Данный пост является переводом и предназначен для новичков. Ну или для тех, кто забыл лекции с начальных курсов своих вузов. Скорее всего, данный материал уже попадался на хабре в той или иной модификации, но здесь упор на PHP и его особенности.
Структуры данных или Абстрактный Тип Данных (ADT) — это модель, определенная как некий набор операций, которые могут быть применены к самой себе и ограничена тем, какой результат дают эти операции.
Большинство из нас сталкиваются со стеком и очередью в повседневной жизни, но что общего между очередью в супермакете и структурой данных? В этом мы и попробуем разобраться в данной статье, где также будут описаны деревья.

UPD: s01e02
Стек, обычно, описывают как некий набор объектов, который сгруппирован вместе, где каждый элемент общего набора идет друг за другом — стопка книг или же подносы, сложенные между собой. В информатике же, стек — это набор объектов, имеющий общее правило образования: последний объект, помещенный в стек, извлекается первым из общего списка. Такое правило еще называют «Последний вошел, первый вышел» или LIFO. Есть и обратное правило — первый вошел, первый вышел (FIFO), но об этом чуть позже.
Данное правило, LIFO, используется, например, в автоматах по продаже сигарет, конфет — последний загруженный туда объект будет выдан первым.
Абстрактное определение стека — список, все операции для которого определены относительно одного конца, т.е. вершина стека.
Базовые операции, определяющие стек:
Также можно определить стек с максимально возможным количеством элементов, но это уже мелочи. Однако когда стек больше не может принимать элементы, то стек является переполненным и он возвращает сообщение об этом (stack overflow). Ну и обратная ситуация — изъятие элемента из пустого стека (stack underflow).
Зная то, что наш стек определен как LIFO и его базовые операции, мы можем написать наш стек через массив, тем более что мы уже имеем для это базовые операции push и pop. Наш пример будет таким:
В этом примере мы использовали функции PHP array_unshift() и array_shift() вместо array_push() and array_pop(), поэтому у нас первый элемент стека всегда будет сверху, иначе у нас вершиной был бы n-ый элемент стека. Особой разницы нет. Теперь добавим несколько элементов в наш стек:
А теперь извлечем несколько элементов из него:
Что у нас теперь является вершиной стека?
Если снова вызвать метод pop(), то «A Feast for Crows» будет удален из стека. Если же сделать push, а затем сразу pop, то стек не изменится, поскольку наш стек работает на основе «последний зашел, первый вышел». Если продолжать вытаскивать элементы из стека, то рано или поздно мы получим исключение с сообщением о том, что стек пуст.
PHP (Расширение SPL) предоставляет нам реализации разных структур данных, включая SplStack, начиная с версии 5.3. Мы можем создать наш ReadingList просто унаследовав его:
SplStack дает нам чуть больше методов, чем мы определили ранее, потому как SplStack реализует двусвязный список, у которого есть емкость (количество элементов в стеке) для реализации перебора.
Связанный список, являющийся по сути другой абстрактной структурой, это список из узлов, каждый из которых имеет указатель на следующий объект. Данную структуру можно представить таким образом, с однонаправленным перебором:

В двусвязном же списке, каждый узел имеет два указателя — на предыдущий и следующий узлы в списке. Такая структура позволяет производить перебор в двух направлениях:

Перебирая элементы, мы должны знать где у нас заканчивается весь список — для этого служат те самые элементы, перечеркнутые внутри.
Вот мы и подошли к «первый вошел, первый вышел» или же FIFO. Любой, кто стоял в реальной очереди — знает, что тот, кто занял место первым, первым из нее и уйдет.Исключение — объекты, которым только подписать, спросить, etc.
Базовые операции для очередей такие:
P.S Для тех кто знаком с Прологом — в данном случае хвост не содержит в себе все элементы списка, за исключением головы.
PHP также предоставляет нам класс SplQueue (двусвязный список), только в данном случае голова списка — последний элемент. Определим наш ReadingList как очередь:
SplQueue наследуется от SplDoublyLinkedList и реализует интерфейс доступа как к массиву, таким образом позволяя обращаться к нашим очередям и стекам через массивы:
Удалим пару элементов из очереди:
enqueue() это псевдонимом для push(), однако dequeue() не является псевдонимом для pop()! У pop() другое поведение в контексте очереди, так как если мы воспользуемся pop(), то это удалит элемент из хвоста очереди (A Dance with Dragons), поскольку в очереди главным является правило FIFO.
