Предметом внимания вчерашнего поста на Хабре стал фреймворк распределенных вычислений от Microsoft Research — Dryad.
В основе фреймворка лежит представление задания, как направленного ациклического графа, где вершины графа представляют собой программы, а ребра — каналы, по которым данные передаются. Также обзорно была рассмотрена экосистема фреймворка Dryad и сделан подробный обзор архитектуры одного из центральных компонентов экосистемы фреймворка – среды исполнения распределенных приложений Dryad.
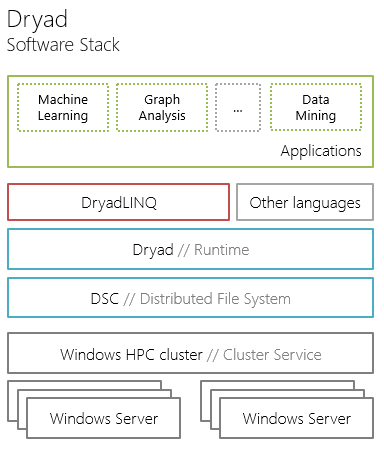
В этой статье обсудим компонент верхнего уровня программного стэка фреймворка Dryad – язык запросов к распределенному хранилищу DryadLINQ.
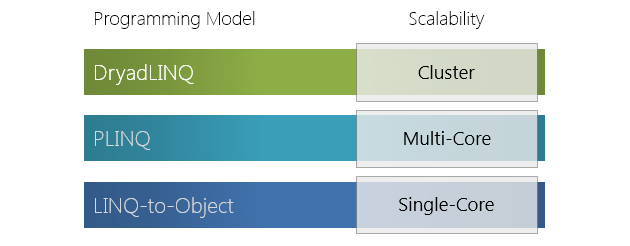
1. Общие сведения
DryadLINQ – высокоуровневый язык запросов к данным, хранящимся в распределенной файловой системе, имеющий SQL-подобный синтаксис. DryadLINQ базируется на программной модели .NET Language Integrated Query (LINQ), реализует специфический LINQ-провайдер для взаимодействия с средой исполнения Dryad и предоставляет разработчику API для написания распределено исполняющихся LINQ-выражений.
В отличие от языков запросов для платформы Hadoop – HiveQL, Pig Latin – DryadLINQ не является еще одним языком запросов со специфическим синтаксисом (необходимым для изучения). Вместо этого DryadLINQ базируется на хорошо знакомых .NET-разработчикам:
Раскрывая первый пункт вышеприведенного списка, стоит отметить, что LINQ изначально не содержал явных ссылок на природу хранилища данных, к которому осуществляется запрос. И, построенные на основе LINQ, API DryadLINQ такжене «выдает» стремиться не «выдавать» своей распределенной природы.
Таким образом, за счет минимизации различий синтаксиса для написания запроса к БД (на LINQ-to-SQL) или к распределенной файловой системе (на DryadLINQ), существенно облегчается решение одного из наиболее частых case’ов — миграции от хранилища на основе БД к хранилищу на основе распределенной файловой системы.
Так представляется DryadLINQ для разработчика распределенных приложений. Ниже поговорим, о внутренней реализации DryadLINQ: о этапах выполнения запросов к данным, компонентах и концепциях, лежащих в основе DryadLINQ.
2. Этапы выполнения

Источник иллюстрации [5]
Шаг 1. Пользовательское распределенное приложение, содержащее LINQ-выражение запущено. LINQ-выражения исполняются отложено (не будут выполнены пока данные, возвращаемые запросом данные, не понадобятся). DryadLINQ-выражения также выполняются отложено.
Шаг 2. При разборе LINQ-выражения вызывается специфичный для DryadLINQ триггер «ToDryadTable()». DryadLINQ перехватывает этот триггер (т.о. на этом этапе становится ясно, что запрос к данным будет распределенным).
Шаг 3. DryadLINQ компилирует LINQ-выражение в распределенный план запросов Dryad: дерево LINQ-выражения раскладывается над подзапросы, каждый из которых представляет собой отдельную вершину в будущем графе исполнения Dryad; происходит генерация служебных данных необходимых для запуска удаленных vertex-операций, генерация исполняемого на вершинах кода, сериализация необходимых типов данных.
Шаг 4. DryadLINQ вызывает специфичный для приложения Dryad Job Manager.
