Сегодня в 09:47 UTC CloudFlare фактически выпал из Интернета. Падение задело все сервисы CloudFlare, в том числе DNS и сервисы проксирования. Все, кто пытался открыть любой использующий сервисы CloudFlare сайт во время падения, получали ошибку DNS. Ping и traceroute до хостов CloudFlare также выдавали ошибку «No Route to Host».
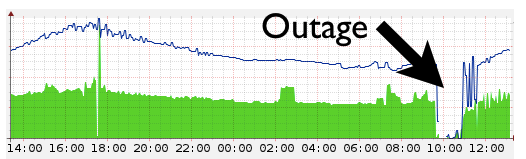
Причиной падения стала ошибка на пограничных маршрутизаторах. У CloudFlare сейчас 23 дата-центра по всему миру. Они соединины с интернетом через маршрутизаторы. Эти маршрутизаторы делали так, чтобы пакеты, отправленные нам из любой точки интернета, обычно доходили до наших серверов. Когда маршрутизатор перестаёт работать, сеть, находящаяся за ним, перестаёт быть доступной для Интернета.
Мы регулярно выключаем один или несколько наших замечательных роутеров, например, во время каких-либо работ. Из-за того, что мы используем Anycast, траффик перенаправляется на ближайший дата-центр. Однако, этим утром мы столкнулись с ошибкой, которая уложила все наши роутеры.
Все пограничные маршрутизаторы, которые были подвержены ошибке, были от Juniper. Одна из причин, по которым нам нравится роутеры Juniper — поддержка протокола Flowspec. Он позволяет вам эффективно распространять правила маршрутизации на большое количество роутеров. Здесь, в CloudFlare, мы постоянно обновляем правила маршрутизации. Это необходимо для защиты от атак и перенаправления траффика для максимально быстрого обслуживания.
Этим утром мы заметили DDoS атаку, направленную на одного из наших клиентов. Атака была направлена исключительно на DNS сервера. У нас есть специальный инструмент для создания сигнатур атак, одинаково хорошо понятных и для автоматизированных систем, и для сотрудников. Обычно, эти сигнатуры используются для создания правил маршрутизации, которые позволят уменьшить количество «плохих» запросов.
В рассматриваемом случае наш профилировщик атак определил, что «плохие» пакеты были длиной от 99,971 до 99,985 байтов. Это довольно странно, потому что длина обычного пакета не превышает 600 байт, а самые крупные бывают до 1,500 байт. В нашей сети установлено ограничение на 4,470 байт, но профилировщик говорил, что пакеты атакующего имеют именно эту длину.
Кто-нибудь из нашей команды всегда следит за сетью, 24/7. Как обычно, один из операторов взял вывод профилировщика и добавил правило, по которому все пакеты размером от 99,971 до 99,985 байт должны «дропаться». Так оно выглядело в Junos, операционной системе Juniper:

Flowspec принял это правило и распределил его по всей пограничной сети. По идее ни один пакет не должен был подойти под это правило, потому что в сети не могло быть таких больших пакетов. На самом же деле все маршрутизаторы приняли правило и начали потреблять всю доступную RAM, пока не зависли.
В обычном случае роутер должен был автоматически перезагрузиться, но тогда это почему-то не произошло. Мы также не смогли получить доступ через порты управления. Даже если какой-то дата-центр вдруг сам поднимался, он тут же ложился обратно, потому что весь траффик всей сети начинал идти через него.
Sam Bowne, профессор City College Сан-Франциско, используя BGPlay получил вот это видео, на котором видно, как один за одним падают роутеры:
Сетевая команда CloudFlare была в курсе инцидента с самого начала. Была неясна причина падения маршрутизаторов, но было очевидно, что пакеты не могут найти путь до нашей сети. Мы смогли получить доступ к нескольким роутерам и выяснили, что падали они из-за того правила. Мы удалили его и затем позвонили операторам в других дата-центрах, чтобы они перезагрузили роутеры.
23 дата-центра CloudFlare находятся в 14 странах, так что время реагирования было где-то около 30 минут. В 10:49 UTC все сервисы CloudFlare уже работали. Мы продолжаем расследовать случаи, на которые до сих пор жалуются наши клиенты. Обычно они связаны с тем, что закешировался плохой DNS ответ.
Мы уже связались со специалистами Juniper чтобы узнать, известен ли им этот баг или наш случай первый. Нам предстоит провести несколько тестов Flowspec и выяснить, можно ли ограничить применение правил несколькими дата-центрами. Также мы планируем вернуть деньги аккаунтам, защищённым SLA. Мы категорически против сколь угодно малого времени недоступности сервисов и команда CloudFlare приносит свои извинения за этот случай.
