Откровенно говоря, ранее я ни разу не занимался в серьезной мере методами тестирования программного обеспечения. Однако, понимаю, что для полной уверенности в том, что программа будет работать, нужно перепробовать всевозможные варианты её использования. Также очевиден для меня и тот факт, что сделать это не всегда возможно. Если имеются конкретные варианты использования, но невозможно проверить их всех в силу их количества, стараются построить набор, который покроет все самые используемые варианты. Но что делать, если использование всех вариантов равновероятно? Как за минимальное число времени обнаружить все ошибки, на которые есть большая вероятность наткнуться? Данная задача действительно известна, и с ней нередко сталкиваются, ну хотя бы, в Яндексе.
Чтобы стало понятно о чем идет речь, представим, что нам необходимо протестировать какую-либо программу или сайт. Очень хорош пример с тестированием веб-формы, скажем, для регистрации или для поиска. Возникает вопрос, с какими ошибками в ней скорее всего встретится пользователь? Пускай у нас в форме имеется 6 вопросов, для каждого из которых возможны 10 вариантов ответа. Допустим, на страницу зашел целый миллион пользователей, и каждый из них ответил уникально. Теперь представим, что в форме для заполнения ответами скрывается ошибка. Если ошибка обнаруживается только при определенной комбинации ответов на все 6 вопросов, то на неё наткнется лишь один человек. Если же ошибка вылетает при наборе определенных ответов на какие-то 3 вопроса, то количество людей, обнаруживших ошибку возрастет до тысячи. Очевидно, что чем меньше элементов в комбинации, требуемой для ошибки, тем больше людей с ней встретится. Соответственно, перед нами теперь стоит задача: если мы не можем обнаружить все ошибки, то давайте хотя бы найдем самые критичные, то есть те, на которые наткнется больше всего пользователей.
Таким образом, мы должны сформировать тест-кейсы (и чем меньше, тем лучше), при переборе которых мы наткнемся на самые легкодоступные ошибки. Допустим, у нас имеется множество вопросов A, которое мы задаем количеством вариантов ответа на каждый из них: А = {2, 3, 5, 2, ...}. Пусть n — количество вопросов, а 1≤m≤n — степень критичности ошибок, она же степень покрытия или глубина покрывающего набора. Чем меньше значение m, тем критичнее ошибка. Задавая степень покрытия мы строим тестовый набор, который позволит обнаружить все ошибки, степень критичности которых меньше данного m. Если m = n, то поиск ошибок сводится к перебору всех вариантов. Чем меньше задаем степень, тем меньше тест-кейсов будет сформировано и тем меньше ошибок мы найдем.

Удобно представить покрывающий набор тестов в виде матрицы, где строчки соответствуют самому тесту, а столбцы — выбору ответов на вопросы. Для примера возьмем список вопросов A = {3, 3, 3, 3} и набор из одиннадцати тестов как на картинке справа. Такой набор отлично подходит для покрытия степени m = 2, так как при выборе любых двух столбцов в данном наборе между ними будут перебраны всевозможные комбинации.
Как минимизировать количество строчек? Первое, что пришло мне в голову, — это сформировать набор с глубиной покрытия n, то есть все варианты тестов, а затем жадно отбирать из него те, которые убирают наибольшее число еще не покрытых комбинаций из m элементов. Таким образом я пришел к чему-то похожему на жадный поиск покрытия множества. Решив, что так не очень интересно, а, возможно, окажется и не практично, я по этому пути не пошел.
Вероятно, многие из вас с этой задачей уже знакомы, мне же никогда еще не приходилось сталкиваться с подобной проблемой, а учитывая, что срок был дан неделя, пришлось серьезно напрячь извилины. Но учиться никогда не поздно. Три дня и три ночи я пытался придумать алгоритм, который будет работать наилучшим образом или хотя бы лучше, чем яндексовский Jenny. Не думайте, что я не обращался к поисковикам, я попросту не мог даже догадаться, какой запрос загуглить. После долгих мучений и различных переборов я все-таки каким-то чудесным образом из ниоткуда родил метод, который основывался на последовательном дополнении комбинаций при добавлении нового вопроса. Видимо, у меня все-таки немного программистский склад ума, поскольку мне не пришло в голову использовать какие-либо генетические алгоритмы, стохастические методы или что-нибудь подобное, зато явился небанальный, но все же жадный алгоритм.