Шаг 5. Job Manager создает граф исполнения приложения, используя план, сгенерированный на этапе 3.
Шаг 6. Vertex программы исполняются на определенных для них вершинах.
Шаг 7. По окончанию исполнения Dryad-задания результат записывается в выходную(ые) таблицу(ы).
Шаг 8. Job Manager возвращает результат на узел, выполняющий DryadLINQ-задание и завершается.
Шаг 9. Контроль возвращается приложению, инициировавшему выполнение DryadLINQ-выражения. Результат выполнения запроса представляет собой объект DryadTable. DryadTable реализует IEnumerable<T>, поэтому к содержимому строготипизированной коллекции DryadTable можно получить доступ как к обычным .NET-объектам.
3. Компилятор DryadLINQ
Сердце языка запросов DryadLINQ – параллельный компилятор (parallel compiler) DryadLINQ. Если проводить аналогию с миром языка запросов SQL, то компилятор DryadLINQ можно сравнить с планировщиком/оптимизатором запросов СУБД.
Компилятор ответственен за компиляцию DryadLINQ-выражения в распределенную программу, запускаемую на Dryad-кластере. Компилятор DryadLINQ содержит в себя как статический компонент, генерирующий план исполнения, так и динамический компонент, позволяющий оптимизировать исполнения, основываясь на различных политиках, изменяя план исполнения прямо в runtime.
3.1. Execution Plan Graph
При передачи управления компилятору, последний трансформирует LINQ-выражение в граф плана исполнения (Execution Plan Graph, EPG). EPG представляет собой прототип графа исполнения (то есть не окончательный план).
DryadLINQ оптимизатор также дополняет EPG метаданными, которые могут дать дополнительную информацию о распределенном задании во время планирования и исполнения. Так для вершин графа это информация о схеме партицирования данных, а для ребер графа – это .NET тип данных и схема сжатия данных, если таковая имеется.
3.2. DryadLINQ Optimizations
В свою очередь, DryadLINQ оптимизатор выполняет как статическую оптимизацию на основе жадных алгоритмов (greedy heuristics), так и динамическую оптимизацию, основанную на собранной во время исполнения статистической информации.
Статическая оптимизация
Основные задачи статического оптимизатора две: минимизация количество операций ввода-вывода на дисковых носителях и в сети. Что логично, так как традиционно дисковая подсистема и интерфейсы межмашинного взаимодействия являются узким местом в распределенных вычислительных средах.
Наиболее интересные техники статической оптимизации приведены ниже:
Динамическая оптимизация
Динамический оптимизатор изменяет граф исполнения во время выполнения распределенной задачи. Таким образом, основываясь на собранных статистических данных (потенциально, даже специально обученной модели), оптимизатор может переопределить граф. Основные техники динамической оптимизации приведены ниже:
Dynamic aggregation: агрегация данных — один из самых эффективных способов уменьшения объемов данных предаваемых между узлами. Агрегация происходит по очереди на уровне вычислительного узла, стойки и кластера. Такая оптимизация очень сильно зависит от топологического расположение узла и агрегируемых данных, поэтому наиболее эффективно ее проводить во время исполнения (т.е. динамически).
Data-dependent partitioning: оптимизатор динамически устанавливает количество партиций (partition) в наборе данных в зависимости от его размера входного набора данных. Также как и с Dynamic aggregation, оценить размер входного набора точно представляется возможным только во время выполнения распределенного задания.
4. Практика
Подсчет слов
DryadLINQ предлагает удивительно лаконичный синтаксис для написания запросов к данным. Следующий листинг, представляет собой полную реализацию вычисления в соответствии с моделью map/reduce:
Листинг 1. Реализация программной модели map/reduce.
Листинг 2 демонстрирует как реализацию программной модели map/reduce, представленную выше, использовать для создания Dryad-задания подсчета слов в неком источнике данных foo.pt (Partitioned Table), хранящемся в распределенной файловой системе.
Листинг 2. Подсчет слов с помощью DryadLINQ.
Фреймворк Dryad генерирует для данного приложения следующий граф исполнения:

Источник иллюстрации [3].
Причем граф исполнения на шаге (2) и (3) генерируются динамически на основе информации о объеме пересылаемых между вершинами данных и топологическом расположении vertex-операций, обрабатывающий эти данные.
