Существует множество компаний, которые продают товары клиентам или оказывают какие-то услуги. Часто продавцы интуитивно принимают решения, какой именно товар из всей существующей линейки лучше подходит клиенту. Также интуитивно определяется, какой массив клиентов более интересен для компании, а для каких клиентов продажа и дальнейшее обслуживание будут слишком затратные и невыгодные.
Для технологичного понимания всех этих вопросов хорошо подходит анализ информации с помощью технологии Data mining. Автоматизируя процесс сегментации клиентов с помощью кластеризации Data mining, компания может найти ответы на множество вопросов.
Рассмотрим вариант, когда компания занимается продажей товаров или услуг и дальнейшим послепродажным обслуживанием. Соответственно у компании есть потенциальные клиенты, которым осуществляются продажи. Также есть клиенты, которые обслуживаются или были ранее на обслуживании, т.е. которым ранее уже продавали. Для простоты будем их называть обслуживаемыми клиентами.
Кратко опишу цель и идею. Для анализа необходимо взять несколько показателей (15-20), которые есть у потенциальных и обслуживаемых клиентов одновременно. Также надо выбрать 2-3 показателя, которые есть только у обслуживаемых клиентов – это целевые показатели. Провести анализ кластеризации Data mining на массиве обслуживаемых клиентов. На выходе получим несколько кластеров со своими характеристиками. Далее кластеры группируем в сегменты по целевым показателям и даем какие-то понятные для маркетологов определения. Полученную модель анализируем, и полученные кластеры проецируем на потенциальных клиентов. На выходе получаем просегментированных потенциальных клиентов. На основании полученных сегментов можно выстроить стратегию и методологию продаж для каждого сегмента клиентов.
Рассмотрим подробнее данную методику и последовательность шагов для достижения результата.
Очевидно, что компания, задумавшаяся об автоматизации подобной аналитики, должна иметь хорошую информационную систему (ИС), в которой будет храниться множество данных по клиентам, например, сколько сотрудников в компании, какой вид деятельности, есть ли бухгалтерия, юристы и т.п. В целом ИС может хранить десятки, сотни таких показателей, но для конкретного анализа может оказаться достаточным 15-20 показателей.
Выберите показатели, которые присутствуют одновременно у обслуживаемых и потенциальных клиентов.
Выбранные показатели должны быть актуальны, т.е. должна быть возможность регулярно обновлять данные по этим показателям. Если вы не можете собрать информацию по какому-то показателю, не используйте его в анализе. Перед началом анализа соберите актуальную информацию, даже если этот этап займет 1-2 месяца, это того стоит.
Определите несколько целевых показателей обслуживаемых клиентов, которые будут однозначно определять, привлекателен для вас клиент или нет, например, период обслуживания клиента, доходность клиента, обслуживаемые продукты и т.п. Очевидно, что эти показатели будут характерны только для обслуживаемых клиентов. Таких показателей может быть немного (2-3), главное чтобы этот показатель характеризовал нужный сегмент в зависимости от ваших целей, например, привлекательный клиент для бизнеса с точки зрения долгосрочной прибыльности.
В ИС значения выбранных показателей могут храниться в виде числовых данных или набора различных полей. Для анализа оптимальнее объединить эти значения в группы, например, количество бухгалтеров: 1, 2-5, 6-9, 10 и более.
Сначала работа ведется только с массивом обслуживаемых клиентов. Оптимальнее выбрать историю взаимоотношений с клиентами за несколько лет, например, за 5 или более лет. Чем больше клиентов будет в выборке, тем более точным будет результат.
Выбранных клиентов с их характеристиками необходимо поместить в базу данных, например в MS SQL Server. В простейшем случае это будет одна таблица фактов, где одна строка это один клиент, а каждое поле таблицы это выбранные на предыдущем этапе показатели.
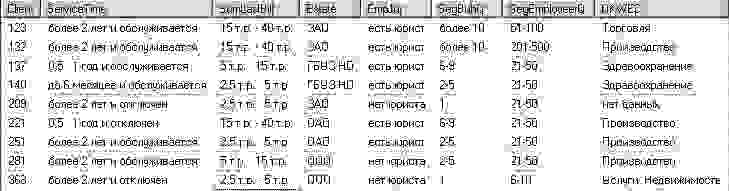
При заливке данных, скорее всего их надо будет подготовить для анализа, преобразовать в соответствии с проведенной ранее группировкой значений показателей.
Причем в таблице вы можете хранить эти значения в виде текста, но более правильно в виде кодов — ссылок на справочник. В таблицу фактов можно заливать данные скриптами на T-sql, с помощью SQL Server Integration Services (SSIS) или другими способами.