Посмотреть (не удаляя) какой элемент является головой списка можно через метод bottom():
Управление ADT обычно сводится к 3 операциям: вставка элементов в вструктуру, удаление и получение значения элемента из структуры. В отношении стека и очередей, данные операции зависимы от позиции (xIFO). Но что если нам нужно получить информацию по значению?
Представим, что у нас есть такая табличка (порядок элементов значения не имеет):
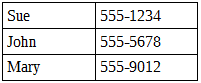
Очевидно, что стек или очередь нам не помогут в данном случае, поскольку придется обойти все значения, если нужное нам находится в конце или отсутствует вообще. Предположим, что нужный элемент есть в списке. Тогда для его поиска нам придется пройтись, в среднем, по n/2 элементам, где n — длина всего списка. Больше список — больше занимаемого времени на обход. Для решения данной проблемы поиска нужно как-то расположить данные так, чтобы поиск по структуре упростился. И вот здесь появляются деревья.
Абстрактный пример данной структуры — таблица со следующими операциями:
Да, это похоже на всем известный CRUD (Создание чтение обновление удаление) из баз данных, потому что деревья и базы данных тесно связаны между собой.
Один из путей представления нашей таблицы — линейно, т.е. описать её построчно. Такая запись может быть сортирована, быть последовательной (т.е. записи с ограниченной длиной или разной длиной, с разделителями) или связанной (используя указатели на данные). Такое представление имели ранние базы данных и файловые системы (FAT, например). Однако у последовательной записи есть минус — она плоха для вставок и удаления данных, в то время как связанная позволяет динамически выделять место под новые данные. Также, последовательная запись с фиксированной длиной менее эффективна, чем связанная. Поэтому для бинарного дерева поиска лучше выбрать связанную запись.
Деревья как раз и есть реализация нелинейного поиска, они дают более эффективные возможности двух типов — последовательной и связанной, поддерживают все табличные операции. Поэтому многие современные базы данных используют именно деревья (MyISAM использует деревья для индексов).
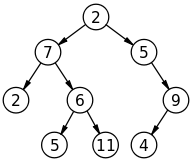
Как видно из этой картинки — деревья это иерархическая структура, где между узлами есть связь родитель → потомок. Узел без потомков — концевой узел (лист), потомок без родителя — корень дерева, связи между узлами — ребра. Узел с двумя потомками — простейшее дерево и основываясь на этом, мы можем представить дерево в виде рекурсивного списка таких узлов. Стоит отметить, что дерево по своей структуре напоминает двусвязный список.
Поэтому наше дерево можно описать следующим образом:
Вставка новых значений уже куда более интересная тема. Есть несколько решений данной проблемы, основанных на вращении и балансировки дерева, и для разных задач можно использовать разные реализации деревьев, такие как красное-черное, АВЛ или Б деревья, имеющие разные показатели производительности в операциях вставки, удаления и обхода дерева.
Для простоты обозначим некоторые правила простейшей реализации: все, что меньше текущего значения — идет влево, больше — вправо.
Повторы будут исключены:
Удаление узлов — совсем другая история и затрагиваться не будет. Возможно, как-нибудь в другой раз.
Вспомним как мы начинали с корня и проходили дерево, узел за узлом, чтобы найти пустой узел. Есть 4 главных стратегии обхода дерева:
Первые три стратегии известны как обход в глубину, который начинается с корня дерева (ну или узла, обозначенного как узел) и проход максимально глубоко по дереву, как это возможно, перед тем как вернуться обратно. Каждая из этих стратегий используется в разных целях. Прямой порядок, например, используется при вставке новых узлов (наш случай) или копировании поддерева, обратный — наоборот, при удалении узлов из дерева.
Чтобы понять как работает симметричный проход нужно немного изменить наш пример:
Благодарю всех дочитавших до заключения, еще немного текста и картинки :)
Стоит отметить, что реализации SplStack, SplQueue и двусвязного списка не освещены полностью. В документации PHP по ним спрятано довольно много методов, в том числе подсчет количества элементов или использование структуры в качестве итератора.
Также стоит обратить внимание на данную статью от kpuzuc
Визуализацию этих структур, ссылки на которые можно найти в посте от tangro
Бенчмарки производительности реализаций данных структур скопипастил отсюда
Что касается очереди, то выбор в пользу SPL довольно очевиден. Реализация стека не особо выигрывает у массива, а двусвязный список так и вовсе проигрывает массивам по количеству операций в секунду. Я, если честно, не вникал в тесты и самому хотелось бы узнать с чем это связано, но скорее всего с тем, что слишком много тянется из «смежных» интерфейсов, поправьте, если ошибаюсь.