Расчет PageRank
Листинги 3-5 представляет код распределенного алгоритма расчета PageRank.
Листинг 3. Реализация алгоритма расчета PageRank [5].
Листинг 4. Расчет PageRank с помощью DryadLINQ. Источник [5].
Передача данных между различными итерациями будет происходить посредством канала in-memory FIFO, что гарантирует на порядок более высокую производительность, чем передача данных по сети, как это имеет место при реализации аналогичного алгоритма в Hadoop (речь о последней release-версии [plain] Hadoop).

Источник иллюстрации [5]
Дополнение к иллюстрации: передача данных между итерациями iteration 1 > iteration 2 > … > iteration n происходит исключительно через канал in-memory FIFO.
5. Ограничения
Фреймворк Dryad, в отличие от Hadoop MapReduce, не смешивает ответственности исполнения распределенного приложения и программной модели/языка запросов, с помощью которой такие приложения можно писать.
Несмотря на такое разделение ответственностей, по моему мнению, программная модель DryadLINQ внутри себя все-таки смешивает ответственности, когда берет на себя не только прямые обязательства, касающиеся интерпретации LINQ-выражений в Dryad-программы, но и занимается построением EPG-графов выполнения и оптимизациями. Последнее неизбежно приведет к более длительному времени запуска Dryad-задания: на интерпретацию DryadLINQ-выражения тратится большее количество тактов CPU, чем могло уходить бы при меньшем количестве обязательств.
Как следствие, интерпретация множества DryadLINQ-выражений на одном вычислительном узле будет оказывать большее негативное влияние на время исполнения задания как на локальном уровне, так и на уровне кластера в целом. Хотя все же я не вижу, как описанная проблема может перерасти в проблему масштабируемости Dryad-кластера в целом.
Еще одно замечание связано со статическим оптимизатором, которому, чтобы эффективно применять оптимизации, нужно знать слишком много, в том числе и о внутренних «делах» компонентов среды исполнения Dryad – топология веб-узлов, схема партицирования данных.
Из документации осталось неясным, что за статистика у динамического оптимизатора: ведь статистика количества операций ввода/вывода – это опять же внутренние данные execution engine (Dryad runtime), которые не должны раскрываться на уровне программной модели (DryadLINQ).
6. Достоинства
Полноценный язык программирования
Разработка с использованием современных высокоуровневых языков программирования, модели LINQ с возможностью написания запросов к данным в функциональном стиле.
Строгая типизация данных
Фреймворк Dryad производит вычисления над строго типизированными данными и возвращает строго типизированные коллекции объектов.
Автоматическая сериализация данных
Данные автоматически сериализуются/десериализуются фреймворком при передаче по каналам.
Автоматическое распараллеливание выполнения
DryadLINQ генерирует план распределенного исполнения, выполняющийся в кластер. Улучшенная утилизация многопроцессорных вычислительных узлов, благодаря использованию PLINQ (Parallel LINQ) для задач выполняющихся локально.
Автоматическая оптимизация исполнения
Граф выполнения оптимизируется специальным компонентов фреймворка Dryad как во время создания плана исполнения, используя политики оптимизации, так и динамически во время исполнения, полагаясь на статистические данные.
Знакомые инструменты разработки
Для написание MPP-приложений, использующих программную модель DryadLINQ, можно использовать MS Visual Studio, а также такие возможности VS как: Intellisense, code refactoring, integrated debugging, build, source code management.
100% совместимость с .NET Framework
DryadLINQ можно использовать с любыми .NET-библиотеки и CLS-совместимыми языками программирования со статической типизацией.
Заключение
DryadLINQ – знакомая .net-разработчикам программная модель, прекрасно интегрированная в существующий стэк .NET Framework, обладающая выразительностью и лаконичностью, свойственные функциональному стилю написания программ. Кроме того, модель DryadLINQ предоставляет разработчикам LINQ-подобный синтаксис написания запросов к распределенному хранилищу данных, инкапсулируя в себе детали распределенной природы запроса, планирование выполнения и его оптимизации.
Список источников
[1] The DryadLINQ Project. Microsoft Research.
[2] M. Isard and Y. Yu. Distributed data-parallel computing using a high-level programming language. In International Conference on Management of Data (SIGMOD), 2009.