Каким же было мое удивление, когда еще через несколько дней я узнал, что идея, которую я придумал и взял за основу, и схожая последовательность действий уже существуют, и называется соответствующий алгоритм In Parameter Order, иначе говоря, алгоритм, основанный на добавлении нового параметра. Более того, есть несколько неплохих статей и даже целая книга под названием «Обзор методов построения покрывающих наборов», которые рассматривают задачи такого рода.
Вот как можно классифицировать наиболее известные стратегии:
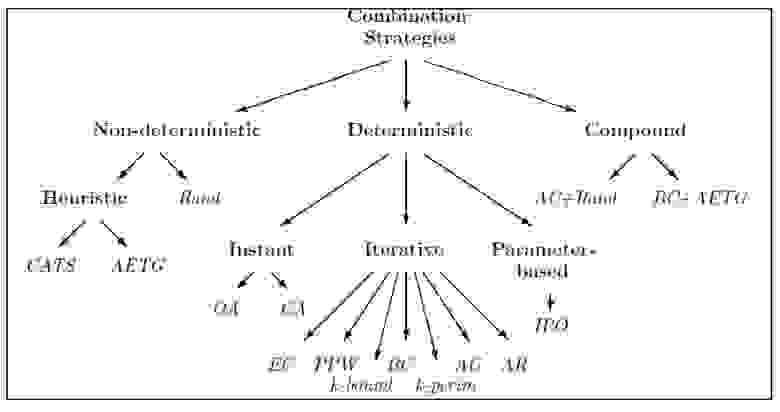
Как вы, наверное, догадались, алгоритм, о котором пойдет речь в моей статье — детерминированный параметризованный IPO с моими личными модификациями. На вход подается A и m, на выход — минимальное число тестов. Стратегия IPO делится на две последовательные части: горизонтальный и вертикальный рост. Сначала мы добавляем столбец, соответствующий новому вопросу, затем добавляются строки, соответствующие недостающим тестам.
Для начала мы берем первые m вопросов и перебираем между ними все комбинации. На выходе получится матрица из m столбцов и количеством строчек, равным A(1)*A(2)*...A(m). Так как в любом случае между этими m столбцами должны быть перебраны все комбинации, то меньшее количество строк мы никак получить не можем. В связи с этим для лучшего результата просто обязательно надо отсортировать вопросы по количеству вариантов в порядке убывания. Почему? Это станет понятно в дальнейшем.
Пускай k — номер итерации + m — 1. То есть первоначальное k = m. Сейчас у нас есть покрытие глубины m для первых k столбцов. Добавляем следующий столбец k+1 следующим образом:
Теперь, если все комбинации покрыты, то переходим снова ко второму шагу, к новому горизонтальному росту, то есть добавляем новый вопрос/столбец. Если количество вопросов закончилось, алгоритм завершается.
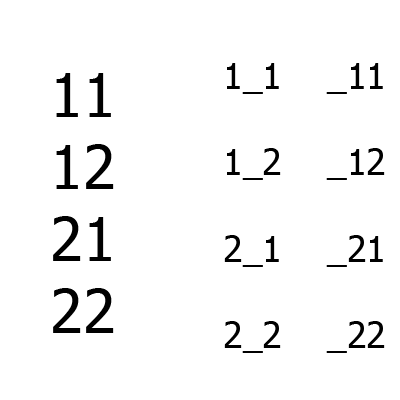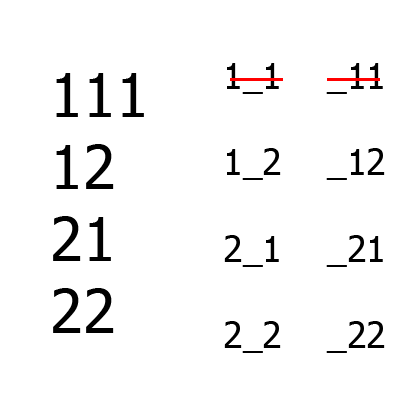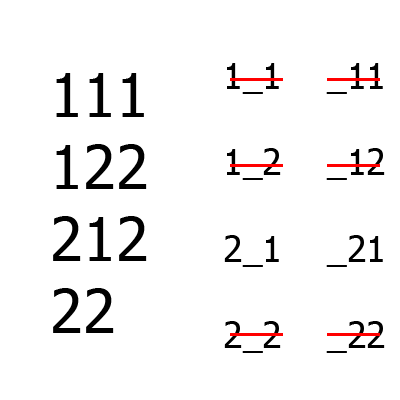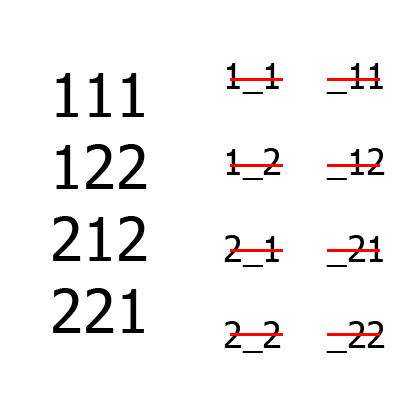
Большие цифры — набор тестов, маленькие — множество B aka непокрытые комбинации (слева — между первым и третьим столбцом, справа — между вторым и третьим). Сначала формируются первые два столбца, затем к ним добавляется третий. Для сравнения, даже для такого простого примера алгоритм Jenny построит на одну больше строк, чем IPO.
Однако может возникнуть ситуация посложнее, когда горизонтальным ростом не обойтись, и придется добавлять новые строки, чтобы покрыть оставшиеся комбинации.
Жадность в горизонтальном росте действительно дает отличные результаты, если отсортировать столбцы по количеству вариантов в порядке убывания. Если добавлять столбец с меньшим количеством вариантов, соответственно с меньшим числом комбинаций с другими столбцами, тем больше вероятность покрыть эти комбинации в горизонтальном росте и избежать вертикального или хотя бы его уменьшить.