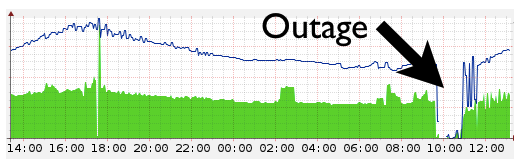
Причиной падения стала ошибка на пограничных маршрутизаторах. У CloudFlare сейчас 23 дата-центра по всему миру. Они соединины с интернетом через маршрутизаторы. Эти маршрутизаторы делали так, чтобы пакеты, отправленные нам из любой точки интернета, обычно доходили до наших серверов. Когда маршрутизатор перестаёт работать, сеть, находящаяся за ним, перестаёт быть доступной для Интернета.
Мы регулярно выключаем один или несколько наших замечательных роутеров, например, во время каких-либо работ. Из-за того, что мы используем Anycast, траффик перенаправляется на ближайший дата-центр. Однако, этим утром мы столкнулись с ошибкой, которая уложила все наши роутеры.
Flowspec
Все пограничные маршрутизаторы, которые были подвержены ошибке, были от Juniper. Одна из причин, по которым нам нравится роутеры Juniper — поддержка протокола Flowspec. Он позволяет вам эффективно распространять правила маршрутизации на большое количество роутеров. Здесь, в CloudFlare, мы постоянно обновляем правила маршрутизации. Это необходимо для защиты от атак и перенаправления траффика для максимально быстрого обслуживания.
Этим утром мы заметили DDoS атаку, направленную на одного из наших клиентов. Атака была направлена исключительно на DNS сервера. У нас есть специальный инструмент для создания сигнатур атак, одинаково хорошо понятных и для автоматизированных систем, и для сотрудников. Обычно, эти сигнатуры используются для создания правил маршрутизации, которые позволят уменьшить количество «плохих» запросов.
В рассматриваемом случае наш профилировщик атак определил, что «плохие» пакеты были длиной от 99,971 до 99,985 байтов. Это довольно странно, потому что длина обычного пакета не превышает 600 байт, а самые крупные бывают до 1,500 байт. В нашей сети установлено ограничение на 4,470 байт, но профилировщик говорил, что пакеты атакующего имеют именно эту длину.
Роковое правило
Кто-нибудь из нашей команды всегда следит за сетью, 24/7. Как обычно, один из операторов взял вывод профилировщика и добавил правило, по которому все пакеты размером от 99,971 до 99,985 байт должны «дропаться». Так оно выглядело в Junos, операционной системе Juniper:

Flowspec принял это правило и распределил его по всей пограничной сети. По идее ни один пакет не должен был подойти под это правило, потому что в сети не могло быть таких больших пакетов. На самом же деле все маршрутизаторы приняли правило и начали потреблять всю доступную RAM, пока не зависли.
В обычном случае роутер должен был автоматически перезагрузиться, но тогда это почему-то не произошло. Мы также не смогли получить доступ через порты управления. Даже если какой-то дата-центр вдруг сам поднимался, он тут же ложился обратно, потому что весь траффик всей сети начинал идти через него.
Sam Bowne, профессор City College Сан-Франциско, используя BGPlay получил вот это видео, на котором видно, как один за одним падают роутеры:
Реакция на инцидент
Сетевая команда CloudFlare была в курсе инцидента с самого начала. Была неясна причина падения маршрутизаторов, но было очевидно, что пакеты не могут найти путь до нашей сети. Мы смогли получить доступ к нескольким роутерам и выяснили, что падали они из-за того правила. Мы удалили его и затем позвонили операторам в других дата-центрах, чтобы они перезагрузили роутеры.
23 дата-центра CloudFlare находятся в 14 странах, так что время реагирования было где-то около 30 минут. В 10:49 UTC все сервисы CloudFlare уже работали. Мы продолжаем расследовать случаи, на которые до сих пор жалуются наши клиенты. Обычно они связаны с тем, что закешировался плохой DNS ответ.
Мы уже связались со специалистами Juniper чтобы узнать, известен ли им этот баг или наш случай первый. Нам предстоит провести несколько тестов Flowspec и выяснить, можно ли ограничить применение правил несколькими дата-центрами. Также мы планируем вернуть деньги аккаунтам, защищённым SLA. Мы категорически против сколь угодно малого времени недоступности сервисов и команда CloudFlare приносит свои извинения за этот случай.