P.S. Как всегда в личку принимаются ошибки в тексте и переводе оригинала.
Структуры данных или Абстрактный Тип Данных (ADT) — это модель, определенная как некий набор операций, которые могут быть применены к самой себе и ограничена тем, какой результат дают эти операции.
Большинство из нас сталкиваются со стеком и очередью в повседневной жизни, но что общего между очередью в супермакете и структурой данных? В этом мы и попробуем разобраться в данной статье, где также будут описаны деревья.

UPD: s01e02
Стек
Стек, обычно, описывают как некий набор объектов, который сгруппирован вместе, где каждый элемент общего набора идет друг за другом — стопка книг или же подносы, сложенные между собой. В информатике же, стек — это набор объектов, имеющий общее правило образования: последний объект, помещенный в стек, извлекается первым из общего списка. Такое правило еще называют «Последний вошел, первый вышел» или LIFO. Есть и обратное правило — первый вошел, первый вышел (FIFO), но об этом чуть позже.
Данное правило, LIFO, используется, например, в автоматах по продаже сигарет, конфет — последний загруженный туда объект будет выдан первым.
Абстрактное определение стека — список, все операции для которого определены относительно одного конца, т.е. вершина стека.
Базовые операции, определяющие стек:
- init – создать стек.
- push – добавить элемент в начало (верх) стека, сдвинув остальные на 1 позицию вниз.
- pop – извлечь (и удалить) элемент из стека (из вершины).
- top – получить значение на первый элемент стека (не удаляя).
- isEmpty – проверка стека на пустоту.
Также можно определить стек с максимально возможным количеством элементов, но это уже мелочи. Однако когда стек больше не может принимать элементы, то стек является переполненным и он возвращает сообщение об этом (stack overflow). Ну и обратная ситуация — изъятие элемента из пустого стека (stack underflow).
Зная то, что наш стек определен как LIFO и его базовые операции, мы можем написать наш стек через массив, тем более что мы уже имеем для это базовые операции push и pop. Наш пример будет таким:
<?php
class ReadingList
{
protected $stack;
protected $limit;
public function __construct($limit = 10) {
// инициализация стека
$this->stack = array();
// устанавливаем ограничение на количество элементов в стеке
$this->limit = $limit;
}
public function push($item) {
// проверяем, не полон ли наш стек
if (count($this->stack) < $this->limit) {
// добавляем новый элемент в начало массива
array_unshift($this->stack, $item);
} else {
throw new RunTimeException('Стек переполнен!');
}
}
public function pop() {
if ($this->isEmpty()) {
// проверка на пустоту стека
throw new RunTimeException('Стек пуст!');
} else {
// Извлекаем первый элемент массива
return array_shift($this->stack);
}
}
public function top() {
return current($this->stack);
}
public function isEmpty() {
return empty($this->stack);
}
}
В этом примере мы использовали функции PHP array_unshift() и array_shift() вместо array_push() and array_pop(), поэтому у нас первый элемент стека всегда будет сверху, иначе у нас вершиной был бы n-ый элемент стека. Особой разницы нет. Теперь добавим несколько элементов в наш стек:
<?php
$myBooks = new ReadingList();
$myBooks->push('A Dream of Spring');
$myBooks->push('The Winds of Winter');
$myBooks->push('A Dance with Dragons');
$myBooks->push('A Feast for Crows');
$myBooks->push('A Storm of Swords');
$myBooks->push('A Clash of Kings');
$myBooks->push('A Game of Thrones');
А теперь извлечем несколько элементов из него:
<?php
echo $myBooks->pop(); // Получили и удалили 'A Game of Thrones'
echo $myBooks->pop(); // Получили и удалили 'A Clash of Kings'
echo $myBooks->pop(); // Получили и удалили 'A Storm of Swords'
Что у нас теперь является вершиной стека?
<?php
echo $myBooks->top(); // Получили 'A Feast for Crows'
Если снова вызвать метод pop(), то «A Feast for Crows» будет удален из стека. Если же сделать push, а затем сразу pop, то стек не изменится, поскольку наш стек работает на основе «последний зашел, первый вышел». Если продолжать вытаскивать элементы из стека, то рано или поздно мы получим исключение с сообщением о том, что стек пуст.