[3] Y. Yu, M. Isard, D. Fetterly, M. Budiu, U. Erlingsson, P. K. Gunda, and J. Currey. DryadLINQ: A system for general-purpose distributed data-parallel computing using a high-level language. In Proceedings of the 8th Symposium on Operating Systems Design and Implementation (OSDI), 2008.
[4] Y. Yu, M. Isard, D. Fetterly, M. Budiu, U. Erlingsson, P. K. Gunda, J. Currey, Report MSR-TR-2008-74, Microsoft Research, 2008.
[5] Jinyang Li. Dryad / DryadLINQ Slides adapted from those of Yuan Yu and Michael Isard, 2009.
В основе фреймворка лежит представление задания, как направленного ациклического графа, где вершины графа представляют собой программы, а ребра — каналы, по которым данные передаются. Также обзорно была рассмотрена экосистема фреймворка Dryad и сделан подробный обзор архитектуры одного из центральных компонентов экосистемы фреймворка – среды исполнения распределенных приложений Dryad.
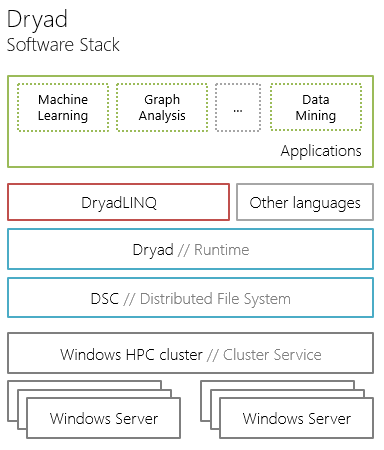
В этой статье обсудим компонент верхнего уровня программного стэка фреймворка Dryad – язык запросов к распределенному хранилищу DryadLINQ.
#region Лирическое отступление (о мотивации написания)
Вчерашняя статья о Dryad я упустил один абзац, который надо писать всегда, когда пишешь что-то о продуктах Microsoft.
Подчеркиваю: я не предлагаю, как и не отговариваю использовать Dryad в своих исследовательских проектах (т.к. сейчас доступна только академическая лицензия). Более этого я повторюсь, что Dryad это «внутренний» продукт всем нам известной корпорациизла, стратегию развития которого [продукта и зла] Microsoft вправе решать единолично (что вполне справедливо).
Все эти факты не делают (говорю за себя) изучение идей и концепций платформы Dryad менее интересным или менее полезным для профессионального развития (опять – за себя). Если у Вас что-то по-другому — тос этим не ко мне это исключительно Ваше дело.
Для тех, кточитает через строчку беспокоится, что статья о сравнении с Hadoop open-source проектами, а не о DryadLINQ, намекну, что сравнение с альтернативными решениями будет только в следующей статье.
Подчеркиваю: я не предлагаю, как и не отговариваю использовать Dryad в своих исследовательских проектах (т.к. сейчас доступна только академическая лицензия). Более этого я повторюсь, что Dryad это «внутренний» продукт всем нам известной корпорации
Все эти факты не делают (говорю за себя) изучение идей и концепций платформы Dryad менее интересным или менее полезным для профессионального развития (опять – за себя). Если у Вас что-то по-другому — то
Для тех, кто
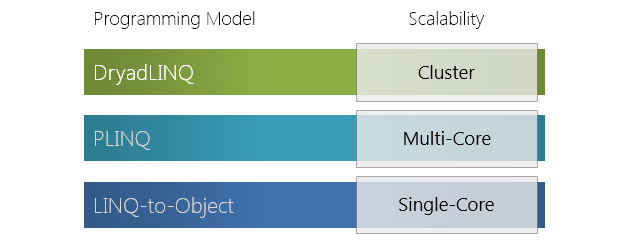
1. Общие сведения
We want them to be able to write sequential and declarative code, and then, that same code can be run on a single machine, on a multicore machine, or on a cluster of machines. That’s the beauty of the DryadLINQ programming model.
— Yuan Yu, Principal Researcher, Microsoft Research
DryadLINQ – высокоуровневый язык запросов к данным, хранящимся в распределенной файловой системе, имеющий SQL-подобный синтаксис. DryadLINQ базируется на программной модели .NET Language Integrated Query (LINQ), реализует специфический LINQ-провайдер для взаимодействия с средой исполнения Dryad и предоставляет разработчику API для написания распределено исполняющихся LINQ-выражений.
