (http://www.drawntoscalehq.com/ и http://www.hadapt.com/ )
2. Неструктурированные (schemaless)
Смысл таков, что в NoSQL базах в отличие от реляционных структура данных не регламентирована (или слабо типизированна, если проводить аналогии с языками прогаммирования) — в отдельной строке или документе можно добавить произвольное поле без предварительного декларативного изменения структуры всей таблицы. Таким образом, если появляется необходимость поменять модель данных, то единственное достаточное действие — отразить изменение в коде приложения.
Например, при переименовании поля в MongoDB:
Если мы меняем логику приложения, значит мы ожидаем новое поле также и при чтении. Но в силу отсутствия схемы данных поле totalSum отсутствует у других уже существующих объектов Order. В этой ситуации есть два варианта дальнейших действий. Первый — обойти все документы и обновить это поле во всех существующих документах. В силу объемов данных этот процесс происходит без каких-либо блокировок (сравним с командой alter table rename column), поэтому во время обновления уже существующие данные могут считываться другими процессами. Поэтому второй вариант — проверка в коде приложения — неизбежен:
А уже при повторной записи мы запишем это поле в базу в новом формате.
Приятное следствие отсутствия схемы — эффективность работы с разреженными (sparse) данными. Если в одном документе есть поле date_published, а во втором — нет, значит никакого пустого поля date_published для второго создано не будет. Это, в принципе, логично, но менее очевидный пример — column-family NoSQL базы данных, в которых используются знакомые понятия таблиц/колонок. Однако в силу отсутствия схемы, колонки не объявляются декларативно и могут меняться/добавляться во время пользовательской сессии работы с базой. Это позволяет в частности использовать динамические колонки для реализации списков.
У неструктурированной схемы есть свои недостатки — помимо упомянутых выше накладных расходов в коде приложения при смене модели данных — отсутствие всевозможных ограничений со стороны базы (not null, unique, check constraint и т.д.), плюс возникают дополнительные сложности в понимании и контроле структуры данных при параллельной работе с базой разных проектов (отсутствуют какие-либо словари на стороне базы). Впрочем, в условиях быстро меняющегося современного мира такая гибкость является все-таки преимуществом. В качестве примера можно привести Твиттер, который лет пять назад вместе с твиттом хранил лишь немного дополнительной информации (время, Twitter handle и еще несколько байтов метаинформации), однако сейчас в дополнение к самому сообщению в базе сохраняется еще несколько килобайт метаданных.
(Здесь и далее речь идет в-основном о key-value, document и column-family базах данных, graph базы данных могут не обладать этими свойствами).
3. Представление данных в виде агрегатов (aggregates).
В отличие от реляционной модели, которая сохраняет логическую бизнес-сущность приложения в различные физические таблицы в целях нормализации, NoSQL хранилища оперируют с этими сущностями как с целостными объектами:
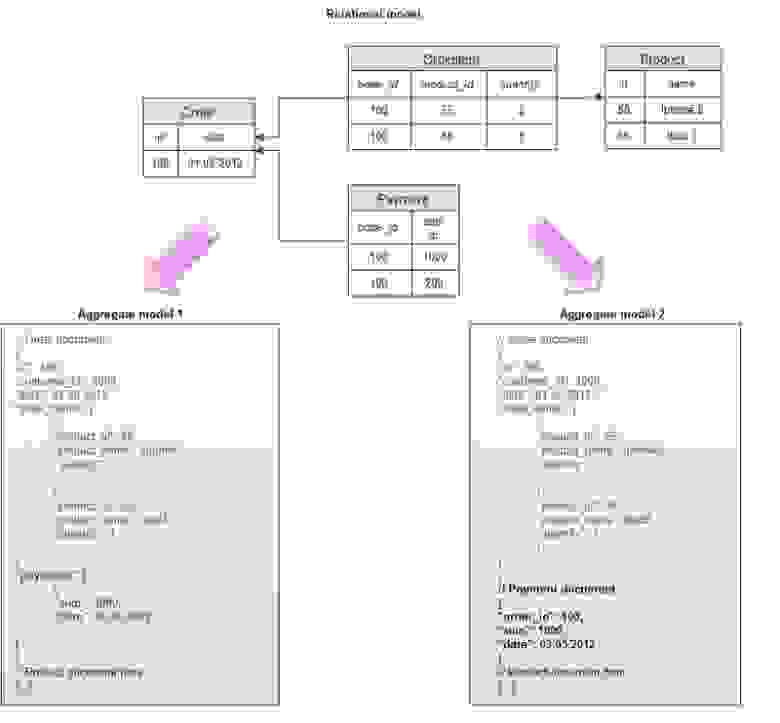
В этом примере продемонстрированы агрегаты для стандартной концептуальной реляционной модели e-commerce “заказ — позиции заказа — платежи — продукт”. В обоих случаях заказ объединяется с позициями в один логический объект, при этом каждая позиция хранит в себе ссылку на продукт и некоторые его атрибуты, например, название (такая денормализация необходима, чтобы не запрашивать объект продукта при извлечении заказа — главное правило распределенных систем — минимум “джоинов” между объектами). В одном агрегате платежи объединены с заказом и являются составной частью объекта, в другом — вынесены в отдельный объект. Этим демонстрируется главное правило проектирования структуры данных в NoSQL базах — она должна подчиняться требованиям приложения и быть максимально оптимизированной под наиболее частые запросы. Если платежи регулярно извлекаются вместе с заказом — имеет смысл их включать в общий объект, если же многие запросы работают только с платежами — значит, лучше их вынести в отдельную сущность.
