От переводчика: данный текст даётся с незначительными сокращениями по причине местами излишней «разжёванности» материала. Автор абсолютно справедливо предупреждает, что отдельные темы могут показаться читателю чересчур простыми или общеизвестными. Тем не менее, лично мне этот текст помог упорядочить имеющиеся знания по анализу сложности алгоритмов. Надеюсь, что он окажется полезен и кому-то ещё.
Из-за большого объёма оригинальной статьи я разбила её на части, которых в общей сложности будет четыре.
Я (как всегда) буду крайне признательна за любые замечания в личку по улучшению качества перевода.
Опубликовано ранее:
Часть 1
Часть 2
Часть 3
Поздравляю! Теперь вы знаете о том, как анализировать сложность алгоритмов, что такое асимптотическая оценка и нотация «большое-О». Вы также в курсе, как интуитивно выяснить является ли сложностью алгоритма
Этот финальный раздел — опциональный. Он несколько сложнее, так что можете не стесняясь пропустить его, если хотите.От вас потребуется сфокусироваться и потратить некоторое время на решение упражнений. Однако, так же здесь будет продемонстрирован очень полезный и мощный способ анализа сложности алгоритмов, что, безусловно, стоит внимания.
Мы рассматривали реализацию сортировки, называемую сортировкой выбором, и упоминали, что она не является оптимальной. Оптимальный алгоритм — это тот, который решает задачу наилучшим образом, подразумевая, что не существует алгоритма, делающего это лучше. Т.е. все прочие алгоритмы для решения данной проблемы имеют такую же или большую сложность. Может существовать масса оптимальных алгоритмов, имеющих одинаковую сложность. Та же проблема сортировки может быть решена оптимально многими способами. Например, мы можем использовать для быстрой сортировки ту же идею, что и при бинарном поиске. Такой способ называется сортировкой слиянием.
Прежде, чем реализовать собственно сортировку слиянием, нам надо написать вспомогательную функцию. Назовём её
Функция
Анализ этого алгоритма показывает, что его время выполнения —
Используя эту функцию, мы можем построить лучший алгоритм сортировки. Идея следующая: мы разбиваем массив на две части, рекурсивно сортируем каждую из них и объединяем два отсортированных массива в один. Псевдокод:
Эта функция сложнее предыдущих для понимания, поэтому выполнение следующего упражнения может потребовать у вас больше времени.
В качестве финального упражнения давайте проанализируем сложность
Итак, мы разбили оригинальный массив на две части, размером
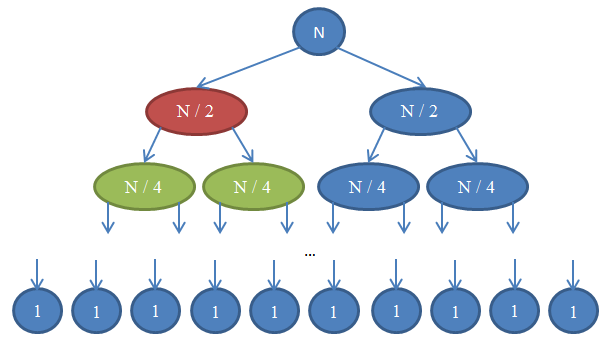
Давайте посмотрим, что здесь происходит. Каждый кружок представляет собой вызов функции
Заметьте, что количество элементов в каждой строке остаётся равным
В результате сложностью каждой строки является
Как вы видели в последнем примере, анализ сложности позволяет нам сравнивать алгоритмы, чтобы понять, который из них лучше. Исходя из этих соображений, теперь мы можем быть уверены, что для массивов больших размеров сортировка слиянием намного опередит сортировку выбором. Такое заключение было бы проблематично сделать, если бы мы не имели теоретического базиса анализа разработанных нами алгоритмов. Несомненно, алгоритмы сортировки с временем выполнения
После изучения данной статьи, приобретённая вами интуиция относительно анализа сложности алгоритмов должна будет помогать вам создавать быстрые программы и сосредотачивать усилия по оптимизации на тех вещах, которые действительно имеют большое влияние на скорость выполнения. Всё вместе позволит вам работать более продуктивно. К тому же математический язык и нотации (например, «большое О»), рассмотренные в данной статье, будут вам полезны при общении с другими разработчиками программного обеспечения, когда речь зайдёт о времени выполнения алгоритмов, и, надеюсь, вы сможете применить на практике приобретённые знания.
Статья публикуется под Creative Commons 3.0 Attribution. Это означает, что вы можете копировать её, публиковать на своих веб-сайтах, вносить в текст изменения и вообще делать с ней всё, что заблагорассудится. Только не забывайте упоминать при этом моё имя. Единственное но: если вы основываете свою работу на данном тексте, то я настоятельно призываю вас публиковать её под Creative Commons, чтобы облегчить совместную работу и распространение информации.