В отличие от языков запросов для платформы Hadoop – HiveQL, Pig Latin – DryadLINQ не является еще одним языком запросов со специфическим синтаксисом (необходимым для изучения). Вместо этого DryadLINQ базируется на хорошо знакомых .NET-разработчикам:
- унифицированной программной модели LINQ;
- => как следствие — изящный функциональный подход для при написании запросов к данным;
- объектной модели .NET Framework;
- среде разработки MS Visual Studio;
- высокоуровневых ЯП, таких как C#, F# или любого CLS-совместимого языка.
Раскрывая первый пункт вышеприведенного списка, стоит отметить, что LINQ изначально не содержал явных ссылок на природу хранилища данных, к которому осуществляется запрос. И, построенные на основе LINQ, API DryadLINQ также
Таким образом, за счет минимизации различий синтаксиса для написания запроса к БД (на LINQ-to-SQL) или к распределенной файловой системе (на DryadLINQ), существенно облегчается решение одного из наиболее частых case’ов — миграции от хранилища на основе БД к хранилищу на основе распределенной файловой системы.
Так представляется DryadLINQ для разработчика распределенных приложений. Ниже поговорим, о внутренней реализации DryadLINQ: о этапах выполнения запросов к данным, компонентах и концепциях, лежащих в основе DryadLINQ.
2. Этапы выполнения

Источник иллюстрации [5]
Шаг 1. Пользовательское распределенное приложение, содержащее LINQ-выражение запущено. LINQ-выражения исполняются отложено (не будут выполнены пока данные, возвращаемые запросом данные, не понадобятся). DryadLINQ-выражения также выполняются отложено.
Шаг 2. При разборе LINQ-выражения вызывается специфичный для DryadLINQ триггер «ToDryadTable()». DryadLINQ перехватывает этот триггер (т.о. на этом этапе становится ясно, что запрос к данным будет распределенным).
Шаг 3. DryadLINQ компилирует LINQ-выражение в распределенный план запросов Dryad: дерево LINQ-выражения раскладывается над подзапросы, каждый из которых представляет собой отдельную вершину в будущем графе исполнения Dryad; происходит генерация служебных данных необходимых для запуска удаленных vertex-операций, генерация исполняемого на вершинах кода, сериализация необходимых типов данных.
Шаг 4. DryadLINQ вызывает специфичный для приложения Dryad Job Manager.
Шаг 5. Job Manager создает граф исполнения приложения, используя план, сгенерированный на этапе 3.
Шаг 6. Vertex программы исполняются на определенных для них вершинах.
Шаг 7. По окончанию исполнения Dryad-задания результат записывается в выходную(ые) таблицу(ы).
Шаг 8. Job Manager возвращает результат на узел, выполняющий DryadLINQ-задание и завершается.
Шаг 9. Контроль возвращается приложению, инициировавшему выполнение DryadLINQ-выражения. Результат выполнения запроса представляет собой объект DryadTable. DryadTable реализует IEnumerable<T>, поэтому к содержимому строготипизированной коллекции DryadTable можно получить доступ как к обычным .NET-объектам.
3. Компилятор DryadLINQ
Сердце языка запросов DryadLINQ – параллельный компилятор (parallel compiler) DryadLINQ. Если проводить аналогию с миром языка запросов SQL, то компилятор DryadLINQ можно сравнить с планировщиком/оптимизатором запросов СУБД.
Компилятор ответственен за компиляцию DryadLINQ-выражения в распределенную программу, запускаемую на Dryad-кластере. Компилятор DryadLINQ содержит в себя как статический компонент, генерирующий план исполнения, так и динамический компонент, позволяющий оптимизировать исполнения, основываясь на различных политиках, изменяя план исполнения прямо в runtime.
3.1. Execution Plan Graph
При передачи управления компилятору, последний трансформирует LINQ-выражение в граф плана исполнения (Execution Plan Graph, EPG). EPG представляет собой прототип графа исполнения (то есть не окончательный план).
DryadLINQ оптимизатор также дополняет EPG метаданными, которые могут дать дополнительную информацию о распределенном задании во время планирования и исполнения. Так для вершин графа это информация о схеме партицирования данных, а для ребер графа – это .NET тип данных и схема сжатия данных, если таковая имеется.