Многие возразят, заметив, что работа с большими, часто денормализованными, объектами чревата многочисленными проблемами при попытках произвольных запросов к данным, когда запросы не укладываются в структуру агрегатов. Что, если мы используем заказы вместе с позициями и платежами по заказу (так работает приложение), но бизнес просит нас посчитать, сколько единиц определенного продукта было проданно в прошлом месяце? В этом случае вместо сканирования таблицы OrderItem (в случае реляционной модели) нам придется извлекать заказы целиком в NoSQL хранилище, хотя большая часть этой информации нам будет не нужна. К сожалению, это компромисс, на который приходится идти в распределенной системе: мы не можем проводить нормализацию данных как в обычной односерверной системе, так как это создаст необходимость объединения данных с разных узлов и может привести к значительному замедлению работы базы
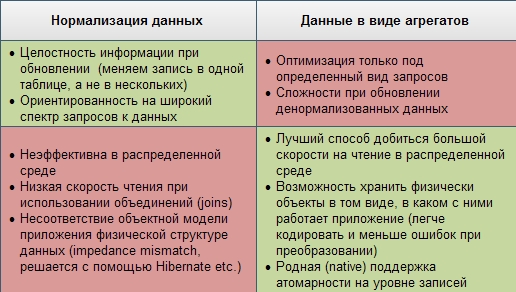
Плюсы и минусы обоих подходов я попытался сгруппировать в табличке:
4. Слабые ACID свойства.
Долгое время консистентность (consistency) данных была “священной коровой” для архитекторов и разработчиков. Все реляционные базы обеспечивали тот или иной уровень изоляции — либо за счет блокировок при изменении и блокирующего чтения, либо за счет undo-логов. С приходом огромных массивов информации и распределенных систем стало ясно, что обеспечить для них транзакционность набора операций с одной стороны и получить высокую доступность и быстрое время отклика с другой — невозможно. Более того, даже обновление одной записи не гарантирует, что любой другой пользователь моментально увидит изменения в системе, ведь изменение может произойти, например, в мастер-ноде, а реплика асинхронно скопируется на слейв-ноду, с которой и работает другой пользователь. В таком случае он увидит результат через какой-то промежуток времени. Это называется eventual consistency и это то, на что идут сейчас все крупнейшие интернет-компании мира, включая Facebook и Amazon. Последние с гордостью заявляют, что максимальный интервал, в течение которого пользователь может видеть неконсистентные данные составляют не более секунды. Пример такой ситуации показан на рисунке:

Логичный вопрос, который появляется в такой ситуации — а что делать системам, которые классически предъявляют высокие требования к атомарности-консистентности операций и в то же время нуждаются в быстрых распределенных кластерах — финансовым, интернет-магазинам и т.д? Практика показывает, что эти требования уже давно неактуальны: вот что сказал один разработчик финансовой банковской системы: “Если бы мы действительно ждали завершения каждой транзакции в мировой сети ATM (банкоматов), транзакции занимали бы столько времени, что клиенты убегали бы прочь в ярости. Что происходит, если ты и твой партнер снимаете деньги одновременно и превышаете лимит? — Вы оба получите деньги, а мы поправим это позже.” Другой пример — бронирование гостиниц, показанный на картинке. Онлайн-магазины, чья политика работы с данными предполагает eventual consistency, обязаны предусмотреть меры на случай таких ситуаций (автоматическое решение конфликтов, откат операции, обновление с другими данными). На практике гостиницы всегда стараются держать “пул” свободных номеров на непредвиденный случай и это может стать решением спорной ситуации.
