
Пару недель назад, я наткнулся на эту статью How Shazam Works
Мне стало интересно, как же работают такие программы как Shazam… Что еще более важно, насколько тяжело написать что-либо похожее в Java?
О Shazam
Если кто-то не знает, Shazam это приложение с помощью которого вы можете анализировать/подбирать музыку. Установив ее на свой телефон, и поднеся микрофон к какому-либо источнику музыки на 20-30 секунд, приложение определит, что это за песня.
При первом использовании у меня возникло волшебное чувство. «Как оно это сделало!?» И даже сегодня, когда я уже пользовался им много раз, это чувство меня не покидает.
Разве не будет классно, если бы мы смогли написать что-то сами, что вызывало бы такие же чувства? Это и было моей целью в прошлый уикенд.
Слушайте внимательно..!
Прежде всего, перед тем как взять образец музыки для анализа, нам необходимо прослушать микрофон через наше приложение Java…! Это то, что мне на тот момент еще не приходилось реализовывать в Java, поэтому я себе даже не представлял, как сложно это будет.
Но оказалось, что это довольно просто:

Теперь мы можем считывать данные с TargetDataLine как с обычных потоков InputStream:

Этот метод позволяет легко открывать микрофон и записывать все звуки! В данном случае я использую следующий AudioFormat:

И так, теперь у нас есть записанные данные в классе ByteArrayOutputStream, отлично! Первый этап пройден.
Данные с микрофона
Следующее испытание – анализ данных, на выходе, полученные данные были в виде байтового массива, это был длинный список чисел, наподобие этого:

Хммм… да. И это звук?
Чтобы узнать, могут ли данные быть визуализированы, я закинул их в Open Office и преобразовал в линейный график:

Да! Теперь это похоже на «звук». Выглядит так, как если бы вы, например, пользовались Windows Sound Recorder.
Данные такого типа известны как time domain (временная область). Но на данном этапе эти числа для нас бесполезны… если вы прочтете вышеупомянутую статью о том как работает Shazam, то вы узнаете, что они используют spectrum analysis (спектральный анализ) вместо непрерывных данных временной области.
Поэтому следующий важный вопрос – это: «Как нам преобразовать наши данные в формате спектрального анализа?»
Дискретное преобразование Фурье
Чтобы превратить наши данные во что-то пригодное, мы должны применить так называемое Discrete Fourier Transformation (Дискретное Преобразование Фурье). Что позволит нам преобразовать наши данные из временной области в частотные интервалы.
Но это только одна проблема, если вы преобразуете данные в частотные интервалы, то каждый бит информации касательно временных данных будет потерян. И так, вам будет известна магнитуда каждого колебания, но вы не будете иметь ни малейшего понятия, когда она должна произойти.
Чтобы решить эту проблему, воспользуемся протоколами sliding window. Берем часть данных (в моем случае 4096 байтов данных) и преобразуем только этот бит информации. Затем нам будет известна магнитуда всех колебаний возникающих в течении этих 4096 байтов.
Применение
Вместо того, чтобы думать о Преобразовании Фурье, я немного прогуглил и нашел код для так называемого БПФ (Быстрое Преобразование Фурье). Я называю этот код – код с пачками данных:

Теперь у нас есть два ряда с пачками всех данных – Complex[]. Эти ряды содержат данные обо всех частотах. Чтобы визуализировать эти данные я решил воспользоваться анализатором всего спектра (просто убедиться в том, что мои расчеты верны).
Чтобы показать вам данные, я скомпоновал их вместе:

Ввод, Aphex Twin
Это немного не по теме, но я бы хотел рассказать вам о электро-музыканте Aphex Twin (Ричард Дэвид Джеймс). Он писал сумасшедшую электронную музыку… но некоторые его песни обладают интересной характеристикой. К примеру, его величайший хит — Windowlicker, в нем заложено изображение – спектрограмма.
Если вы посмотрите на песню как на спектральное изображение, то увидите красивую спираль. Другая песня — Mathematical Equation, показывает лицо Twin’а! Узнать больше вы сможете здесь — Bastwood – Aphex Twin’s face.
Прогнав эту песню через мой спектральный анализатор я получил следующие результаты:
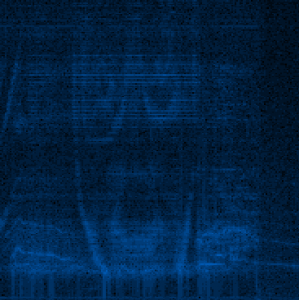
Конечно же не идеально, но это должно быть лицо Twin’а!
Определение ключевых музыкальных точек
Следующий шаг в алгоритме приложения Shazam – определить некоторые ключевые точки в песне, сохранить их в виде знаков и затем попытаться подобрать нужную песню из своей более чем 8 миллионной базы песен. Это происходит очень быстро, поиск знака происходит со скоростью — O(1). Теперь становится ясно, почему Shazam работает так великолепно!
Так как я хотел, чтобы у меня все заработало по истечению одного уикенда (к сожалению это максимальный промежуток времени моей концентрации на одном деле, затем мне нужно найти новый проект) я постарался упростить мой алгоритм насколько это возможно. И к моему удивлению это сработало.
Для каждой линии в спектральном анализе, в определенном диапазоне я выделил точки с наивысшей магнитудой. В моем случае: 40-80, 80-120, 120-180, 180-300.
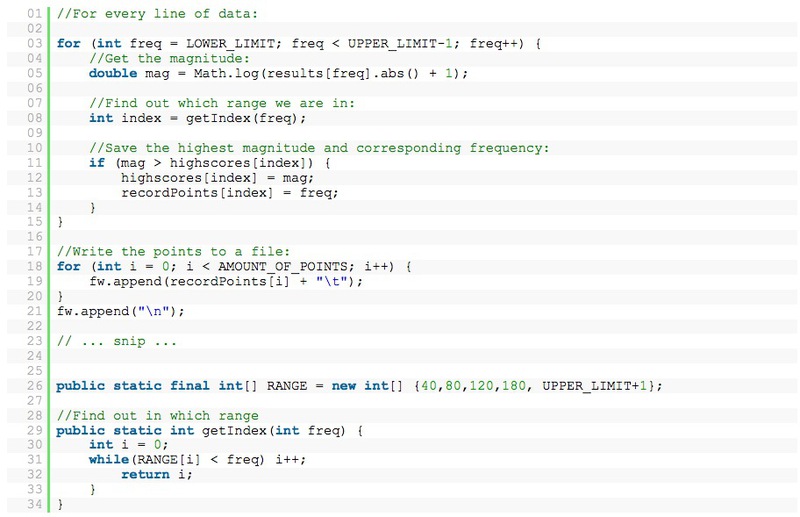
Теперь, когда мы записываем песню, мы получаем список чисел, подобных этому:

Если я запишу песню и визуализирую ее, то она будет выглядеть примерно так:

(все красные точки – «ключевые точки»)
Индексация моей собственной музыки
Имея на руках рабочий алгоритм, я решил проиндексировать все мои 3000 песен. Вместо микрофона вы можете просто открыть mp3 файлы, конвертировать их в нужный формат, и считать их таким же способом, как и при использовании микрофона, используя AudioInputStream. Конвертирование стерео записей в моно режим оказалось сложнее чем я думал. Примеры можно найти в интернете (требует немного больше кодировки, чтобы выкладывать здесь) придется немного поменять примеры.
Процесс подбора
Наиболее важная часть приложения – процесс подбора. Из руководства к Shazam понятно, что они используют знаки чтобы найти совпадения и затем решить какая песня доходит лучше всего.
Вместо использования замысловатых временных группировок точек я решил строку наших данных (например, 33, 47, 94, 137) как один единственный знак: 1370944733
(в процессе тестирования, 3 или 4 точки – лучший вариант, сложнее с тонкой настройкой, каждый раз приходится реиндексировать мои mp3!)
Пример кодировки знаками, используя 4 точки на линию:

Теперь я создам два массива данных:
-Список песен, List (где List index это Song-ID, String это songname)
-Базу данных знаков: Map<Long, List>
Long в базе данных знаков представляет собой сам знак, и включает в себя сегмент DataPoints.
DataPoints выглядят следующим образом:

Теперь у нас есть все что нужно для начала поиска. Сначала я считал все песни и сгенерировал знаки для каждой точки данных. Это войдет в базу данных знаков.
Второй шаг – считывание данных песни, которую мы хотим определить. Эти знаки извлекаются и производится поиск совпадений с базой данных.
Это только одна проблема, для каждого знака существует несколько хитов, но как мы определим какая песня та самая..? По количеству совпадений? Нет, так не пойдет…
Наиболее важная штука – это время. Мы должны наложить время…! Но как нам это сделать, если мы не знаем в какой части песни находимся? С таким же успехом мы просто могли записать последние аккорды песни.
Изучая данные, я нашел нечто интересное, так как мы имеем следующие данные:
— Знаки записи
— Совпадающие знаки вероятных вариантов
— ID песни вероятных вариантов
— Временной поток в наших собственных записях
— Время знаков вероятных вариантов
Теперь мы можем сминусовать текущее время в нашей записи (например, строка 34) с временем знака (например, строка 1352). Эта разница сохраняется вместе с ID песни. Так как этот контраст, эта разница, указывает нам на то, где мы можем находиться в песне.
После того, как мы покончим со всеми знаками из нашей записи мы останемся с кучей ID песен и контрастов. Фишка в том, что если у вас много знаков с подобранными контрастами, то вы нашли свою песню.
Итоги
К примеру, слушая The Kooks – Match Box первые 20 секунд, мы получаем следующие данные в моем приложении:

Работает!!!
Прослушав 20 секунд оно может определить почти все песни, которые у меня есть. И даже эту live recording of the Editors можно определить после 40 секунд прослушивания!
И снова, это чувство волшебства!
В настоящий момент, код нельзя считать завершенным и он работает неидеально. Я слепил его за один уикенд, это больше похоже на доказательство теории/изучение алгоритма.
Возможно, если достаточное количество людей об этом попросят, то я доведу его до ума и где-нибудь выложу.
Дополнение
Юристы обладателей патентных прав на Shazam присылают мне мейлы с просьбой прекратить выпуск кода и удалении этой темы, прочитать об этом можно здесь.
От переводчика
Небольшой анонс: летом 2013 года Яндекс открывает Tolstoy Summer Camp— экспериментальную мастерскую для тех, кто хочет научиться создавать и запускать стартапы. В рамках двухмесячного курса Яндекс поможем участникам собрать достойную команду, правильно сформулировать концепцию, получить на нее фидбек от правильных экспертов и разработать прототип проекта. Разнообразные семинары и воркшопы позволят прокачать необходимые скилзы. Также мы будем регулярно публиковать интересные переводные статьи на около стартапную тематику. Если вам попадается что-то интересное, кидайте в личку! Кст, статья на хабре как Яндекс учился распознавать музыку.
Подать заявку (осталось 2 дня!!) и найти более подробную информацию можно здесь. А также в анонсе на хабре. Я буду рассказывать про Lean-методы, Customer Development и MVP. Приходите!