3.2. DryadLINQ Optimizations
В свою очередь, DryadLINQ оптимизатор выполняет как статическую оптимизацию на основе жадных алгоритмов (greedy heuristics), так и динамическую оптимизацию, основанную на собранной во время исполнения статистической информации.
Статическая оптимизация
Основные задачи статического оптимизатора две: минимизация количество операций ввода-вывода на дисковых носителях и в сети. Что логично, так как традиционно дисковая подсистема и интерфейсы межмашинного взаимодействия являются узким местом в распределенных вычислительных средах.
Наиболее интересные техники статической оптимизации приведены ниже:
- Pipelining (внутрипроцессовое взаимодействие): оптимизатор старается максимально локализовать расчеты в рамках одного вычислительного узла, если это возможно;
- I/O reduction: оптимизатор старается использовать TCP-pipe и in-memory FIFO для передачи данных между vertex-операциями вместо способа передачи данных по умолчанию – записи/чтения временных файлов на/с диска (подробно каналы данных Dryad разбирались в прошлой статье);
- Removing redundancy: оптимизатор удаляет избыточные/ненужные hash- и range-partitioning шаги.
Динамическая оптимизация
Динамический оптимизатор изменяет граф исполнения во время выполнения распределенной задачи. Таким образом, основываясь на собранных статистических данных (потенциально, даже специально обученной модели), оптимизатор может переопределить граф. Основные техники динамической оптимизации приведены ниже:
Dynamic aggregation: агрегация данных — один из самых эффективных способов уменьшения объемов данных предаваемых между узлами. Агрегация происходит по очереди на уровне вычислительного узла, стойки и кластера. Такая оптимизация очень сильно зависит от топологического расположение узла и агрегируемых данных, поэтому наиболее эффективно ее проводить во время исполнения (т.е. динамически).
Data-dependent partitioning: оптимизатор динамически устанавливает количество партиций (partition) в наборе данных в зависимости от его размера входного набора данных. Также как и с Dynamic aggregation, оценить размер входного набора точно представляется возможным только во время выполнения распределенного задания.
4. Практика
Подсчет слов
DryadLINQ предлагает удивительно лаконичный синтаксис для написания запросов к данным. Следующий листинг, представляет собой полную реализацию вычисления в соответствии с моделью map/reduce:
Листинг 1. Реализация программной модели map/reduce.
public static IQueryable<TResult> MapReduce<TSource, TMap, TKey, TResult>(
this IQueryable<TSource> source,
Expression<Func<TSource, IEnumerable<TMap>>> mapper,
Expression<Func<TMap, TKey>> keySelector,
Expression<Func<IGrouping<TKey, TMap>, TResult>> reducer)
{
return source
.SelectMany(mapper)
.GroupBy(keySelector)
.Select(reducer);
} Листинг 2 демонстрирует как реализацию программной модели map/reduce, представленную выше, использовать для создания Dryad-задания подсчета слов в неком источнике данных foo.pt (Partitioned Table), хранящемся в распределенной файловой системе.
Листинг 2. Подсчет слов с помощью DryadLINQ.
const string inputPath = @"file://\\machine\directory\foo.pt";
const string outputPath = @"file://\\machine\directory\count.pt";
PartitionedTable<LineRecord> inputTable = PartitionedTable.Get<LineRecord>(inputPath);
var result = inputTable.MapReduce(
r => r.Line.Split(' '), // r: rows
w => w, // w: words
g => new Tuple<string, int>(g.Key, g.Count())); // g: groups
result.ToDryadPartitionedTable(outputPath);Фреймворк Dryad генерирует для данного приложения следующий граф исполнения:
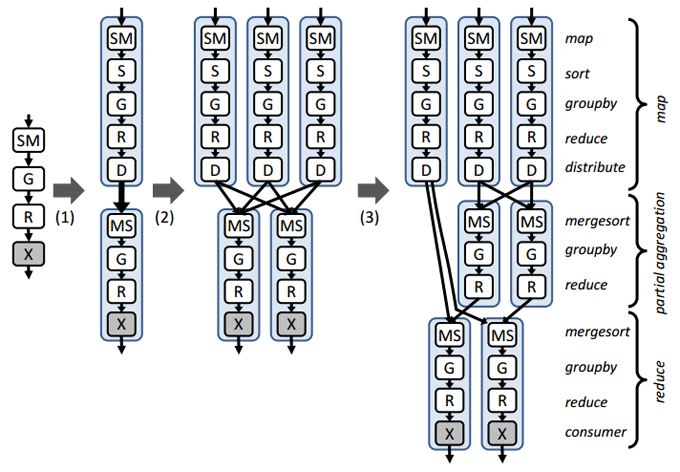
Источник иллюстрации [3].