На самом деле слабые ACID свойства не означают, что их нет вообще. В большинстве случаев приложение, работающее с реляционной базой данных, использует транзакцию для изменения логически связанных объектов (заказ — позиции заказа), что необходимо, так как это разные таблицы. При правильном проектировании модели данных в NoSQL базе (агрегат представляет из себя заказ вместе с перечнем пунктов заказа) можно добиться такого же самого уровня изоляции при изменении одной записи, что и в реляционной базе данных.
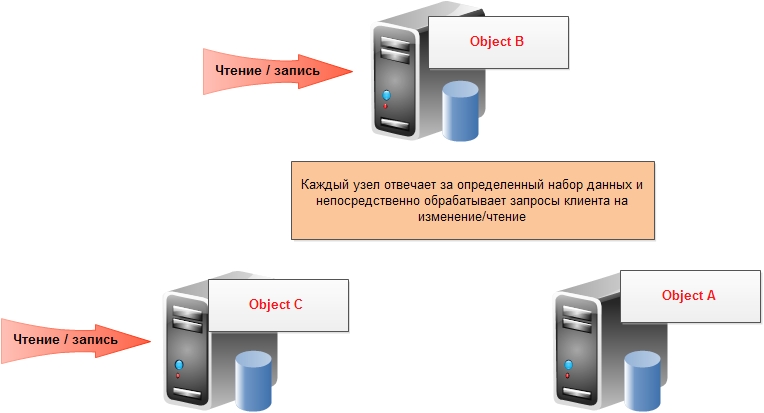
5. Распределенные системы, без совместно используемых ресурсов (share nothing).
Опять же, это не касается граф баз данных, чья структура по определению плохо разносится по удаленным нодам.
Это, возможно, главный лейтмотив развития NoSQL баз. С лавинообразным ростом информации в мире и необходимости ее обрабатывать за разумное время встала проблема вертикальной масштабируемости — рост скорости процессора остановился на 3.5 Ггц, скорость чтения с диска также растет тихими темпами, плюс цена мощного сервера всегда больше суммарной цены нескольких простых серверов. В этой ситуации обычные реляционные базы, даже кластеризованные на массиве дисков, не способны решить проблему скорости, масштабируемости и пропускной способности. Единственный выход из ситуации — горизонтальное масштабирование, когда несколько независимых серверов соединяются быстрой сетью и каждый владеет/обрабатывает только часть данных и/или только часть запросов на чтение-обновление. В такой архитектуре для повышения мощности хранилища (емкости, времени отклика, пропускной способности) необходимо лишь добавить новый сервер в кластер — и все. Процедурами шардинга, репликации, обеспечением отказоустойчивости (результат будет получен даже если одна или несколько серверов перестали отвечать), перераспределения данных в случае добавления ноды занимается сама NoSQL база. Вкратце представлю основные свойства распределенных NoSQL баз:
Репликация — копирование данных на другие узлы при обновлении. Позволяет как добиться большей масштабируемости, так и повысить доступность и сохранность данных. Принято подразделять на два вида:
master-slave:

и peer-to-peer:
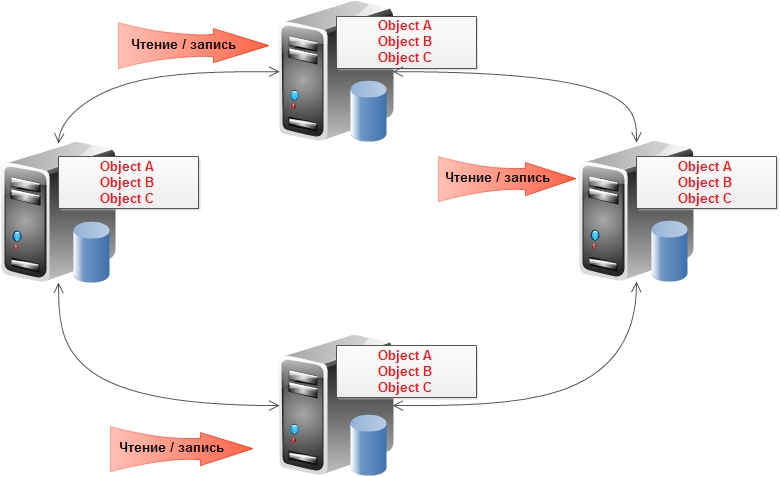
Первый тип предполагает хорошую масштабируемость на чтение (может происходить с любого узла), но немасштабируемую запись (только в мастер узел). Также есть тонкости с обеспечением постоянной доступности (в случае падения мастера либо вручную, либо автоматически на его место назначается один из оставшихся узлов). Для второго типа репликации предполагается, что все узлы равны и могут обслуживать как запросы на чтение, так и на запись.
Шардинг — разделение данных по узлам:
Шардинг часто использовался как “костыль” к реляционным базам данных в целях увеличения скорости и пропускной способности: пользовательское приложение партицировало данные по нескольким независимым базам данных и при запросе соответствующих данных пользователем обращалось к конкретной базе. В NoSQL базах данных шардинг, как и репликация, производятся автоматически самой базой и пользовательское приложение обособленно от этих сложных механизмов.
6. NoSQL базы в-основном оупенсорсные и созданы в 21 столетии.
Именно по второму признаку Садаладж и Фаулер не классифицировали объектные базы данных как NoSQL (хотя http://nosql-database.org/ включает их в общий список), так как они были созданы еще в 90-х и так и не снискали большой популярности.
Дополнительно я хотел остановиться на классификации NoSQL баз данных, но, пожалуй, сделаю это в следующей статье, если это будет интересно хаброюзерам.
NoSQL движение набирает популярность гигантскими темпами. Однако это не означает, что реляционные базы данных становятся рудиментом или чем-то архаичным. Скорее всего они будут использоваться и использоваться по-прежнему активно, но все больше в симбиозе с ними будут выступать NoSQL базы. Мы вступаем в эру polyglot persistence — эру, когда для различных потребностей используются разные хранилища данных. Теперь нет монополизма реляционных баз данных, как безальтернативного источника данных. Все чаще архитекторы выбирают хранилище исходя из природы самих данных и того, как мы ими хотим манипулировать, какие объемы информации ожидаются. И поэтому все становится только интереснее.

История.
Самое интересное в термине, что при том, что впервые он стал использоваться в конце 90-х, реальный смысл в том виде, как он используется сейчас, приобрел только в середине 2009. Изначально так называлась опенсорсная база данных, созданная Карло Строззи, которая хранила все данные как ASCII файлы и использовала шелловские скрипты вместо SQL для доступа к данным. С “NoSQL” в его нынешнем виде она ничего общего не имела.
В июне 2009 в Сан-Франциско Йоханом Оскарссоном была организована встреча, на которой планировалось обсудить новые веяния на ИТ рынке хранения и обработки данных. Главным стимулом для встречи стали новые опенсорсные продукты наподобие BigTable и Dynamo. Для яркой вывески для встречи требовалось найти емкий и лаконичный термин, который отлично укладывался бы в Твиттеровский хэштег. Один из таких терминов предложил Эрик Эванс из RackSpace — «NoSQL». Термин планировался лишь на одну встречу и не имел под собой глубокой смысловой нагрузки, но так получилось, что он распространился по мировой сети наподобие вирусной рекламы и стал де-факто названием целого направления в ИТ-индустрии. На конференции, к слову, выступали Voldemort (клон Amazon Dynamo), Cassandra, Hbase (аналоги Google BigTable), Hypertable, CouchDB, MongoDB.
