

Содержание цикла статей про морфологию
• Морфология и компьютерная лингвистика для самых маленьких
• Роль морфологии в компьютерной лингвистике
• Морфология. Задачи и подходы к их решению
• Псевдолемматизация, композиты и прочие странные словечки
• Роль морфологии в компьютерной лингвистике
• Морфология. Задачи и подходы к их решению
• Псевдолемматизация, композиты и прочие странные словечки
В прошлой статье мы вплотную подошли к решению задачи лемматизации и выяснили, что, хотим мы этого или нет, но нам придется в том или ином виде хранить словарь со всеми словами описываемого языка.
Для русского языка это несколько сотен тысяч слов. Может быть, это не экономично, зато дает нам очень много бонусов.
Во-первых, мы можем проверить, есть ли слово в словаре. С помощью правил, основанных на регулярных выражениях, мы не выясним, есть слово «мымымымыться» в русском языке. Окончание вполне подчиняется правилам русского языка, повторение слогов – тоже не исключительный случай. Регулярное выражение это слово пропустит, но на самом деле никакого «мымымымыться» в русском языке не существует.
Другая задача, которую решает словарь, хранимый в морфологии, – это исправление ошибок. Как только мы не находим в словаре какого-то слова, зато обнаруживаем там другое слово на коротком расстоянии Левенштейна до искомого, мы принимаем решение об исправлении.
Для решения этих задач нам нужно хранить не только все слова, но и все их формы. Все правила образования форм для группы слов, похожих друг на друга, называются парадигмой словоизменения. Возьмем глагол «будлануть»: будланул, будланешь, будланет, будланул, будланула, будланули. Можно найти массу глаголов, которые будут изменяться по тем же правилам; с другой стороны, огромное количество глаголов будет изменяться по иным правилам. Значит, эти глаголы принадлежат разным парадигмам.
Для того чтобы мы могли отвечать на вопросы синтаксиса, с каждой формой мы храним еще и ее грамматическое значение.
Хранение словаря
Таким образом, словарь, хранимый в системе, решает массу задач, что не может не радовать. Но как же хранить этот словарь? В русском языке несколько сотен тысяч слов. В среднем на одно слово приходится 15 форм. Откуда мы берем это число? Рассмотрим падежи: их 6 для единственного числа и 6 для множественного – уже 12. И это не говоря о том, что в русском языке не 6 падежей, как учат в школе, а 8.
Во-первых, в предложном падеже прячется падеж, который называется локатив. Если мы поставим в предложный падеж слово «лес», у нас получится два варианта: «о лесе» и «в лесу». В лесу – это локативный падеж, а не предложный. Для многих существительных формы этих падежей совпадают, потому что мы не различаем «в столе», «о столе», и «на столе». Все потому, что локации «в столе» нет, а вот локация «в лесу» есть.
Восьмой падеж носит название партитив. Этот падеж показывает на часть от целого. Если у нас закончился чай, вставать лень, а рядом ходит кто-то незанятый, мы ему говорим: «Налей мне, пожалуйста, чаю». Как правило, форма слов в партитиве совпадает с родительным или винительным падежом. Википедия приводит нам прекрасный пример слова, которое не имеет никаких других форм, кроме партитива множественного числа – «щец» («Щец не желаете?»; «Налей-ка мне щец!»)
 Итого, 8 падежей умножить на 2 формы (единственное и множественное число) — уже 16. У глаголов же есть время, число и род. Путем нехитрых арифметических вычислений получаем, что 15 форм – довольно скромная оценка снизу.
Итого, 8 падежей умножить на 2 формы (единственное и множественное число) — уже 16. У глаголов же есть время, число и род. Путем нехитрых арифметических вычислений получаем, что 15 форм – довольно скромная оценка снизу.Среднее эмпирическое число символов в русском слове – 9. Умножаем полученные результаты, не забывая учесть, что на 1 символ приходится 2 байта, и выясняется, что для словаря всех форм русского языка необходимо 50 мегабайт. На практике же наши идеальные 50 мегабайт увеличиваются еще в полтора раза: в итоге текстовый файл со всеми формами слов русского языка занимает более 75 мегабайт.