Причем граф исполнения на шаге (2) и (3) генерируются динамически на основе информации о объеме пересылаемых между вершинами данных и топологическом расположении vertex-операций, обрабатывающий эти данные.
Расчет PageRank
Листинги 3-5 представляет код распределенного алгоритма расчета PageRank.
Листинг 3. Реализация алгоритма расчета PageRank [5].
public static IQueryable<Rank> PRStep(IQueryable<Page> pages, IQueryable<Rank> ranks)
{
// join pages with ranks, and disperse updates
var updates = from page in pages
join rank in ranks on page.Name equals rank.Name
select page.Disperse(rank);
// re-accumulate
return from list in updates
from rank in list
group rank.Rank by rank.Name into g
select new Rank(g.Key, g.Sum());
} Листинг 4. Расчет PageRank с помощью DryadLINQ. Источник [5].
const string inputPath = @"dfs://pages.txt";
const string outputPath = @"dfs://outputranks.txt";
var pages = PartitionedTable.Get<Page>(inputPath);
var ranks = pages.Select(page => new Rank(page.Name, 1.0));
const int iterationCount = 1000;
for (int iter = 0; iter < iterationCount; iter++)
ranks = PRStep(pages, ranks);
ranks.ToPartitionedTable<Rank>(outputPath); Листинг 5. Вспомогательные классы. Источник [5]
public class Page
{
public Page(Int64 name, Int64 degreee, Int64[] links)
{
this.Name = name;
this.Degree = degreee;
this.Links = links;
}
public Int64 Name { get; set; }
public Int64 Degree { get; set; }
public Int64[] Links { get; set; }
public Rank[] Disperse(Rank rank)
{
Rank[] ranks = new Rank[Links.Length];
double score = rank.Value / this.Degree;
for (int i = 0; i < ranks.Length; i++)
ranks[i] = new Rank(this.Links[i], score);
return ranks;
}
}
public class Rank
{
public Rank(Int64 name, double rank)
{
this.Name = name;
this.Value = rank;
}
public Int64 Name { get; set; }
public double Value { get; set; }
} Передача данных между различными итерациями будет происходить посредством канала in-memory FIFO, что гарантирует на порядок более высокую производительность, чем передача данных по сети, как это имеет место при реализации аналогичного алгоритма в Hadoop (речь о последней release-версии [plain] Hadoop).
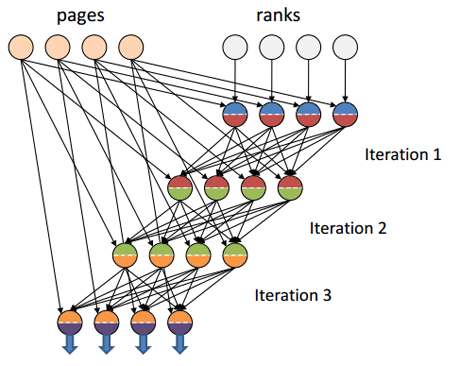
Источник иллюстрации [5]
Дополнение к иллюстрации: передача данных между итерациями iteration 1 > iteration 2 > … > iteration n происходит исключительно через канал in-memory FIFO.
5. Ограничения
Фреймворк Dryad, в отличие от Hadoop MapReduce, не смешивает ответственности исполнения распределенного приложения и программной модели/языка запросов, с помощью которой такие приложения можно писать.
Несмотря на такое разделение ответственностей, по моему мнению, программная модель DryadLINQ внутри себя все-таки смешивает ответственности, когда берет на себя не только прямые обязательства, касающиеся интерпретации LINQ-выражений в Dryad-программы, но и занимается построением EPG-графов выполнения и оптимизациями. Последнее неизбежно приведет к более длительному времени запуска Dryad-задания: на интерпретацию DryadLINQ-выражения тратится большее количество тактов CPU, чем могло уходить бы при меньшем количестве обязательств.