Аналогичным образом работаем с вертикальным ростом — добавляем такую строку, которая уберет из B наибольшее количество комбинаций. Здесь искать их уже гораздо сложнее, так как меняется не один элемент, а целая строка, и это наиболее тяжкая часть алгоритма. Поэтому, как правило, этой части избегают и добавляют столько строк, сколько получится, зато за полиномиальное время. Насколько оправдан поиск локально наилучшей строки, точно сказать не могу, но на практике результаты дает хорошие.
Я поступал следующим образом: сортировал в порядке убывания мощности множества b(1), b(2), ..., b(k) — непересекающиеся подмножества B, в которые занесены по соответствующим столбцам непокрытые комбинации. Для ясности: если B = { _11, 1_1, 1_2}, то b(1) = {1_1, 1_2}, b(2) = {_11}. Такая упорядоченность сделана с целью приоритета множеств с наибольшим числом оставшихся комбинаций. Затем я брал первую комбинацию из b(1), далее — любую не противоречащую предыдущей комбинации комбинацию в b(2), далее — любую подходящую в b(3) и т.д. В данном примере _11 из b(2) противоречит 1_2 из b(1), но не противоречит 1_1. Перебор был похож на поиск в глубину, когда доходил до b(k), запоминал число взятых из B комбинаций, возвращался в b(k-1), брал другую комбинацию и снова в b(k). Концом поиска было, как и при горизонтальном росте, либо достижение k комбинаций, либо полный перебор. Затем аналогичный поиск начинался с b(2), затем с b(3) и так до конца. Притом очевидно, что если уже можно было вычеркнуть не меньше r комбинаций, то начинать поиск с b(k-r) не имеет смысла. Строку, соответствующую наибольшему числу взятых комбинаций, вставлял в список тестов, и по новой — искать следующую.
На оптимальность и быстроту сего поиска не претендую, но это было единственным, что я тогда придумал.
Еще одна немаловажная модификация — если в строку мы добавили не все комбинации из b(1)...b(k), то есть в каком-то из этих множеств не была найдена комбинация, не противоречащая предыдущим, то в строке обязательно образуются пустые места. Например, если нам не важно, что вставлять — строку 111 или 121, так как комбинации _11 и _21 уже покрыты, то мы можем вставить любое приемлемое значение, но лучше всего оставить пустое место. Почему? Когда все комбинации точно покрыты, мы возвращаемся на второй шаг или, если k = n — 1, выходим. Так вот в случае, если нам придется еще горизонтально расти, мы сможем воспользоваться этим пустым местом, вставив туда значение, которое позволит убрать какую-нибудь комбинацию со столбцом с пустующим местом.