Стоит еще раз подчеркнуть, что термин “NoSQL” имеет абсолютно стихийное происхождение и не имеет общепризнанного определения или научного учреждения за спиной. Это название скорее характеризует вектор развития ИТ в сторону от реляционных баз данных. Расшифровывается как Not Only SQL, хотя есть сторонники и прямого определения No SQL. Сгруппировать и систематизировать знания о NoSQL мире попытались сделать Прамод Садаладж и Мартин Фаулер в своей недавней книге “NoSQL Distilled”.
Характеристики NoSQL баз данных
Общих характеристик для всех NoSQL немного, так как под лэйблом NoSQL сейчас скрывается множество разнородных систем (самый полный, пожалуй, список можно найти на сайте http://nosql-database.org/). Многие характеристики свойственны только определенным NoSQL базам, это я обязательно упомяну при перечислении.
1. Не используется SQL
Имеется в виду ANSI SQL DML, так как многие базы пытаются использовать query languages похожие на общеизвестный любимый синтаксис, но полностью его реализовать не удалось никому и вряд ли удастся. Хотя по слухам есть стартапы, которые пытаются реализовать SQL, например, в хадупе (http://www.drawntoscalehq.com/ и http://www.hadapt.com/ )
2. Неструктурированные (schemaless)
Смысл таков, что в NoSQL базах в отличие от реляционных структура данных не регламентирована (или слабо типизированна, если проводить аналогии с языками прогаммирования) — в отдельной строке или документе можно добавить произвольное поле без предварительного декларативного изменения структуры всей таблицы. Таким образом, если появляется необходимость поменять модель данных, то единственное достаточное действие — отразить изменение в коде приложения.
Например, при переименовании поля в MongoDB:
BasicDBObject order = new BasicDBObject();
order.put(“date”, orderDate); // это поле было давно
order.put(“totalSum”, total); // раньше мы использовали просто “sum”
Если мы меняем логику приложения, значит мы ожидаем новое поле также и при чтении. Но в силу отсутствия схемы данных поле totalSum отсутствует у других уже существующих объектов Order. В этой ситуации есть два варианта дальнейших действий. Первый — обойти все документы и обновить это поле во всех существующих документах. В силу объемов данных этот процесс происходит без каких-либо блокировок (сравним с командой alter table rename column), поэтому во время обновления уже существующие данные могут считываться другими процессами. Поэтому второй вариант — проверка в коде приложения — неизбежен:
BasicDBObject order = new BasicDBObject();
Double totalSum = order.getDouble(“sum”); // Это старая модель
if (totalSum == null)
totalSum = order.getDouble(“totalSum”); // Это обновленная модель
А уже при повторной записи мы запишем это поле в базу в новом формате.
Приятное следствие отсутствия схемы — эффективность работы с разреженными (sparse) данными. Если в одном документе есть поле date_published, а во втором — нет, значит никакого пустого поля date_published для второго создано не будет. Это, в принципе, логично, но менее очевидный пример — column-family NoSQL базы данных, в которых используются знакомые понятия таблиц/колонок. Однако в силу отсутствия схемы, колонки не объявляются декларативно и могут меняться/добавляться во время пользовательской сессии работы с базой. Это позволяет в частности использовать динамические колонки для реализации списков.
У неструктурированной схемы есть свои недостатки — помимо упомянутых выше накладных расходов в коде приложения при смене модели данных — отсутствие всевозможных ограничений со стороны базы (not null, unique, check constraint и т.д.), плюс возникают дополнительные сложности в понимании и контроле структуры данных при параллельной работе с базой разных проектов (отсутствуют какие-либо словари на стороне базы). Впрочем, в условиях быстро меняющегося современного мира такая гибкость является все-таки преимуществом. В качестве примера можно привести Твиттер, который лет пять назад вместе с твиттом хранил лишь немного дополнительной информации (время, Twitter handle и еще несколько байтов метаинформации), однако сейчас в дополнение к самому сообщению в базе сохраняется еще несколько килобайт метаданных.
(Здесь и далее речь идет в-основном о key-value, document и column-family базах данных, graph базы данных могут не обладать этими свойствами).
3. Представление данных в виде агрегатов (aggregates).