Кроме того, даже если мы запишем все эти слова в файл, нам необходимо будет проводить по нему поиск (иначе зачем он нужен?). То есть мы должны упорядочить слова по алфавиту и дополнительно к каждому слову добавить указатель на начальную форму слова. Указатели, хоть и не тяжелые по одному, все же ощутимо добавят веса нашему словарю. При этом скорость поиска составит

И это только на русский язык, а еще есть английский, французский, испанский, итальянский и масса других прекрасных и богатых языков. Если мы хотим, чтобы, например, FineReader распознавал и поддерживал много языков, нам одних морфологических словарей нужно будет уместить в него на гигабайт. Что говорить об эталонах для распознавания и других dll'ках? Пользователь нас с такой тяжеловесной технологией не поймет — и будет прав. Надо быть скромнее и хранить оптимальнее.
Префиксное дерево
Нам на помощь приходит префиксное дерево. Как оно устроено? Все начинается с вершины – пустого символа, в котором хранится алфавит. Для первой буквы там хранится весь алфавит, точнее, массив из 33 указателей. Каждый указатель соответствует своему символу. Первый указатель – символу А, второй – символу Б, некий К-тый указатель – символу К и некий П-тый – символу П. По указателям мы можем получить следующие узлы этого дерева, которые соответствуют буквам русского алфавита.
В следующих узлах снова хранятся массивы. Причем для быстроты поиска мы пренебрегаем тем, что букв, на которые нам нужны указатели, будет уже меньше 33 (вряд ли нам потребуется сочетание «аы», например). Мы оставляем размерность массива неизменной, вставляя для отсутствующих символов нулевые указатели.
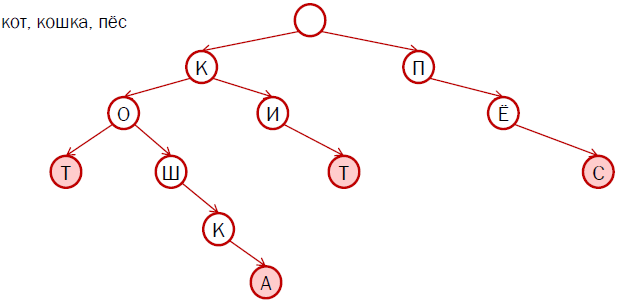
На рисунке изображен пример префиксного дерева для четырех слов: «кот», «кошка», «кит» и «пес». Розовым закрашены финальные вершины.
Преимущество такого подхода в том, что мы не храним огромные цепочки повторяющихся символов для одного и того же слова, стоящего в разных формах. Таким образом, мы уменьшаем размер файла со словарем. К примеру, для русского языка это дерево вместе с дополнительными данными занимает порядка 2 мегабайт. Во-первых, по сравнению с 75 мегабайтами это, безусловно, успех. Во-вторых, скорость поиска по такому дереву значительно выше, чем по отсортированному файлу. Теперь она зависит не от размера всего словаря, а только от того, что мы ищем. Если мы ищем союз «а», мы найдем его за один шаг, а если мы ищем длинное слово, например, «вертолетостроительный», поискать придется немножко подольше.
Разумеется, если мы поместим в дерево все формы всех слов без грамматических значений, то ни о какой компьютерной лингвистике мы говорить не сможем: мы не сможем подняться на уровень синтаксиса, не говоря уже о семантике, а без них невозможен автоматический перевод. Следовательно, над структурой данных надо еще поработать.
Что хранить в словаре
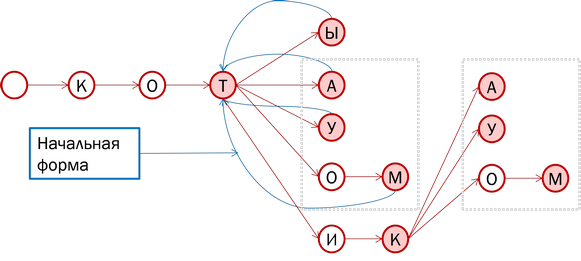
Теоретически мы действительно можем хранить все формы слов в дереве, сохраняя при этом указатели на начальную форму (синие линии на рисунке). Однако обратите внимание: несмотря на то что «кот» и «котик» относятся к разным словообразовательным парадигмам, часть флексий (так мы называем окончания) у них совпадают. Что если эти хвосты слов хранить отдельно, а в дереве оставить начальные формы котов, котиков и китов? Так будет эффективнее.
Основательный подход
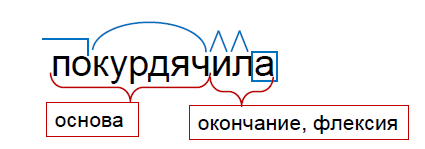
В школе слово делят на составные части следующим образом: приставка, корень, несколько суффиксов и окончание. Мы пойдем другим путем. Во-первых, мы не будем отделять приставку от корня. Это связано с тем, что часто приставка вместе с корнем образуют совершенно новый смысл. Возьмем для примера слова «приставка» и «ставка». «При-» – это всего лишь приставка у слова «ставка», но «приставка» и «ставка» – это совершенно разные вещи.
