Корни истории уходят в те годы, когда один из кланов древней текстовой игры «Бойцовский клуб» заказал у меня, молодого программиста на Perl, капчу для игры. Пара бессонных ночей — и четыре ровных цифры готовы вместе с проверкой ввода.

Через несколько дней пришёл другой, не менее уважаемый клан, и заказал парсер той самой капчи. Для её разбора пришлось потратить гораздо больше времени, никакого Ocrad тогда ещё не было, но был найден очень простой и рабочий способ.
Через неделю пришёл третий, и самый заслуженный в игре клан, и заказал новую капчу. Через пару месяцев перетягивания одеяла почти все топовые кланы обогатились на новые картинки-артефакты, их программисты на ворох разноцветных бумажек, проект — на кучу генераторов чепухи, а лично я на бесценный опыт.
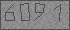


Совсем недавно этот опыт пригодился для разбора тысяч телефонных номеров с одного из сайтов из изображения обратно в текст. Алгоритм использовался тот же самый, и я хочу им поделиться. Вот отвёртка и молоток, а что вы ими соберёте — синхрофазотрон или гравипушку — уже ваше личное дело.
Писал я это всё сначала на Perl, а потом на PHP, но не стоит никого утомлять листингами, правда?
Шаг 1. Изображение в матрицу.
Разбираем изображение в двумерную матрицу вида axy, или a[x][y], если так больше нравится.
Каждому элементу матрицы присваиваем значение — цвет пикселя.
Считаем количество пикселей разного цвета, информацию об этом заносим в обычный массив.
Шаг 2. Избавляемся от лишнего.
Изображение, хоть взято и из GIF, хранящего не более 256 цветов, всё равно требует уменьшения количества информации. Сокращаем количество цветов: отбрасываем все значения, которых меньше, чем хотя бы 50% от цвета, набравшего наибольшее количество упоминаний в нашем массиве. От вроде бы монохромного изображения обычно остаётся четыре цвета. Это — список основных цветов.
Шаг 3. Дальше — самое забавное: делаем тотальный Sharpen и Grayscale. Следите за руками:
Создаём новую двумерную матрицу b[x][y]. В неё будем писать результаты.
Берём четыре соседних пикселя — квадрат.
Если хотя бы один из цветов этих пикселей остался в списке основных цветов — пишем в новую матрицу b[0][0]=Х. Если ни одного нет — пишем b[0][0]=0.
Берём следующие 4 пикселя. Повторять до конца матрицы, а в случае больших изображений операцию даже можно прогнать дважды. Только не увлекайтесь — чем сложнее изображение, тем сложнее будет сравнивать дальше.
В результате получается вот такая красота:

Что-то в этом есть из детства, когда в школе учили писать почтовые индексы, правда?
Осталось самое простое: объяснить компьютеру, что графическое изображение, состоящее из крестиков и ноликов, вполне может являться десятичной цифрой. Для этого разделяем матрицу на кусочки-подматрицы по символам, и сравниваем их с эталоном. К сожалению, эталон для каждой капчи свой, и каждый раз приходится его подгонять, пусть и незначительно.
В самом конце нас спасает алгоритм Оливье для сравнения похожих строк, который используется в готовой функции PHP int similar_text(str, str). Конечно, чем меньше длина строк, тем быстрей они проверяются, так что я сравнивал первую строку в «распознанном» символе с первой строкой эталона, вторую со второй, и так до конца.
Сорок тысяч телефонных номеров распознались с погрешностью в 1 штуку. Теперь бы сделать алгоритм более универсальным — и миллион у нас в кармане, правда?

Через несколько дней пришёл другой, не менее уважаемый клан, и заказал парсер той самой капчи. Для её разбора пришлось потратить гораздо больше времени, никакого Ocrad тогда ещё не было, но был найден очень простой и рабочий способ.
Через неделю пришёл третий, и самый заслуженный в игре клан, и заказал новую капчу. Через пару месяцев перетягивания одеяла почти все топовые кланы обогатились на новые картинки-артефакты, их программисты на ворох разноцветных бумажек, проект — на кучу генераторов чепухи, а лично я на бесценный опыт.
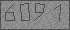


Совсем недавно этот опыт пригодился для разбора тысяч телефонных номеров с одного из сайтов из изображения обратно в текст. Алгоритм использовался тот же самый, и я хочу им поделиться. Вот отвёртка и молоток, а что вы ими соберёте — синхрофазотрон или гравипушку — уже ваше личное дело.
Писал я это всё сначала на Perl, а потом на PHP, но не стоит никого утомлять листингами, правда?
Шаг 1. Изображение в матрицу.
Разбираем изображение в двумерную матрицу вида axy, или a[x][y], если так больше нравится.
Каждому элементу матрицы присваиваем значение — цвет пикселя.
Считаем количество пикселей разного цвета, информацию об этом заносим в обычный массив.
Шаг 2. Избавляемся от лишнего.
Изображение, хоть взято и из GIF, хранящего не более 256 цветов, всё равно требует уменьшения количества информации. Сокращаем количество цветов: отбрасываем все значения, которых меньше, чем хотя бы 50% от цвета, набравшего наибольшее количество упоминаний в нашем массиве. От вроде бы монохромного изображения обычно остаётся четыре цвета. Это — список основных цветов.
Шаг 3. Дальше — самое забавное: делаем тотальный Sharpen и Grayscale. Следите за руками:
Создаём новую двумерную матрицу b[x][y]. В неё будем писать результаты.
Берём четыре соседних пикселя — квадрат.
Если хотя бы один из цветов этих пикселей остался в списке основных цветов — пишем в новую матрицу b[0][0]=Х. Если ни одного нет — пишем b[0][0]=0.
Берём следующие 4 пикселя. Повторять до конца матрицы, а в случае больших изображений операцию даже можно прогнать дважды. Только не увлекайтесь — чем сложнее изображение, тем сложнее будет сравнивать дальше.
В результате получается вот такая красота:
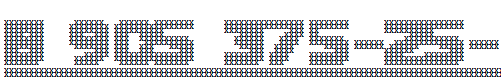
Что-то в этом есть из детства, когда в школе учили писать почтовые индексы, правда?
Осталось самое простое: объяснить компьютеру, что графическое изображение, состоящее из крестиков и ноликов, вполне может являться десятичной цифрой. Для этого разделяем матрицу на кусочки-подматрицы по символам, и сравниваем их с эталоном. К сожалению, эталон для каждой капчи свой, и каждый раз приходится его подгонять, пусть и незначительно.
В самом конце нас спасает алгоритм Оливье для сравнения похожих строк, который используется в готовой функции PHP int similar_text(str, str). Конечно, чем меньше длина строк, тем быстрей они проверяются, так что я сравнивал первую строку в «распознанном» символе с первой строкой эталона, вторую со второй, и так до конца.
Сорок тысяч телефонных номеров распознались с погрешностью в 1 штуку. Теперь бы сделать алгоритм более универсальным — и миллион у нас в кармане, правда?