Спасибо за то, что дочитали до конца!
Из-за большого объёма оригинальной статьи я разбила её на части, которых в общей сложности будет четыре.
Я (как всегда) буду крайне признательна за любые замечания в личку по улучшению качества перевода.
Опубликовано ранее:
Часть 1
Часть 2
Часть 3
Оптимальная сортировка
Поздравляю! Теперь вы знаете о том, как анализировать сложность алгоритмов, что такое асимптотическая оценка и нотация «большое-О». Вы также в курсе, как интуитивно выяснить является ли сложностью алгоритма
O( 1 ), O( log( n ) ), O( n ), O( n2 ) и так далее. Вы знакомы с символами o, O, ω, Ω, Θ и понятием «наихудшего случая». Если вы добрались до этого места, то моя статья уже выполнила свою задачу.Этот финальный раздел — опциональный. Он несколько сложнее, так что можете не стесняясь пропустить его, если хотите.От вас потребуется сфокусироваться и потратить некоторое время на решение упражнений. Однако, так же здесь будет продемонстрирован очень полезный и мощный способ анализа сложности алгоритмов, что, безусловно, стоит внимания.
Мы рассматривали реализацию сортировки, называемую сортировкой выбором, и упоминали, что она не является оптимальной. Оптимальный алгоритм — это тот, который решает задачу наилучшим образом, подразумевая, что не существует алгоритма, делающего это лучше. Т.е. все прочие алгоритмы для решения данной проблемы имеют такую же или большую сложность. Может существовать масса оптимальных алгоритмов, имеющих одинаковую сложность. Та же проблема сортировки может быть решена оптимально многими способами. Например, мы можем использовать для быстрой сортировки ту же идею, что и при бинарном поиске. Такой способ называется сортировкой слиянием.
Прежде, чем реализовать собственно сортировку слиянием, нам надо написать вспомогательную функцию. Назовём её
merge, и пусть она принимает два уже отсортированных массива и соединяет их в один (тоже отсортированный). Это легко сделать:def merge( A, B ):
if empty( A ):
return B
if empty( B ):
return A
if A[ 0 ] < B[ 0 ]:
return concat( A[ 0 ], merge( A[ 1...A_n ], B ) )
else:
return concat( B[ 0 ], merge( A, B[ 1...B_n ] ) )
Функция
concat принимает элемент («голову») и массив («хвост») и соединяет их, возвращая новый массив с «головой» в качестве первого элемента и «хвостом» в качестве оставшихся элементов. Например, concat( 3, [ 4, 5, 6 ] ) вернёт [ 3, 4, 5, 6 ]. Мы используем A_n и B_n, чтобы обозначить размеры массивов A и B соответственно.Упражнение 8
Убедитесь, что функция выше действительно осуществляет слияние. Перепишите её на вашем любимом языке программирования, используя итерации (цикл for) вместо рекурсии.
Анализ этого алгоритма показывает, что его время выполнения —
Θ( n ), где n — длина результирующего массива (n = A_n + B_n).Упражнение 9
Проверьте, что временем выполнения
merge является Θ( n ).Используя эту функцию, мы можем построить лучший алгоритм сортировки. Идея следующая: мы разбиваем массив на две части, рекурсивно сортируем каждую из них и объединяем два отсортированных массива в один. Псевдокод:
def mergeSort( A, n ):
if n = 1:
return A # it is already sorted
middle = floor( n / 2 )
leftHalf = A[ 1...middle ]
rightHalf = A[ ( middle + 1 )...n ]
return merge( mergeSort( leftHalf, middle ), mergeSort( rightHalf, n - middle ) )
Эта функция сложнее предыдущих для понимания, поэтому выполнение следующего упражнения может потребовать у вас больше времени.