Далее необходимо создать модель для анализа Data mining, например, с помощью SQL Server Business Intelligence Development Studio (BIDS). Подробное описание создания моделей в BIDS выходит за рамки данной статьи, отмечу лишь, что мной используется стандартный микрософтовский алгоритм кластеризации.
На выходе получаем определенное количество кластеров, каждый из которых характеризуется выбранными показателями клиентов.
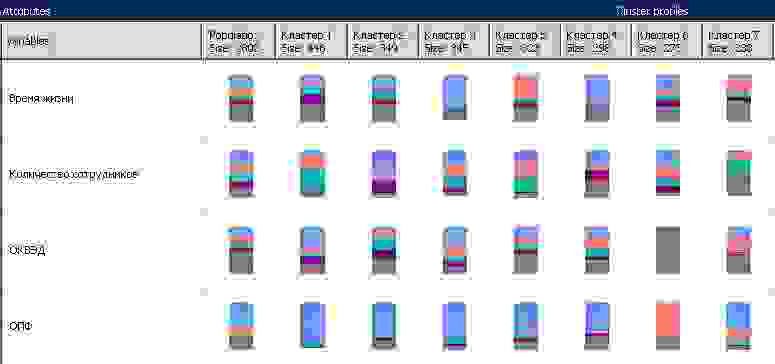
Каждый кластер необходимо описать характерными значениями по всем используемым в анализе показателям, характерным для потенциальных и обслуживаемых клиентов. Например, для кластера 1 характерно количество бухгалтеров 2-5, бюджетный тип налогообложения и вид деятельности здравоохранение. Важно, чтобы в описании кластера присутствовали значения по всем показателям. Возможно, что один показатель будет содержать несколько значений, например, в одном кластере с близкой вероятностью будут находиться клиенты с видом деятельности здравоохранение и образование. Это нормально, берите оба значения.

Далее анализируем полученные кластеры в разрезе тех самых 2-3 целевых показателей обслуживаемых клиентов, которые были выбраны ранее. Фактически можно составить таблицу, в которой каждый кластер будет описан понятным для продавцов языком. Например, кластер 1 — с клиентами, живущими средний срок жизни и приносящими ежемесячный доход выше среднего, кластер 2 – с клиентами, живущими больше среднего, и приносящими доход ниже среднего уровня. Все эти описания и формулировки лежат в компетентной области маркетингового аналитика. Какие-то кластеры можно сгруппировать, если они по целевым показателям относятся к одной группе. Полученные группы кластеров будем называть сегментами.
Необходимо выбрать массив всех потенциальных клиентов, которых мы хотим сегментировать. В общем случае это все клиенты, которые могут поступить в работу сотрудникам для продажи.
Далее с помощью специально написанного программного кода для каждого кластера последовательно отбираем потенциальных клиентов на основании тех значений анализируемых показателей, которые у них хранятся в ИС. Например, для кластера 1 характерно: количество бухгалтеров 2-5, бюджетный тип налогообложения и вид деятельности здравоохранение. Находим всех клиентов, у которых в соответствующих полях ИС такие значения и помещаем их в кластер 1.
На практике возникнут три ситуации:
Рассмотрим эти ситуации:
Логика всех сравнений понятна из вкладки Cluster Discrimination в модели SQL Server Business Intelligence Development Studio.
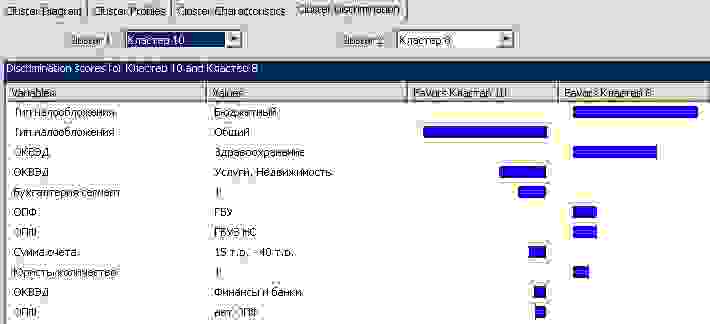
На выходе все потенциальные клиенты распределены по различным сегментам. Значения этих сегментов записываются в ИС. Для каждого сегмента отдел маркетинга прописывает стратегию и методологию продаж.
Важно, чтобы информация по кластерам обновлялась регулярно. Ежедневно меняется информация в ИС по потенциальным клиентам, появляются новые клиенты и им надо проставлять соответствующий сегмент. Вся вышеописанная логика размещается в виде набора программного кода. Следовательно, есть возможность оперативно автоматически рассчитать сегмент для новых клиентов. Кому то необходимо это делать «на лету», при введении клиента в ИС, кому-то достаточно делать раз в сутки, все зависит от потребностей конкретного бизнеса.