SPLStack
PHP (Расширение SPL) предоставляет нам реализации разных структур данных, включая SplStack, начиная с версии 5.3. Мы можем создать наш ReadingList просто унаследовав его:
<?php
class ReadingList extends SplStack
{
}
SplStack дает нам чуть больше методов, чем мы определили ранее, потому как SplStack реализует двусвязный список, у которого есть емкость (количество элементов в стеке) для реализации перебора.
Связанный список, являющийся по сути другой абстрактной структурой, это список из узлов, каждый из которых имеет указатель на следующий объект. Данную структуру можно представить таким образом, с однонаправленным перебором:

В двусвязном же списке, каждый узел имеет два указателя — на предыдущий и следующий узлы в списке. Такая структура позволяет производить перебор в двух направлениях:

Перебирая элементы, мы должны знать где у нас заканчивается весь список — для этого служат те самые элементы, перечеркнутые внутри.
Очередь
Вот мы и подошли к «первый вошел, первый вышел» или же FIFO. Любой, кто стоял в реальной очереди — знает, что тот, кто занял место первым, первым из нее и уйдет.
Базовые операции для очередей такие:
- init – создать очередь.
- enqueue – добавить элемент в конец (хвост) очереди.
- dequeue – удалить элемент из начала очереди (голова).
- isEmpty – проверка очереди на пустоту.
P.S Для тех кто знаком с Прологом — в данном случае хвост не содержит в себе все элементы списка, за исключением головы.
PHP также предоставляет нам класс SplQueue (двусвязный список), только в данном случае голова списка — последний элемент. Определим наш ReadingList как очередь:
<?php
class ReadingList extends SplQueue
{
}
$myBooks = new ReadingList();
// добавим несколько элементов в нашу очередь
$myBooks->enqueue('A Game of Thrones');
$myBooks->enqueue('A Clash of Kings');
$myBooks->enqueue('A Storm of Swords');
SplQueue наследуется от SplDoublyLinkedList и реализует интерфейс доступа как к массиву, таким образом позволяя обращаться к нашим очередям и стекам через массивы:
<?php
$myBooks[] = 'A Feast of Crows';
$myBooks[] = 'A Dance with Dragons';
Удалим пару элементов из очереди:
<?php
echo $myBooks->dequeue() . "\n"; // Выводит и удаляет 'A Game of Thrones'
echo $myBooks->dequeue() . "\n"; // Выводит и удаляет 'A Clash of Kings'
enqueue() это псевдонимом для push(), однако dequeue() не является псевдонимом для pop()! У pop() другое поведение в контексте очереди, так как если мы воспользуемся pop(), то это удалит элемент из хвоста очереди (A Dance with Dragons), поскольку в очереди главным является правило FIFO.
Посмотреть (не удаляя) какой элемент является головой списка можно через метод bottom():
<?php
echo $myBooks->bottom() . "\n"; // Выводит 'A Storm of Swords'
Деревья
Управление ADT обычно сводится к 3 операциям: вставка элементов в вструктуру, удаление и получение значения элемента из структуры. В отношении стека и очередей, данные операции зависимы от позиции (xIFO). Но что если нам нужно получить информацию по значению?
Представим, что у нас есть такая табличка (порядок элементов значения не имеет):
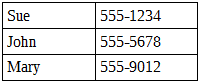
Очевидно, что стек или очередь нам не помогут в данном случае, поскольку придется обойти все значения, если нужное нам находится в конце или отсутствует вообще. Предположим, что нужный элемент есть в списке. Тогда для его поиска нам придется пройтись, в среднем, по n/2 элементам, где n — длина всего списка. Больше список — больше занимаемого времени на обход. Для решения данной проблемы поиска нужно как-то расположить данные так, чтобы поиск по структуре упростился. И вот здесь появляются деревья.
Абстрактный пример данной структуры — таблица со следующими операциями:
- create – создать пустую таблицу.
- insert – добавить элемент в таблицу.
- delete – удалить элемент из таблицы.
- retrieve – найти элемент в таблице.
Да, это похоже на всем известный CRUD (Создание чтение обновление удаление) из баз данных, потому что деревья и базы данных тесно связаны между собой.