В отличие от реляционной модели, которая сохраняет логическую бизнес-сущность приложения в различные физические таблицы в целях нормализации, NoSQL хранилища оперируют с этими сущностями как с целостными объектами:
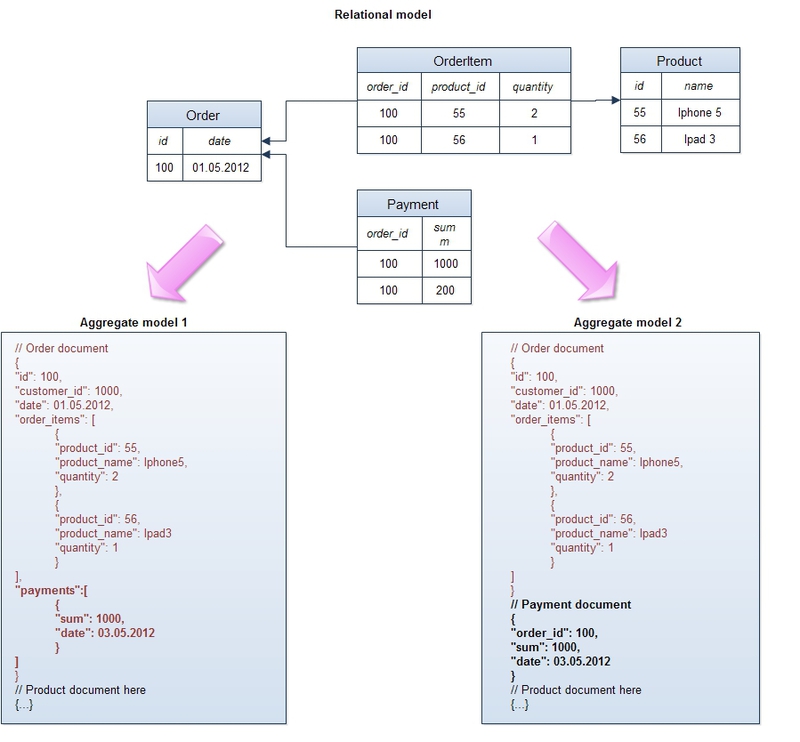
В этом примере продемонстрированы агрегаты для стандартной концептуальной реляционной модели e-commerce “заказ — позиции заказа — платежи — продукт”. В обоих случаях заказ объединяется с позициями в один логический объект, при этом каждая позиция хранит в себе ссылку на продукт и некоторые его атрибуты, например, название (такая денормализация необходима, чтобы не запрашивать объект продукта при извлечении заказа — главное правило распределенных систем — минимум “джоинов” между объектами). В одном агрегате платежи объединены с заказом и являются составной частью объекта, в другом — вынесены в отдельный объект. Этим демонстрируется главное правило проектирования структуры данных в NoSQL базах — она должна подчиняться требованиям приложения и быть максимально оптимизированной под наиболее частые запросы. Если платежи регулярно извлекаются вместе с заказом — имеет смысл их включать в общий объект, если же многие запросы работают только с платежами — значит, лучше их вынести в отдельную сущность.
Многие возразят, заметив, что работа с большими, часто денормализованными, объектами чревата многочисленными проблемами при попытках произвольных запросов к данным, когда запросы не укладываются в структуру агрегатов. Что, если мы используем заказы вместе с позициями и платежами по заказу (так работает приложение), но бизнес просит нас посчитать, сколько единиц определенного продукта было проданно в прошлом месяце? В этом случае вместо сканирования таблицы OrderItem (в случае реляционной модели) нам придется извлекать заказы целиком в NoSQL хранилище, хотя большая часть этой информации нам будет не нужна. К сожалению, это компромисс, на который приходится идти в распределенной системе: мы не можем проводить нормализацию данных как в обычной односерверной системе, так как это создаст необходимость объединения данных с разных узлов и может привести к значительному замедлению работы базы
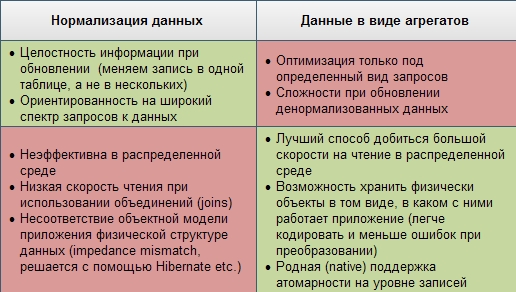
Плюсы и минусы обоих подходов я попытался сгруппировать в табличке:
4. Слабые ACID свойства.