Реализовав сей алгоритм, я был безмерно счастлив, так как работал он лучше и быстрее Jenny. Единственный, зато немаленький, минус IPO в том, что теоретически крайне сложно заранее точно определить количество полученных строк. То есть, он работает от заданной глубины, которую следует вычислять в зависимости от максимального числа тестов. В указанной мною статье дается примерная оценка размера тестовых наборов, равная наибольшему количеству вариантов ответа на вопрос в квадрате. Однако, она верна лишь в немногих случаях и только при m = 2, кроме того, в ней не учитывается количество вопросов, а ведь разброс реального размера слишком велик, чтобы мы могли ограничиться такой скудной оценкой. В случае m = 1 количество тестов совпадает с наибольшим количеством вариантов ответа, например A(k), а при m = n — A(1)*...*A(n). Потому этот вопрос для меня остается открытым.
Чтобы стало понятно о чем идет речь, представим, что нам необходимо протестировать какую-либо программу или сайт. Очень хорош пример с тестированием веб-формы, скажем, для регистрации или для поиска. Возникает вопрос, с какими ошибками в ней скорее всего встретится пользователь? Пускай у нас в форме имеется 6 вопросов, для каждого из которых возможны 10 вариантов ответа. Допустим, на страницу зашел целый миллион пользователей, и каждый из них ответил уникально. Теперь представим, что в форме для заполнения ответами скрывается ошибка. Если ошибка обнаруживается только при определенной комбинации ответов на все 6 вопросов, то на неё наткнется лишь один человек. Если же ошибка вылетает при наборе определенных ответов на какие-то 3 вопроса, то количество людей, обнаруживших ошибку возрастет до тысячи. Очевидно, что чем меньше элементов в комбинации, требуемой для ошибки, тем больше людей с ней встретится. Соответственно, перед нами теперь стоит задача: если мы не можем обнаружить все ошибки, то давайте хотя бы найдем самые критичные, то есть те, на которые наткнется больше всего пользователей.
Таким образом, мы должны сформировать тест-кейсы (и чем меньше, тем лучше), при переборе которых мы наткнемся на самые легкодоступные ошибки. Допустим, у нас имеется множество вопросов A, которое мы задаем количеством вариантов ответа на каждый из них: А = {2, 3, 5, 2, ...}. Пусть n — количество вопросов, а 1≤m≤n — степень критичности ошибок, она же степень покрытия или глубина покрывающего набора. Чем меньше значение m, тем критичнее ошибка. Задавая степень покрытия мы строим тестовый набор, который позволит обнаружить все ошибки, степень критичности которых меньше данного m. Если m = n, то поиск ошибок сводится к перебору всех вариантов. Чем меньше задаем степень, тем меньше тест-кейсов будет сформировано и тем меньше ошибок мы найдем.

Удобно представить покрывающий набор тестов в виде матрицы, где строчки соответствуют самому тесту, а столбцы — выбору ответов на вопросы. Для примера возьмем список вопросов A = {3, 3, 3, 3} и набор из одиннадцати тестов как на картинке справа. Такой набор отлично подходит для покрытия степени m = 2, так как при выборе любых двух столбцов в данном наборе между ними будут перебраны всевозможные комбинации.
Как минимизировать количество строчек? Первое, что пришло мне в голову, — это сформировать набор с глубиной покрытия n, то есть все варианты тестов, а затем жадно отбирать из него те, которые убирают наибольшее число еще не покрытых комбинаций из m элементов. Таким образом я пришел к чему-то похожему на жадный поиск покрытия множества. Решив, что так не очень интересно, а, возможно, окажется и не практично, я по этому пути не пошел.