Один из путей представления нашей таблицы — линейно, т.е. описать её построчно. Такая запись может быть сортирована, быть последовательной (т.е. записи с ограниченной длиной или разной длиной, с разделителями) или связанной (используя указатели на данные). Такое представление имели ранние базы данных и файловые системы (FAT, например). Однако у последовательной записи есть минус — она плоха для вставок и удаления данных, в то время как связанная позволяет динамически выделять место под новые данные. Также, последовательная запись с фиксированной длиной менее эффективна, чем связанная. Поэтому для бинарного дерева поиска лучше выбрать связанную запись.
Деревья как раз и есть реализация нелинейного поиска, они дают более эффективные возможности двух типов — последовательной и связанной, поддерживают все табличные операции. Поэтому многие современные базы данных используют именно деревья (MyISAM использует деревья для индексов).

Как видно из этой картинки — деревья это иерархическая структура, где между узлами есть связь родитель → потомок. Узел без потомков — концевой узел (лист), потомок без родителя — корень дерева, связи между узлами — ребра. Узел с двумя потомками — простейшее дерево и основываясь на этом, мы можем представить дерево в виде рекурсивного списка таких узлов. Стоит отметить, что дерево по своей структуре напоминает двусвязный список.
Поэтому наше дерево можно описать следующим образом:
<?php
class BinaryNode
{
public $value; // значение узла
public $left; // левый потомок типа BinaryNode
public $right; // правый потомок типа BinaryNode
public function __construct($item) {
$this->value = $item;
// новые потомки - вершина
$this->left = null;
$this->right = null;
}
}
class BinaryTree
{
protected $root; // корень дерева
public function __construct() {
$this->root = null;
}
public function isEmpty() {
return $this->root === null;
}
}
Вставка новых значений
Вставка новых значений уже куда более интересная тема. Есть несколько решений данной проблемы, основанных на вращении и балансировки дерева, и для разных задач можно использовать разные реализации деревьев, такие как красное-черное, АВЛ или Б деревья, имеющие разные показатели производительности в операциях вставки, удаления и обхода дерева.
Для простоты обозначим некоторые правила простейшей реализации: все, что меньше текущего значения — идет влево, больше — вправо.
Повторы будут исключены:
- Если дерево пустое — вставим [новый_узел] как корень дерева (очевидно же!)
- пока (дерево не пустое):
- 2a. Если ([текущий узел] пуст) — вставить сюда и остановиться;
- 2b. Если ([новый_узел] > [текущий узел]) — пробуем вставить [новый_узел] справа и повторим шаг 2
- 2c. Если ([новый_узел] < [текущий узел]) — пробуем вставить [новый_узел] слева и повторим шаг 2
- 2d. Иначе значение уже в дереве
<?php
class BinaryTree
{
...
public function insert($item) {
$node = new BinaryNode($item);
if ($this->isEmpty()) {
// правило 1
$this->root = $node;
}
else {
// правило 1
$this->insertNode($node, $this->root);
}
}
protected function insertNode($node, &$subtree) {
if ($subtree === null) {
// правило 2
$subtree = $node;
}
else {
if ($node->value > $subtree->value) {
// правило 2b
$this->insertNode($node, $subtree->right);
}
else if ($node->value < $subtree->value) {
// правило 2c
$this->insertNode($node, $subtree->left);
}
else {
// исключаем повторы, правило 2d
}
}
}
}
Удаление узлов — совсем другая история и затрагиваться не будет. Возможно, как-нибудь в другой раз.
Обход дерева
Вспомним как мы начинали с корня и проходили дерево, узел за узлом, чтобы найти пустой узел. Есть 4 главных стратегии обхода дерева:
- pre-order (прямой порядок)– обработка текущего узла, а затем переход к левому и правому.
- in-order (симметричная) – сначала проход левой стороны, обработка текущего узла и обход правой стороны.
- post-order (обратный порядок) – обход левой и правой стороны, затем обработка текущего значения.
- level-order (в ширину) – обработка текущего значения, затем обработка потомков и переход на следующий уровень.
Первые три стратегии известны как обход в глубину, который начинается с корня дерева (ну или узла, обозначенного как узел) и проход максимально глубоко по дереву, как это возможно, перед тем как вернуться обратно. Каждая из этих стратегий используется в разных целях. Прямой порядок, например, используется при вставке новых узлов (наш случай) или копировании поддерева, обратный — наоборот, при удалении узлов из дерева.
Чтобы понять как работает симметричный проход нужно немного изменить наш пример:
<?php
class BinaryNode
{
...