Кроме того, приставка не выражает никакой грамматической категории. Когда мы добавляем приставку «пере-» («переделать» или «перекурдячить»), мы меняем лексический смысл слова, а не грамматический. Поэтому приставку и корень мы рассматриваем как единое целое и называем это основой слова.
Еще одно отличие от школы: мы практически никогда не отделяем суффиксы от окончаний, так как в большинстве случаев они выражают грамматическую категорию. В нашем примере «-л-» и «-а-» выражают прошедшее время, женский род, и мы объединяем их в флексию. При таком делении мы получаем изменяемую часть слова – флексию и неизменяемую – основу.
Удобные допущения

Вы уже, наверное, привыкли к тому, что в компьютерной лингвистике ничего просто так не бывает. Вот и здесь: в разных формах слова может меняться даже часть корня. Можно, конечно, нудно рассуждать о том, что это всего лишь изменяемая согласная в корне «дру-г» и «дру-зь», но для решения практических задач нам удобнее принять, что у этих слов одинаковая основа «дру-», а флексии разные.
Итак, мы определили, что лексемы (основы слов) и флексии будут храниться отдельно. Наконец мы подходим вплотную к тому, как решает задачи лемматизации наш морфологический модуль в ABBYY.
Окончательная лемматизация
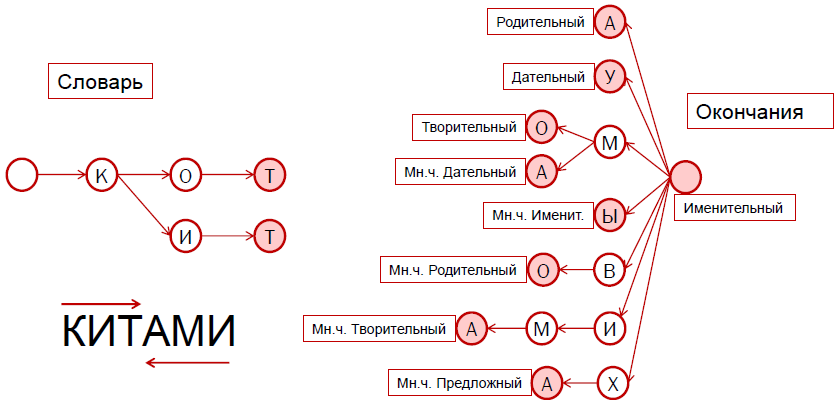
На рисунке слева в виде уже знакомого вам префиксного дерева изображена одна стотысячная часть словаря русского языка. Справа — словарь окончаний, который хранится таким же образом.
Если внимательно посмотреть на окончания, можно заметить, что их можно приписать как к «коту», так и к «киту». Если мы добавим «а», получим родительный падеж, если «у», – дательный и так далее. Всё это – разные формы двух слов, которые принадлежат одной и той же парадигме, и поэтому одинаково меняются.
Разбор китов
Когда мы получаем форму слова, мы начинаем её анализировать не сначала, а с конца. Сначала мы предполагаем, что есть нулевое окончание, которое помечено розовым цветом и показывает, что перед нами именительный падеж, единственное число. Затем мы идём по данному нам слову «китами» и встречаем букву «и». Мы находим букву «и» в префиксном дереве. Следующая буква — «м». Эти буквы не являются последними, поэтому мы продолжаем двигаться вглубь дерева. Следующая буква «а», которая помечена розовым, конечный узел в дереве. Значит, «-ами» слева направо, или «-има» справа налево — это один из вариантов окончания, которым может заканчиваться слово.
Итак, мы нашли два окончания: пустое и «-ами». Теперь нам нужно искать основу в префиксном дереве словаря. Этот поиск осуществляется уже слева направо. Мы последовательно находим буквы «к», «и» и «т», и на букве «т» дерево заканчивается. То есть «кит» — это одно из слов, хранящихся в этом дереве. Если мы попробуем искать дальше, то увидим, что следующая буква «а», но указателей на следующую вершину нет, значит, мы прекращаем поиск.
Мы видим, что три буквы слева и три буквы справа срослись в слово, а вот пустое окончание нам не пригодилось. Мы принимаем решение, что «китами» — это форма множественного числа, творительного падежа, лексемы с начальной формой «кит».
Об ещё не освещённых задачах, решаемых подсистемой морфологии, читайте в следующем посте.