Вероятно, многие из вас с этой задачей уже знакомы, мне же никогда еще не приходилось сталкиваться с подобной проблемой, а учитывая, что срок был дан неделя, пришлось серьезно напрячь извилины. Но учиться никогда не поздно. Три дня и три ночи я пытался придумать алгоритм, который будет работать наилучшим образом или хотя бы лучше, чем яндексовский Jenny. Не думайте, что я не обращался к поисковикам, я попросту не мог даже догадаться, какой запрос загуглить. После долгих мучений и различных переборов я все-таки каким-то чудесным образом из ниоткуда родил метод, который основывался на последовательном дополнении комбинаций при добавлении нового вопроса. Видимо, у меня все-таки немного программистский склад ума, поскольку мне не пришло в голову использовать какие-либо генетические алгоритмы, стохастические методы или что-нибудь подобное, зато явился небанальный, но все же жадный алгоритм.
Каким же было мое удивление, когда еще через несколько дней я узнал, что идея, которую я придумал и взял за основу, и схожая последовательность действий уже существуют, и называется соответствующий алгоритм In Parameter Order, иначе говоря, алгоритм, основанный на добавлении нового параметра. Более того, есть несколько неплохих статей и даже целая книга под названием «Обзор методов построения покрывающих наборов», которые рассматривают задачи такого рода.
Вот как можно классифицировать наиболее известные стратегии:

Как вы, наверное, догадались, алгоритм, о котором пойдет речь в моей статье — детерминированный параметризованный IPO с моими личными модификациями. На вход подается A и m, на выход — минимальное число тестов. Стратегия IPO делится на две последовательные части: горизонтальный и вертикальный рост. Сначала мы добавляем столбец, соответствующий новому вопросу, затем добавляются строки, соответствующие недостающим тестам.
Шаг первый.
Для начала мы берем первые m вопросов и перебираем между ними все комбинации. На выходе получится матрица из m столбцов и количеством строчек, равным A(1)*A(2)*...A(m). Так как в любом случае между этими m столбцами должны быть перебраны все комбинации, то меньшее количество строк мы никак получить не можем. В связи с этим для лучшего результата просто обязательно надо отсортировать вопросы по количеству вариантов в порядке убывания. Почему? Это станет понятно в дальнейшем.
Шаг второй. Горизонтальный рост
Пускай k — номер итерации + m — 1. То есть первоначальное k = m. Сейчас у нас есть покрытие глубины m для первых k столбцов. Добавляем следующий столбец k+1 следующим образом:
- Создаем множество B — множество всех неиспользованных комбинаций между столбцом k+1 и столбцами 1,..., k. Комбинации внутри этого множества следует классифицировать по столбцам, которым они соответствуют. Рассматриваем первую строку.
- Какой элемент нужно добавить в столбец k+1 в рассматриваемой строке? Как я уже говорил, мой алгоритм жадный, а потому добавляем тот, который вычеркнет из множества B как можно больше комбинаций. Делаем так: подставляем в строку первый вариант ответа и узнаем, сколько комбинаций из B можно вычеркнуть такой строкой. Если их число равняется k, то вариант подходит, если меньше — переходим к следующему. Тот вариант, который даст наибольшее число вычеркнутых из B комбинаций и выбираем. От себя бы добавил, что если несколько вариантов претендуют на оптимальный, то следует отдать предпочтение тому, который будет вычеркивать комбинации с теми столбцами, с которыми количество комбинаций, еще не покрытых, наибольшее. Тогда вероятность вычеркнуть больше комбинаций на следующих строках увеличится.
- Удаляем из B покрытые комбинации и переходим ко второму пункту, где рассматриваем следующую строку. Если же строк больше нет — выходим.
Теперь, если все комбинации покрыты, то переходим снова ко второму шагу, к новому горизонтальному росту, то есть добавляем новый вопрос/столбец. Если количество вопросов закончилось, алгоритм завершается.
Пример работы алгоритма для ситуации A = {2, 2, 2}, m = 2.
Большие цифры — набор тестов, маленькие — множество B aka непокрытые комбинации (слева — между первым и третьим столбцом, справа — между вторым и третьим). Сначала формируются первые два столбца, затем к ним добавляется третий. Для сравнения, даже для такого простого примера алгоритм Jenny построит на одну больше строк, чем IPO.
Однако может возникнуть ситуация посложнее, когда горизонтальным ростом не обойтись, и придется добавлять новые строки, чтобы покрыть оставшиеся комбинации.