В дальнейшем полученный алгоритм можно сделать самообучающимся, интегрировав технологию Data mining непосредственно в ИС. В этом случае модель кластеризации будет постоянно самообучаться на основании новой информации из ИС, полученной по меняющимся данным обслуживаемых и отключаемых клиентов, и корректировать распределение потенциальных клиентов по кластерам.
Для технологичного понимания всех этих вопросов хорошо подходит анализ информации с помощью технологии Data mining. Автоматизируя процесс сегментации клиентов с помощью кластеризации Data mining, компания может найти ответы на множество вопросов.
Рассмотрим вариант, когда компания занимается продажей товаров или услуг и дальнейшим послепродажным обслуживанием. Соответственно у компании есть потенциальные клиенты, которым осуществляются продажи. Также есть клиенты, которые обслуживаются или были ранее на обслуживании, т.е. которым ранее уже продавали. Для простоты будем их называть обслуживаемыми клиентами.
Кратко опишу цель и идею. Для анализа необходимо взять несколько показателей (15-20), которые есть у потенциальных и обслуживаемых клиентов одновременно. Также надо выбрать 2-3 показателя, которые есть только у обслуживаемых клиентов – это целевые показатели. Провести анализ кластеризации Data mining на массиве обслуживаемых клиентов. На выходе получим несколько кластеров со своими характеристиками. Далее кластеры группируем в сегменты по целевым показателям и даем какие-то понятные для маркетологов определения. Полученную модель анализируем, и полученные кластеры проецируем на потенциальных клиентов. На выходе получаем просегментированных потенциальных клиентов. На основании полученных сегментов можно выстроить стратегию и методологию продаж для каждого сегмента клиентов.
Рассмотрим подробнее данную методику и последовательность шагов для достижения результата.
Выберите показатели клиентов для анализа
Очевидно, что компания, задумавшаяся об автоматизации подобной аналитики, должна иметь хорошую информационную систему (ИС), в которой будет храниться множество данных по клиентам, например, сколько сотрудников в компании, какой вид деятельности, есть ли бухгалтерия, юристы и т.п. В целом ИС может хранить десятки, сотни таких показателей, но для конкретного анализа может оказаться достаточным 15-20 показателей.
Выберите показатели, которые присутствуют одновременно у обслуживаемых и потенциальных клиентов.
Выбранные показатели должны быть актуальны, т.е. должна быть возможность регулярно обновлять данные по этим показателям. Если вы не можете собрать информацию по какому-то показателю, не используйте его в анализе. Перед началом анализа соберите актуальную информацию, даже если этот этап займет 1-2 месяца, это того стоит.
Выберите целевые показатели обслуживаемых клиентов
Определите несколько целевых показателей обслуживаемых клиентов, которые будут однозначно определять, привлекателен для вас клиент или нет, например, период обслуживания клиента, доходность клиента, обслуживаемые продукты и т.п. Очевидно, что эти показатели будут характерны только для обслуживаемых клиентов. Таких показателей может быть немного (2-3), главное чтобы этот показатель характеризовал нужный сегмент в зависимости от ваших целей, например, привлекательный клиент для бизнеса с точки зрения долгосрочной прибыльности.
Произведите группировку значений показателей
В ИС значения выбранных показателей могут храниться в виде числовых данных или набора различных полей. Для анализа оптимальнее объединить эти значения в группы, например, количество бухгалтеров: 1, 2-5, 6-9, 10 и более.
Выберите клиентов для создания модели
Сначала работа ведется только с массивом обслуживаемых клиентов. Оптимальнее выбрать историю взаимоотношений с клиентами за несколько лет, например, за 5 или более лет. Чем больше клиентов будет в выборке, тем более точным будет результат.
Выбранных клиентов с их характеристиками необходимо поместить в базу данных, например в MS SQL Server. В простейшем случае это будет одна таблица фактов, где одна строка это один клиент, а каждое поле таблицы это выбранные на предыдущем этапе показатели.
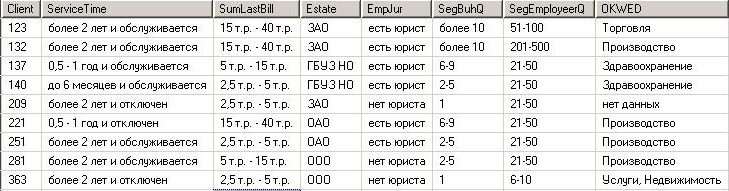
При заливке данных, скорее всего их надо будет подготовить для анализа, преобразовать в соответствии с проведенной ранее группировкой значений показателей.
Причем в таблице вы можете хранить эти значения в виде текста, но более правильно в виде кодов — ссылок на справочник. В таблицу фактов можно заливать данные скриптами на T-sql, с помощью SQL Server Integration Services (SSIS) или другими способами.