Долгое время консистентность (consistency) данных была “священной коровой” для архитекторов и разработчиков. Все реляционные базы обеспечивали тот или иной уровень изоляции — либо за счет блокировок при изменении и блокирующего чтения, либо за счет undo-логов. С приходом огромных массивов информации и распределенных систем стало ясно, что обеспечить для них транзакционность набора операций с одной стороны и получить высокую доступность и быстрое время отклика с другой — невозможно. Более того, даже обновление одной записи не гарантирует, что любой другой пользователь моментально увидит изменения в системе, ведь изменение может произойти, например, в мастер-ноде, а реплика асинхронно скопируется на слейв-ноду, с которой и работает другой пользователь. В таком случае он увидит результат через какой-то промежуток времени. Это называется eventual consistency и это то, на что идут сейчас все крупнейшие интернет-компании мира, включая Facebook и Amazon. Последние с гордостью заявляют, что максимальный интервал, в течение которого пользователь может видеть неконсистентные данные составляют не более секунды. Пример такой ситуации показан на рисунке:

Логичный вопрос, который появляется в такой ситуации — а что делать системам, которые классически предъявляют высокие требования к атомарности-консистентности операций и в то же время нуждаются в быстрых распределенных кластерах — финансовым, интернет-магазинам и т.д? Практика показывает, что эти требования уже давно неактуальны: вот что сказал один разработчик финансовой банковской системы: “Если бы мы действительно ждали завершения каждой транзакции в мировой сети ATM (банкоматов), транзакции занимали бы столько времени, что клиенты убегали бы прочь в ярости. Что происходит, если ты и твой партнер снимаете деньги одновременно и превышаете лимит? — Вы оба получите деньги, а мы поправим это позже.” Другой пример — бронирование гостиниц, показанный на картинке. Онлайн-магазины, чья политика работы с данными предполагает eventual consistency, обязаны предусмотреть меры на случай таких ситуаций (автоматическое решение конфликтов, откат операции, обновление с другими данными). На практике гостиницы всегда стараются держать “пул” свободных номеров на непредвиденный случай и это может стать решением спорной ситуации.
На самом деле слабые ACID свойства не означают, что их нет вообще. В большинстве случаев приложение, работающее с реляционной базой данных, использует транзакцию для изменения логически связанных объектов (заказ — позиции заказа), что необходимо, так как это разные таблицы. При правильном проектировании модели данных в NoSQL базе (агрегат представляет из себя заказ вместе с перечнем пунктов заказа) можно добиться такого же самого уровня изоляции при изменении одной записи, что и в реляционной базе данных.
5. Распределенные системы, без совместно используемых ресурсов (share nothing).
Опять же, это не касается граф баз данных, чья структура по определению плохо разносится по удаленным нодам.