Шаг третий. Вертикальный рост
Жадность в горизонтальном росте действительно дает отличные результаты, если отсортировать столбцы по количеству вариантов в порядке убывания. Если добавлять столбец с меньшим количеством вариантов, соответственно с меньшим числом комбинаций с другими столбцами, тем больше вероятность покрыть эти комбинации в горизонтальном росте и избежать вертикального или хотя бы его уменьшить.
Аналогичным образом работаем с вертикальным ростом — добавляем такую строку, которая уберет из B наибольшее количество комбинаций. Здесь искать их уже гораздо сложнее, так как меняется не один элемент, а целая строка, и это наиболее тяжкая часть алгоритма. Поэтому, как правило, этой части избегают и добавляют столько строк, сколько получится, зато за полиномиальное время. Насколько оправдан поиск локально наилучшей строки, точно сказать не могу, но на практике результаты дает хорошие.
Я поступал следующим образом: сортировал в порядке убывания мощности множества b(1), b(2), ..., b(k) — непересекающиеся подмножества B, в которые занесены по соответствующим столбцам непокрытые комбинации. Для ясности: если B = { _11, 1_1, 1_2}, то b(1) = {1_1, 1_2}, b(2) = {_11}. Такая упорядоченность сделана с целью приоритета множеств с наибольшим числом оставшихся комбинаций. Затем я брал первую комбинацию из b(1), далее — любую не противоречащую предыдущей комбинации комбинацию в b(2), далее — любую подходящую в b(3) и т.д. В данном примере _11 из b(2) противоречит 1_2 из b(1), но не противоречит 1_1. Перебор был похож на поиск в глубину, когда доходил до b(k), запоминал число взятых из B комбинаций, возвращался в b(k-1), брал другую комбинацию и снова в b(k). Концом поиска было, как и при горизонтальном росте, либо достижение k комбинаций, либо полный перебор. Затем аналогичный поиск начинался с b(2), затем с b(3) и так до конца. Притом очевидно, что если уже можно было вычеркнуть не меньше r комбинаций, то начинать поиск с b(k-r) не имеет смысла. Строку, соответствующую наибольшему числу взятых комбинаций, вставлял в список тестов, и по новой — искать следующую.
На оптимальность и быстроту сего поиска не претендую, но это было единственным, что я тогда придумал.
Еще одна немаловажная модификация — если в строку мы добавили не все комбинации из b(1)...b(k), то есть в каком-то из этих множеств не была найдена комбинация, не противоречащая предыдущим, то в строке обязательно образуются пустые места. Например, если нам не важно, что вставлять — строку 111 или 121, так как комбинации _11 и _21 уже покрыты, то мы можем вставить любое приемлемое значение, но лучше всего оставить пустое место. Почему? Когда все комбинации точно покрыты, мы возвращаемся на второй шаг или, если k = n — 1, выходим. Так вот в случае, если нам придется еще горизонтально расти, мы сможем воспользоваться этим пустым местом, вставив туда значение, которое позволит убрать какую-нибудь комбинацию со столбцом с пустующим местом.
Пример работы алгоритма для ситуации A = {3, 3, 3, 3}, m = 2.
Первая итерация. К сформированным первым двум столбцам, добавляется третий. Затем добавляются две строчки для покрытия оставшихся комбинаций _23 и _31
Вторая итерация. Добавляем четвертый столбец. Пустые места заполняем случайными числами.
Заключение
Реализовав сей алгоритм, я был безмерно счастлив, так как работал он лучше и быстрее Jenny. Единственный, зато немаленький, минус IPO в том, что теоретически крайне сложно заранее точно определить количество полученных строк. То есть, он работает от заданной глубины, которую следует вычислять в зависимости от максимального числа тестов. В указанной мною статье дается примерная оценка размера тестовых наборов, равная наибольшему количеству вариантов ответа на вопрос в квадрате. Однако, она верна лишь в немногих случаях и только при m = 2, кроме того, в ней не учитывается количество вопросов, а ведь разброс реального размера слишком велик, чтобы мы могли ограничиться такой скудной оценкой. В случае m = 1 количество тестов совпадает с наибольшим количеством вариантов ответа, например A(k), а при m = n — A(1)*...*A(n). Потому этот вопрос для меня остается открытым.