Создайте модель для анализа
Далее необходимо создать модель для анализа Data mining, например, с помощью SQL Server Business Intelligence Development Studio (BIDS). Подробное описание создания моделей в BIDS выходит за рамки данной статьи, отмечу лишь, что мной используется стандартный микрософтовский алгоритм кластеризации.
На выходе получаем определенное количество кластеров, каждый из которых характеризуется выбранными показателями клиентов.

Выделите характерные значения для полученных кластеров
Каждый кластер необходимо описать характерными значениями по всем используемым в анализе показателям, характерным для потенциальных и обслуживаемых клиентов. Например, для кластера 1 характерно количество бухгалтеров 2-5, бюджетный тип налогообложения и вид деятельности здравоохранение. Важно, чтобы в описании кластера присутствовали значения по всем показателям. Возможно, что один показатель будет содержать несколько значений, например, в одном кластере с близкой вероятностью будут находиться клиенты с видом деятельности здравоохранение и образование. Это нормально, берите оба значения.

Объедините кластеры в сегменты
Далее анализируем полученные кластеры в разрезе тех самых 2-3 целевых показателей обслуживаемых клиентов, которые были выбраны ранее. Фактически можно составить таблицу, в которой каждый кластер будет описан понятным для продавцов языком. Например, кластер 1 — с клиентами, живущими средний срок жизни и приносящими ежемесячный доход выше среднего, кластер 2 – с клиентами, живущими больше среднего, и приносящими доход ниже среднего уровня. Все эти описания и формулировки лежат в компетентной области маркетингового аналитика. Какие-то кластеры можно сгруппировать, если они по целевым показателям относятся к одной группе. Полученные группы кластеров будем называть сегментами.
Выберите потенциальных клиентов
Необходимо выбрать массив всех потенциальных клиентов, которых мы хотим сегментировать. В общем случае это все клиенты, которые могут поступить в работу сотрудникам для продажи.
Распределите потенциальных клиентов по кластерам
Далее с помощью специально написанного программного кода для каждого кластера последовательно отбираем потенциальных клиентов на основании тех значений анализируемых показателей, которые у них хранятся в ИС. Например, для кластера 1 характерно: количество бухгалтеров 2-5, бюджетный тип налогообложения и вид деятельности здравоохранение. Находим всех клиентов, у которых в соответствующих полях ИС такие значения и помещаем их в кластер 1.
На практике возникнут три ситуации:
- клиент однозначно соответствует только одному кластеру;
- клиент соответствует двум и более кластерам;
- клиент не попадает ни в один кластер.
Рассмотрим эти ситуации:
- Когда один клиент попадает только в один кластер, проставляем ему нужное значение кластера и забываем о нем.
- Когда клиент соответствует двум и более кластерам, то надо анализировать какому кластеру клиент соответствует в большей степени. Мы знаем, какие значения показателей, в той или иной степени характеризуют сравниваемые кластеры. И знаем значения показателей для конкретного клиента. Отсюда однозначно можно определить к какому кластеру клиент ближе, туда мы его и размещаем. Очевидно, что делать это надо не вручную для всех клиентов, а программно анализируя варианты возможных пересечений между кластерами.
- Когда клиент не попадает в явном виде ни в один кластер, необходимо расширить варианты значений показателей, характеризующих кластер. Далее по расширенным характеристикам можно определить к какому кластеру клиент относится. Например, кластер 1 по показателю «Количество бухгалтеров» характеризуется в большей степени значением «2-5», но также этому кластеру в меньшей степени характерно значение «6-9». Это значение и добавляем в расширенный анализ.
Логика всех сравнений понятна из вкладки Cluster Discrimination в модели SQL Server Business Intelligence Development Studio.

Результаты
На выходе все потенциальные клиенты распределены по различным сегментам. Значения этих сегментов записываются в ИС. Для каждого сегмента отдел маркетинга прописывает стратегию и методологию продаж.
Важно, чтобы информация по кластерам обновлялась регулярно. Ежедневно меняется информация в ИС по потенциальным клиентам, появляются новые клиенты и им надо проставлять соответствующий сегмент. Вся вышеописанная логика размещается в виде набора программного кода. Следовательно, есть возможность оперативно автоматически рассчитать сегмент для новых клиентов. Кому то необходимо это делать «на лету», при введении клиента в ИС, кому-то достаточно делать раз в сутки, все зависит от потребностей конкретного бизнеса.
В дальнейшем полученный алгоритм можно сделать самообучающимся, интегрировав технологию Data mining непосредственно в ИС. В этом случае модель кластеризации будет постоянно самообучаться на основании новой информации из ИС, полученной по меняющимся данным обслуживаемых и отключаемых клиентов, и корректировать распределение потенциальных клиентов по кластерам.