Это, возможно, главный лейтмотив развития NoSQL баз. С лавинообразным ростом информации в мире и необходимости ее обрабатывать за разумное время встала проблема вертикальной масштабируемости — рост скорости процессора остановился на 3.5 Ггц, скорость чтения с диска также растет тихими темпами, плюс цена мощного сервера всегда больше суммарной цены нескольких простых серверов. В этой ситуации обычные реляционные базы, даже кластеризованные на массиве дисков, не способны решить проблему скорости, масштабируемости и пропускной способности. Единственный выход из ситуации — горизонтальное масштабирование, когда несколько независимых серверов соединяются быстрой сетью и каждый владеет/обрабатывает только часть данных и/или только часть запросов на чтение-обновление. В такой архитектуре для повышения мощности хранилища (емкости, времени отклика, пропускной способности) необходимо лишь добавить новый сервер в кластер — и все. Процедурами шардинга, репликации, обеспечением отказоустойчивости (результат будет получен даже если одна или несколько серверов перестали отвечать), перераспределения данных в случае добавления ноды занимается сама NoSQL база. Вкратце представлю основные свойства распределенных NoSQL баз:
Репликация — копирование данных на другие узлы при обновлении. Позволяет как добиться большей масштабируемости, так и повысить доступность и сохранность данных. Принято подразделять на два вида:
master-slave:
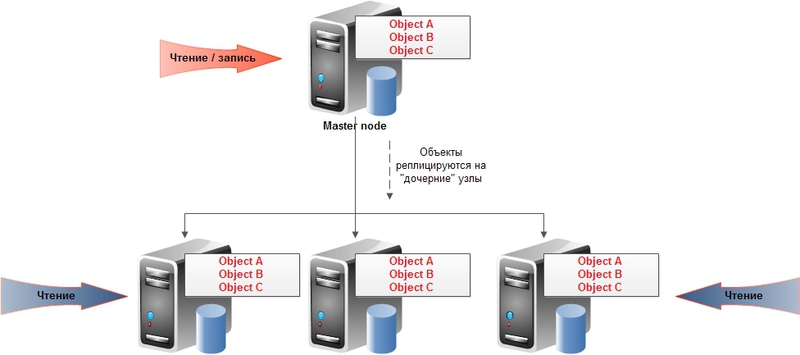
и peer-to-peer:

Первый тип предполагает хорошую масштабируемость на чтение (может происходить с любого узла), но немасштабируемую запись (только в мастер узел). Также есть тонкости с обеспечением постоянной доступности (в случае падения мастера либо вручную, либо автоматически на его место назначается один из оставшихся узлов). Для второго типа репликации предполагается, что все узлы равны и могут обслуживать как запросы на чтение, так и на запись.
Шардинг — разделение данных по узлам:
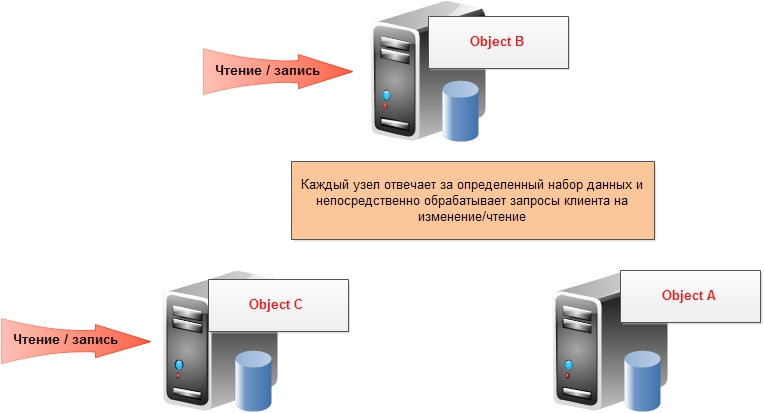
Шардинг часто использовался как “костыль” к реляционным базам данных в целях увеличения скорости и пропускной способности: пользовательское приложение партицировало данные по нескольким независимым базам данных и при запросе соответствующих данных пользователем обращалось к конкретной базе. В NoSQL базах данных шардинг, как и репликация, производятся автоматически самой базой и пользовательское приложение обособленно от этих сложных механизмов.
6. NoSQL базы в-основном оупенсорсные и созданы в 21 столетии.
Именно по второму признаку Садаладж и Фаулер не классифицировали объектные базы данных как NoSQL (хотя http://nosql-database.org/ включает их в общий список), так как они были созданы еще в 90-х и так и не снискали большой популярности.
Дополнительно я хотел остановиться на классификации NoSQL баз данных, но, пожалуй, сделаю это в следующей статье, если это будет интересно хаброюзерам.
Резюме.
NoSQL движение набирает популярность гигантскими темпами. Однако это не означает, что реляционные базы данных становятся рудиментом или чем-то архаичным. Скорее всего они будут использоваться и использоваться по-прежнему активно, но все больше в симбиозе с ними будут выступать NoSQL базы. Мы вступаем в эру polyglot persistence — эру, когда для различных потребностей используются разные хранилища данных. Теперь нет монополизма реляционных баз данных, как безальтернативного источника данных. Все чаще архитекторы выбирают хранилище исходя из природы самих данных и того, как мы ими хотим манипулировать, какие объемы информации ожидаются. И поэтому все становится только интереснее.