// сделаем симметричный проход текущего узла
public function dump() {
if ($this->left !== null) {
$this->left->dump();
}
var_dump($this->value);
if ($this->right !== null) {
$this->right->dump();
}
}
}
class BinaryTree
{
...
public function traverse() {
// отображение дерева в возрастающем порядке от корня
$this->root->dump();
}
}
Заключение
Благодарю всех дочитавших до заключения, еще немного текста и картинки :)
Стоит отметить, что реализации SplStack, SplQueue и двусвязного списка не освещены полностью. В документации PHP по ним спрятано довольно много методов, в том числе подсчет количества элементов или использование структуры в качестве итератора.
Также стоит обратить внимание на данную статью от kpuzuc
Визуализацию этих структур, ссылки на которые можно найти в посте от tangro
Бенчмарки производительности реализаций данных структур скопипастил отсюда
взглянуть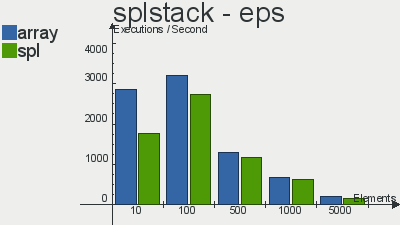
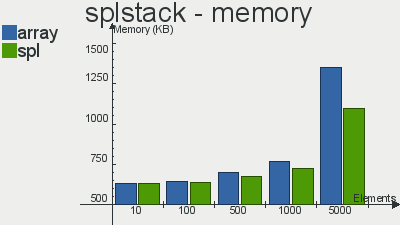
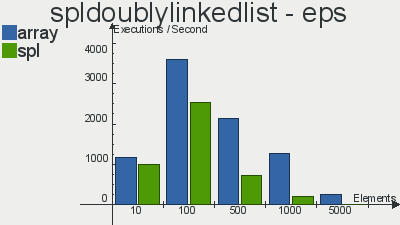
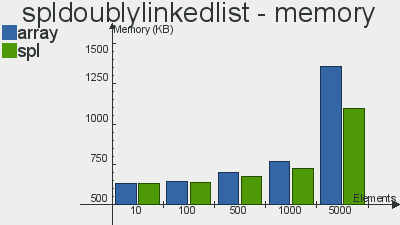
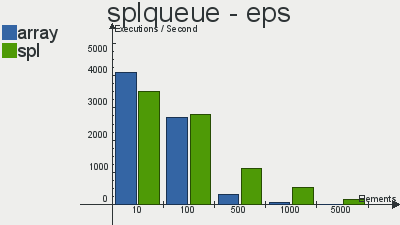
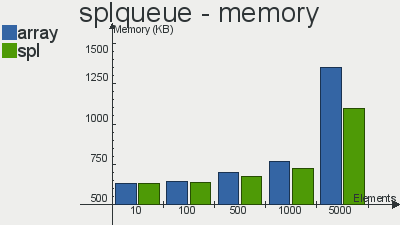
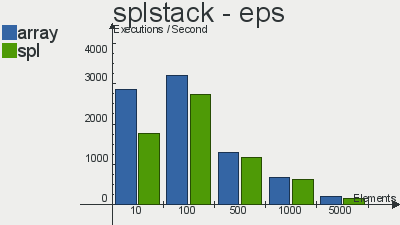
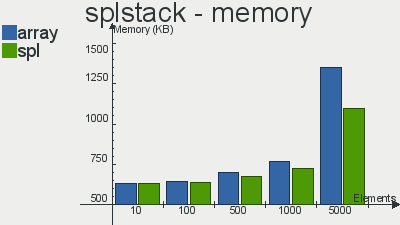
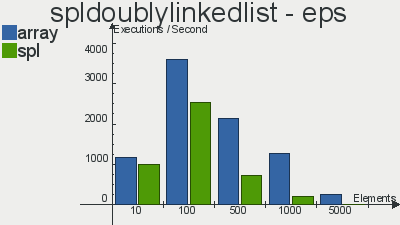
Что касается очереди, то выбор в пользу SPL довольно очевиден. Реализация стека не особо выигрывает у массива, а двусвязный список так и вовсе проигрывает массивам по количеству операций в секунду. Я, если честно, не вникал в тесты и самому хотелось бы узнать с чем это связано, но скорее всего с тем, что слишком много тянется из «смежных» интерфейсов, поправьте, если ошибаюсь.
P.S. Как всегда в личку принимаются ошибки в тексте и переводе оригинала.
Only registered users can participate in poll. Log in, please.
Продолжать перевод оригинала?
89.97% Да538
10.03% Нет60
598 users voted. 82 users abstained.