Как следствие, интерпретация множества DryadLINQ-выражений на одном вычислительном узле будет оказывать большее негативное влияние на время исполнения задания как на локальном уровне, так и на уровне кластера в целом. Хотя все же я не вижу, как описанная проблема может перерасти в проблему масштабируемости Dryad-кластера в целом.
Еще одно замечание связано со статическим оптимизатором, которому, чтобы эффективно применять оптимизации, нужно знать слишком много, в том числе и о внутренних «делах» компонентов среды исполнения Dryad – топология веб-узлов, схема партицирования данных.
Из документации осталось неясным, что за статистика у динамического оптимизатора: ведь статистика количества операций ввода/вывода – это опять же внутренние данные execution engine (Dryad runtime), которые не должны раскрываться на уровне программной модели (DryadLINQ).
DryadLINQ performs both static and dynamic optimizations. [3]По процитированному выше отрывку сразу возникает вопрос: почему задача динамический оптимизации входит в зону ответственности DryadLINQ? Ведь по семантике динамический оптимизатор работает уже после окончательной интерпретации DryadLINQ-выражения, то есть на уровне среды исполнения.
6. Достоинства
Полноценный язык программирования
Разработка с использованием современных высокоуровневых языков программирования, модели LINQ с возможностью написания запросов к данным в функциональном стиле.
Строгая типизация данных
Фреймворк Dryad производит вычисления над строго типизированными данными и возвращает строго типизированные коллекции объектов.
Автоматическая сериализация данных
Данные автоматически сериализуются/десериализуются фреймворком при передаче по каналам.
Автоматическое распараллеливание выполнения
DryadLINQ генерирует план распределенного исполнения, выполняющийся в кластер. Улучшенная утилизация многопроцессорных вычислительных узлов, благодаря использованию PLINQ (Parallel LINQ) для задач выполняющихся локально.
Автоматическая оптимизация исполнения
Граф выполнения оптимизируется специальным компонентов фреймворка Dryad как во время создания плана исполнения, используя политики оптимизации, так и динамически во время исполнения, полагаясь на статистические данные.
Знакомые инструменты разработки
Для написание MPP-приложений, использующих программную модель DryadLINQ, можно использовать MS Visual Studio, а также такие возможности VS как: Intellisense, code refactoring, integrated debugging, build, source code management.
100% совместимость с .NET Framework
DryadLINQ можно использовать с любыми .NET-библиотеки и CLS-совместимыми языками программирования со статической типизацией.
Заключение
DryadLINQ – знакомая .net-разработчикам программная модель, прекрасно интегрированная в существующий стэк .NET Framework, обладающая выразительностью и лаконичностью, свойственные функциональному стилю написания программ. Кроме того, модель DryadLINQ предоставляет разработчикам LINQ-подобный синтаксис написания запросов к распределенному хранилищу данных, инкапсулируя в себе детали распределенной природы запроса, планирование выполнения и его оптимизации.
Для тех, кто заскучал (или бонус)
В 3-ей заключительной части цикла будет проведено сравнение фреймворка Dryad с другими MPP «инструментами» – реляционными СУБД, GPU-вычислениями и платформой Hadoop. Поэтому впереди нас ждут 'увлекательные' споры в комментариях на тему 'Виндовс глючит' и падение кармы.
Список источников
[1] The DryadLINQ Project. Microsoft Research.
[2] M. Isard and Y. Yu. Distributed data-parallel computing using a high-level programming language. In International Conference on Management of Data (SIGMOD), 2009.
[3] Y. Yu, M. Isard, D. Fetterly, M. Budiu, U. Erlingsson, P. K. Gunda, and J. Currey. DryadLINQ: A system for general-purpose distributed data-parallel computing using a high-level language. In Proceedings of the 8th Symposium on Operating Systems Design and Implementation (OSDI), 2008.
[4] Y. Yu, M. Isard, D. Fetterly, M. Budiu, U. Erlingsson, P. K. Gunda, J. Currey, Report MSR-TR-2008-74, Microsoft Research, 2008.
[5] Jinyang Li. Dryad / DryadLINQ Slides adapted from those of Yuan Yu and Michael Isard, 2009.