Упражнение 10
Убедитесь в правильности
mergeSort (т.е. проверьте, что она верно сортирует переданный ей массив). Если вы не можете понять, почему она в принципе работает, то прорешайте вручную небольшой пример. При этом не забудьте убедиться, что leftHalf и rightHalf получаются при разбиении массива примерно пополам. Разбиение не обязательно должно приходиться точно на середину, если, например, массив содержит нечётное количество элементов (вот для чего нам нужна функция floor).В качестве финального упражнения давайте проанализируем сложность
mergeSort. На каждом шаге мы разбиваем исходный массив на две равные части (аналогично binarySearch). Однако, в этом случае дальнейшие вычисления происходят на обеих частях. После возврата рекурсии мы применяем к результатам операцию merge, что занимает Θ( n ) времени. Итак, мы разбили оригинальный массив на две части, размером
n / 2 каждая. Когда мы будем их соединять, в операции будут участвовать n элементов, следовательно, время выполнения будет Θ( n ). Рисунок ниже поясняет эту рекурсию: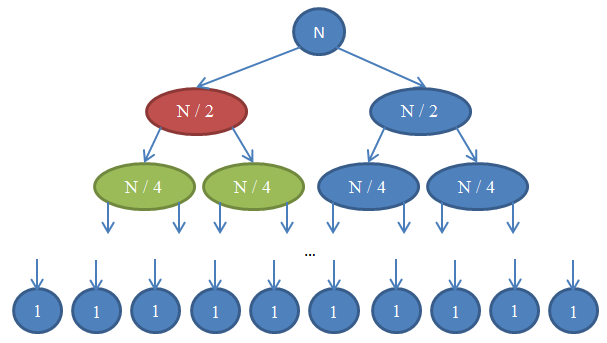
Давайте посмотрим, что здесь происходит. Каждый кружок представляет собой вызов функции
mergeSort. Число в кружке показывает количество элементов в массиве, который будет отсортирован. Верхний синий кружок — первоначальный вызов mergeSort для массива, размером n. Стрелочки показывают рекурсивные вызовы между функциями. Оригинальный вызов mergeSort порождает два новых для массивов, размером n / 2 каждый. В свою очередь, каждый из них порождает ещё два вызова с массивами в n / 4 элементов, и так далее до тех пор, пока мы не получим массив размера 1. Эта диаграмма называется рекурсивным деревом, потому что иллюстрирует работу рекурсии и выглядит как дерево (точнее, как инверсия дерева с корнем вверху и листьями внизу).Заметьте, что количество элементов в каждой строке остаётся равным
n. Так же обратите внимание, что каждый вызывающий узел использует для операции merge результаты, полученные от вызываемых узлов. Например, красный узел сортирует n / 2 элементов. Чтобы сделать это, он разбивает n / 2 массив на два по n / 4, рекурсивно вызывает с каждым из них mergeSort (зелёные узлы) и объединяет результаты в единое целое размером n / 2.В результате сложностью каждой строки является
Θ( n ). Мы знаем, что количество таких строк, называемое глубиной рекурсивного дерева, будет log( n ). Основанием для этого являются те же аргументы, которые мы использовали для бинарного поиска. Итак, у нас log( n ) строк со сложностью Θ( n ), следовательно, общая сложность mergeSort: Θ( n * log( n ) ). Это намного лучше, чем Θ( n2 ), которую нам даёт сортировка выбором (помните, log( n ) намного меньше n, поэтому n * log( n ) так же намного меньше n * n = n2).Как вы видели в последнем примере, анализ сложности позволяет нам сравнивать алгоритмы, чтобы понять, который из них лучше. Исходя из этих соображений, теперь мы можем быть уверены, что для массивов больших размеров сортировка слиянием намного опередит сортировку выбором. Такое заключение было бы проблематично сделать, если бы мы не имели теоретического базиса анализа разработанных нами алгоритмов. Несомненно, алгоритмы сортировки с временем выполнения
Θ( n * log( n ) ) широко используются на практике. Например, ядро Linux использует алгоритм, называемый «сортировкой кучей», который имеет такое же время выполнения, как и сортировка слиянием. Заметим, что мы не будем доказывать оптимальность данных алгоритмов сортировки. Это потребовало бы гораздо более громоздких математических аргументов, но будьте уверены: с точки зрения сложности нельзя найти вариант лучше.После изучения данной статьи, приобретённая вами интуиция относительно анализа сложности алгоритмов должна будет помогать вам создавать быстрые программы и сосредотачивать усилия по оптимизации на тех вещах, которые действительно имеют большое влияние на скорость выполнения. Всё вместе позволит вам работать более продуктивно. К тому же математический язык и нотации (например, «большое О»), рассмотренные в данной статье, будут вам полезны при общении с другими разработчиками программного обеспечения, когда речь зайдёт о времени выполнения алгоритмов, и, надеюсь, вы сможете применить на практике приобретённые знания.
Вместо заключения
Статья публикуется под Creative Commons 3.0 Attribution. Это означает, что вы можете копировать её, публиковать на своих веб-сайтах, вносить в текст изменения и вообще делать с ней всё, что заблагорассудится. Только не забывайте упоминать при этом моё имя. Единственное но: если вы основываете свою работу на данном тексте, то я настоятельно призываю вас публиковать её под Creative Commons, чтобы облегчить совместную работу и распространение информации.
Спасибо за то, что дочитали до конца!
Ссылки
- Cormen, Leiserson, Rivest, Stein. Introduction to Algorithms, MIT Press
- Dasgupta, Papadimitriou, Vazirani. Algorithms, McGraw-Hill Press
- Fotakis. Course of Discrete Mathematics at the National Technical University of Athens
- Fotakis. Course of Algorithms and Complexity at the National Technical University of Athens
